在医疗 AI 领域,很多分类任务具有有序类别 的特性,如疾病严重程度(轻度→中度→重度)、肿瘤分级(G1→G2→G3)等。这类任务被称为序数回归(Ordinal Regression),需要特殊的损失函数设计。本文将深入解析序数回归损失函数的原理及其实现代码。
一、序数回归与传统分类的区别
传统分类任务(如疾病类型识别)假设类别之间是无序 的,而序数回归的类别具有自然顺序。例如:
- 疾病严重程度:0(正常)→1(轻度)→2(中度)→3(重度)
- 影像评分:1 分→2 分→3 分→4 分→5 分
对于这类任务,传统的交叉熵损失存在局限性:它只关注类别预测的正确性,而忽略了类别之间的顺序关系。例如,将真实标签为 "中度"(2)的样本预测为 "重度"(3),与预测为 "轻度"(1),在交叉熵损失中被视为同等错误,但实际上前者的错误程度更小。
二、序数回归损失函数的核心思想
序数回归损失函数的设计目标是:不仅要正确分类,还要保持类别之间的顺序关系。常见的实现方法有以下几种:
- 累积概率模型:将序数分类转化为一系列二分类问题
- 相邻类别比较:比较相邻类别的预测概率
- 距离敏感损失:惩罚与真实类别距离更远的错误预测
代码中实现的是累积概率模型,这是最常用的序数回归方法之一。
三、累积概率模型的数学原理
累积概率模型的核心思想是:将序数类别转化为一系列累积概率。对于有K个类别的问题,定义K-1个阈值cutspoints,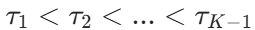 ,则样本属于类别k的概率为:
,则样本属于类别k的概率为: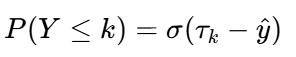 ,其中:
,其中:

四、代码实现解析
下面详细解析序数回归损失函数的实现代码:
python
def ordinal_regression_loss(self, pred, label, num_classes, train_cutpoints=False, scale=20.0):
# 1. 计算阈值(cutpoints)
num_cutpoints = num_classes - 1#计算阈值数量
cutpoints = torch.arange(num_cutpoints, device=pred.device).float() * scale / (num_classes - 2) - scale / 2
cutpoints = nn.Parameter(cutpoints, requires_grad=train_cutpoints)
# 2. 计算累积概率
sigmoids = torch.sigmoid(cutpoints - pred)
# 3. 构建概率矩阵:将累积概率转换为每个类别的概率
link_mat = sigmoids[:, 1:] - sigmoids[:, :-1] # 中间类别的概率
link_mat = torch.cat((
sigmoids[:, [0]], # 第一个类别的概率
link_mat, # 中间类别的概率
(1 - sigmoids[:, [-1]]) # 最后一个类别的概率
), dim=1)
# 4. 数值稳定性处理:防止对数计算时出现NaN
eps = 1e-15
likelihoods = torch.clamp(link_mat, eps, 1 - eps)
# 5. 计算负对数似然损失
neg_log_likelihood = torch.log(likelihoods)
if label is None:
loss = 0
else:
loss = -torch.gather(neg_log_likelihood, 1, label).mean()
return loss, likelihoods五、关键步骤详解
1. 阈值(Cutpoints)计算
python
cutpoints = torch.arange(num_cutpoints, device=pred.device).float() * scale / (num_classes - 2) - scale / 2- 作用:生成均匀分布的阈值点,将连续空间划分为多个区间
例如:

- 参数 :
scale:控制阈值的范围,默认 20.0train_cutpoints:是否将阈值作为可训练参数(默认为 False)
- 基础序列torch.arange(num_cutpoints):对于K个类别,生成序列0,1,2,...,K-2
- 缩放因子 :
scale / (num_classes - 2)调整阈值之间的间隔 - 线性变换 :
* scale / (num_classes - 2) - scale / 2:将基础序列映射到[-scale/2, scale/2]区间。
这两行代码的核心是将连续的预测空间均匀划分为多个有序区间 ,每个区间对应一个类别。通过调整 scale 参数,可以控制区间的宽度,适应不同的任务需求。当 train_cutpoints=True 时,模型会在训练过程中自动学习最优的阈值位置,进一步提升序数回归的性能。
2. 累积概率计算
python
sigmoids = torch.sigmoid(cutpoints - pred)- 作用:将模型预测值与阈值的差值通过 sigmoid 函数转换为累积概率
- 示例:对于 3 个类别(2 个阈值),累积概率为:
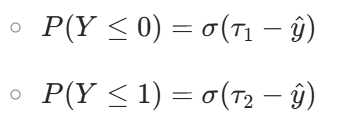
将模型输出的抽象分数 pred,通过与阈值 cutpoints 的比较,转换为 "属于某个类别或更低等级" 的概率 。这个概率越接近 1,说明 pred 越可能落在该类别或更低等级的区间里。
3. 类别概率矩阵构建
python
link_mat = sigmoids[:, 1:] - sigmoids[:, :-1]
link_mat = torch.cat((sigmoids[:, [0]], link_mat, 1 - sigmoids[:, [-1]]), dim=1)
sigmoids[:, 1:]→ 取所有样本的第二个及以后的累积概率sigmoids[:, :-1]→ 取所有样本的第一个及以前的累积概率
4.数值稳定性处理:防止对数计算时出现NaN
在深度学习中,当计算概率的对数时(如交叉熵损失中的 log(p)),如果概率 p 非常接近 0(如 1e-20),会导致以下问题:
- 数值下溢:计算机无法精确表示极小数,可能返回 0
- 对数计算错误 :
log(0)会返回负无穷(-inf) - 梯度爆炸 :反向传播时,
-inf的梯度会导致参数更新异常
同样,当概率 p 接近 1 时,1-p 接近 0,也会引发类似问题。
torch.clamp(input, min, max)将输入张量的每个元素限制在[min, max]范围内- 确保所有概率值在
[1e-15, 1-1e-15]之间,避免过于接近 0 或 1
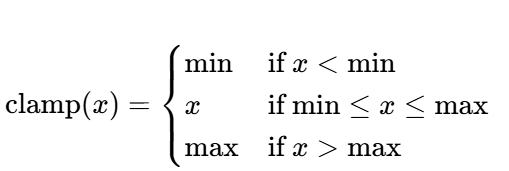
5. 负对数似然损失计算
python
neg_log_likelihood = torch.log(likelihoods)
loss = -torch.gather(neg_log_likelihood, 1, label).mean()- 作用:计算每个样本的真实类别对应的负对数概率,并取平均
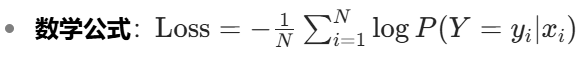
通过最大似然估计,让模型预测的真实类别概率最大化。具体步骤为:
- 计算对数似然:将概率转换为对数空间
- 按标签选择:提取真实类别对应的对数似然
- 取负平均:转换为损失(越小越好)
六、为什么选择序数回归损失?
在医疗分类任务中,序数回归损失有以下优势:
- 利用顺序信息:充分利用类别之间的顺序关系,提高模型对程度差异的敏感性
- 减少信息损失:相比将序数问题简单视为分类问题,保留了更多结构信息
- 更好的校准:输出的概率具有更明确的临床意义(如疾病严重程度的概率)
- 提升性能:在序数分类任务中,通常比传统分类损失取得更好的性能
七、实践建议
-
阈值初始化:
- 代码中的线性初始化是常用方法,但对于特定任务,可根据先验知识自定义阈值
- 当
train_cutpoints=True时,模型会学习最优阈值位置
-
模型输出设计:
- 模型最后一层应输出单个连续值(而非类别概率),作为序数回归的预测值
- 可通过全连接层实现:
nn.Linear(input_dim, 1)
-
超参数调整:
scale参数影响阈值的分布范围,需根据具体任务调整- 对于严重不平衡的序数类别,可考虑加权损失
-
评估指标:
- 除准确率外,建议使用 Kendall's τ 或 Spearman 相关性等评估顺序一致性
- 医学场景中,还需关注不同严重程度类别的敏感性和特异性
八、总结
序数回归损失函数为具有顺序关系的医疗分类任务提供了更合适的优化目标。通过将类别转化为累积概率,它不仅能正确分类,还能保持类别之间的顺序关系,特别适合疾病严重程度分级、影像评分等医疗场景。
在实际应用中,可根据任务特点调整阈值初始化方式和损失函数参数,结合适当的评估指标,构建更符合临床需求的医疗 AI 模型。