一、是什么
官网:Elasticsearch:官方分布式搜索和分析引擎 | Elastic
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据
为什么有了mysql还要用它?
在mysql想要检索一个东西 ,大多都是like ,比如电商网站,你搜小米为什么出现的是小米手机还是真正的小米,如果用mysql去查,得写多少like
但是es它就能做到全文检索
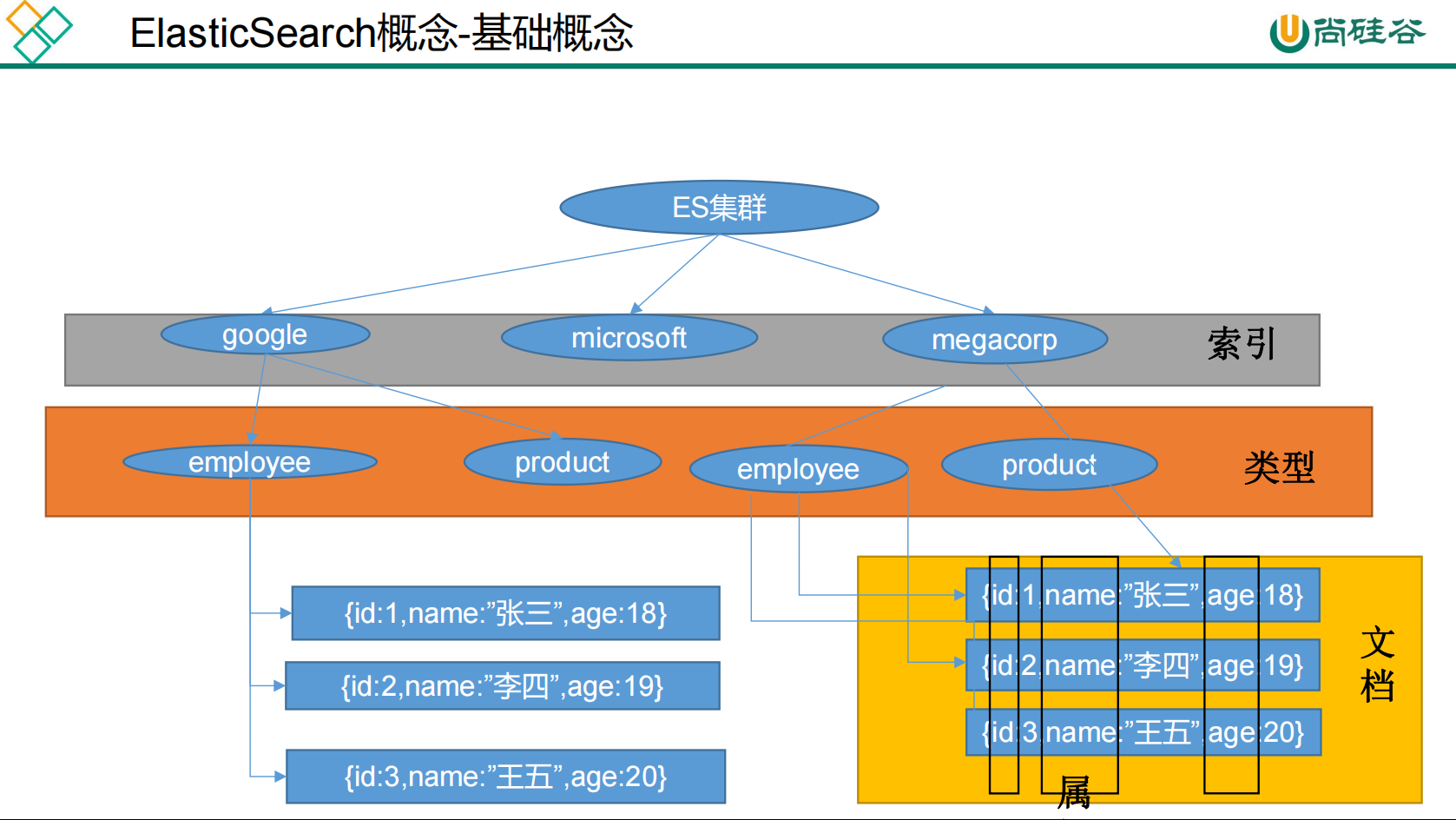
es基本概念
1 、 Index (索引)
动词,相当于 MySQL 中的 insert ;
名词,相当于 MySQL 中的 Database
2 、 Type (类型)
在 Index (索引)中,可以定义一个或多个类型。
类似于 MySQL 中的 Table ;每一种类型的数据放在一起;
3 、 Document (文档)
保存在某个索引( Index )下,某种类型( Type )的一个数据( Document ),文档是 JSON 格
式的, Document 就像是 MySQL 中的某个 Table 里面的内容;
4 、倒排索引机制
分词: 将整句分拆为单词
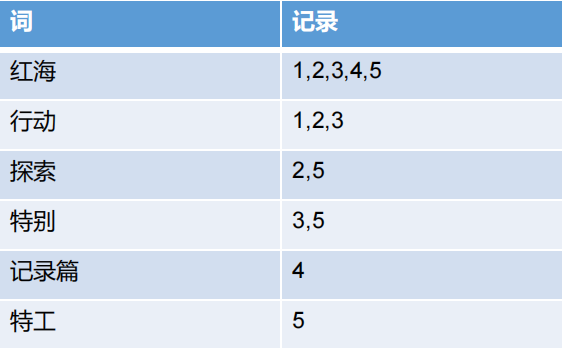
保存的记录
1- 红海行动
2- 探索红海行动
3- 红海特别行动
4- 红海记录篇
5- 特工红海特别探索
检索:
1 )、红海特工行动?
2 )、红海行动?
相关性得分:
刚刚我们说es可以做全文检索,主要依赖于它的倒排索引机制,我们会将数据库中的数据再保存一份在es中,es会将它们进行分词保存
比如上面的数据
将以下的保存信息按照某一个分词规则保存到es
1- 红海行动
2- 探索红海行动
3- 红海特别行动
4- 红海记录篇
5- 特工红海特别探索
分词后保存如下
词 记录
红海 1,2,3,4,5
行动 1,2,3
探索 2,5
特别 3,5
记录篇 4
特工 5
比如检索 红海特工行动
它要进行检索 也是将 红海特工行动 进行分词:红海 特工 行动
也就是看【红海 特工 行动】在哪些数据中有
只要记录里面包含这些 一个 或多个单词 都会查出来
红海 1,2,3,4,5
行动 1,2,3
特工 5
最终查到了12345
但是哪一个是我们真正想要的?
查出来的记录里面会有一个相关性得分
3 总共有三个单词命中了两个 2/3
5 有4个才命中两个 2/4 1/2
2/3 和 1/2 分母通分后 4/6 3/6 所以3相关性得分更高
二、安装
安装es
1 、下载镜像文件
docker pull elasticsearch:7.4.2
存储和检索数据
docker pull kibana:7.4.2
可视化检索数据
2 、创建实例
1 、 ElasticSearch
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
chmod -R 777 /mydata/elasticsearch/ 保证权限
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch: 7.4.2
以后再外面装好插件重启即可;
特别注意:
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \ 测试环境下,设置 ES 的初始内存和最大内存,否则导
致过大启动不了 ES
参数解释
--name 为容器起个名字
-p 是暴露两个端口 9200 是后来我们发送http请求 也就是说rest api的时候,给elasticsearch 的9200发送请求 9300是es在集群的情况下,它们节点之间的通信端口
单结点运行
-e ES_JAVA_OPTS非常重要 如果不指定,es 一启动就会把内存全部占用,整个虚拟机就卡死了,在这里指定初始内存64m 最大内存128m,在测试期间肯定就够用了,当然项目上线以后的真正的服务器内存都是32G的,我们可以多分配
-v 挂载文件和目录
-d 后台启动 用哪个镜像
2 、 Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS= http://192.168.56.10:9200 -p 5601:5601 \
-d kibana:7.4.2
http://192.168.56.10:9200 一定改为自己虚拟机的地址
安装好后在浏览器输入 ip:9200
返回就说明安装成功
{
"name" : "00101784e7bf",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "oPcArjTgToyGbGXvEDCkDA",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}安装kibana
可视化界面
docker run --name kibana -e ELASTICSEARCH_HOSTS= http://192.168.56.10:9200 -p 5601:5601 \
-d kibana:7.4.2
http://192.168.56.10:9200 一定改为自己虚拟机的地址
浏览器输入 ip:5601访问到这个界面即为成功
设置两个容器开机自启动
docker update 容器id/容器name --restart=always三、初步检索
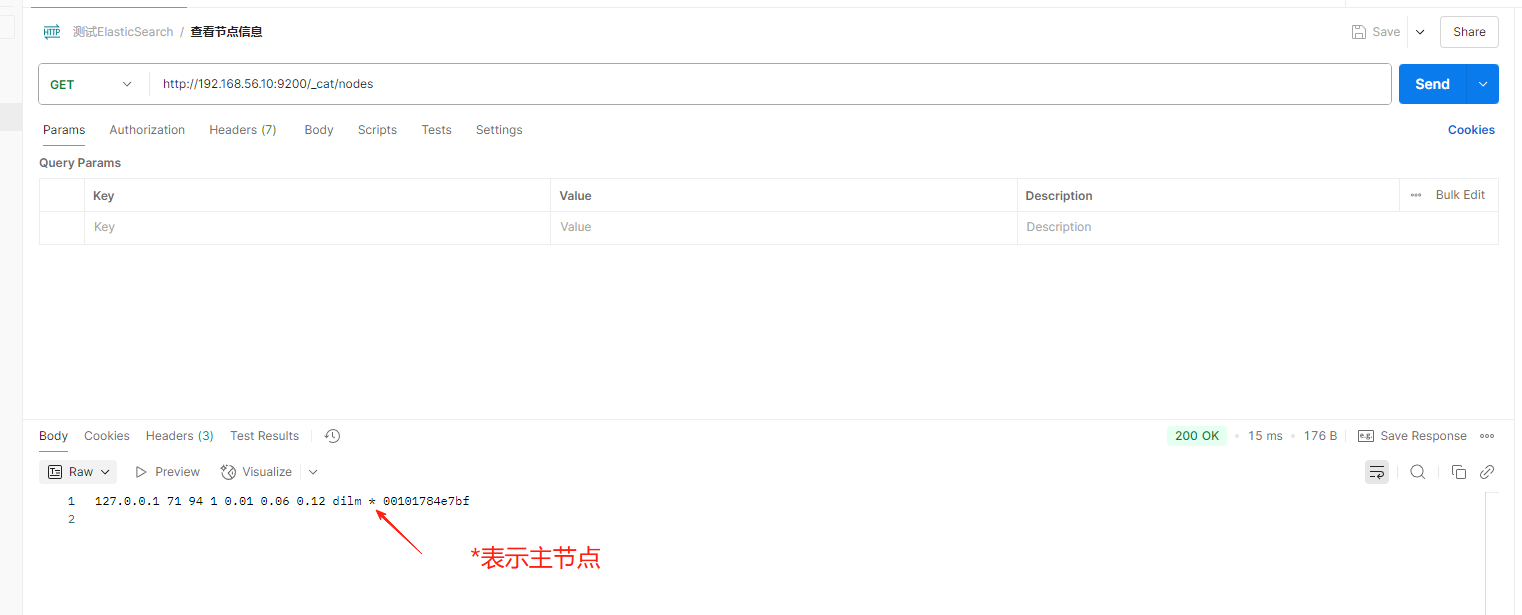
1、_cat
- GET /_cat/nodes:查看所有节点
- GET /_cat/health:查看 es 健康状况
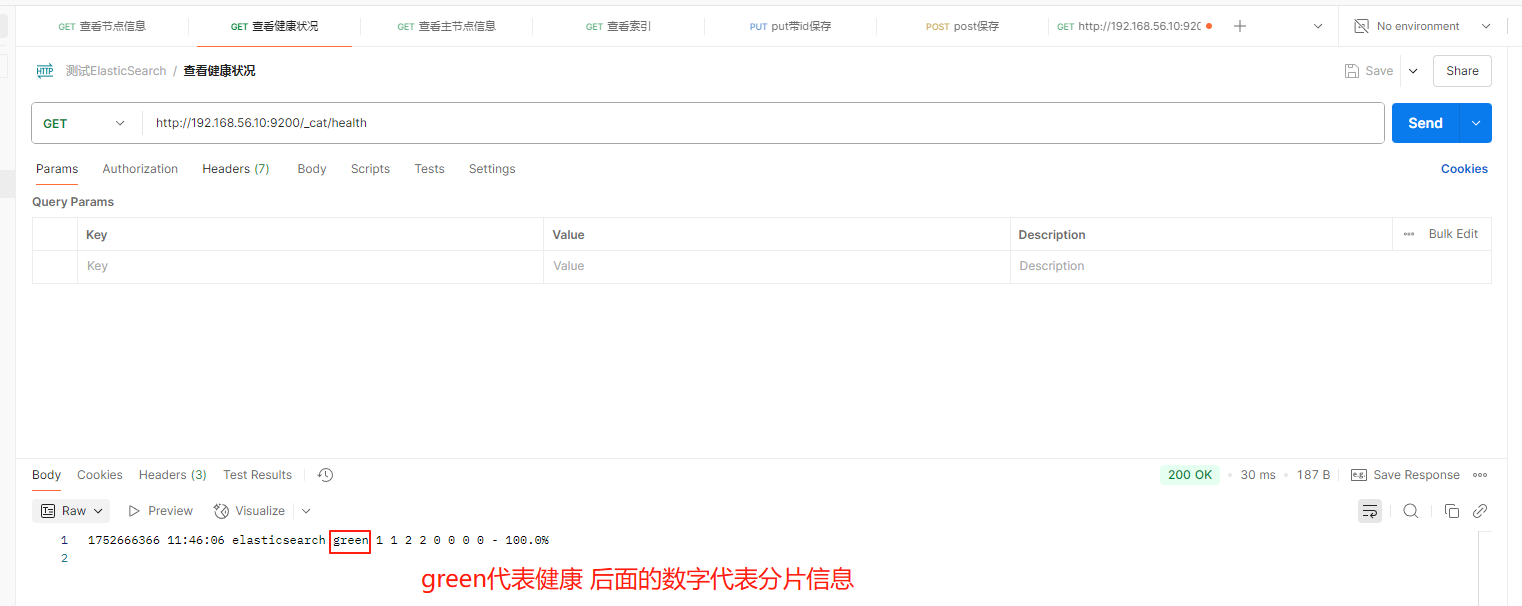
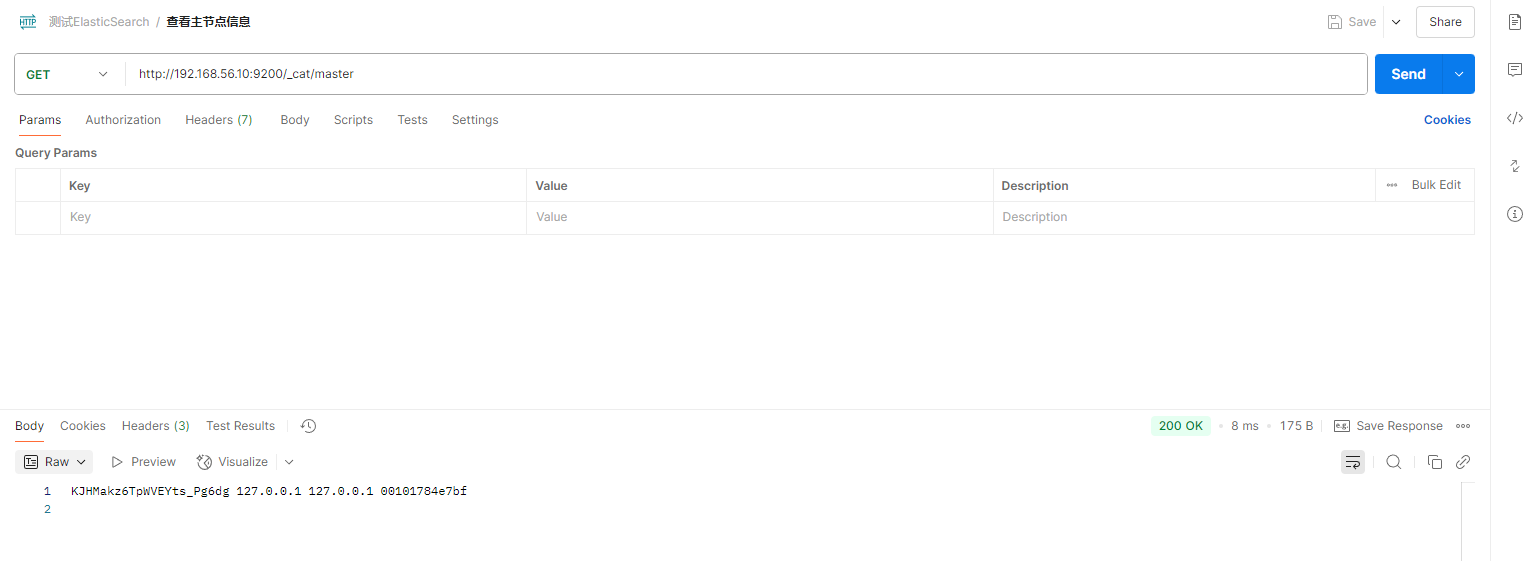
- GET /_cat/master:查看主节点
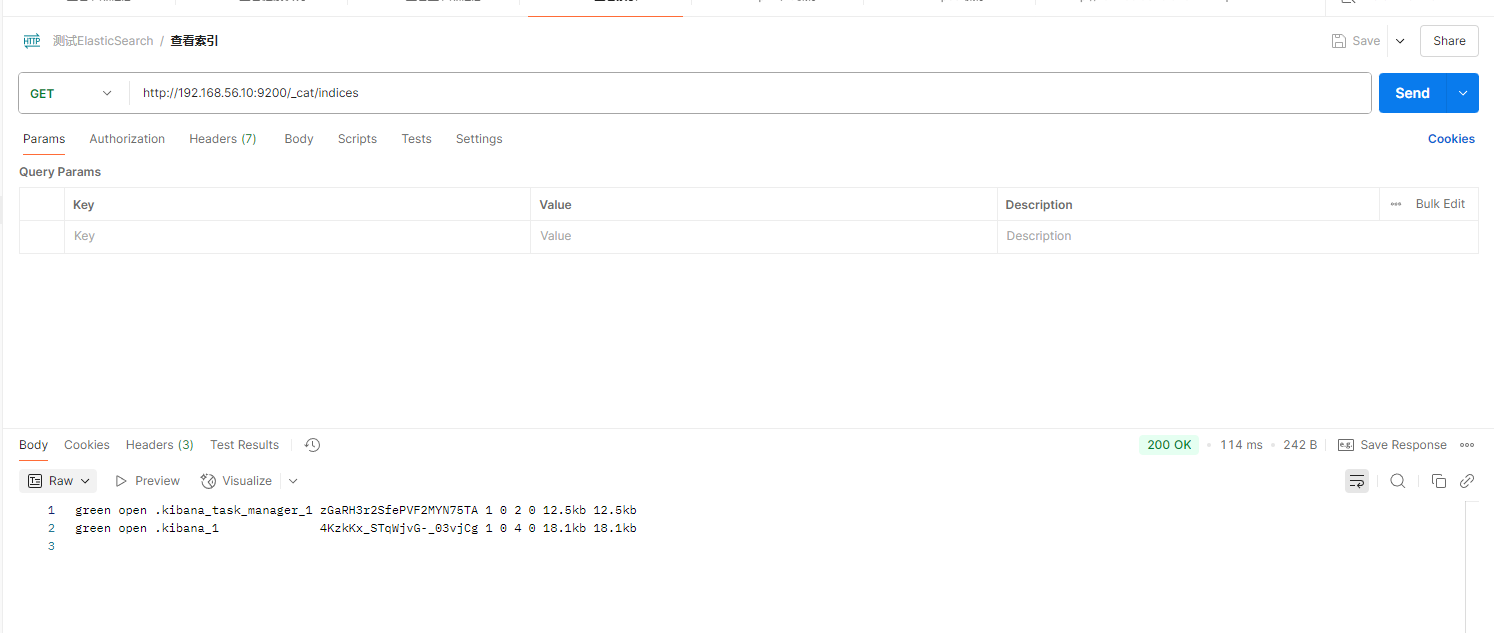
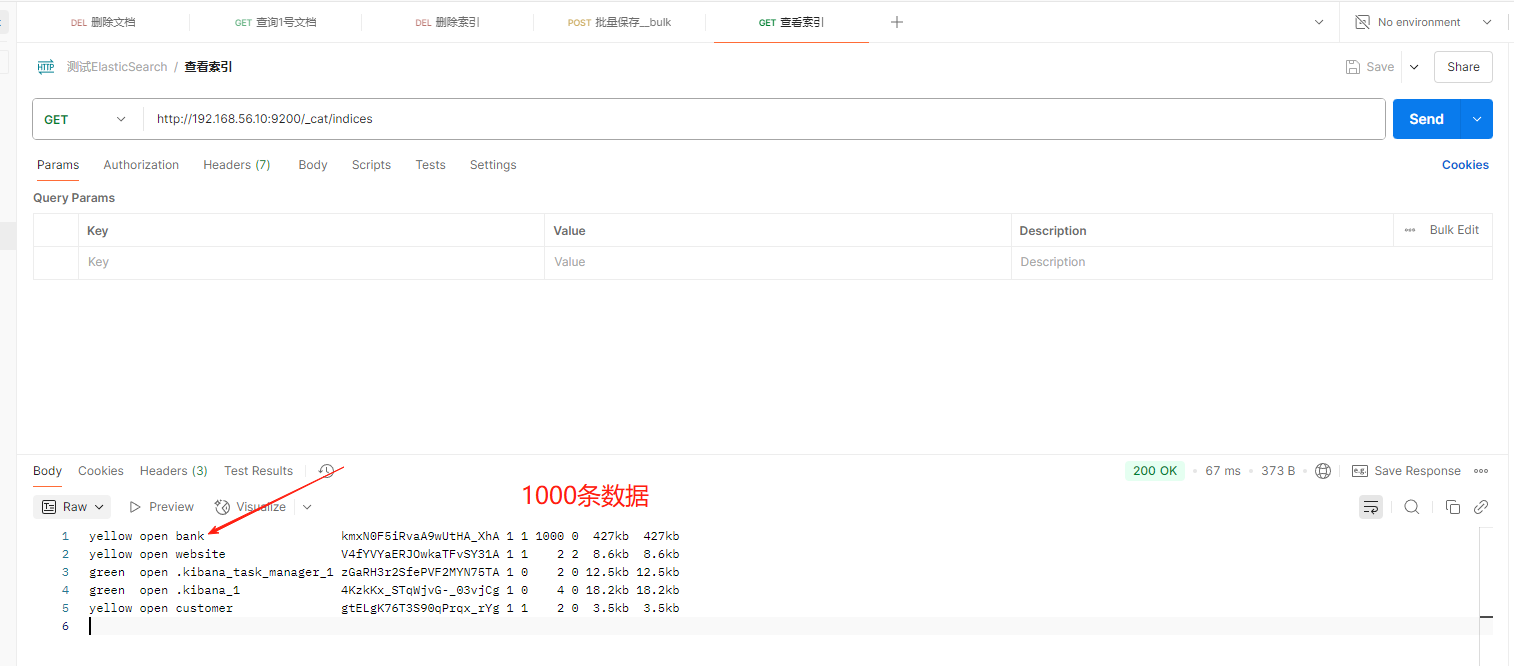
- GET /_cat/indices:查看所有索引 show databases;
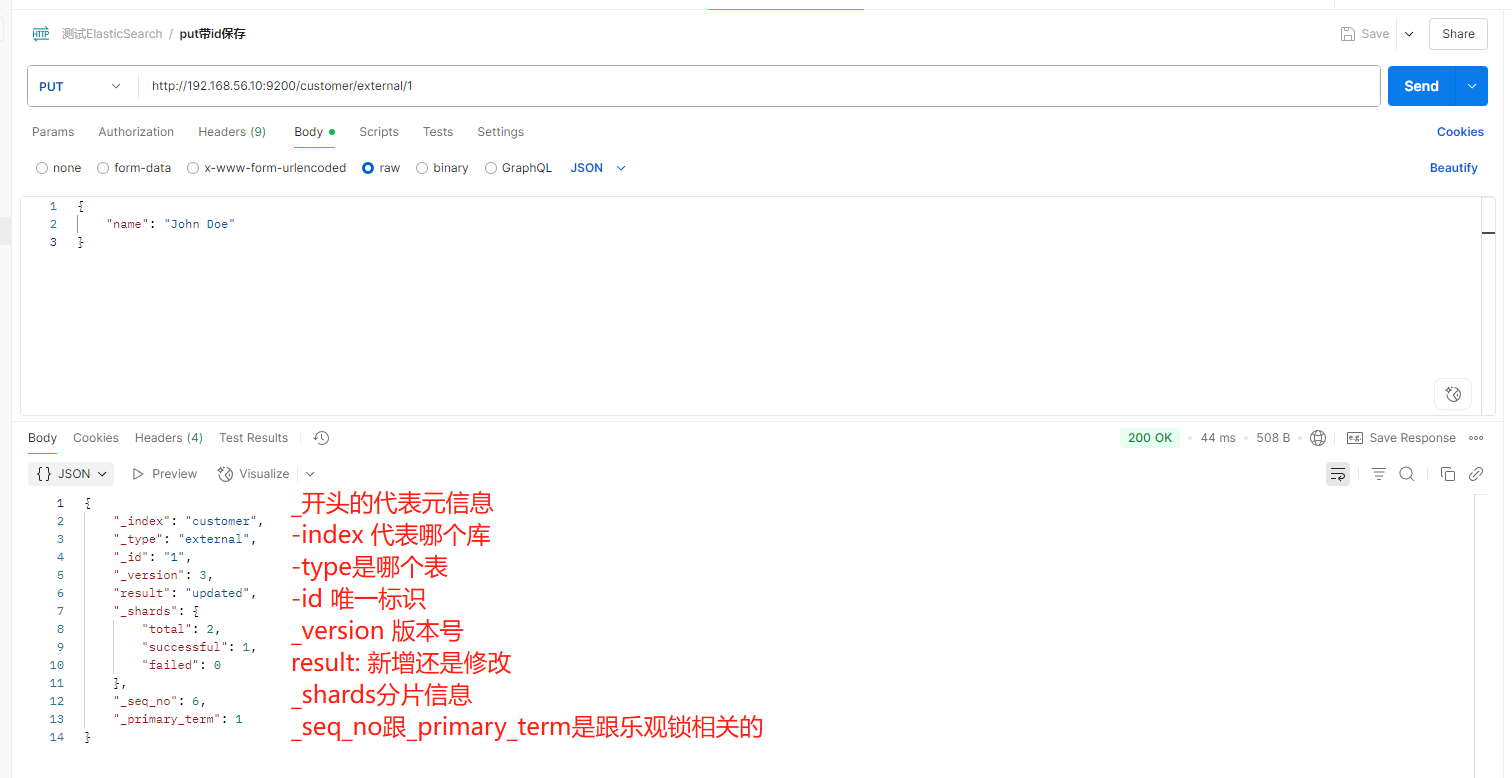
2、索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1 ;在 customer 索引下的 external 类型下保存 1 号数据为
post请求
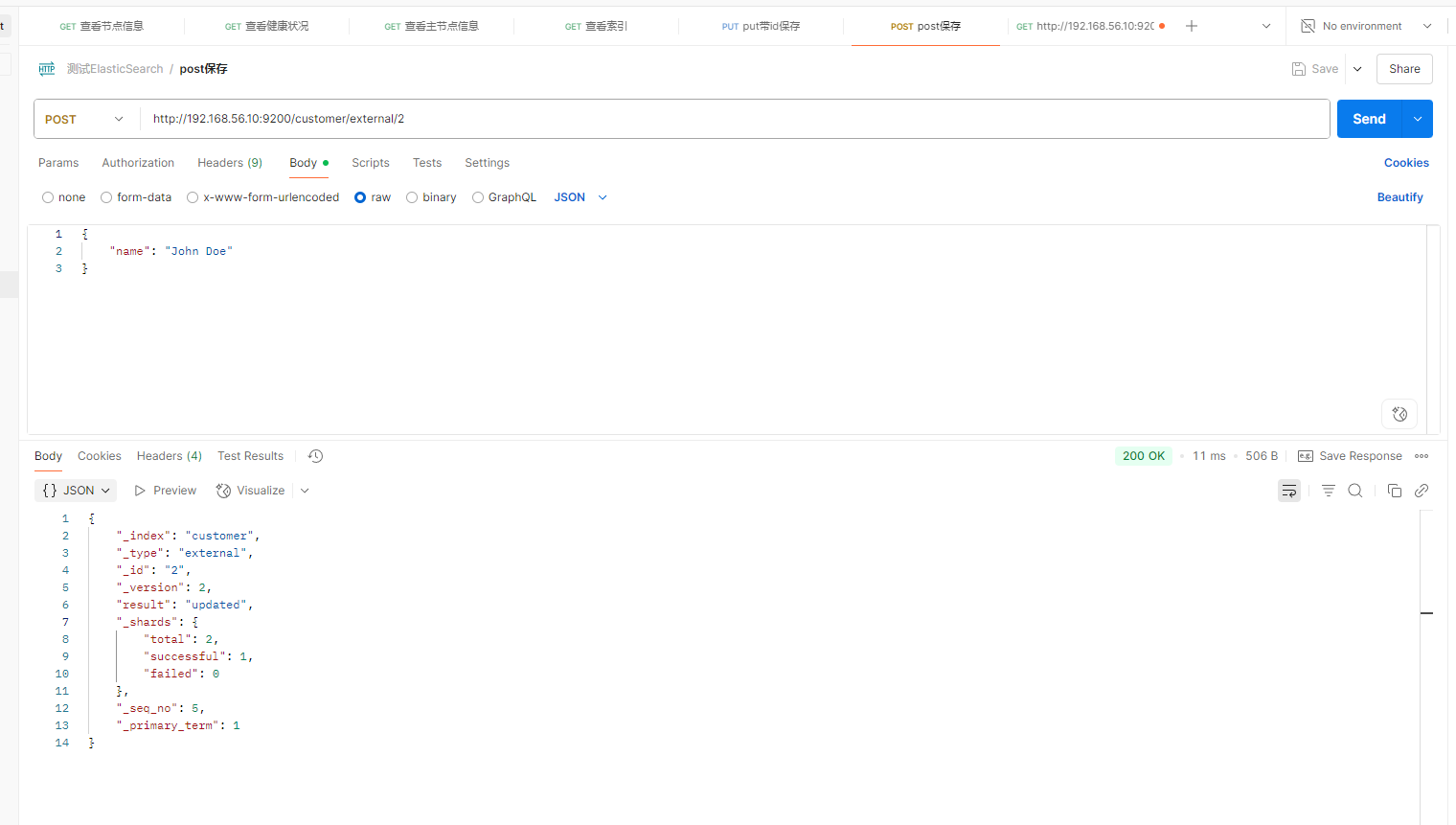
PUT 和 POST 都可以
PUT 可以新增可以修改。 PUT 必须指定 id ;由于 PUT 需要指定 id ,我们一般都用来做修改
操作,不指定 id 会报错。
POST 新增。如果不指定 id ,会自动生成 id 。指定 id 就会修改这个数据,并新增版本号
post新增的情况:不带id; 带了id但之前没数据
post修改的情况:带id,并且有数据
3**、查询文档**
GET customer/external/1
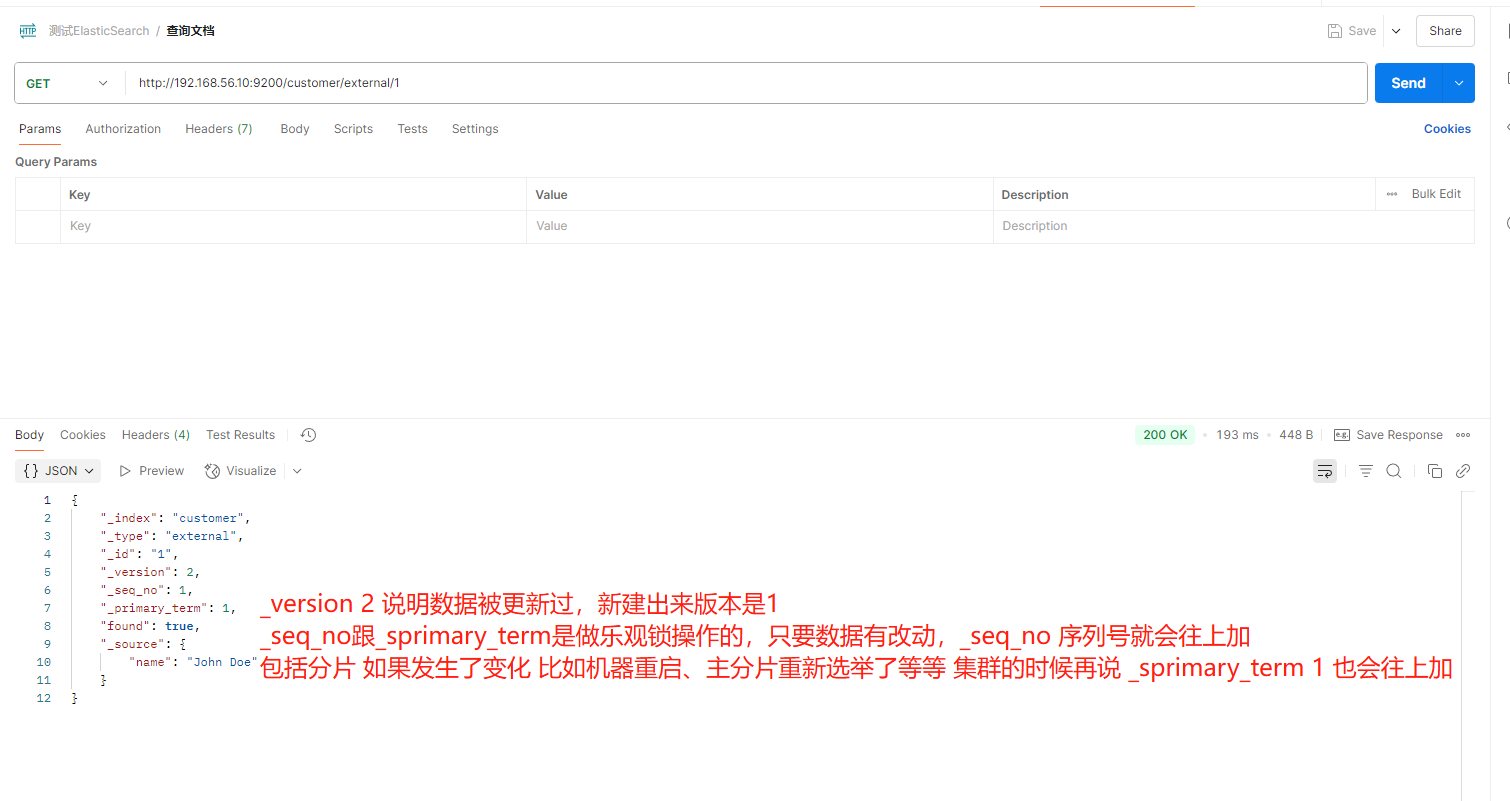
结果:
{
"_index": "customer", //在哪个索引
"_type": "external", //在哪个类型
"_id": "1", //记录 id
"_version": 2, //版本号
"_seq_no": 1, //并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": { //真正的内容
"name": "John Doe"
}
}更新携带 ?if_seq_no=0&if_primary_term=1
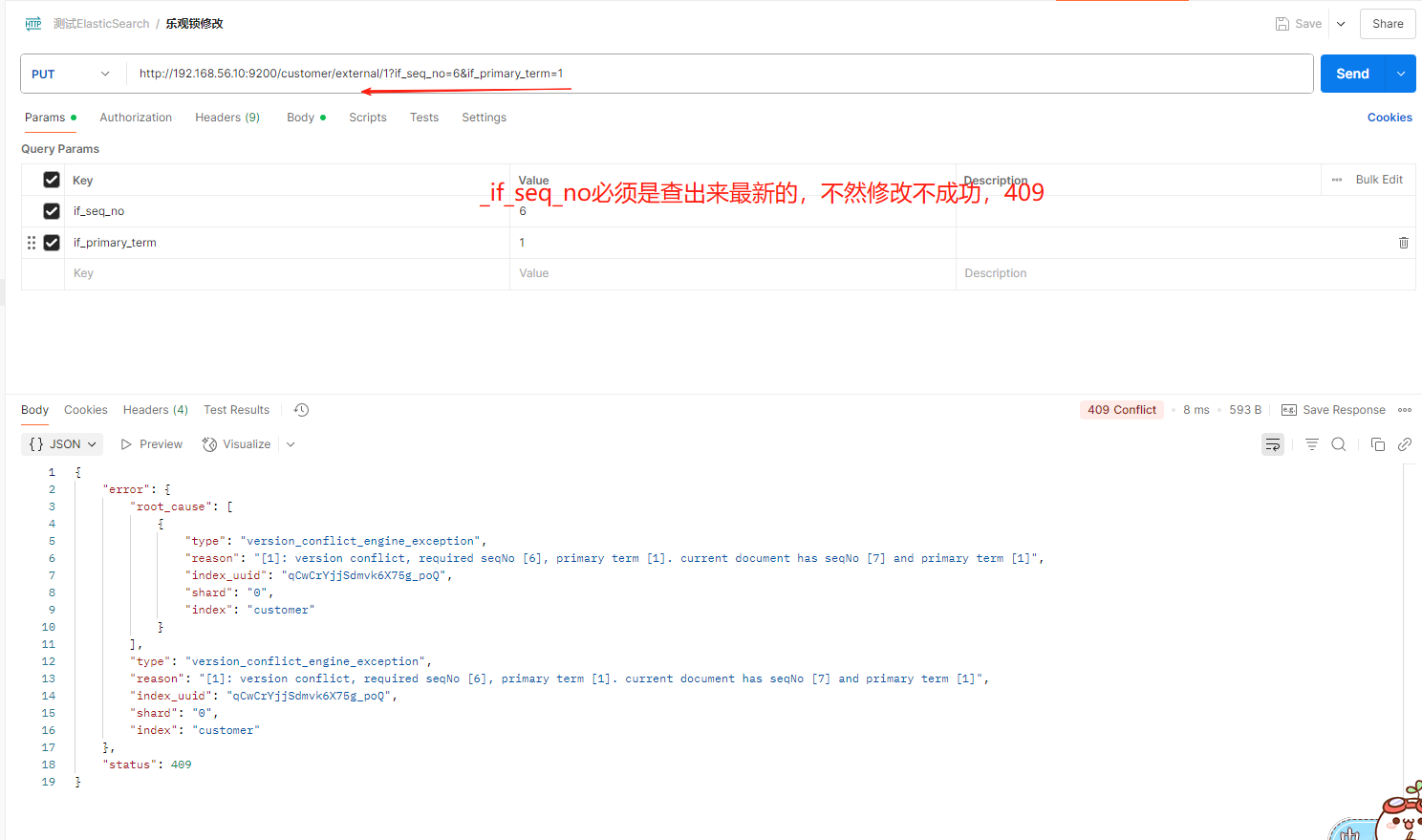
4**、更新文档**
-
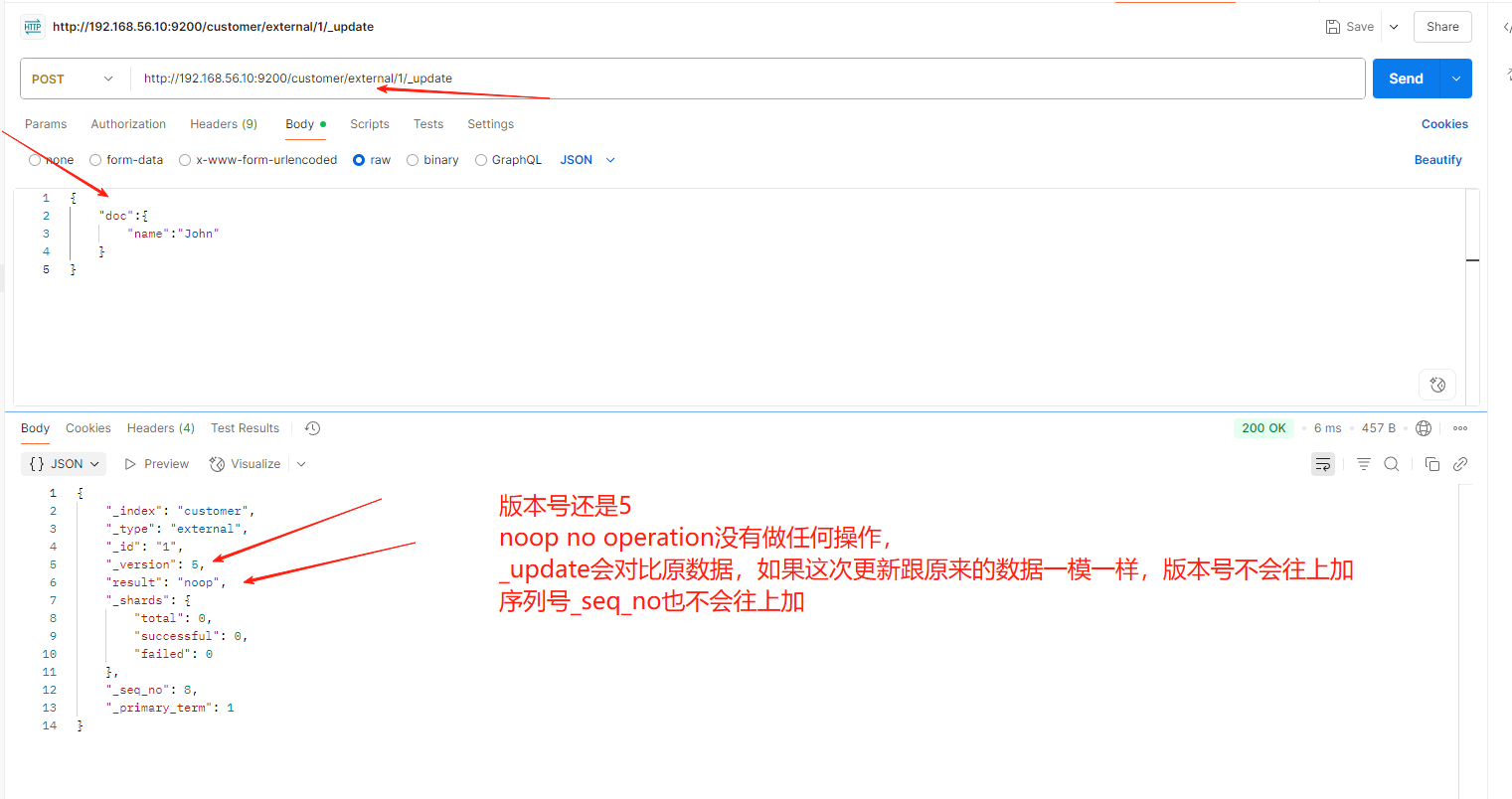
带_update
POST customer/external/1/_update
{
"doc":{
"name": "John Doew"
}
}
第一次发送请求
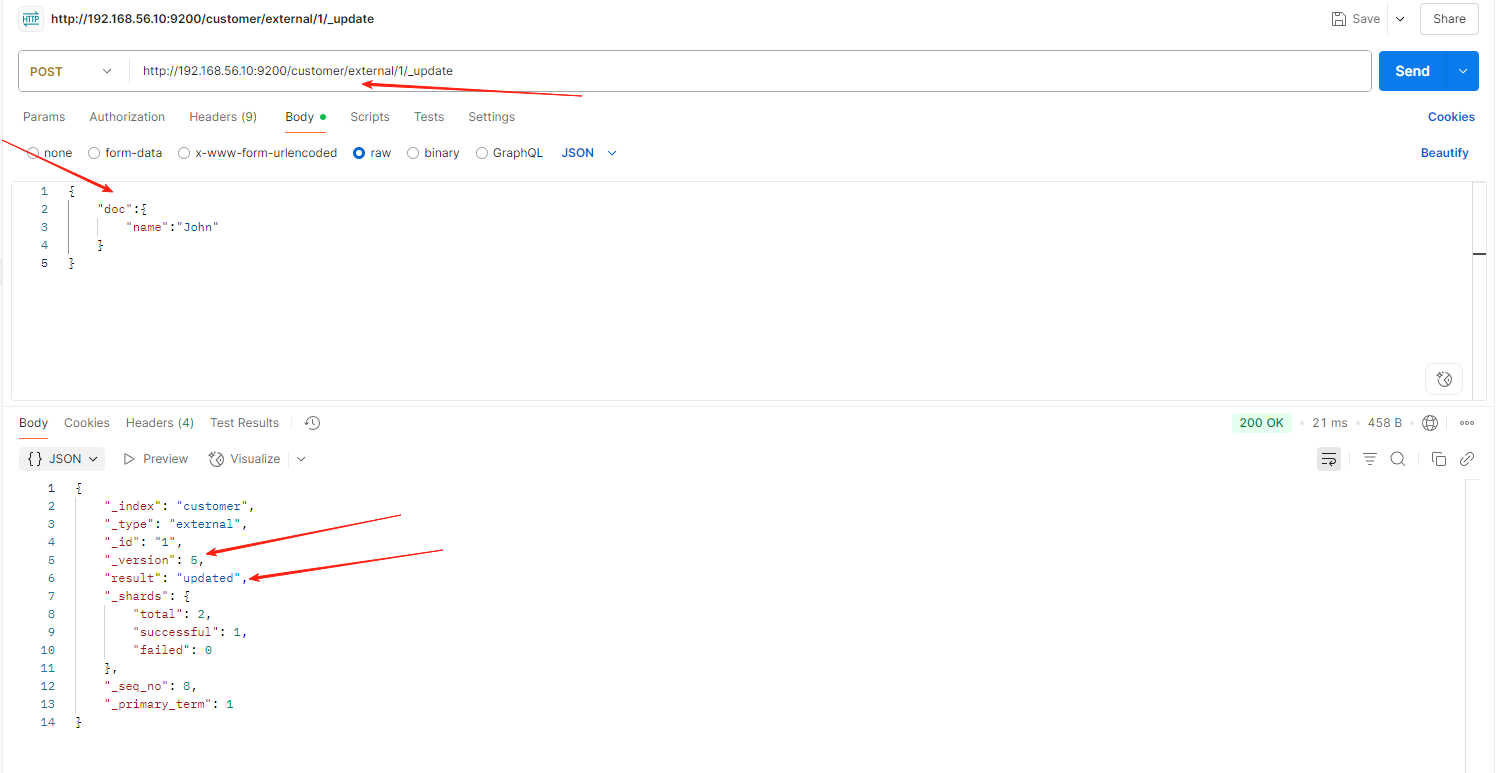
第二次发送请求
-
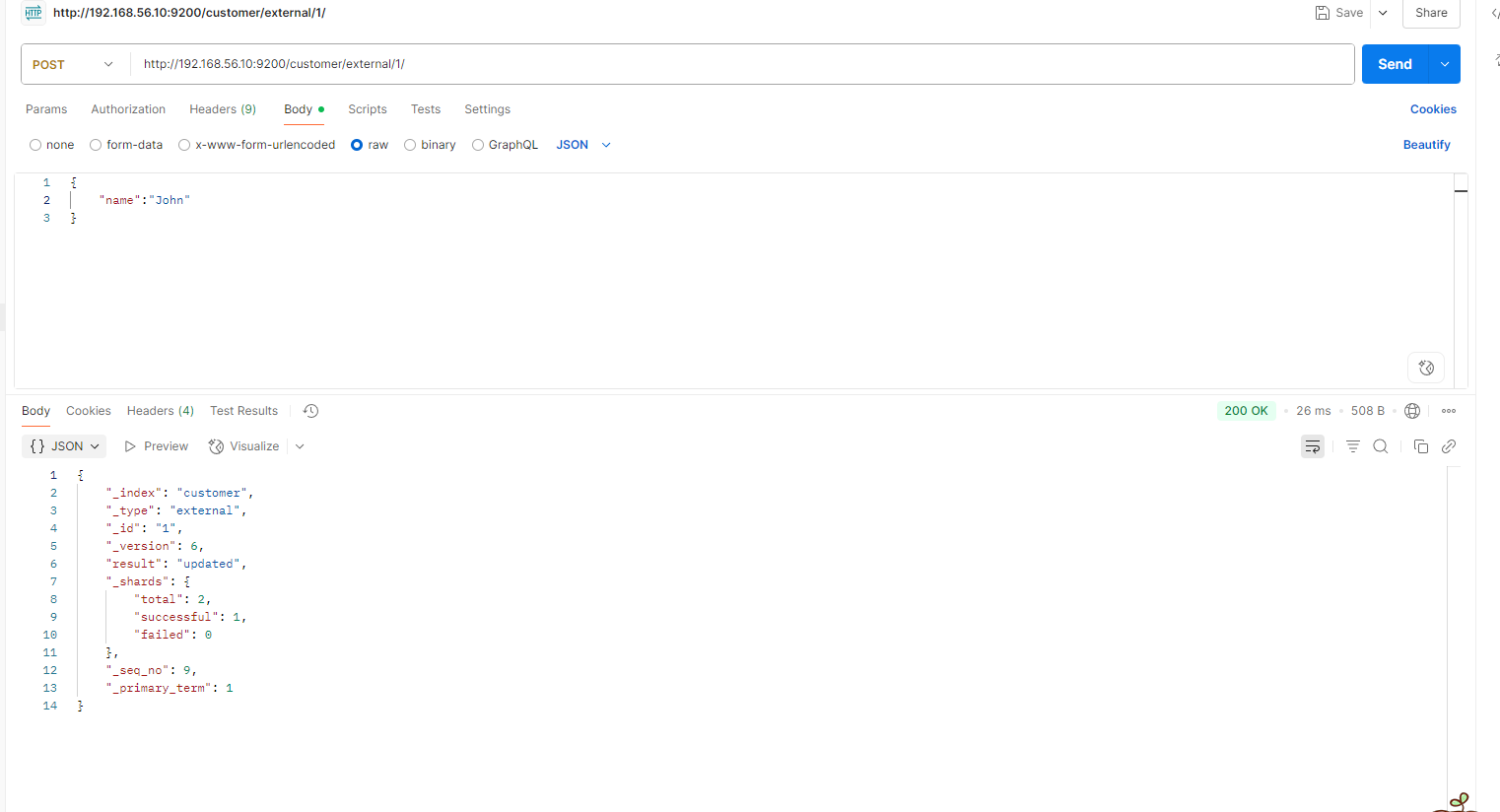
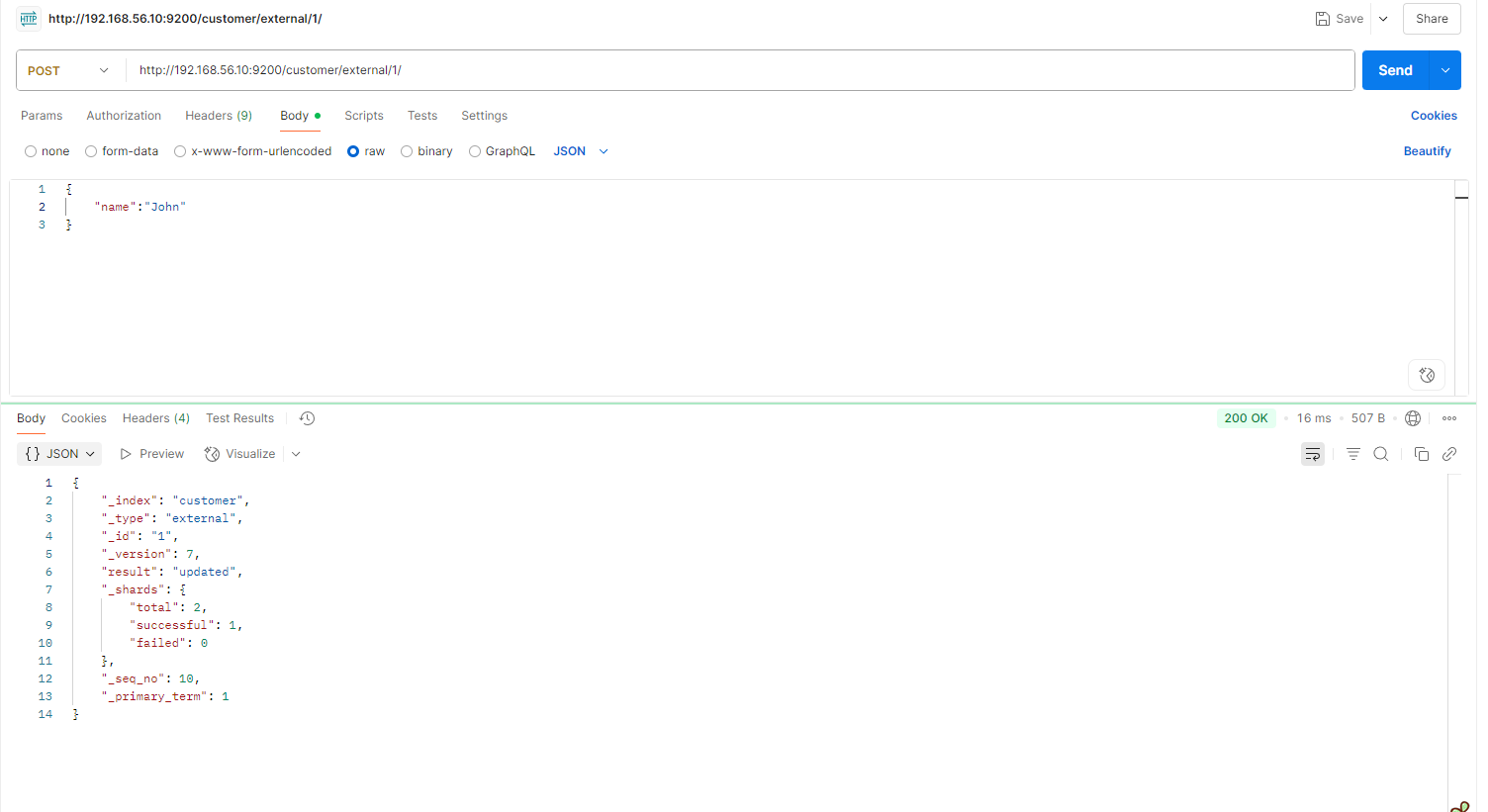
不带update
POST customer/external/1
{
"name": "John Doe2"
}
不断的发送请求,不断的更新成功,不会检查原数据
-
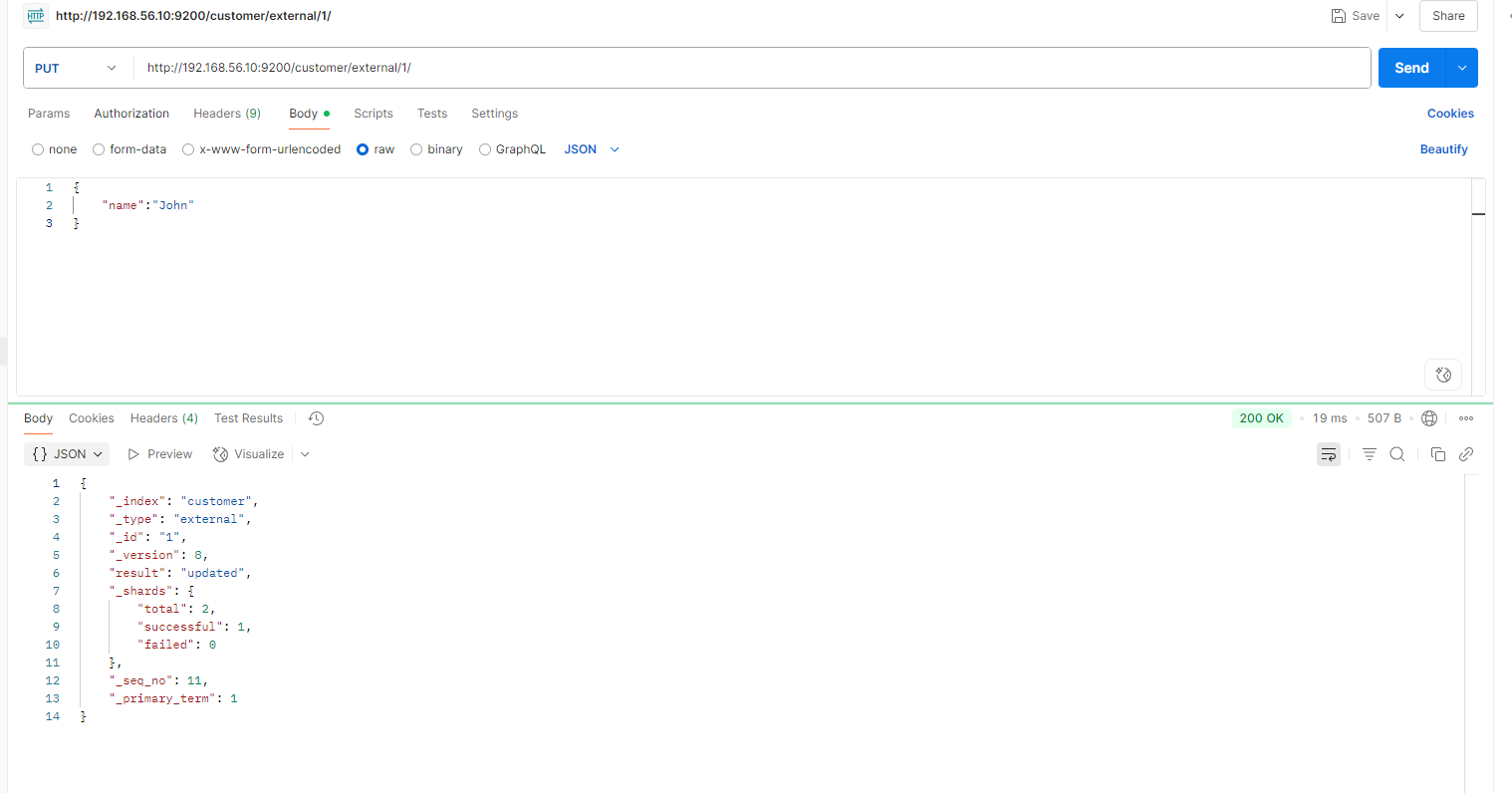
put更新一样
PUT customer/external/1
{
"name": "John Doe"
}
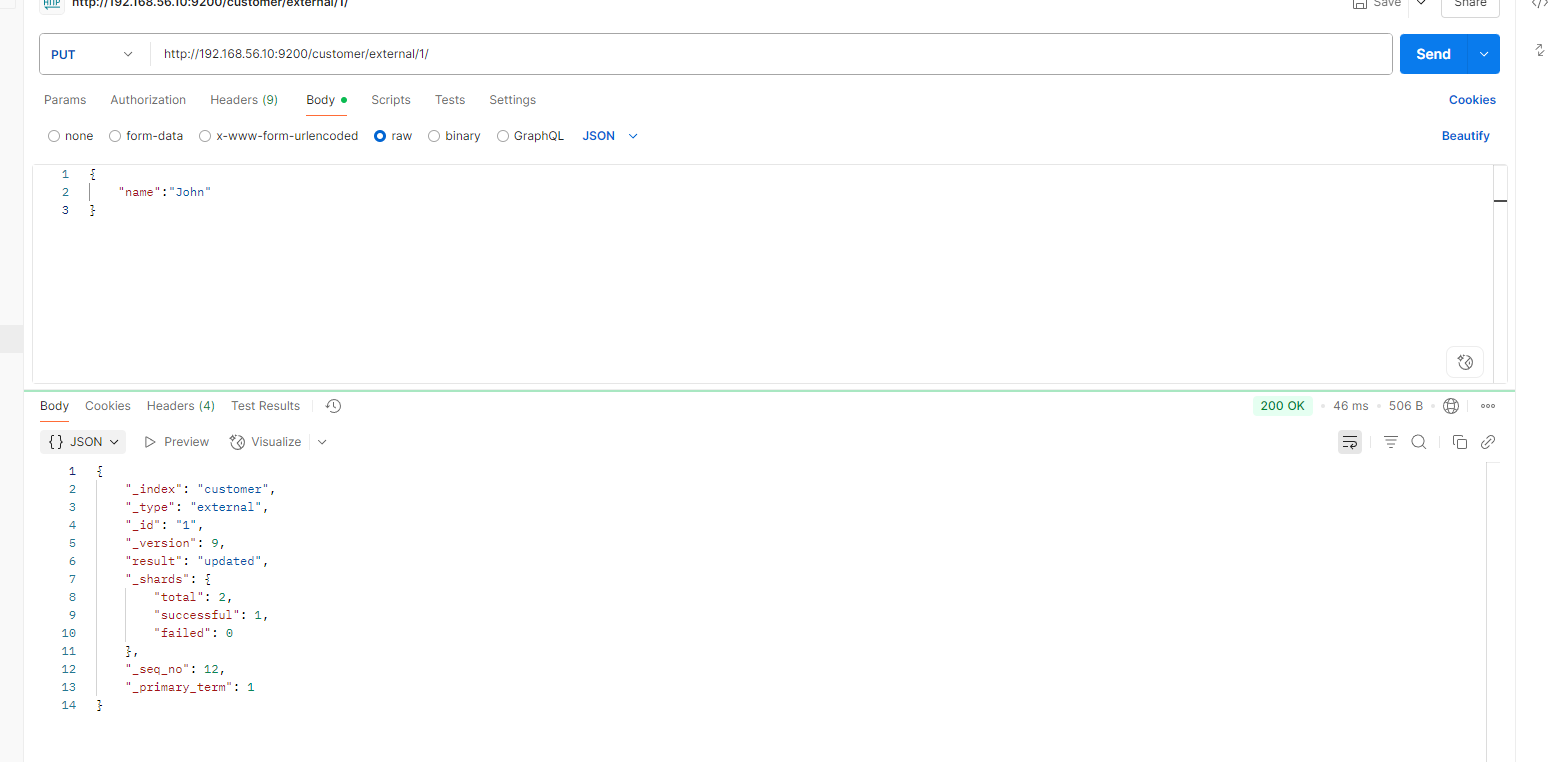
不同:
POST带 _update 对比元数据如果一样就不进行任何操作。文档 version 不增加
PUT 操作 和post 不带_update 总会将数据重新保存并增加 version 版本;
看场景;
对于大并发更新,不带 update ;
对于大并发查询偶尔更新,带 update ;对比更新,重新计算分配规则。
-
更新同时增加属性
POST customer/external/1/_update
{
"doc": { "name": "Jane Doe", "age": 20 }
}
PUT 和 POST 不带 _update 也可以
5**、删除文档****&**索引
-
删除文档
DELETE customer/external/1
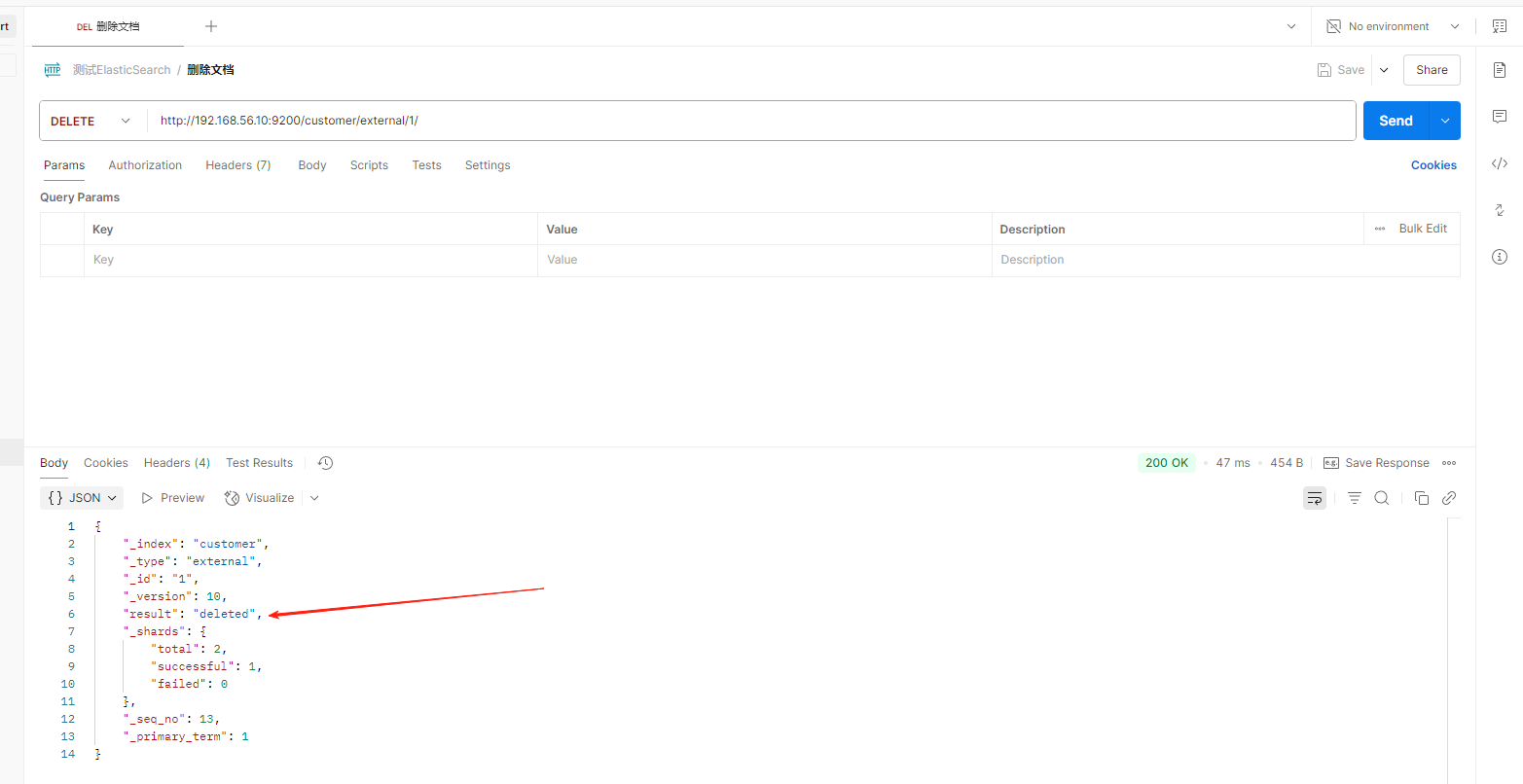
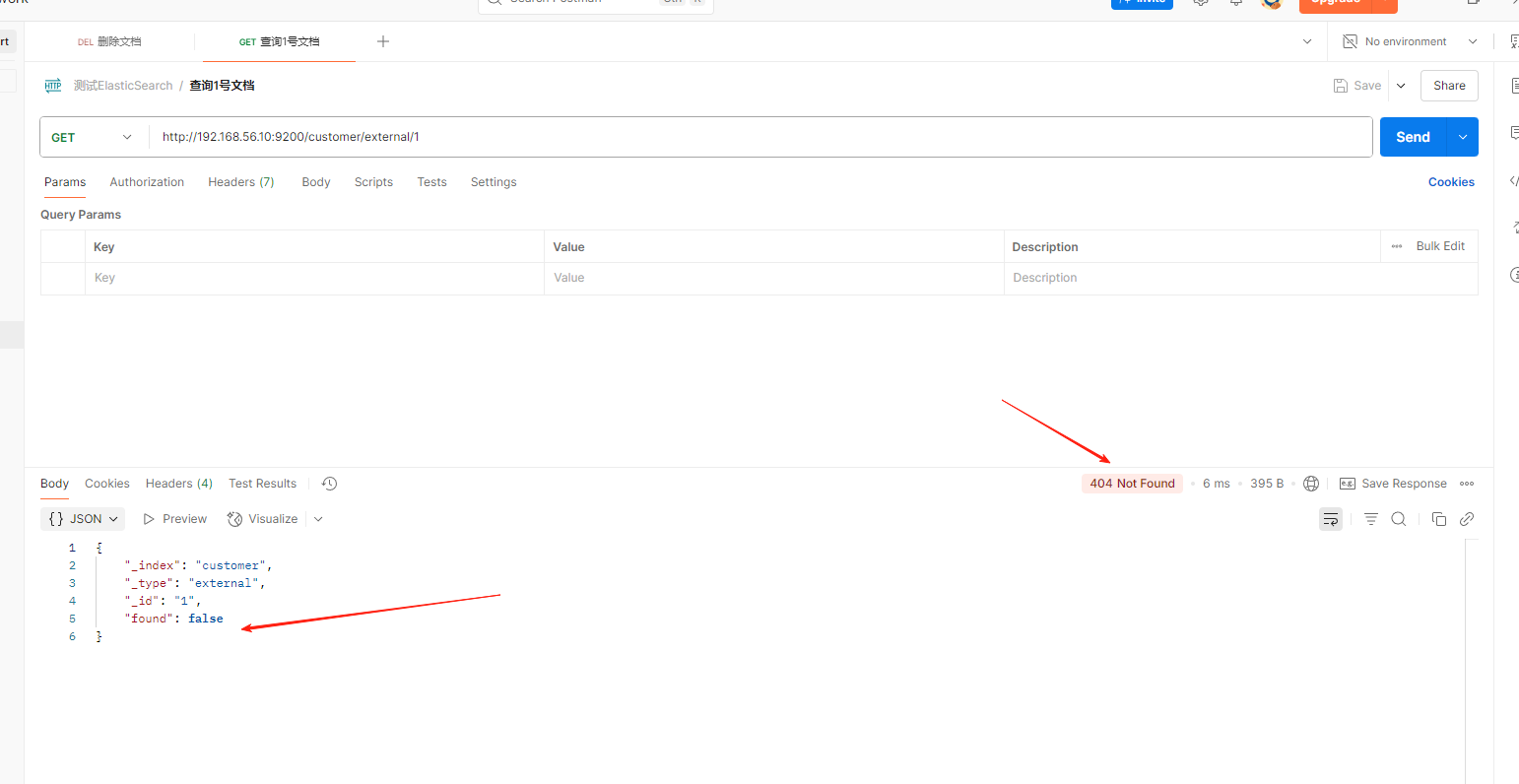
-
删除索引
DELETE customer
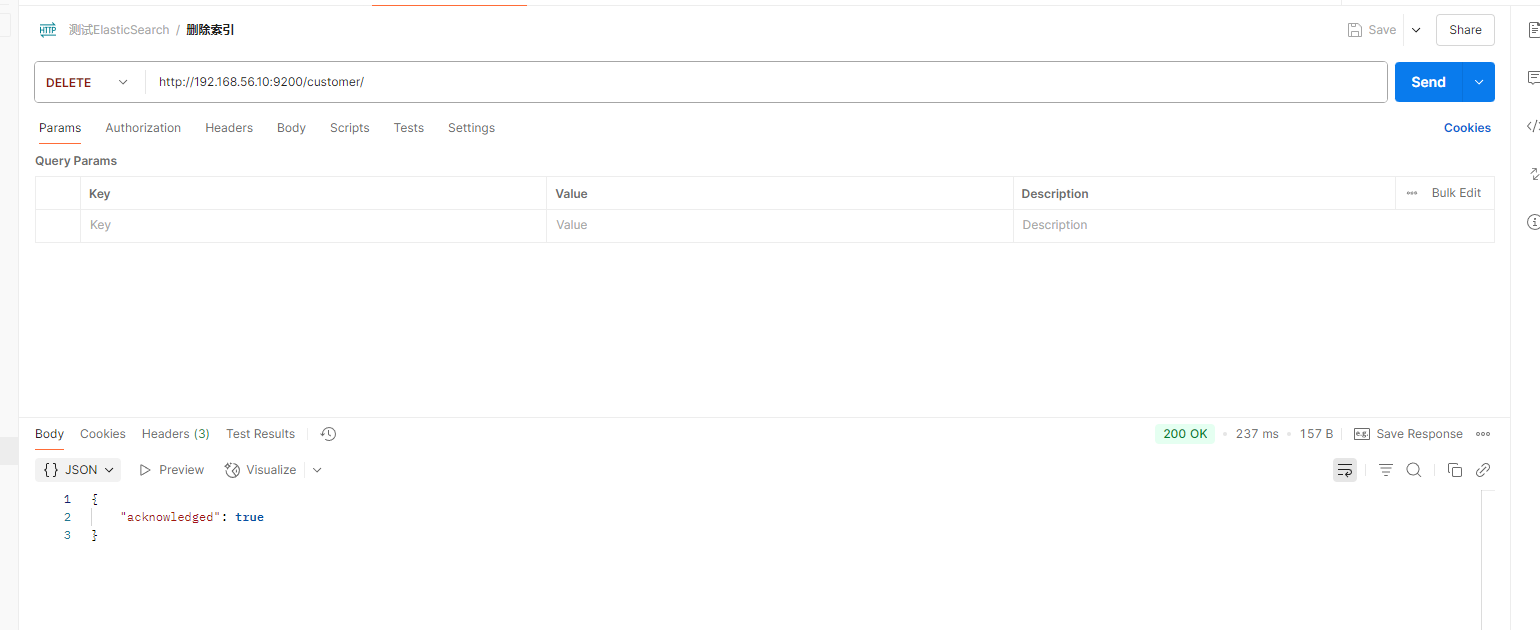
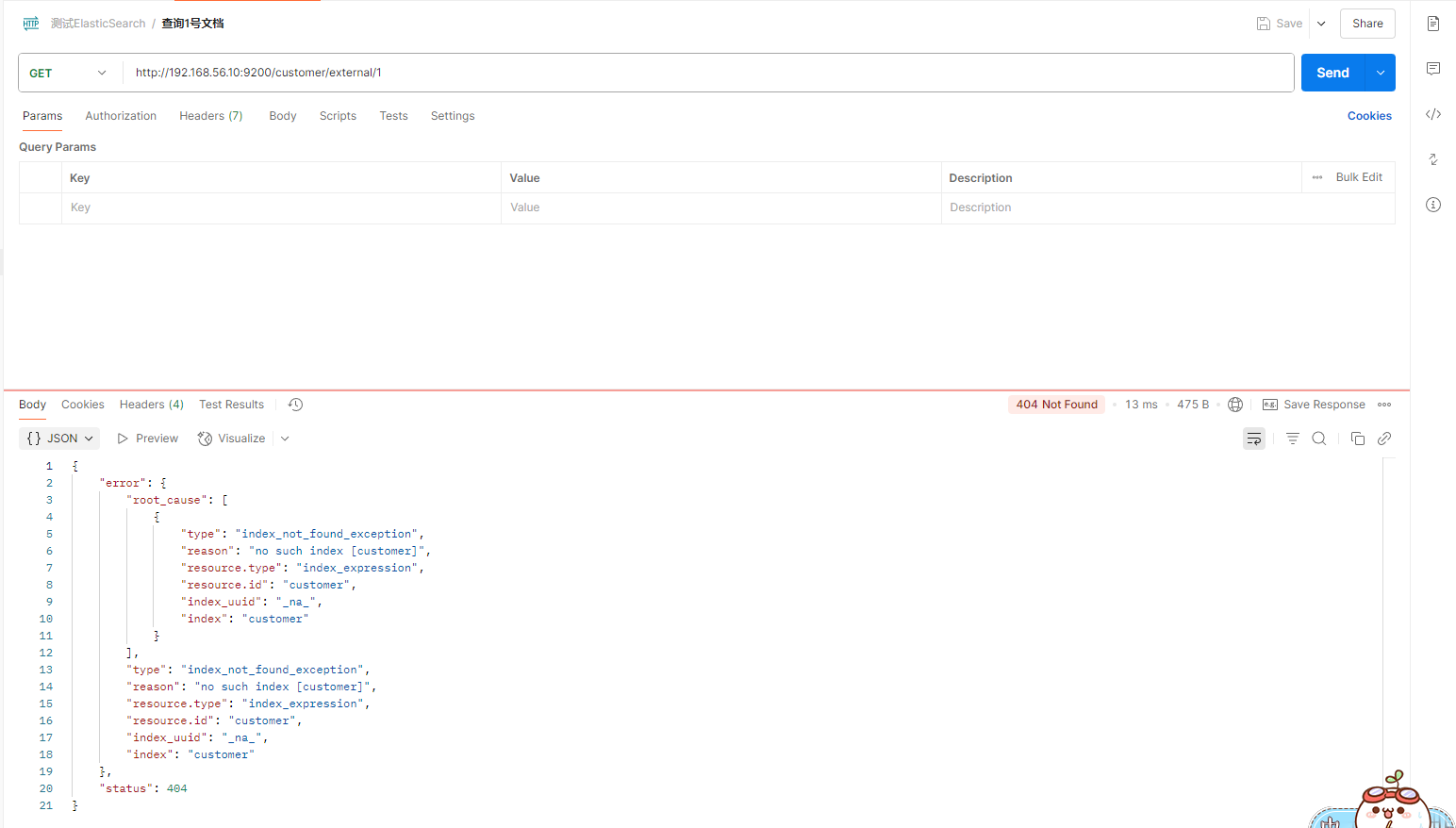
可以删除文档 也可以删除索引,那能删除类型吗?类型不就是mysql中的表吗,drop table ,es中没有直接来删除类型,虽说一个索引下可以有很多的类型,es没有提供类型的删除操作,你只可以删除整个索引,或者把这个类型下的所有数据都删除,也算是删除了这个类型
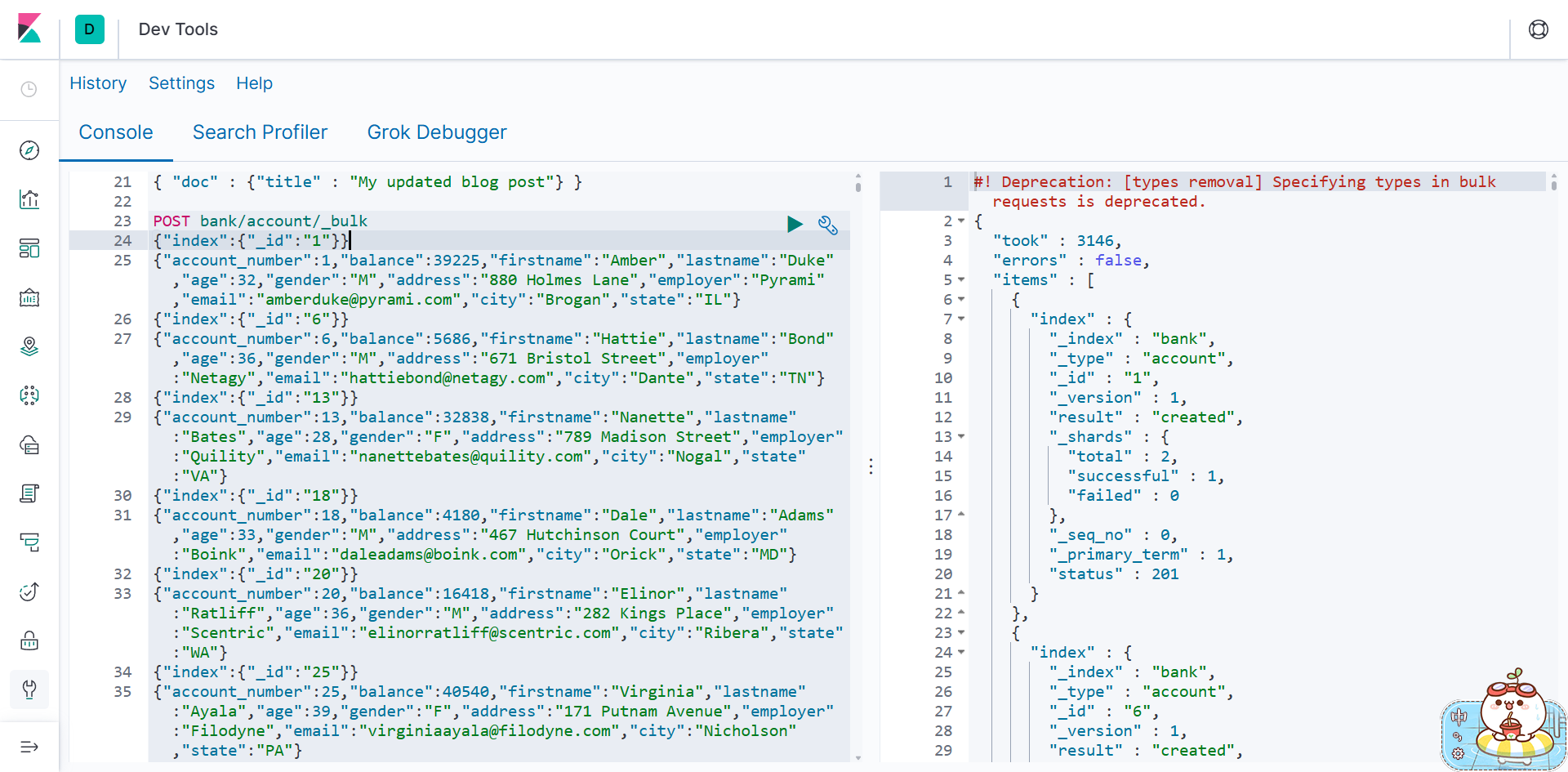
6 、 bulk 批量 API
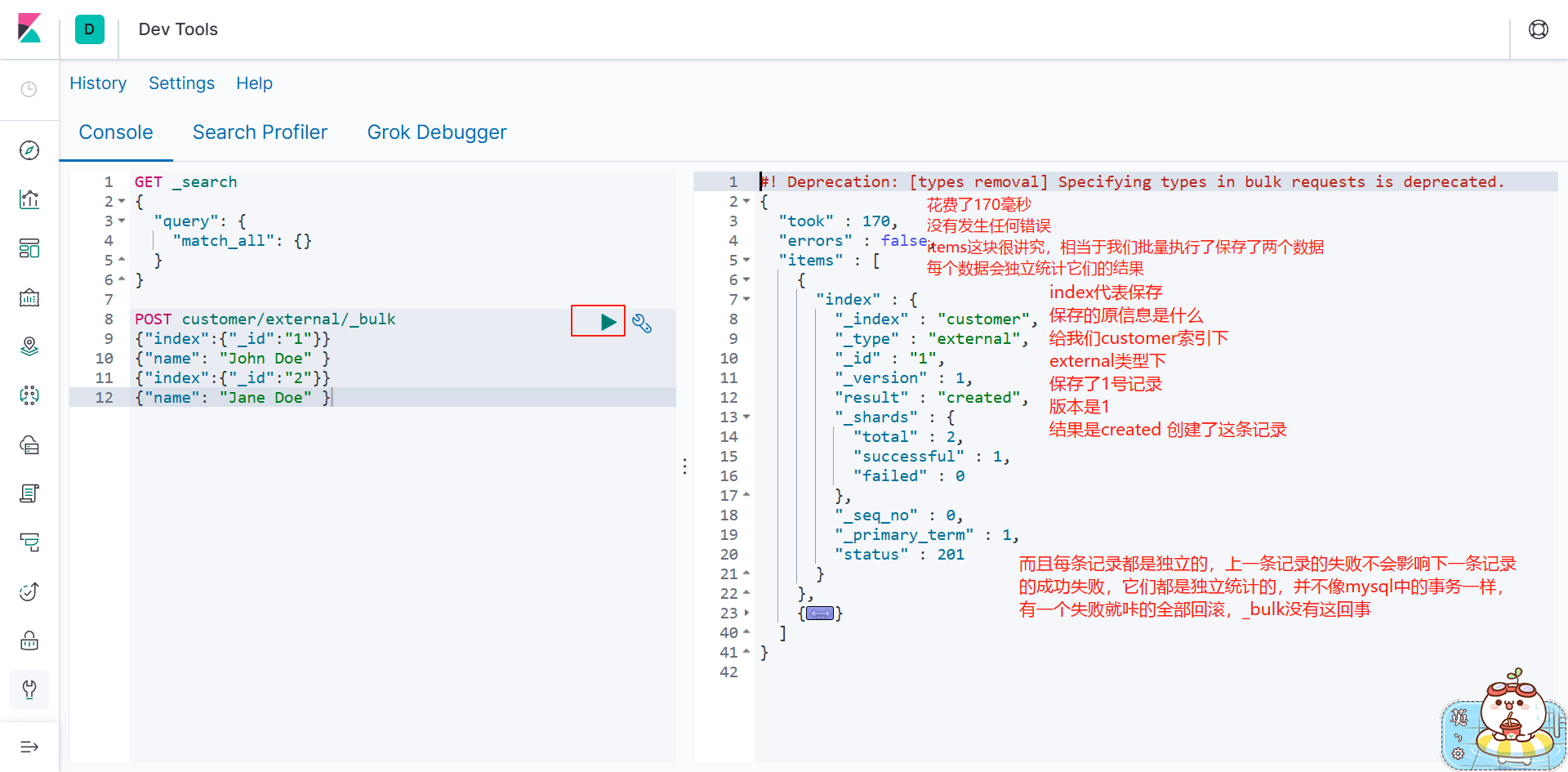
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }还记得开始的时候 我们说过index 作为名词是索引 作为动词就是插入相当于insert
{"index":{"_id":"1"}}
{"name": "John Doe" }
这里第一行相当于就是插入数据 id为1
第二行才是真正的数据
语法格式:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
复杂实例:
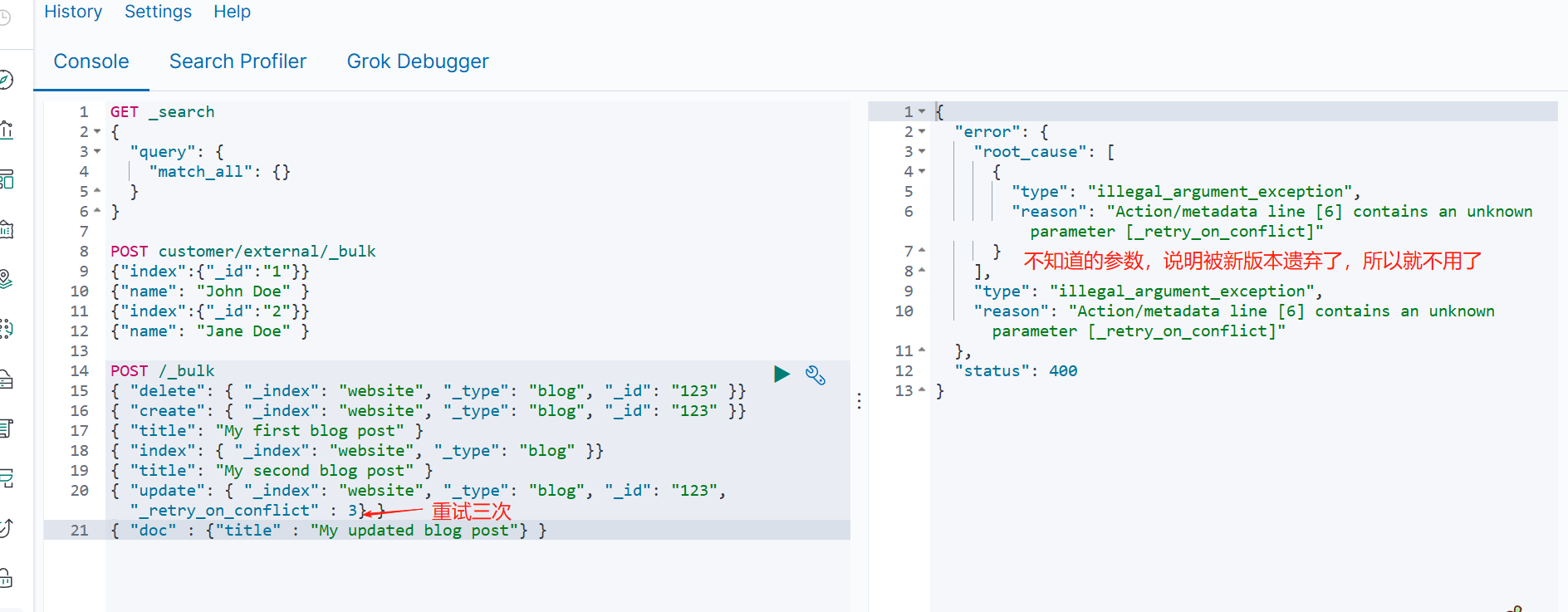
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }提示不接收这样类型的数据
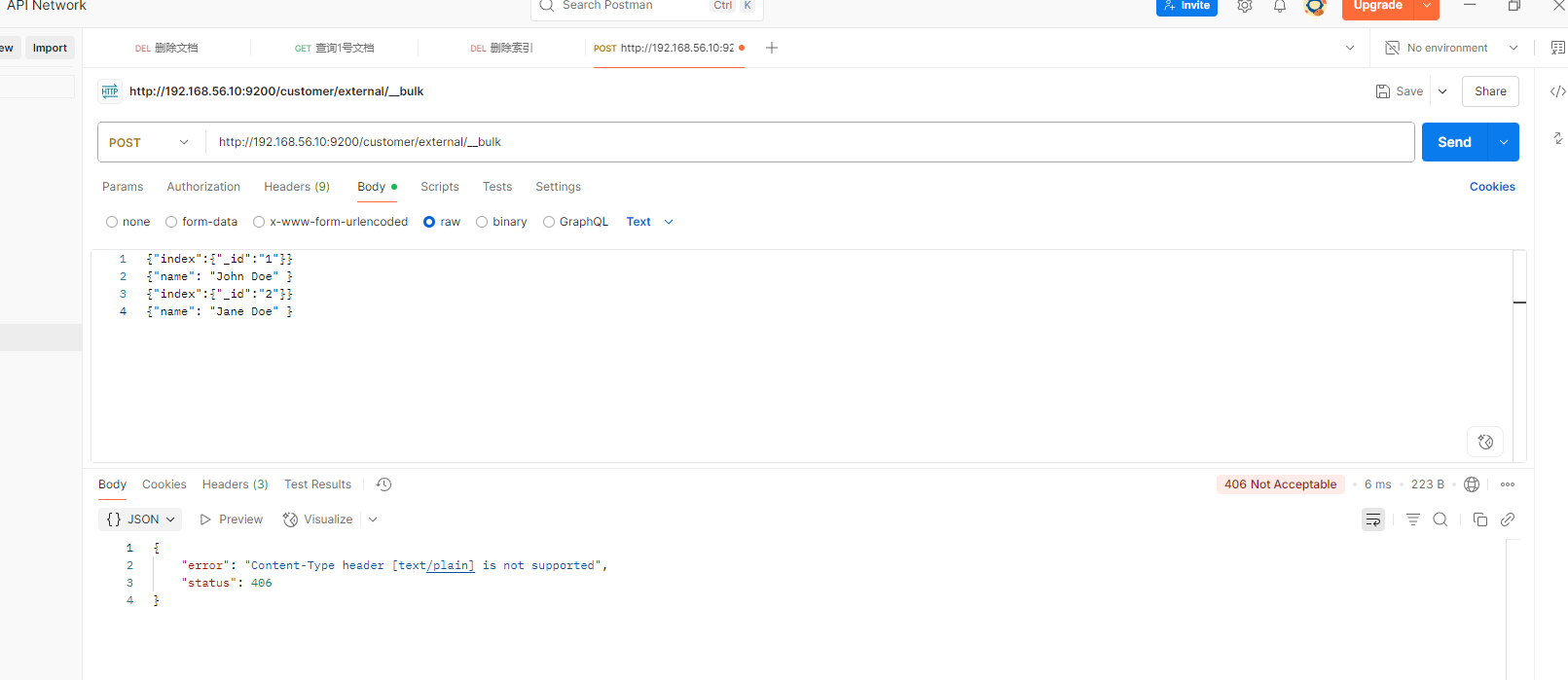
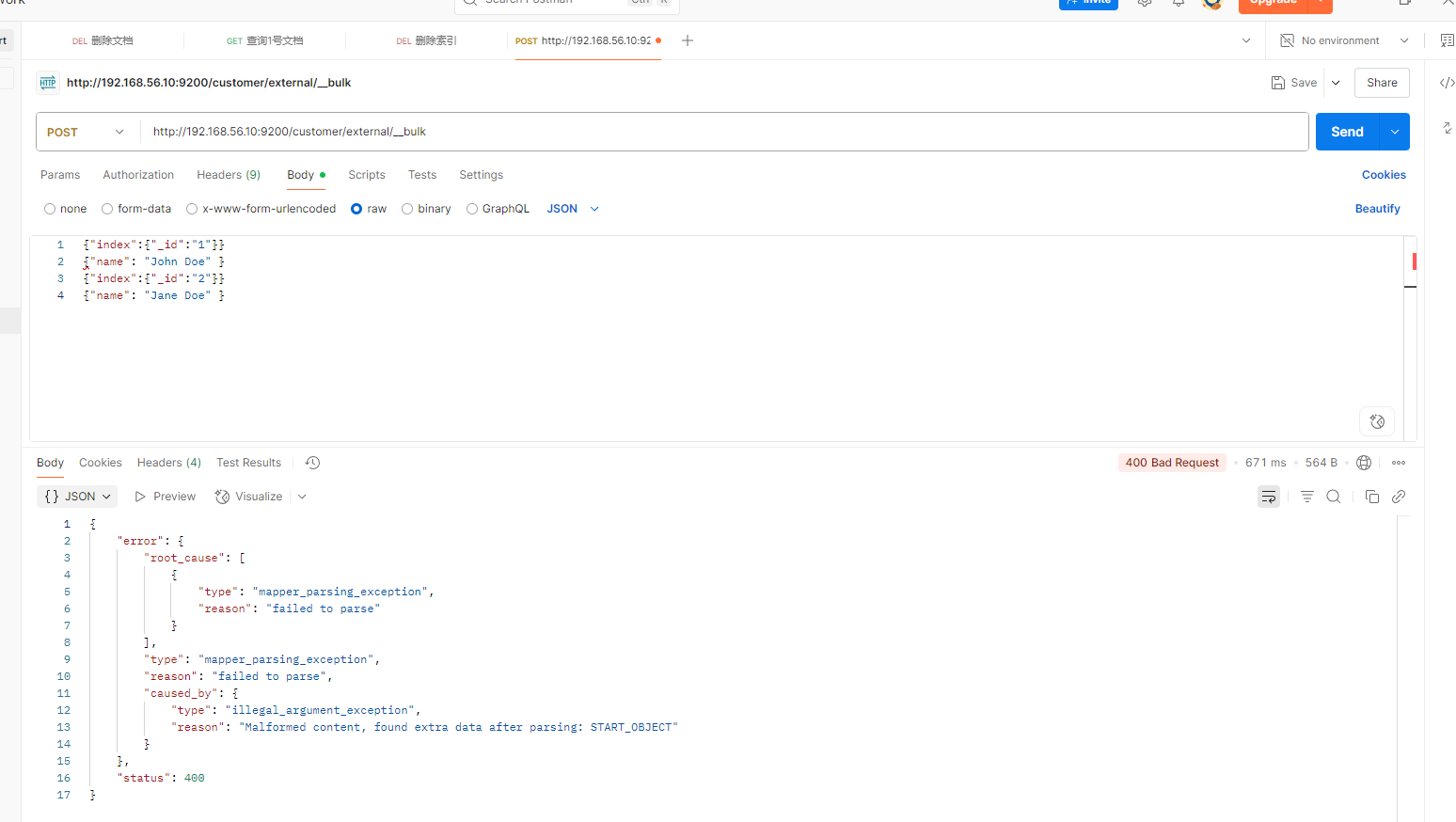
postman没法测,移步kibana
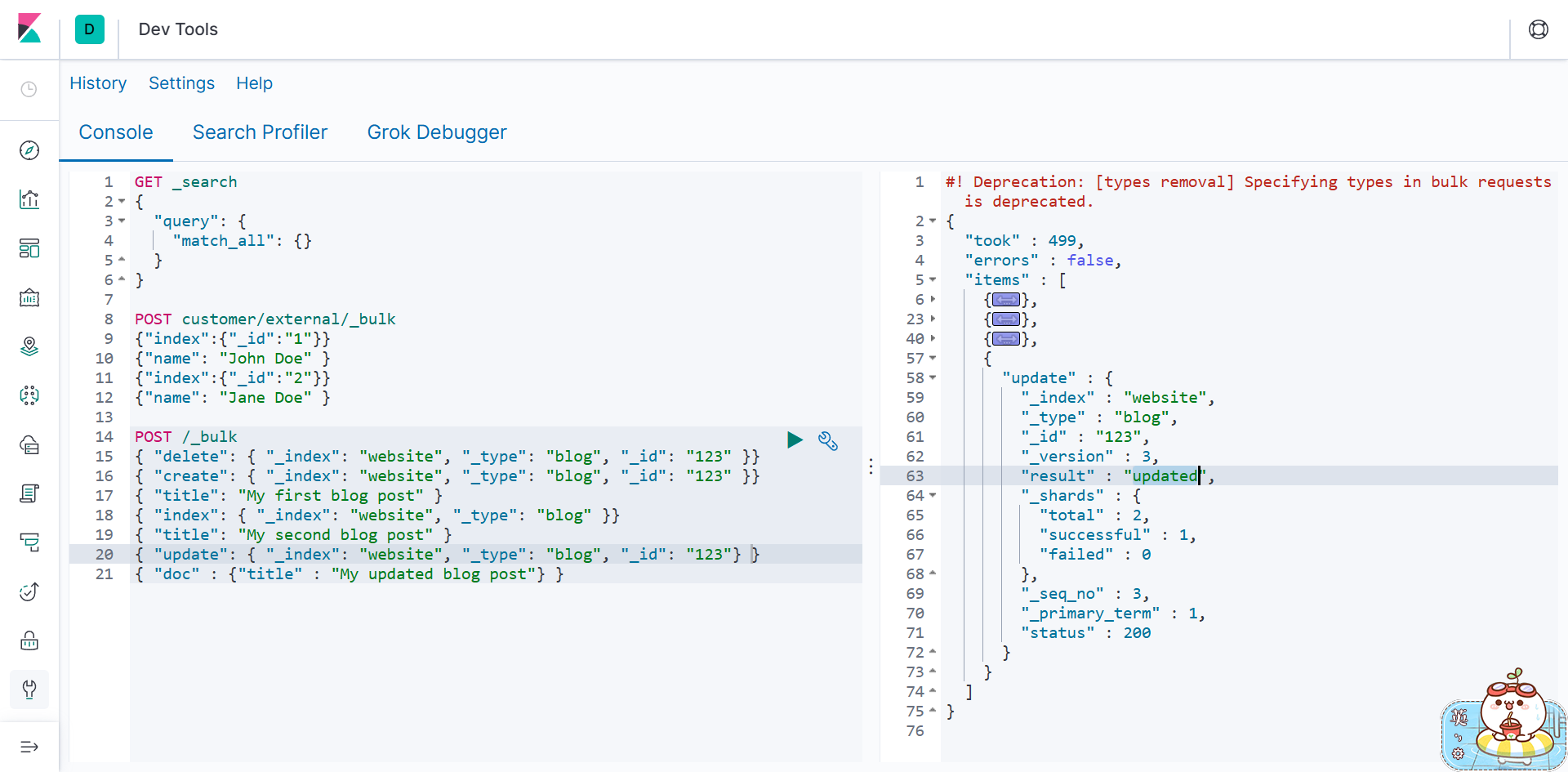
bulk API 以此按顺序执行所有的 action (动作)。如果一个单个的动作因任何原因而失败,
它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送
的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
7**、样本测试数据**
es测试数据.json · 坐看云起时/common_content - Gitee.com
四、进阶检索
参考官方的文档(学的7.4的,所以我看7.4的文档)
Start searching | Elasticsearch Guide 7.4 | Elastic
1 、 SearchAPI
ES 支持两种基本方式检索 :
- 一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
1 )、检索信息
一切检索从_search 开始
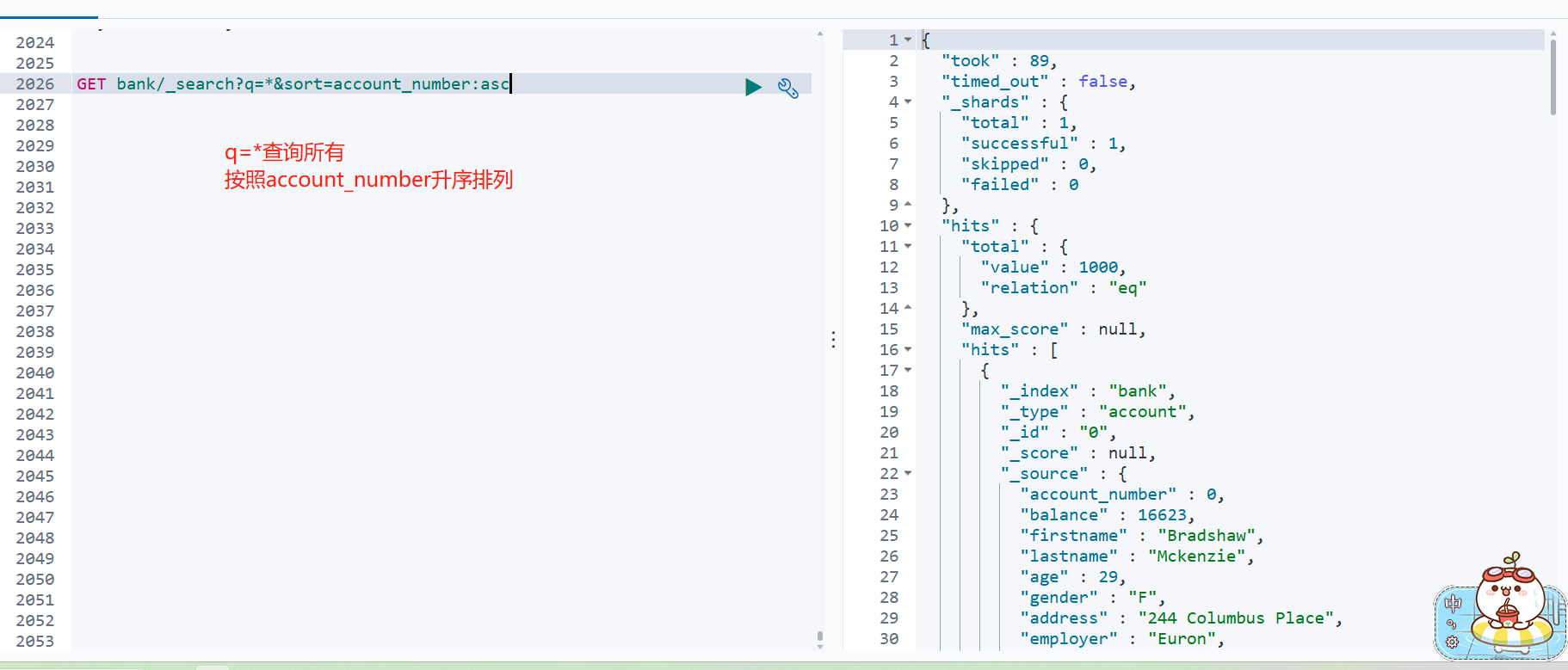
GET bank/_search
检索 bank 下所有信息,包括 type 和 docs
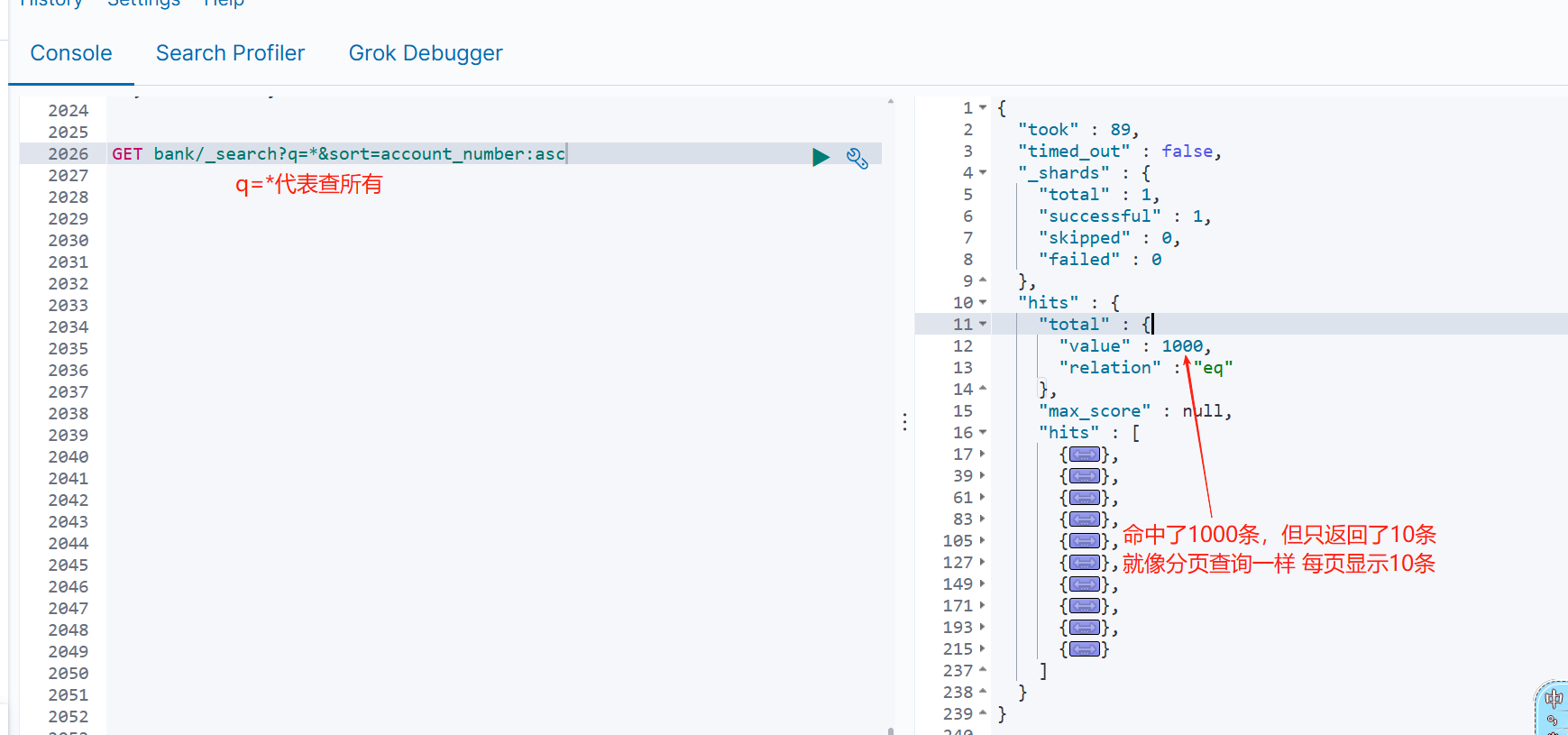
GET bank/_search?q=*&sort=account_number:asc
请求参数方式检索
响应结果解释:
took - Elasticsearch 执行搜索的时间(毫秒)
time_out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功 / 失败的搜索分片
hits - 搜索结果
hits.total - 搜索结果
hits.hits - 实际的搜索结果数组(默认为前 10 的文档)
sort - 结果的排序 key (键)(没有则按 score 排序)
score 和 max_score -- 相关性得分和最高得分(全文检索用)
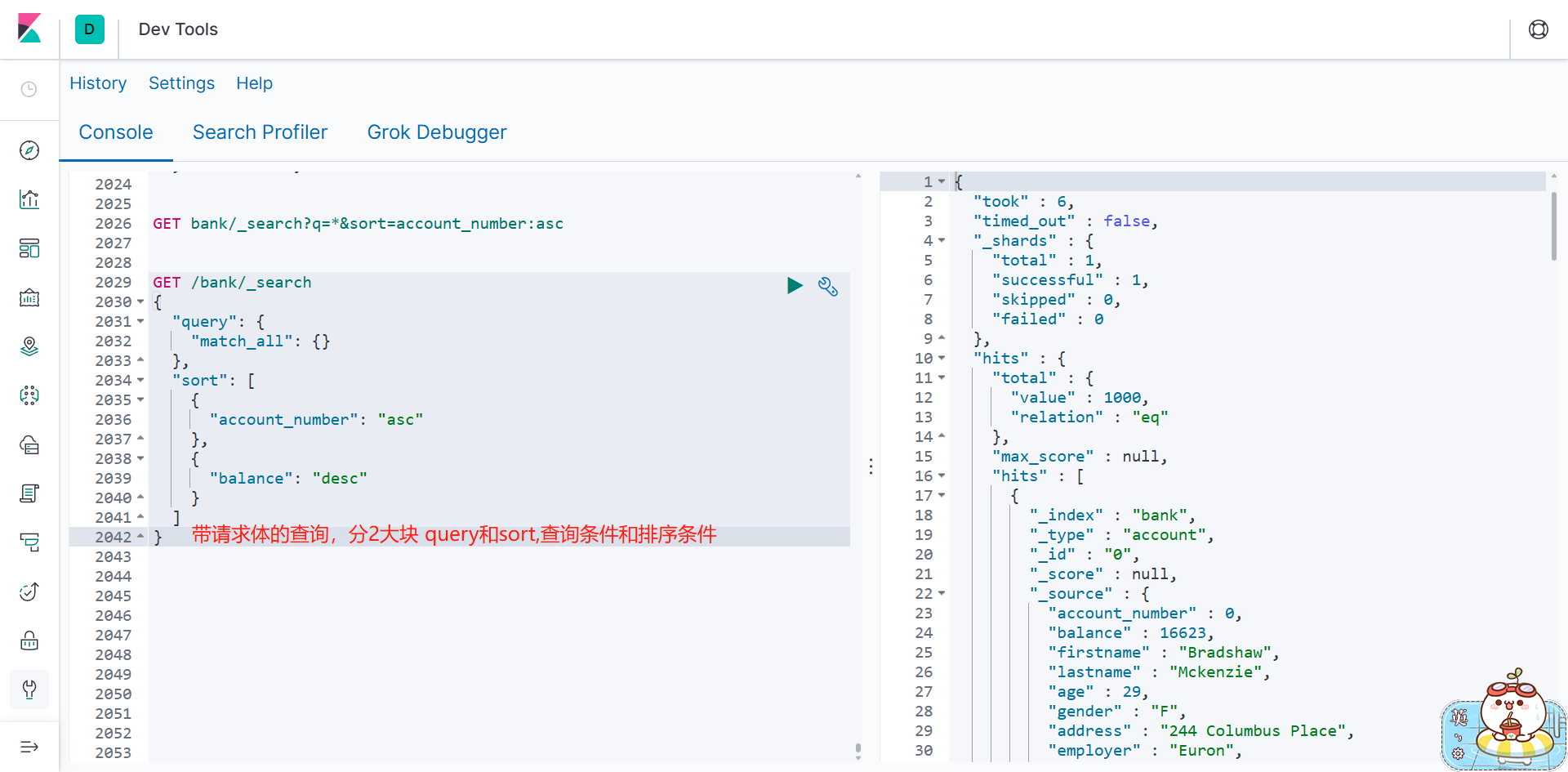
2 、 Query DSL
1 )、基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL ( domain-specific language 领域特
定语言)。这个被称为 Query DSL 。该查询语言非常全面,并且刚开始的时候感觉有点复杂,
真正学好它的方法是从一些基础的示例开始的。
一个查询语句 的典型结构 {
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
如果是针对某个字段,那么它的结构如下:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
所有的语法在kibana都会有提示,建议直接去kibana手敲,或者参考文档
//TODO 没时间整理就先到这里,后面有时间了再来完善