目录
-
- 一、透明大页
-
- [1.1 原理](#1.1 原理)
- [1.2 透明大页的三大优势](#1.2 透明大页的三大优势)
- [1.3 透明大页控制接口详解](#1.3 透明大页控制接口详解)
- [1.4 使用场景与最佳实践](#1.4 使用场景与最佳实践)
- [1.5 问题排查与监控](#1.5 问题排查与监控)
- [1.6 与传统大页的对比](#1.6 与传统大页的对比)
- 二、Linux伙伴系统水位机制详解
-
- [2.1 三种核心水位详解](#2.1 三种核心水位详解)
- [2.2 水位在伙伴系统中的实现](#2.2 水位在伙伴系统中的实现)
- [2.3 水位触发机制的实际行为](#2.3 水位触发机制的实际行为)
- [2.4 水位关键操作接口](#2.4 水位关键操作接口)
- [2.5 水位优化策略](#2.5 水位优化策略)
- [2.6 水位与其他机制的关系](#2.6 水位与其他机制的关系)
- [2.7 kswapd:内存回收守护进程](#2.7 kswapd:内存回收守护进程)
- 三、/proc/sys/vm/extfrag_threshold
-
- [3.1 基本概念](#3.1 基本概念)
- [3.2 作用](#3.2 作用)
- [3.3 配置方法](#3.3 配置方法)
- [3.4 kcompactd:内存碎片规整守护进程](#3.4 kcompactd:内存碎片规整守护进程)
- [3.5 与伙伴系统水位有什么区别](#3.5 与伙伴系统水位有什么区别)
- [四、Linux 内存规整机制](#四、Linux 内存规整机制)
-
- [4.1 内存规整关键特性演进](#4.1 内存规整关键特性演进)
- [4.2 新旧内核性能对比分析](#4.2 新旧内核性能对比分析)
- [4.3 kswapd与kcompactd的协同机制](#4.3 kswapd与kcompactd的协同机制)
- [4.4 诊断命令与参数调整](#4.4 诊断命令与参数调整)
- 五、/proc/sys/vm/min_free_kbytes
-
- [5.1 这个保留的内存能不能被使用?](#5.1 这个保留的内存能不能被使用?)
- [5.2 保留的意义是什么?](#5.2 保留的意义是什么?)
- [5.3 详细解释和工作机制](#5.3 详细解释和工作机制)
- [5.4 假如设置 `echo 16384 > /proc/sys/vm/min_free_kbytes`](#5.4 假如设置
echo 16384 > /proc/sys/vm/min_free_kbytes)
- [六、直接同步回收(Direct Reclaim)深度解析](#六、直接同步回收(Direct Reclaim)深度解析)
-
- [6.1 直接同步回收 vs kswapd/kcompactd](#6.1 直接同步回收 vs kswapd/kcompactd)
- [6.2 直接同步回收的完整执行流程](#6.2 直接同步回收的完整执行流程)
- [6.3 性能影响与优化](#6.3 性能影响与优化)
- [6.4 总结](#6.4 总结)
一、透明大页
bash
# 1. 手动触发内存压缩
echo 1 > /proc/sys/vm/compact_memory
# 2. 检查碎片指数
cat /proc/buddyinfo
cat /proc/pagetypeinfo
# 3. 调整透明大页
echo always > /sys/kernel/mm/transparent_hugepage/enabled1.1 原理
透明大页(Transparent HugePages,简称 THP)是 Linux 内核的一种自动化内存优化技术 ,它通过将多个标准 4KB 页动态合并为更大的 2MB 或 1GB 页,显著提升系统性能。/sys/kernel/mm/transparent_hugepage/enabled 正是控制这一特性的关键接口。
| 特性 | 标准页 (4KB) | 透明大页 (2MB/1GB) |
|---|---|---|
| 页大小 | 4KB | 2MB (512倍) 或 1GB |
| 页表项数量 | 多 (约 50 万/GB) | 少 (512/GB) |
| TLB 覆盖率 | 低 | 高 |
| 内存管理 | 静态分配 | 动态合并 |
请求内存 是 是 否 成功 否 应用程序 内核 启用 THP? 尝试分配 2MB 大页 连续 2MB 可用? 直接分配大页 分配 4KB 小页 后台 khugepaged 合并 替换为大页 始终分配 4KB 小页
在 Linux 系统中,可以通过以下几种方法来确认内核是否开启透明大页(Transparent Huge Pages,THP)功能:
方法一:查看 /sys/kernel/mm/transparent_hugepage/enabled 文件
透明大页的状态信息存储在 /sys/kernel/mm/transparent_hugepage/enabled 文件中,你可以使用 cat 命令查看该文件的内容:
bash
cat /sys/kernel/mm/transparent_hugepage/enabled- 输出示例及含义
- 如果输出为
[always] madvise never,表示透明大页功能已开启,并且始终尝试使用大页。方括号[]括起来的选项表示当前生效的设置。 - 如果输出为
always madvise [never],则表示透明大页功能已关闭。 - 如果输出为
always [madvise] never,表示使用madvise系统调用的方式来决定是否使用大页,即应用程序可以通过madvise系统调用显式地请求或避免使用大页。
- 如果输出为
方法二:使用 grep 结合 /proc/meminfo 文件
你也可以通过在 /proc/meminfo 文件中查找与透明大页相关的信息来间接确认其状态:
bash
grep -i huge /proc/meminfo- 输出示例及含义
- 如果输出中包含类似
AnonHugePages的信息,且其值不为 0,则说明透明大页功能可能是开启的,因为AnonHugePages表示匿名大页的使用情况。例如:
- 如果输出中包含类似
plaintext
AnonHugePages: 204800 kB 不过这种方法只能作为一个参考,因为即使 AnonHugePages 为 0,也不能完全确定透明大页功能是关闭的,还需要结合前面的方法来综合判断。
1.2 透明大页的三大优势
- TLB(转换后援缓冲器)优化
- 问题:TLB 容量有限(通常 64-512 条目)
- 解决:单个 2MB 页表项覆盖 512 倍内存区域
- 效果:TLB 未命中率降低 80-90%
- 页表遍历加速
- 传统页表:4 级页表查找(PGD→PUD→PMD→PTE)
- 大页页表:跳过 PTE 层查找(PGD→PUD→PMD)
- 性能提升:内存访问延迟降低 30-70%
- 内存操作效率
| 操作 | 标准页 (512次) | 大页 (1次) | 提升倍数 |
|---|---|---|---|
| 页分配/释放 | 512 次系统调用 | 1 次 | 512x |
| 缺页中断 | 512 次 | 1 次 | 512x |
| 内存清零 | 512 次 | 1 次 | 512x |
1.3 透明大页控制接口详解
核心控制文件
bash
/sys/kernel/mm/transparent_hugepage/enabled- 可选值 :
always:强制所有内存使用大页madvise:仅对标记区域使用(推荐)never:完全禁用
相关调优参数
| 文件路径 | 功能 | 推荐值 |
|---|---|---|
/defrag |
碎片整理策略 | defer (延迟整理) |
/khugepaged/defrag |
后台整理 | 1 (启用) |
/hpage_pmd_size |
大页尺寸 | 2097152 (2MB) |
1.4 使用场景与最佳实践
推荐启用场景
- 内存密集型应用:MySQL, MongoDB, Redis
- 科学计算:MATLAB, TensorFlow
- 虚拟化平台:KVM, Docker
- 大数据处理:Spark, Hadoop
配置示例
bash
# 启用透明大页(madvise模式)
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
# 优化后台合并进程
echo 1 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
echo 10 > /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan
# 应用程序主动请求大页
#include <sys/mman.h>
posix_memalign(&ptr, 2*1024*1024, size);
madvise(ptr, size, MADV_HUGEPAGE);禁用场景
- 实时系统:避免合并导致的延迟波动
- 内存碎片严重:物理内存不足时
- 特定数据库:如 Oracle 推荐禁用
1.5 问题排查与监控
bash
# 查看大页使用情况
grep AnonHugePages /proc/meminfo
# 监控khugepaged活动
grep -E 'thp|khugepaged' /proc/vmstat
# ubuntu可视化工具
sudo apt install hugeadm
hugeadm --pool-list问题: 内存碎片导致大页分配失败
解决方案:
bash
# 手动触发碎片整理
echo 1 > /proc/sys/vm/compact_memory
# 调整碎片阈值
sysctl vm.extfrag_threshold=500问题: khugepaged 占用高 CPU
解决方案:
bash
# 减少扫描频率
echo 100 > /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs1.6 与传统大页的对比
| 特性 | 透明大页 (THP) | 传统大页 (HugeTLB) |
|---|---|---|
| 配置方式 | 自动/动态 | 静态预分配 |
| 管理复杂度 | 低 (内核自动管理) | 高 (手动配置) |
| 内存利用率 | 高 (按需分配) | 低 (固定预留) |
| 适用场景 | 通用工作负载 | 特定应用 |
| 调整灵活性 | 运行时动态调整 | 需重启生效 |
最佳实践:现代系统优先使用 THP,仅在特殊需求(如 DPDK)时使用传统大页。
透明大页技术通过智能化地平衡内存效率与系统开销,已成为现代 Linux 系统性能优化的关键组件。合理配置后,可使内存密集型应用获得高达 50% 的性能提升,同时保持系统的灵活性和稳定性。
二、Linux伙伴系统水位机制详解
伙伴系统中的水位(Watermarks) 是Linux内核内存管理的关键机制,用于动态监控内存压力 并触发内存回收操作。它定义了系统内存使用的临界阈值,确保内存分配不会耗尽系统资源。
内存充足 内存压力 内存紧张 内存区域 最高水位 high_wmark 低水位 low_wmark 最低水位 min_wmark 正常分配 唤醒kswapd 直接回收
2.1 三种核心水位详解
最高水位 (high_wmark)
-
位置:内存区域的顶部
-
含义:系统内存充足状态
-
触发行为 :
- 允许快速内存分配
- kswapd休眠状态
-
计算公式 :
chigh_wmark = min_free_kbytes * 5 / 4
低水位 (low_wmark)
-
位置:high和min之间
-
含义:中等内存压力
-
触发行为 :
- 唤醒kswapd守护进程
- 开始后台页面回收
-
视觉表现 :
内存使用 [||||||||||__________] low_wmark
最低水位 (min_wmark)
-
位置:内存区域的底部
-
含义:严重内存压力
-
触发行为 :
- 直接同步回收(阻塞分配进程)
- 可能触发OOM Killer
-
计算公式 :
cmin_free_kbytes = sqrt(总内存*16) // 内核自动计算 也可以人为设定数值
2.2 水位在伙伴系统中的实现
数据结构
c
struct zone {
unsigned long watermark[NR_WMARK]; // 三水位值
// [0] = min_wmark
// [1] = low_wmark
// [2] = high_wmark
struct per_cpu_pageset pageset[NR_CPUS];
struct free_area free_area[MAX_ORDER]; // 伙伴系统核心
}内存分配检查流程
c
static struct page *get_page_from_freelist(...) {
for_each_zone(zone) {
// 检查当前区域是否低于水位
if (!zone_watermark_ok(zone, order, mark, ...))
continue;
// 尝试分配页面
page = buffered_rmqueue(zone, order, gfp_mask);
if (page)
return page;
}
return NULL;
}2.3 水位触发机制的实际行为
正常状态(高于high_wmark)
App 伙伴系统 分配请求 立即分配 App 伙伴系统
中等压力(低于low_wmark)
App 伙伴系统 kswapd 页面缓存 分配请求 唤醒后台回收 回收页面 返还页面 延迟分配 App 伙伴系统 kswapd 页面缓存
严重压力(低于min_wmark)
App 伙伴系统 直接回收 分配请求 阻塞进程 同步回收内存 回收完成 分配内存 App 伙伴系统 直接回收
2.4 水位关键操作接口
查看当前水位
bash
# 查看所有内存区域水位
cat /proc/zoneinfo | grep -E 'Node|min|low|high'
# 示例输出
Node 0, zone Normal
pages free 32415
min 14895
low 18618
high 22341调整水位参数
bash
# 临时调整
echo 65536 > /proc/sys/vm/min_free_kbytes监控水位变化
bash
watch -n 1 "grep -E 'min|low|high' /proc/zoneinfo"2.5 水位优化策略
嵌入式设备优化
bash
# 减少保留内存(内存紧张设备)
echo 8192 > /proc/sys/vm/min_free_kbytes
# 更积极回收
echo 150 > /proc/sys/vm/vfs_cache_pressure解决常见问题:频繁触发直接回收导致卡顿
bash
# 查看事件计数
grep "pgsteal" /proc/vmstat
# 优化方案:
1. 增加 min_free_kbytes
2. 优化应用程序内存使用
3. 添加物理内存2.6 水位与其他机制的关系
伙伴系统水位 触发kswapd 触发直接回收 页面缓存回收 SLAB收缩 进程阻塞 OOM Killer 文件系统操作加速 内核对象分配加速
水位机制是Linux内存管理的"预警系统",它:
- 预防内存耗尽:提前触发回收避免OOM
- 平衡性能:后台回收减少阻塞
- 动态适应:根据系统负载自动调整压力响应
理解水位机制对优化系统性能、诊断内存压力问题至关重要,特别是在高负载服务器和资源受限的嵌入式系统中。
2.7 kswapd:内存回收守护进程
核心功能
-
内存水位维护 :当系统空闲内存低于低水位线(
low watermark)时,kswapd被唤醒,异步回收内存,确保空闲内存恢复到高水位线(high watermark)以上。 -
回收对象:主要回收两类内存:
- 文件页(Page Cache):缓存的文件数据,可直接丢弃(除非脏页需写回磁盘)。
- 匿名页(Anonymous Pages):进程堆栈等数据,需交换(swap)到磁盘。
-
触发条件:
- 常规周期唤醒(默认100毫秒)。
- 进程分配内存失败时(如
alloc_pages()慢路径触发wakeup_kswapd())。
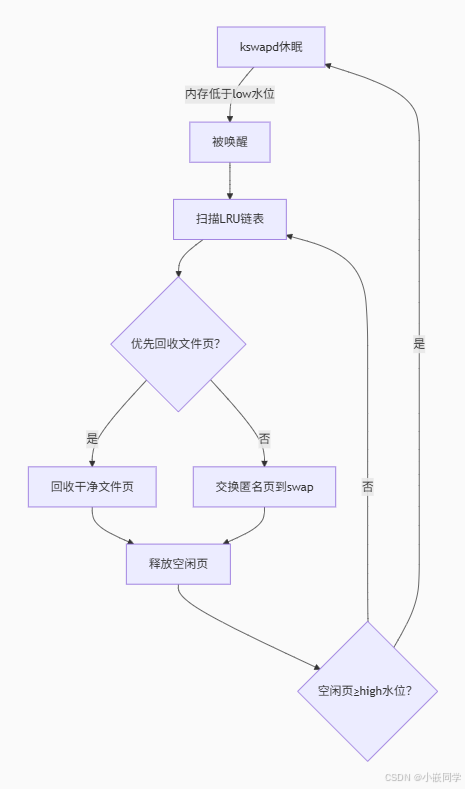
-
异步操作:不阻塞进程,后台运行。
-
优先级策略:按页面活跃度(Active/Inactive LRU)选择回收对象。
-
NUMA优化 :每个NUMA节点独立运行一个
kswapd线程(如kswapd0、kswapd1)。
三、/proc/sys/vm/extfrag_threshold
3.1 基本概念
extfrag_threshold 是Linux 内核中一个与内存碎片管理相关的参数,是一个范围在 0 到 1000 的整数,它主要用于衡量系统对外部内存碎片的容忍程度。外部内存碎片指的是由于频繁的内存分配和释放操作,导致物理内存中出现大量不连续的空闲内存块,使得即使系统中总的空闲内存量充足,但无法分配出连续的大块内存的现象。
3.2 作用
这个参数在内核进行内存分配决策时发挥着重要作用。内核在分配内存时,会根据当前系统的内存碎片情况和 extfrag_threshold 的值来选择合适的分配策略:
- 低阈值(接近 0):表示系统对内存碎片的容忍度较低。当内存碎片程度达到较低水平时,内核就会采取积极的措施来减少碎片,例如进行内存紧凑(memory compaction)操作,将分散的空闲内存块移动到一起,形成连续的大块空闲内存,以满足后续的大内存分配请求。不过,内存紧凑操作会消耗一定的系统资源和时间,可能会对系统性能产生一定影响。
- 高阈值(接近 1000):意味着系统对内存碎片有较高的容忍度。只有当内存碎片程度非常严重时,内核才会尝试进行内存紧凑或其他减少碎片的操作。在这种情况下,系统在一定程度上可以避免频繁进行内存紧凑带来的性能开销,但可能会面临无法分配大块连续内存的风险。
3.3 配置方法
可以通过 /proc/sys/vm/extfrag_threshold 文件来查看和修改 extfrag_threshold 的值。
- 查看当前值 :使用以下命令可以查看当前系统中
extfrag_threshold的设置:
bash
cat /proc/sys/vm/extfrag_threshold- 修改值 :可以使用
echo命令将新的值写入该文件来修改参数设置。例如,将extfrag_threshold设置为 500:
bash
echo 500 > /proc/sys/vm/extfrag_threshold 合理设置 extfrag_threshold 参数对于平衡系统对内存碎片的处理和系统性能非常重要。在实际应用中,需要根据系统的具体负载和内存使用情况进行调整。
3.4 kcompactd:内存碎片规整守护进程
核心功能
- 碎片合并 :将零散小内存块合并为高阶连续块(如将
order=0的4KB页合并为order=2的16KB页),满足大块内存请求(如DMA、透明大页)。 - 迁移策略 :扫描内存区域,将可移动页(
MIGRATE_MOVABLE)从低地址向高地址迁移,形成连续空闲空间。
触发条件
- 被动触发 :高阶内存分配失败时(如
alloc_pages(order>0)失败)。 - 主动触发 :内核≥5.0支持主动规整(Proactive Compaction),预测碎片风险提前规整。
工作流程
c
// 简化版规整逻辑(mm/compaction.c)
compact_zone() {
isolate_migratepages(); // 隔离可移动页
migrate_pages(); // 迁移至空闲区域
release_freepages(); // 释放新连续块
}3.5 与伙伴系统水位有什么区别
- 功能用途不同
extfrag_threshold关注的是内存碎片的程度,目的是在内存碎片达到一定水平时维护内存的连续性,以确保能够分配出连续的大块内存。- 伙伴系统的水位关注的是内存的使用量,目的是在内存分配时发现内存资源紧张回收内存,保证系统有足够的可用内存。
- 数值范围和含义不同
extfrag_threshold是一个 0 到 1000 的整数,数值越大表示系统对内存碎片的容忍度越高。- 伙伴系统的水位是以物理页框的数量来表示的,不同的内存区域(如 DMA 区、普通区等)可能有不同的水位值,这些值反映了该区域内存的使用状态。
- 两者的联系
虽然extfrag_threshold和伙伴系统的水位是不同的概念,但它们都会影响内核的内存管理决策。例如,当系统内存接近或低于伙伴系统的低水位,同时内存碎片程度达到extfrag_threshold设定的阈值时,内核可能会更积极地进行内存紧凑和回收操作,以满足内存分配需求并减少碎片。
四、Linux 内存规整机制
4.1 内存规整关键特性演进
| 特性 | 内核版本支持 | 嵌入式系统配置方式 | 功能描述 |
|---|---|---|---|
| 异步/后台规整 | <4.6:不支持 ≥4.6:支持 | echo 1 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag |
kcompactd 后台线程自动规整 |
| 主动规整(Proactive) | <5.2:不支持 ≥5.2:默认开启 | echo 1 > /sys/kernel/mm/transparent_hugepage/defrag |
预测性内存规整避免碎片 |
| 手动触发 | < 3.10:不支持 ≥3.10:支持 | echo 1 > /proc/sys/vm/compact_memory |
立即触发全系统内存规整 |
| 碎片阈值 | <4.12:不支持 ≥4.12:支持 | echo 500 > /proc/sys/vm/extfrag_threshold |
碎片敏感度调节(0-1000) |
| 规整力度 | <5.15:不支持 ≥5.15:支持 | echo 20 > /proc/sys/vm/compaction_proactiveness |
规整激进程度(0-100) |
bash
# 减少 kcompactd CPU 占用 (嵌入式设备关键)
echo 1000 > /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs
# 限制每次扫描页数
echo 256 > /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan4.2 新旧内核性能对比分析
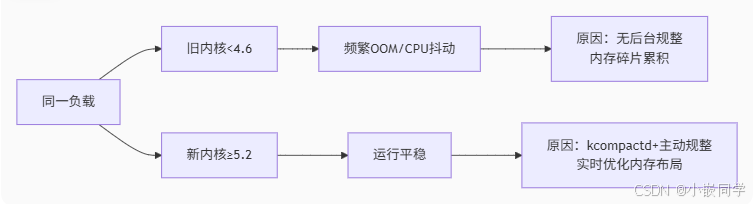
根本原因解析
-
kcompactd 作用(≥4.6):
- 持续后台内存碎片整理
- 预防性合并可移动页
- 保障高阶连续内存可用
-
主动规整优势(≥5.2)
4.3 kswapd与kcompactd的协同机制
协作场景
- 内存分配失败时 :
- 先唤醒
kswapd回收内存 → 若仍失败,触发kcompactd规整碎片。
- 先唤醒
- 后台维护 :
kswapd回收后若碎片指数高(/proc/buddyinfo显示高阶块稀缺),唤醒kcompactd。
性能影响对比
| 指标 | kswapd | kcompactd |
|---|---|---|
| CPU开销 | 中(扫描LRU/写swap) | 高(页面迁移消耗大量CPU) |
| 延迟 | 低(异步) | 可能阻塞进程(同步迁移) |
| 主要目标 | 释放空闲页 | 提升连续内存可用性 |
总结
kswapd:内存"回收者",专注维护水位,异步释放内存。kcompactd:碎片"修复师",合并零散页,保障大块内存分配。- 协作价值 :
二者形成"释放+规整"闭环,从空间 (回收碎片)和时间(异步操作)维度优化内存管理。尤其在≥5.2内核中,主动规整机制显著提升长期运行稳定性,避免旧版本因碎片累积导致的OOM问题。
4.4 诊断命令与参数调整
监控命令
-
碎片指数 :
bashcat /proc/buddyinfo # 各阶空闲块分布(阶数越高越连续) cat /proc/vmstat | grep compact # 规整次数统计 -
回收压力 :
bashcat /proc/zoneinfo | grep -E 'Node|min|low|high' # 水位线 cat /proc/vmstat | grep kswapd # 回收页面计数
调优参数
| 目标 | 操作 | 文件路径 |
|---|---|---|
| 降低kswapd频率 | 延长扫描间隔 | /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs |
| 减少规整开销 | 限制每次扫描页数 | /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan |
| 调整碎片敏感度 | 增大阈值(>500减少规整) | echo 800 > /proc/sys/vm/extfrag_threshold |
| 关闭透明大页 | 避免频繁高阶分配 | 内核启动参数加transparent_hugepage=never |
嵌入式场景特别注意事项
- 资源受限 :
- 减少
kcompactd扫描页数(pages_to_scan),避免CPU过载。
- 减少
- 无swap设备 :
kswapd仅回收文件页,匿名页回收失效,需依赖OOM Killer或LMKD。
- 实时性要求 :
- 禁用主动规整(
compaction_proactiveness=0),减少非确定性延迟。
- 禁用主动规整(
五、/proc/sys/vm/min_free_kbytes
5.1 这个保留的内存能不能被使用?
在系统内存充足时:可以! 当系统的空闲内存 (free) 远大于 min_free_kbytes 时,这部分"保留"的内存区域完全可以被用户进程申请和使用。它并不是被永久锁定或隔离的区域。
在系统内存紧张时:不行! 当系统的空闲内存接近或低于 min_free_kbytes 设定的阈值时,内核会强烈阻止 用户进程再消耗掉这最后一点"保留"内存。内核会采取激进措施(直接回收、OOM Killer)来释放内存,确保空闲内存恢复到 min_free_kbytes 之上。
5.2 保留的意义是什么?
保留这部分内存的核心目的是保障系统在最极端内存压力下的基本功能性和稳定性,避免系统完全崩溃。具体来说:
- 防止死锁和系统僵死: 这是最主要的原因。当所有物理内存都被耗尽时,内核自身执行关键操作(如调度进程、处理中断、执行 I/O、回收内存)都可能需要分配少量内存。如果连这点内存都没有,系统会陷入死锁状态:需要内存来释放内存,但已无内存可用,整个系统完全无响应(僵死)。
min_free_kbytes确保在最坏情况下,内核仍有"救命钱"来执行这些关键操作 - 支持内核关键操作:
- 处理硬件中断: 中断处理程序可能需要分配内存缓冲区。
- 网络和存储 I/O: 网络数据包和磁盘块读写在进入用户空间前需要内核缓冲区。
- 进程创建/销毁: 创建新进程(
fork/exec)需要分配内核数据结构。 - 页面回收:
kswapd或直接回收在执行时需要内存来管理回收过程本身(例如,存放需要写回的脏页链表)。
- 维持
kswapd有效工作:kswapd是内核的后台内存回收守护进程。当空闲内存低于low水位线(与min_free_kbytes相关)时,kswapd会被唤醒并开始后台异步回收 内存。如果允许空闲内存降到极低甚至为零,kswapd可能来不及回收,迫使进程在申请内存时进行代价高昂的直接回收 ,导致严重的延迟(卡顿)。保留内存给kswapd一定的缓冲空间和时间来工作。 - 避免过早触发 OOM Killer: OOM Killer 是内核在内存完全耗尽、回收失败后的最后手段,它会强制杀死进程来释放内存。这个过程非常粗暴,可能导致重要服务中断。保留内存为内存回收提供了缓冲,降低了过早触发 OOM Killer 的概率。
5.3 详细解释和工作机制
-
水位线: 内核基于
min_free_kbytes计算出三个关键的内存水位线:min: 直接对应于min_free_kbytes。这是最后的防线,空闲内存绝对不能低于此值。low: 高于min。当空闲内存低于low时,内核唤醒kswapd开始后台异步回收内存。high: 高于low。当空闲内存回升到high时,kswapd停止回收。
-
内存分配行为:
- 当用户进程通过
malloc等申请内存时,最终会触发内核的页面分配器(如buddy allocator)分配物理页框。 - 分配器会检查当前空闲内存是否充足。
- 如果空闲内存 >
low:分配成功,进程继续运行。 - 如果空闲内存 <
low但 >min:分配器可能 会让进程进入等待状态,同时唤醒或加速kswapd进行回收。回收出足够内存后,进程被唤醒并获得内存。 - 如果空闲内存 <=
min:分配器会进入直接回收 模式。这发生在申请内存的进程上下文中,是同步阻塞 的。该进程会被阻塞,内核在其上下文中立即 尝试回收内存(可能非常慢)。如果直接回收失败且内存仍低于min,内核最终会调用 OOM Killer 选择并杀死一个或多个进程来释放内存。在这个阶段,分配器会拒绝分配任何可能使空闲内存进一步低于min的请求,严格保护这块保留内存。
- 如果空闲内存 >
- 当用户进程通过
5.4 假如设置 echo 16384 > /proc/sys/vm/min_free_kbytes
- 这确实将最低保留内存设置为 16MB (16384 KB)。
- 将默认值(通常为几MB)翻倍意味着:
- 好处: 系统在内存压力下有更大的缓冲空间,
kswapd有更多时间工作,直接回收和 OOM Killer 被触发的可能性降低,系统在高压下可能更稳定。 - 潜在代价: 稍微增加了"浪费"内存的可能性。在内存非常紧张的系统中,16MB 可能意味着一个额外的进程无法运行(因为内核要保护这 16MB)。更关键的是,如果设置过高 (比如在总内存很小的系统上设得太大),可能导致
kswapd过度活跃 ,即使系统负载不高也频繁回收内存,反而增加 CPU 开销和降低性能(回收本身有成本)。它也可能过早触发直接回收 ,因为low水位线也相应提高了。
- 好处: 系统在内存压力下有更大的缓冲空间,
min_free_kbytes 设置的内存是动态保留的底线 。在内存充足时,它可被自由使用;在内存紧张时,它是内核维持自身运转和避免灾难性崩溃的最后保障。你将其设置为 16MB 增加了安全缓冲,但需注意过高设置可能带来性能开销。最佳值取决于你的系统总内存大小和工作负载特性。监控 /proc/vmstat (关注 pgscan_kswapd, pgscan_direct, oom_kill 等) 和 /proc/meminfo 可以帮助评估当前设置是否合理。
六、直接同步回收(Direct Reclaim)深度解析
当系统内存低于最低水位(min_wmark)时触发的直接同步回收是Linux内核最紧急的内存回收机制,其执行过程与kswapd/kcompactd有本质区别。
6.1 直接同步回收 vs kswapd/kcompactd
| 特性 | 直接同步回收 | kswapd | kcompactd |
|---|---|---|---|
| 触发条件 | 内存≤min_wmark | 内存≤low_wmark | 碎片指数超标 |
| 执行者 | 请求内存的进程自身 | 内核后台线程 | 内核后台线程 |
| 执行模式 | 同步阻塞 | 异步 | 异步 |
| 优先级 | 最高(可抢占其他进程) | 普通 | 普通 |
| 延迟影响 | 直接导致进程卡顿 | 无感知 | 可能轻微影响 |
6.2 直接同步回收的完整执行流程
应用程序 内存管理子系统 文件系统 交换分区 内存分配请求 检查空闲内存 < min_wmark? 阻塞进程! 同步回收页面缓存 刷写脏页到磁盘 返回干净页 同步交换匿名页 压缩/写入swap 释放物理页 解除阻塞,分配内存 应用程序 内存管理子系统 文件系统 交换分区
具体步骤解析:
-
进程阻塞
- 当
alloc_pages()检测到zone_watermark_ok() == false - 当前进程进入
TASK_UNINTERRUPTIBLE状态
- 当
-
页面缓存回收
c// 内核源码 mm/vmscan.c unsigned long shrink_page_list(...) { while (!list_empty(page_list)) { if (PageDirty(page)) { // 同步写回磁盘 pageout(page, mapping); } else { // 直接回收干净页 __remove_mapping(...); } } } -
匿名页交换
-
对非活动匿名页执行:
cswap_writepage(page, &wbc); // 同步写swap -
若配置了zswap,优先压缩到内存
-
-
SLAB缓存收缩
cshrink_slab(GFP_KERNEL, ...); // 回收dentries/inodes -
解除阻塞
- 当释放足够页面后,唤醒进程继续分配内存
- 若回收失败,触发OOM Killer
6.3 性能影响与优化
性能瓶颈分析
直接同步回收 磁盘I/O阻塞 高CPU占用 进程延迟 应用卡顿 系统负载飙升 请求超时
优化策略(嵌入式场景)
-
预防性调优
bash# 增加保留内存缓冲 echo 16384 > /proc/sys/vm/min_free_kbytes # 默认值的2倍 # 降低交换倾向 echo 10 > /proc/sys/vm/swappiness -
减少回收压力
c// 代码层面:避免突发内存分配 for (i=0; i<1000; i++) { // 错误:每次分配4KB buffer = malloc(4096); // 正确:批量分配40KB if (i % 10 == 0) big_buf = malloc(40960); } -
监控诊断工具
bash# 追踪直接回收事件 echo 'vfs:shrink_*' > /sys/kernel/debug/tracing/set_event cat /sys/kernel/debug/tracing/trace_pipe # 输出示例 kworker/0:1-125 [000] .... 316.256367: mm_vmscan_direct_reclaim_begin: order=0 kworker/0:1-125 [000] .... 316.259412: mm_vmscan_direct_reclaim_end: nr_reclaimed=32
6.4 总结
虽然直接回收由进程自身执行,但会与kswapd互动:
kswapd正在运行 kswapd未运行 直接回收开始 检查kswapd状态 等待kswapd部分结果 完整执行回收 若回收困难 唤醒kswapd协助
直接同步回收是Linux内存管理的"紧急制动"机制:
- 同步执行:由请求进程直接执行,导致阻塞
- 代价高昂:涉及磁盘I/O和密集计算
- 触发条件:内存≤min_wmark的危急状态
- 优化核心 :
- 增加
min_free_kbytes缓冲 - 避免内存分配尖峰
- 监控
direct reclaim事件
- 增加
在嵌入式系统中,通过合理配置保留内存和优化应用行为,可显著降低直接回收发生概率,保障系统实时性。