java
package com.example.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.BufferedWriter;
import java.io.OutputStreamWriter;
import java.net.InetAddress;
import java.net.URI;
public class HDFSExample {
public static void main(String[] args) {
//这一步主要是看下你本地是不是能把服务器的hostname解析成你服务器的远程访问的IP地址
try {
InetAddress address = InetAddress.getByName("你服务器的hostname");
System.out.println("你服务器的hostname resolves to: " + address.getHostAddress());
} catch (Exception e) {
e.printStackTrace();
}
//把这种地址路径以及用户名称,都换成你自己的
String hdfsUri = "hdfs://你服务器的hostname或者是远程访问ip地址:9000";
String destPathStr = "/user/hadoop/testfile02.txt";
String content = "这是我想写入HDFS的字符串内容!sssss";
String user = "hadoop";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfsUri);
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("hadoop.job.ugi", user);
// 如果你的Hadoop配置了安全机制(kerberos),这里需要配置认证,这里不是必须
System.setProperty("HADOOP_USER_NAME", user);
FileSystem fs = null;
BufferedWriter br = null;
try {
// 以 hadoop 用户身份登录
UserGroupInformation ugi = UserGroupInformation.createRemoteUser(user);
fs = ugi.doAs((java.security.PrivilegedExceptionAction<FileSystem>) () ->
FileSystem.get(new URI(hdfsUri), conf)
);
Path destPath = new Path(destPathStr);
// 删除旧文件
if (fs.exists(destPath)) {
fs.delete(destPath, false);
System.out.println("已删除旧文件:" + destPathStr);
}
// 写入内容
br = new BufferedWriter(new OutputStreamWriter(fs.create(destPath, true), "UTF-8"));
br.write(content);
System.out.println("✅ 写入成功:" + content);
} catch (Exception e) {
System.err.println("❌ 写入失败,错误信息如下:");
e.printStackTrace();
} finally {
try {
if (br != null) br.close();
if (fs != null) fs.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}
xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Hadoop01</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop.version>3.3.6</hadoop.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- 推荐直接使用 hadoop-client 打包所有 HDFS 所需模块 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Protobuf(有些 Hadoop 模块需要) -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>2.5.0</version>
</dependency>
<!-- 日志支持,防止 slf4j 多重绑定 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-reload4j</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>
<build>
<!-- 我这里用打包插件,是为了打包好程序上传到服务器测试,看是我代码的问题,还是远程访问的问题 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.hadoop.HDFSExample</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>运行结果,写入成功也没有报错

上服务器上查看写入成功

聊一聊写入过程中遇到的坑
坑1: java.lang.IllegalArgumentException: java.net.UnknownHostException: VM-20-14-centos

你代码中使用了服务器的hostname,但是你远程java运行的这个电脑根本不会识别到它对应的远程访问的ip地址。
解决方式1
把代码中的hostname 使用你自己服务器远程访问 ip
解决方式2,推荐用这种方式可以避免掉很多坑
配置你本机的hosts文件
路径:C:\Windows\System32\drivers\etc
上面这个路径下有个hosts文件,使用管理员方式进行编辑添加,里面应该有对应格式参照。
列:
xml
你服务器的ip 你服务器的hostname报错2
类似于这种无法写入的问题,都可以通过下面的方式进行排查
bash
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hadoop/testfile02.txt could only be written to 0 of the 1 minReplication nodes. There are 1 datanode(s) running and 1 node(s)这个报错的意思是:
你尝试写入的文件只能写入到 0 个副本节点上,期望最少写入到 1 个副本节点(minReplication = 1),但没成功。后面还有提示
当前 只启动了 1 个 DataNode
但即使如此,这个 DataNode 也无法成功接收数据。
大白话就是,现在因为是伪分布式,当前只有一个DataNode是启动的,但是这个DataNode 不能接收数据
开始排查问题
2.1首先查看你的hadoop是不是正常启动的,使用jps命令
如下图就是正常的
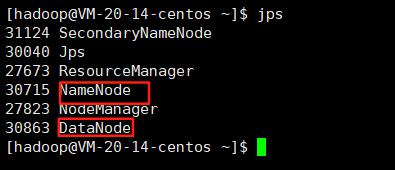
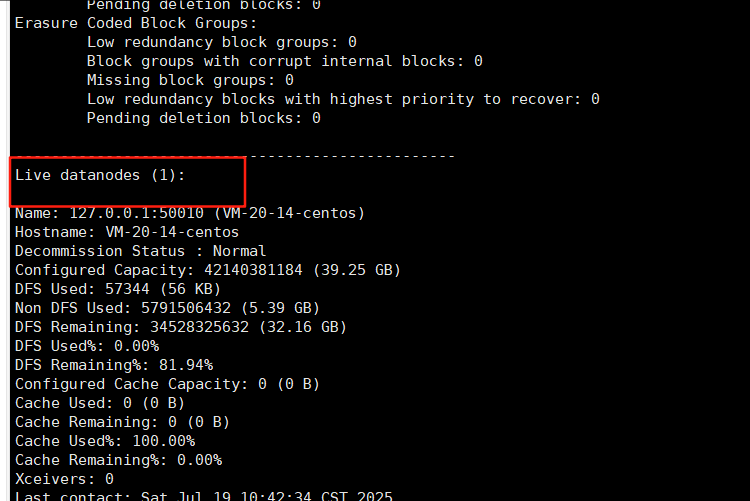
再使用hdfs dfsadmin -report命令进行查看
主要是看下面的datanods节点不能为零至少是1
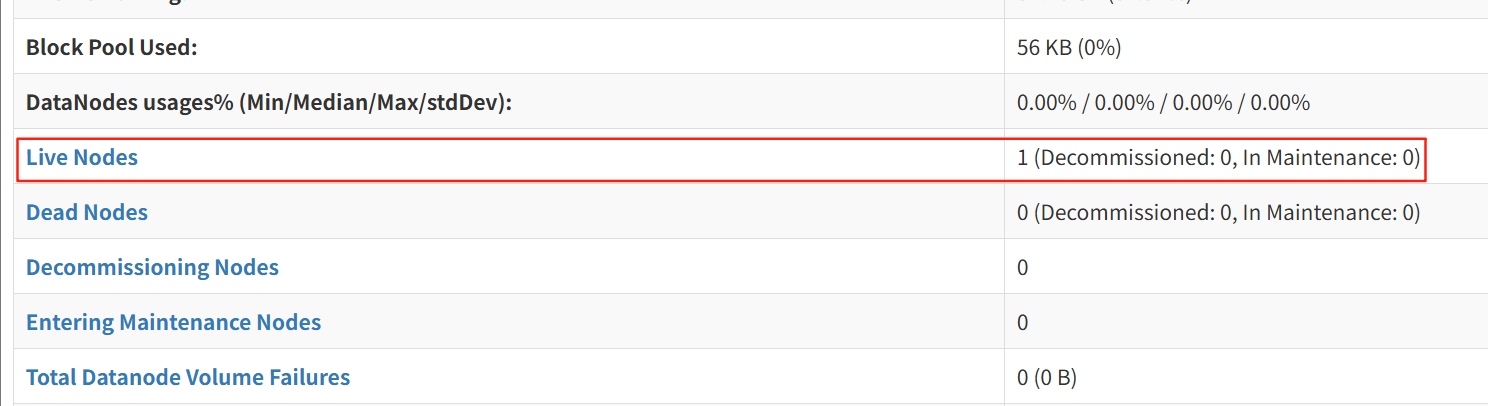
或者是到网页上查看,在你的远程ip9870端口查看
2.2在服务上通过命令来进行测试看能否写入
命令解释
1.先删除掉原本有的这个文件,如果你没有,就不需要这一步,因为命令不会重复写入或者是覆盖掉同一个文件
bash
hdfs dfs -rm -f /user/hadoop/testfile02.txt2.将hello hadoop输出到testfile02.txt文件里面
bash
echo "hello hadoop" | hdfs dfs -put - /user/hadoop/testfile02.txt3.查看testfile02.txt文件里面内容
bash
hdfs dfs -cat /user/hadoop/testfile02.txt4.如下图,如果没有问题证明是服务器上的hadoop是好的,可能是远程和服务器通信的问题

2.3查看是不是你代码中的其他问题导致
将你的代码打包上传到服务器进行运行
如下图如果执行成功,也可以证明是远程通信的问题
bash
java -jar /usr/scripts/Hadoop01-1.0-SNAPSHOT-shaded.jar
2.4 查看下是不是防火墙的问题,你把防火墙关掉,再远程执行java代码,如果成功,可能是防火墙的问题,你需要
执行netstat -plant | grep java这个命令看下,java监听的到底是哪些端口,然后去放行
这里是你可能用到的像关于防火墙的命令
bash
开启防火墙:
sudo systemctl start firewalld
关闭防火墙
sudo systemctl stop firewalld
防火墙有哪些端口开放
sudo firewall-cmd --list-ports
开放防火墙端口
sudo firewall-cmd --zone=public --add-port=8080/tcp --permanent
移出某一个开放的端口的命令
sudo firewall-cmd --zone=public --remove-port=8080/tcp --permanent
放行一个范围的端口
sudo firewall-cmd --zone=public --add-port=5000-10000/tcp --permanent
sudo firewall-cmd --reload
查看防火墙状态的命令
sudo firewall-cmd --state下面是我的防火墙开放的端口
bash
hadoop需要开放的端口
sudo firewall-cmd --zone=public --add-port=9000/tcp --permanent
sudo firewall-cmd --zone=public --add-port=50010/tcp --permanent
sudo firewall-cmd --zone=public --add-port=50020/tcp --permanent
sudo firewall-cmd --zone=public --add-port=9864/tcp --permanent
sudo firewall-cmd --zone=public --add-port=9870/tcp --permanent2.5可能是安全组的问题影响通信
你可以把这里改成让所有的端口进行放行,然后测试,看程序是否能执行成功,如果成功的话,你在通过2.4去确定到底是需要放行哪些端口

2.6无法写入,也可能是你的hadoop刚刚重新启动,进入到了安全模式
你可以等,过段时间会自动关闭安全模式,如果数据量大,等的时间就长,如果是测试服务器,你可以手动关闭
bash
查看hadoop是否是在安全模式
hdfs dfsadmin -safemode get
强制关闭hadoop安全模式不推荐
hdfs dfsadmin -safemode leave2.7可能是你服务器的hostname,和你服务器远程ip访问之间不能相互识别的问题,也会导致无法写入
bash
查看里面的内容
less /etc/hosts
添加内容
sudo vim /etc/hosts
加上
远程访问ip 你服务器hostname
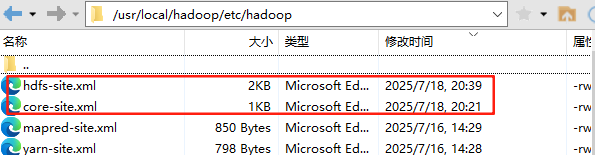
(格式类似于windows上你配置hosts的格式)2.8 可能是配置文件的问题,但是,如果说前面的,你服务器上启动,写入没有问题的,那么应该不是,配置文件的问题,如果前面在服务器上启动写入就有问题,那么可能是配置文件的问题,下面我圈的这两个配置文件的问题(最可能是你副本配置的是多个的问题)
2.9磁盘满了,无法写入,这种情况应该是少见的,除非你是上线很久的项目吧
接下来简单的分析下原理,帮助更容易的找到问题
核心配置文件
| 配置文件名 | 作用 |
|---|---|
core-site.xml |
设置 Hadoop 的通用配置,如 NameNode 的地址(fs.defaultFS)等。 |
hdfs-site.xml |
设置 HDFS 专用配置,如 NameNode/SecondaryNameNode/DataNode 的端口、数据块大小、副本数等。 |
🧠 二、三大组件关系
NameNode:HDFS 的管理者,负责记录文件与数据块的映射关系。
DataNode:实际存储数据块的节点。
客户端(Client):通常是使用 Java API(如 FileSystem)的程序,想要读写 HDFS 文件。
三、Java 客户端写入 HDFS 的流程(带 IP 通信过程)
以下是一个典型的 客户端写入文件到 HDFS 的完整过程,并标出它们之间的交互流程:
| 步骤 | 发起方 | 接收方 | 通信内容 |
|---|---|---|---|
| 1 | 客户端 | 本地 | 读取 XML 配置文件,获取 fs.defaultFS(如 hdfs://namenode:9000) |
| 2 | 客户端 | NameNode(通过 IP:Port) | 请求创建文件,NameNode 分配 block,返回用于写入的 DataNode 列表 |
| 3 | 客户端 | 第一个 DataNode | 建立 Socket 连接 |
| 4 | 客户端 → DN1 → DN2 → DN3 | 数据管道 pipeline(TCP)传输数据块 | |
| 5 | 最后一个 DataNode | NameNode | 确认 block 写入成功 |
| 6 | 客户端 | 本地 | 关闭输出流、写入成功 |
单项写如逻辑
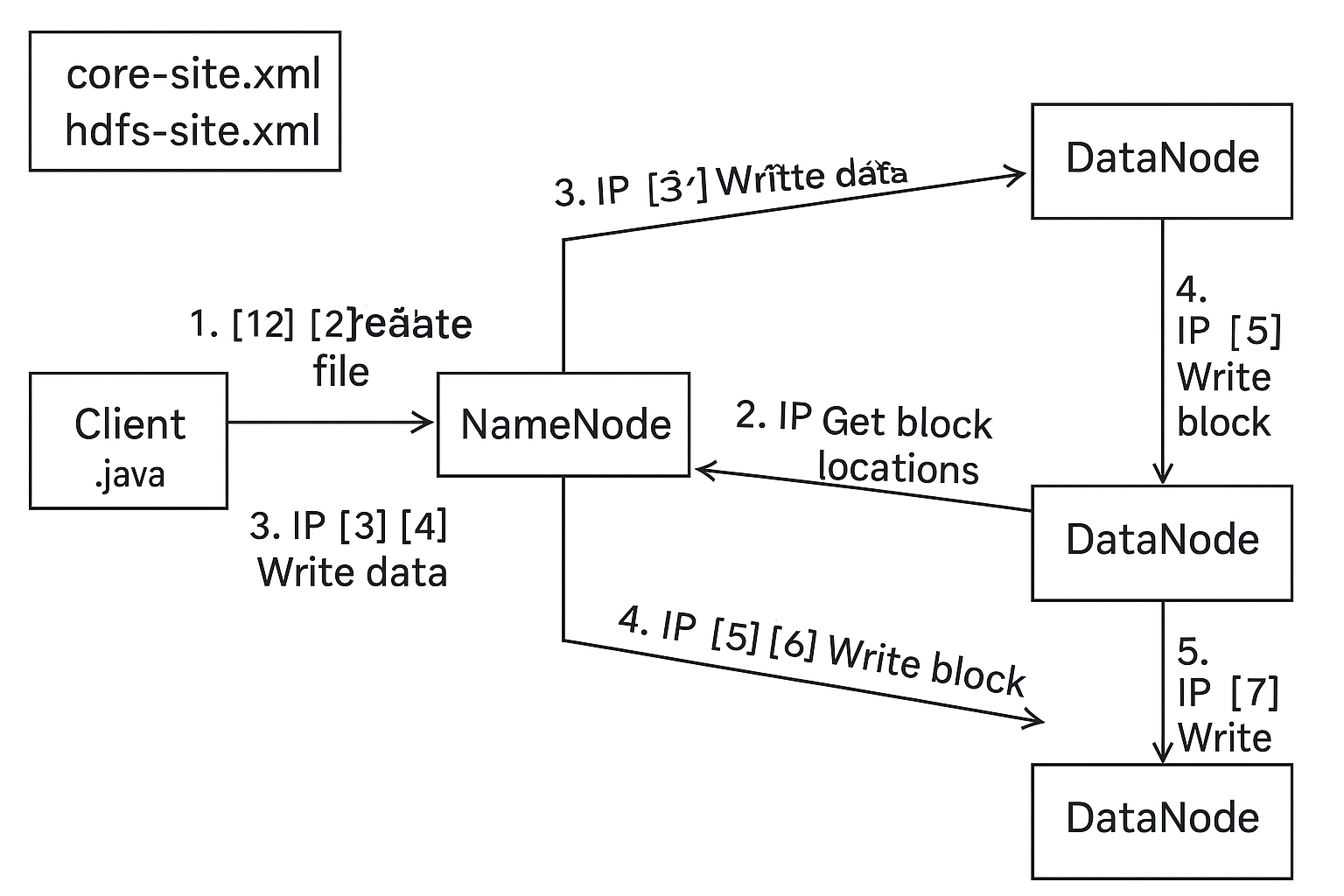
✅ 一、DataNode → NameNode(主动上报)
启动后注册(block report):告诉 NameNode 自己有哪些块(block)。
定期心跳:DataNode 每 3 秒向 NameNode 发心跳。
报告 block 接收情况:写入数据后通知 NameNode block 写成功。
✅ 二、NameNode → DataNode(指令下发)
下发指令:如复制块、删除块等。
返回客户端请求的块位置:返回可用的 DataNode 列表。