一.时间复杂度
时间复杂度是衡量算法执行效率的重要指标,它表示算法的运行时间与输入规模之间的增长关系,通常用大 O 符号(O ())表示。
常数阶 O (1) 访问数组中的某个元素(通过索引直接获取)、简单的加减运算
对数阶 O (log n) 每增加一倍输入,操作次数只增加 1 次。(二分查找)
线性阶 O (n) 遍历数组查找元素(一次for循环)
线性对数阶 O (n log n) 高效排序算法(归并排序、快速排序、堆排序等),其核心是 "分治" 思想,每层处理n个元素,共log n层
平方阶 O (n²) 双层嵌套循环(如冒泡排序、选择排序)
指数阶 O (2ⁿ) 斐波那契数列(递归)
二.常用排序算法
图示 https://zhuanlan.zhihu.com/p/40695917
| 算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 小规模数据,教学演示 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 小规模数据,交换次数少 |
| 插入排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 小规模或基本有序的数据 |
| 希尔排序 | O(n^1.3~n²) | O(n²) | O(n) | O(1) | 不稳定 | 中等规模数据 |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 | 大规模数据,要求稳定性 |
| 快速排序 | O(n log n) | O(n²) | O(n log n) | O(log n) | 不稳定 | 大规模数据,平均性能最优 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 | 大规模数据,空间敏感 |
| 计数排序 | O(n + k) | O(n + k) | O(n + k) | O(k) | 稳定 | 数据范围小且密集 |
| 桶排序 | O(n + k) | O(n²) | O(n) | O(n + k) | 稳定 | 数据分布均匀 |
| 基数排序 | O(d(n + k)) | O(d(n + k)) | O(d(n + k)) | O(n + k) | 稳定 |
初级
冒泡排序 :基于比较,每次比较都交换
选择排序 :基于比较,提高了冒泡排序的性能,它每遍历一次列表只交换一次数据(min/max保存),即进行一次遍历时找 到最大的项,完成遍历后,再把它换到正确的位置
插入排序 :先把前两个排好,第三个插入到前两个合适的位置,依此类推
希尔排序:是插入排序的改进版,划分成多个子列表进行插入排序
高级
归并排序 :持续地将一个列表分成两半,最后归并。归并是这样一个过程:把两个排序好了的列表结合在一起组合成一个单一的有序的新列表。元素1,2排好,3,4排好,然后1,2,3,4排序
快速排序 :通过一趟排序将要排序的数据分割成独立的两部分(选择一个"基准"),其中一部分的所有数据都比另外一部分的所有数据都要小,然后按照此方法递归直到完成(优化:三路快排)
堆排序:是一种树形选择排序。通过提取未排序的区域内最大的元素并将其移动到已排序的区域来迭代缩小未排序的区域
其他
计数排序
桶排序
基数排序
三.简单数据结构
物理结构:
数组
优点 :按照索引查询元素的速度很快;按照索引遍历数组也很方便。
缺点:数组的大小在创建后就确定了,无法扩容;数组只能存储一种类型的数据;添加、删除元素的操作很耗时间,因为要移动其他元素。
链表
优点 :不需要初始化容量;可以添加任意元素;插入和删除的时候只需要更新引用。
缺点:含有大量的引用,占用的内存空间大;查找元素需要遍历整个链表,耗时。
数组vs链表
查找:数组O(1) 链表O(n)
插入删除:数组O(n) 链表O(1)
逻辑结构
栈stack
后进先出FILO,入栈push,出栈pop
队列queue
先进先出FIFO,入队出队
双端队列
两端进出
散列表
定义:哈希表是key/value的映射关系,
实现:为了高效查询,用数组实现,把key转化为数组下标的函数就是哈希函数--hash()
哈希冲突 :
hash()不同的key得到相同数字,解决方案1.开放寻址法ThreadLocal 2.链表法HashMap
HashMap 扩容:负载因子,数组2倍扩容,重新hash
四.树
https://zhuanlan.zhihu.com/p/386991809
树
根节点,叶子节点;
父节点,孩子节点,兄弟节点;
二叉树
每个节点最多有两个孩子节点;
满二叉树,完全二叉树
结构:链表存储(数据,左孩子,右孩子)
二叉查找树
左节点小于父节点,右节点大于父节点:
插入,查找:
如果待插入数据比根结点的数据小,就去检查根结点的左孩子。如果左孩子不为空,就继续向下检查,如果左孩子为空,就说明已经找到应该插入数据的位置了。向右的情况则与向左的情况互为镜像,只是条件判断的符号换了一下而已。
以(3, 2, 1, 5, 4, 6)的顺序插入-查询时间复杂度O(logn)
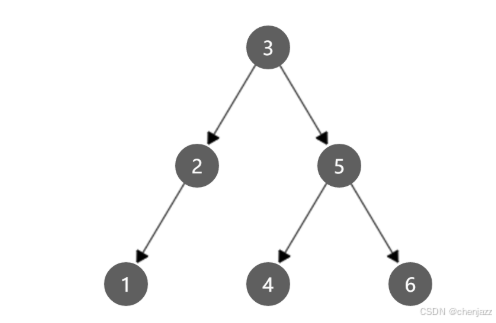
以(1, 2, 3, 4, 5, 6) 和 (6, 5, 4, 3, 2, 1)插入,查询时间复杂度退化成O(n)
遍历:
记:根在前就是前序遍历
| 遍历方式 | 访问顺序 | 适用场景 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 前序遍历 | 根 → 左 → 右 | 复制树、前缀表达式 | O(n) | O(h) |
| 中序遍历 | 左 → 根 → 右 | BST 排序、中缀表达式 | O(n) | O(h) |
| 后序遍历 | 左 → 右 → 根 | 释放内存、后缀表达式 | O(n) | O(h) |
| 层序遍历 | 按层从上到下、从左到右 | 按层处理数据、最短路径(BFS) | O(n) | O(w) |
注:n 为节点数,h 为树的高度(最坏情况 h = n),w 为树的最大宽度。
总结
DFS 与 BFS 的选择:
若需递归处理子树,选 DFS(前 / 中 / 后序)。
若需按层处理,选 BFS(层序)。
迭代与递归:
递归实现简洁,但可能导致栈溢出(如树过深)。
迭代实现需借助栈或队列,避免栈溢出。
遍历用途:
前序遍历常用于复制树结构。
中序遍历是 BST 的天然排序方式。
后序遍历适用于需要子树结果的场景(如动态规划)。
层序遍历常用于按层处理数据或求解最短路径问题。
二叉堆
二叉堆是一棵完全二叉树(除最后一层外,所有层均被填满;最后一层的节点从左到右依次排列,无间隙)。这种结构使其可高效地用数组存储:
所有节点的值需满足以下条件之一:
- 最大堆(Max Heap):每个父节点的值 ≥ 子节点的值(根节点为最大值)。
- 最小堆(Min Heap):每个父节点的值 ≤ 子节点的值(根节点为最小值)。
二叉堆的时间复杂度
操作 时间复杂度 说明
插入(Insert) O(log n) 最多上浮 log n 层
删除堆顶 O(log n) 最多下沉 log n 层
构建堆 O(n) 底层节点下沉次数少
查看堆顶 O(1) 直接访问数组第一个元素
二叉堆的应用
- 优先队列(Priority Queue):
堆是优先队列的经典实现,支持高效的 "取最值" 和 "插入" 操作,例如:
任务调度(按优先级执行任务)。霍夫曼编码(频繁合并最小权重节点)。 - 堆排序(Heap Sort):
步骤:
将数组构建为最大堆。
反复将堆顶(最大值)与末尾元素交换,缩小堆范围并下沉新堆顶,最终得到升序数组。
堆排序时间复杂度为 O(n log n),但不稳定(相同元素可能交换位置)。 - Top K 问题:
例如 "找出数组中前 K 个最大元素",可通过小顶堆(仅保留 K 个元素)高效实现,时间复杂度 O (n log K)。
二叉堆的局限性
- 不支持快速查找:堆仅维护最值,查找任意元素需遍历整个数组(O (n))。
- 删除中间元素效率低:需先查找元素(O (n)),再执行下沉 / 上浮(O (log n)),整体 O (n)。
- 与其他数据结构对比:
平衡二叉搜索树(如红黑树)支持更全面的操作(查找、插入、删除均 O (log n)),但实现更复杂。
斐波那契堆(Fibonacci Heap)理论上插入效率更高(O (1) amortized),但实际应用中因实现复杂较少使用。
AVL 树
自平衡 BST,通过旋转保证左右子树高度差 ≤1,插入 / 删除 / 查找 O (log n)。
红黑树
自平衡 BST,通过颜色标记和旋转保证树的平衡性,插入 / 删除 / 查找 O (log n)。
比较
| 树结构 | 核心特性 | 典型操作效率 | 核心应用场景 |
|---|---|---|---|
| 二叉搜索树 | 左小右大,无平衡约束 | 理想 O (log n) | 简单动态排序查询 |
| AVL 树 | 平衡因子≤1,严格平衡 | O(log n) | 高频查询、低频次更新 |
| 红黑树 | 颜色规则平衡,弱平衡 | O(log n) | 高频更新(如 map/set、进程调度) |
| B 树 | 多路平衡,节点存数据 | O(log_m n) | 磁盘存储(早期数据库索引) |
| B + 树 | 多路平衡,叶子存数据且链表化 | O(log_m n) | 数据库索引(范围查询优先) |
| 字典树 | 共享前缀,字符串存储 | O(L) | 前缀匹配、自动补全 |
| 哈夫曼树 | 带权路径最短 | 构建 O (n log n) | 数据压缩(哈夫曼编码) |
| 线段树 | 区间查询与更新 | O(log n) | 区间统计(如区间最大值) |