自动化爬虫selenium
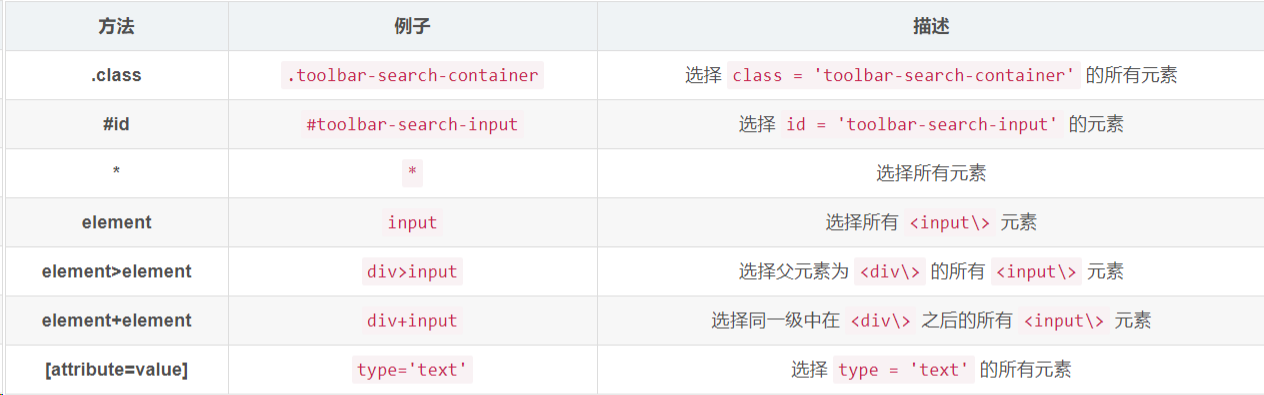
文章目录
- 自动化爬虫selenium
-
- 一:Selenium简介
- 二:元素定位
-
- [1:id 定位](#1:id 定位)
- [2:name 定位](#2:name 定位)
- [3:class 定位](#3:class 定位)
- [4:tag 定位](#4:tag 定位)
- [5:xpath 定位(最常用)](#5:xpath 定位(最常用))
- [6:css 定位](#6:css 定位)
- [7:link 定位](#7:link 定位)
- [8:partial_link 定位](#8:partial_link 定位)
- 三:浏览器控制
-
- 1:窗口大小
- [2:浏览器前进 & 后退](#2:浏览器前进 & 后退)
- 3:浏览器的刷新
- 4:浏览器窗口之间切换
- 5:常用方法
- 四:鼠标操作
- 五:键盘控制
- 六:设置元素等待
- 七:定位一组元素
- 八:切换操作
- 九:弹窗处理
- 十:百度自动化实例
- [十一:Chrome handless](#十一:Chrome handless)
一:Selenium简介
1:什么是selenium
Selenium是一个用于Web应用程序测试的工具
Selenium测试直接运行在浏览器之中,就像真正的用户在操作一样
支持各种的driver(火狐,谷歌,IE,Opera),驱动真实的浏览器完成测试
支持无界面浏览器操作
可以模拟浏览器的功能,自动执行网页中的JS代码,实现动态的加载
2:安装准备
1:安装selenium
shell
pip install selenium2:针对不同的浏览器,需要安装不同的驱动,常见的有谷歌和_Edge_
- Google:(https://chromedriver.storage.googleapis.com/index.html)
- Edge:(https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)
3:查看浏览器对应的版本,决定下哪个版本的驱动(设置 -> 关于 -> 得到版本)
- google查看方法
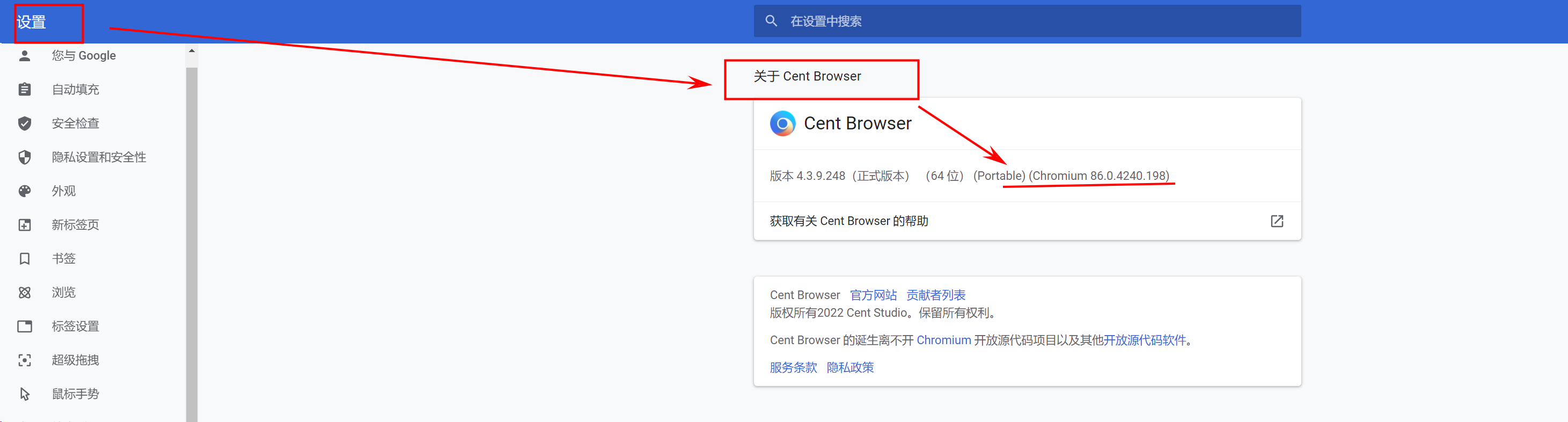
- edge查看方法
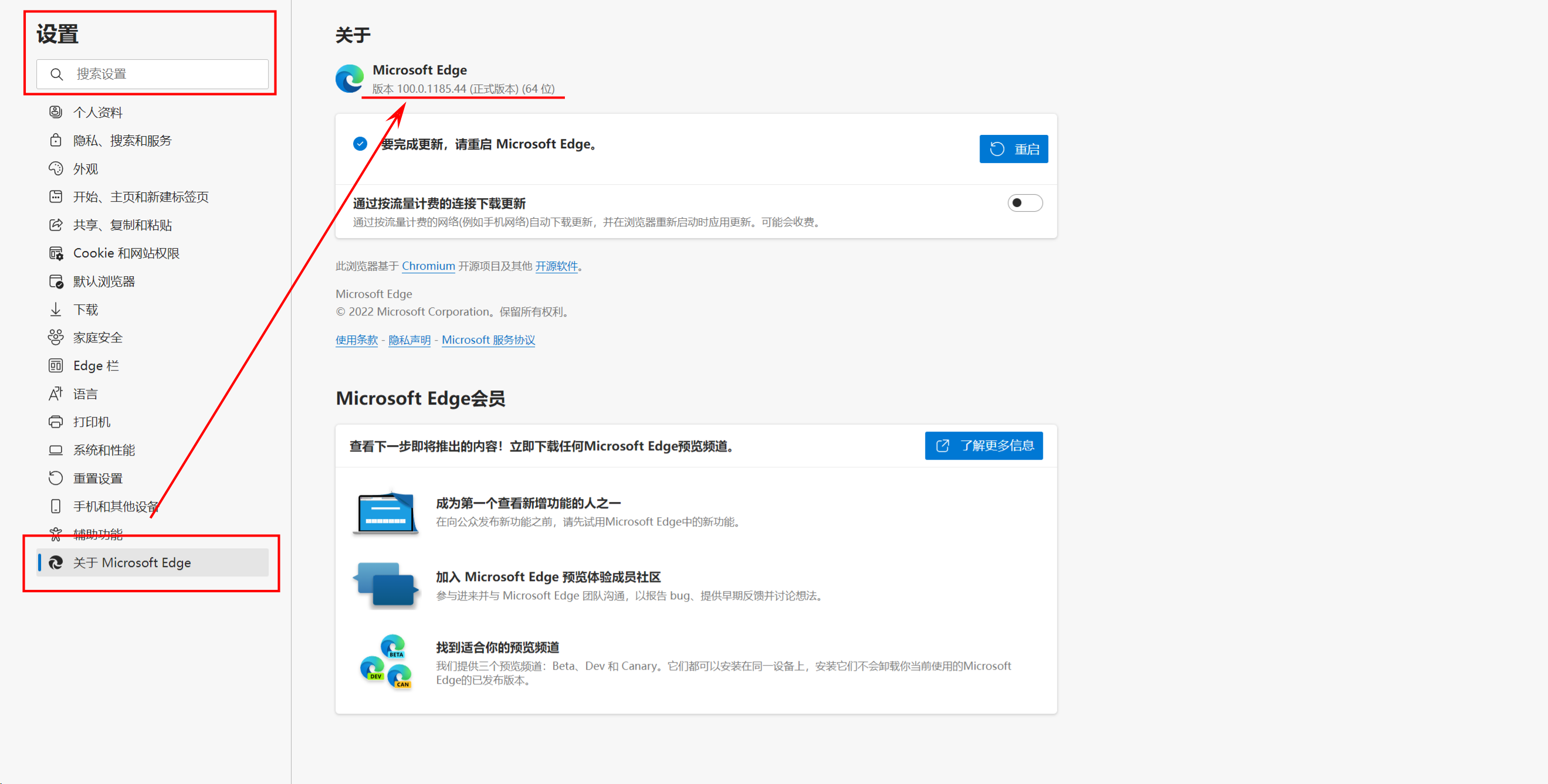
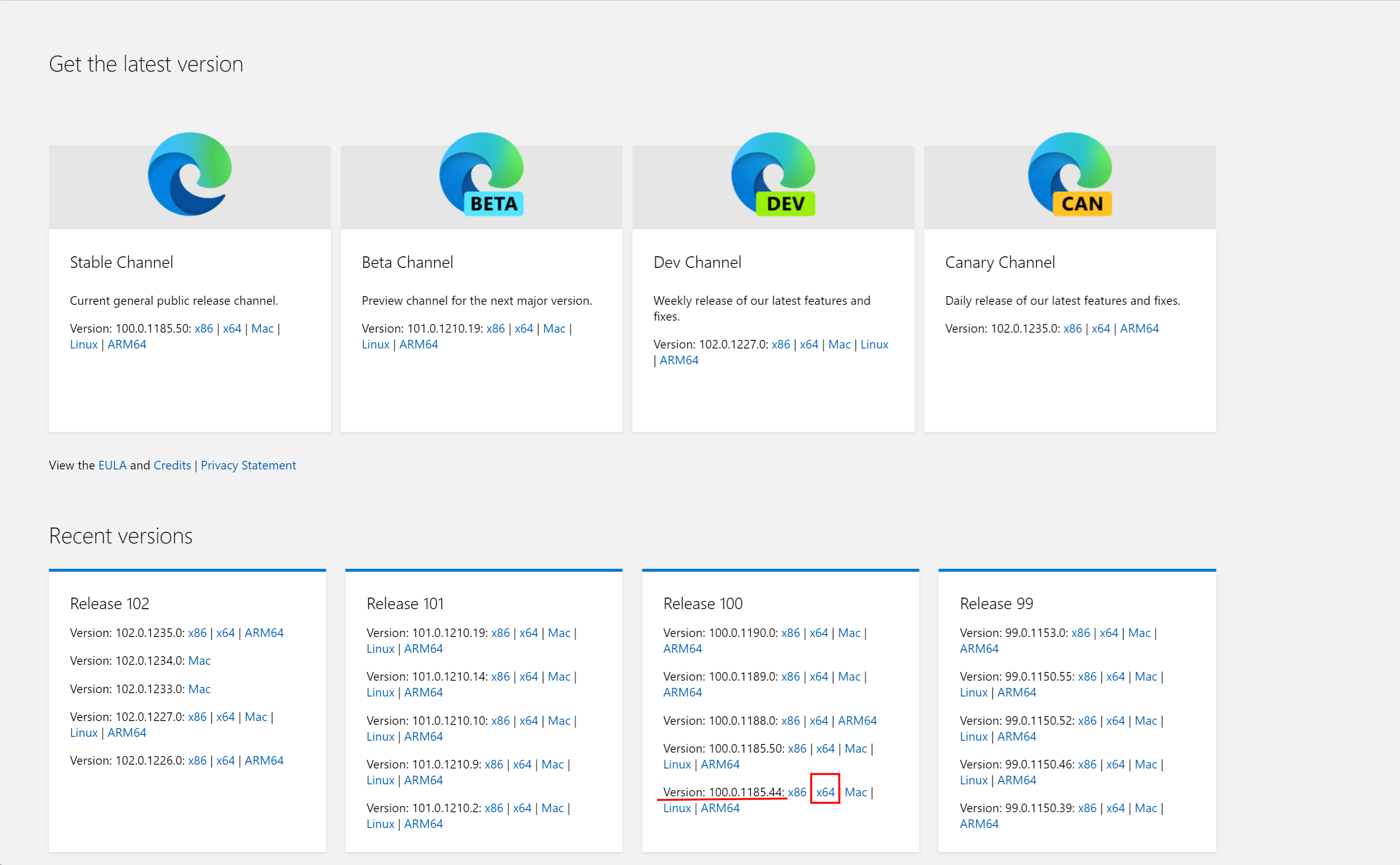
4:复制对应的解压文件到python的文件夹和浏览器的文件夹中
5:编写测试代码
python
from selenium import webdriver
if __name__ == '__main__':
driver = webdriver.Chrome(r'E:\centbrowser\chromedriver.exe')
driver.get('https://www.csdn.net/')⚠️ 如果打开主页后自动关闭,可以设置为不立刻关闭
python
from selenium import webdriver
if __name__ == '__main__':
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
driver = webdriver.Chrome(r'E:\centbrowser\chromedriver.exe', chrome_options=option)
driver.get('https://www.csdn.net/')二:元素定位
1:id 定位
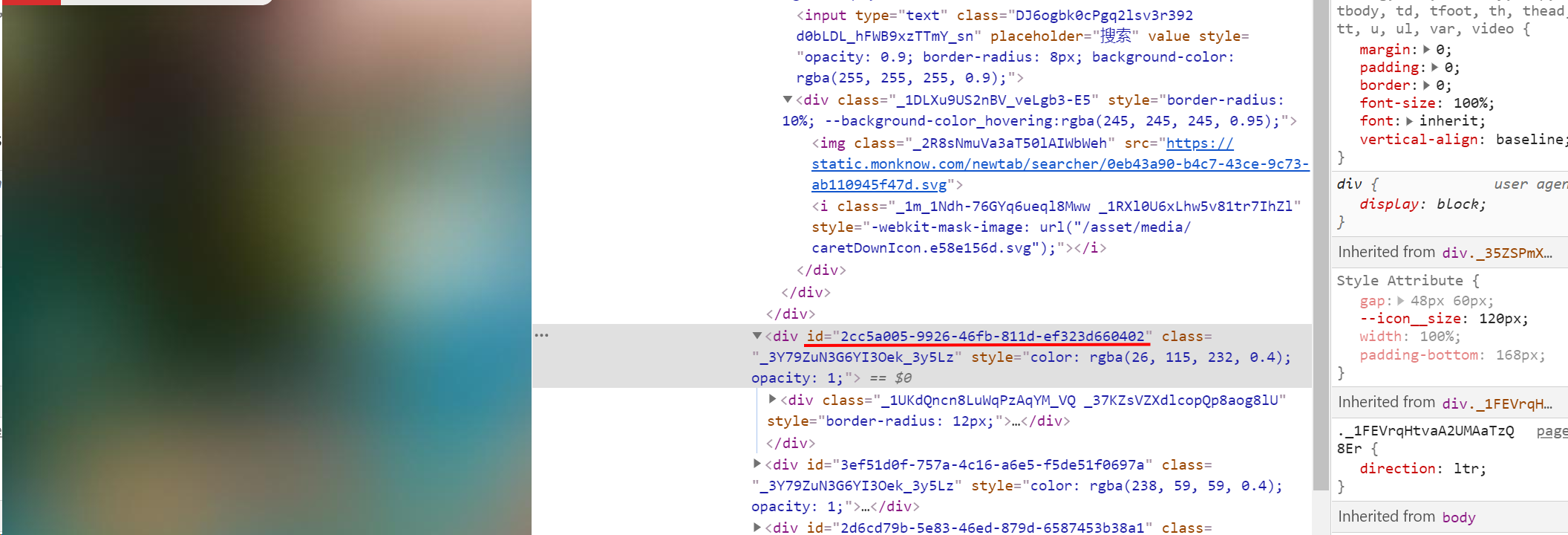
- 标签的
id具有唯一性,就像人的身份证 - 可以通过
id定位到它,由于id的唯一性,我们可以不用管其他的标签的内容。
python
driver.find_element_by_id("2cc5a005-9926-46fb-811d-ef323d660402")2:name 定位
html
<meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">name指定标签的名称,在页面中可以不唯一- 可以使用
find_element_by_name定位到meta标签。
python
driver.find_element_by_name("keywords")3:class 定位
html
<div class="toolbar-search-container">class指定标签的类名,在页面中可以不唯一- 可以使用
find_element_by_class_name定位到上面_html_片段的div标签
python
driver.find_element_by_class_name("toolbar-search-container")4:tag 定位
html
<div class="toolbar-search-container">- 每个
tag往往用来定义一类功能,通过tag来识别某个元素的成功率很低,每个页面一般都用很多相同的tag - 我们可以使用
find_element_by_class_name定位
python
driver.find_element_by_tag_name("div")5:xpath 定位(最常用)
python
# 绝对路径(层级关系)定位
driver.find_element_by_xpath("/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素属性定位
driver.find_element_by_xpath("//*[@id='toolbar-search-input']"))
# 层级+元素属性定位
driver.find_element_by_xpath("//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 逻辑运算符定位
driver.find_element_by_xpath("//*[@id='toolbar-search-input' and @autocomplete='off']")F12 -> 右键html元素内容 -> copy -> copy full xpath
6:css 定位
CSS使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性- 一般定位速度比
xpath要快,但使用起来略有难度
python
driver.find_element_by_css_selector('#toolbar-search-input')
driver.find_element_by_css_selector('html>body>div>div>div>div>div>div>input')7:link 定位
html
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>link专门用来定位文本链接- 使用
find_element_by_link_text并指明标签内全部文本即可定位
python
driver.find_element_by_link_text("加入!每日一练")8:partial_link 定位
- 就是"部分链接",对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子
python
# 上面的例子使用部分链接匹配
driver.find_element_by_partial_link_text("加入")三:浏览器控制
1:窗口大小
webdriver 提供 set_window_size() 方法来修改浏览器窗口的大小。
python
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600, 800)也可以使用 maximize_window() 方法可以实现浏览器全屏显示
python
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 设置浏览器浏览器的宽高为:600x800
driver.maximize_window()2:浏览器前进 & 后退
webdriver 提供 back 和 forward 方法来实现页面的后退与前进
python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
# 访问CSDN首页
driver.get('https://www.csdn.net/')
sleep(2)
#访问CSDN个人主页
driver.get('https://blog.csdn.net/qq_43965708')
sleep(2)
#返回(后退)到CSDN首页
driver.back()
sleep(2)
#前进到个人主页
driver.forward()第二次 get() 打开新页面时,会在原来的页面打开,而不是在新标签中打开。
如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行 js 语句来打开新的标签
python
# 在原页面打开
driver.get('https://blog.csdn.net/qq_43965708')
# 新标签中打开
js = "window.open('https://blog.csdn.net/qq_43965708')"
driver.execute_script(js)3:浏览器的刷新
python
# 刷新页面
driver.refresh()4:浏览器窗口之间切换
我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照时间 来的
最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打开的那个窗口了
python
# 获取打开的多个窗口句柄
windows = driver.window_handles
# 切换到当前最新打开的窗口(获取句柄数组中的最后一个)
driver.switch_to.window(windows[-1])5:常用方法
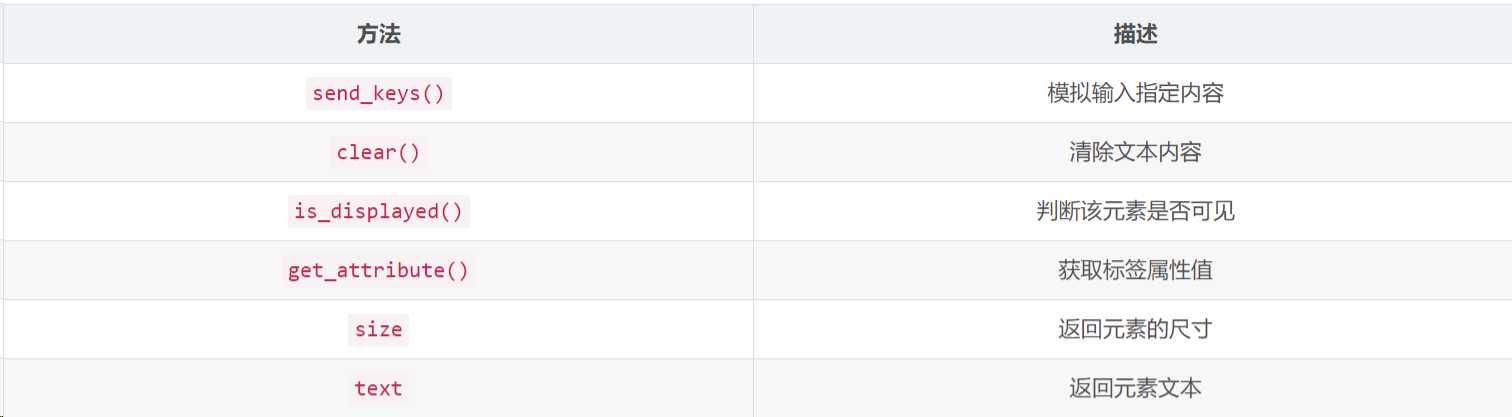
模拟操作
python
if __name__ == '__main__':
driver = webdriver.Chrome(r'E:\centbrowser\chromedriver.exe')
driver.get('https://www.csdn.net/')
sleep(2)
# 定位搜索输入框
text_label = driver.find_element_by_xpath('//*[@id="toolbar-search-input"]')
# 在搜索框中输入
text_label.send_keys('是小崔啊')
sleep(2)
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
button.click()四:鼠标操作
1:单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 ActionChains 。
python
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 执行单击操作
button.click()2:单击右键
单击右键需要使用 ActionChains
python
from selenium.webdriver.common.action_chains import ActionChains
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 右键搜索按钮
ActionChains(driver).context_click(button).perform()3:双击
需要使用 ActionChains
python
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 执行双击动作
ActionChains(driver).double_click(button).perform()4:拖动
模拟鼠标拖动操作,该操作有两个必要参数,
- source:鼠标拖动的元素
- target:鼠标拖至并释放的目标元素
python
# 定位要拖动的元素
source = driver.find_element_by_xpath('xxx')
# 定位目标元素
target = driver.find_element_by_xpath('xxx')
# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()5:鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框
python
# 定位收藏栏
collect = driver.find_element_by_xpath('xxx')
# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()五:键盘控制
webdriver 中 Keys 类几乎提供了键盘上的所有按键方法,我们可以使用 send_keys + Keys 实现输出键盘上的组合按键
python
from selenium.webdriver.common.keys import Keys
# 定位输入框并输入文本
driver.find_element_by_id('xxx').send_keys('是小崔啊')
# 模拟回车键进行跳转(输入内容后)
driver.find_element_by_id('xxx').send_keys(Keys.ENTER)
# 使用 Backspace 来删除一个字符
driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE)
# Ctrl + A 全选输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'a')
# Ctrl + C 复制输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'c')
# Ctrl + V 粘贴输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'v')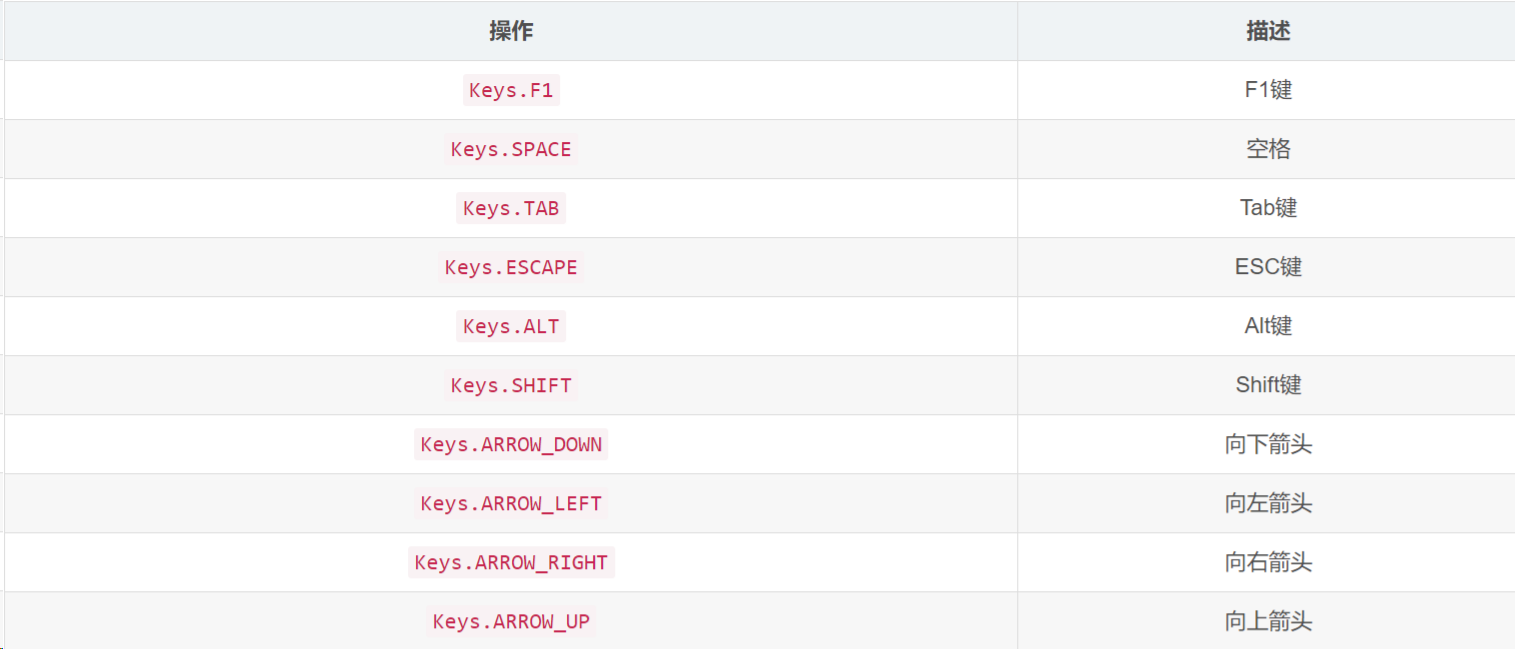
六:设置元素等待
很多页面都使用 ajax 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错。
可以设置元素等来增加脚本的稳定性。webdriver 中的等待分为 显式等待 和 隐式等待。
1:显示等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在:
- 如果存在则执行后续内容
- 如果超过最大时间(超时时间)则抛出超时异常(
TimeoutException)。 - 显示等待需要使用
WebDriverWait,同时配合until或not until。
python
'''
driver:浏览器驱动
timeout:超时时间,单位秒
poll_frequency:每次检测的间隔时间,默认为0.5秒
ignored_exceptions:指定忽略的异常
如果在调用 until 或 until_not 的过程中抛出指定忽略的异常,则不中断代码
默认忽略的只有 NoSuchElementException
'''
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
python
'''
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。
until_not 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
message: 如果超时,抛出 TimeoutException ,并显示 message 中的内容
method 中的预期条件判断方法是由 expected_conditions 提供,下面列举常用方法。
'''
until(method, message='xxx')
until_not(method, message='xxx')
python
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, 'kw')
element = driver.find_element_by_id('kw')
python
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, 'kw')),
message='超时啦!')2:隐式等待
用 implicitly_wait() 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 id 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
python
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
driver.implicitly_wait(5)
try:
# 触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常
driver.find_element_by_id('kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')七:定位一组元素
将元素定位中的element -> elements
find_elements_by_id()find_elements_by_name()find_elements_by_class_name()find_elements_by_tag_name()find_elements_by_xpath()find_elements_by_css_selector()find_elements_by_link_text()find_elements_by_partial_link_text()
python
from selenium import webdriver
# 设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://blog.csdn.net/')
p_list = driver.find_elements_by_xpath("//p[@class='name']")
name = [p.text for p in p_list]八:切换操作
1:窗口切换
窗口切换需要使用页面句柄和 switch_to.windows() 方法。
python
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
# 获取当前所有窗口的句柄
print(driver.window_handles)
可以看到第一个列表 handle 是相同的,说明 selenium 实际操作的还是 _CSDN_首页 ,并未切换到新页面。
下面使用 switch_to.windows() 进行切换。
python
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)
2:表单切换
- 很多页面也会用带 frame or iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用
switch_to.frame()方法将当前操作的对象切换成 frame or iframe 内嵌的页面。 switch_to.frame()默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。下面先写一个包含 iframe 的页面做测试用
举个例子
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div p {
color: red;
animation: change 2s infinite;
}
@keyframes change {
from {
color: red;
}
to {
color: blue;
}
}
</style>
</head>
<body>
<div>
<p>CSDN:是小崔啊</p>
</div>
<!-- 注意这里 -->
<iframe src="https://blog.csdn.net/qq_43350524" width="400" height="200"></iframe>
</body>
</html>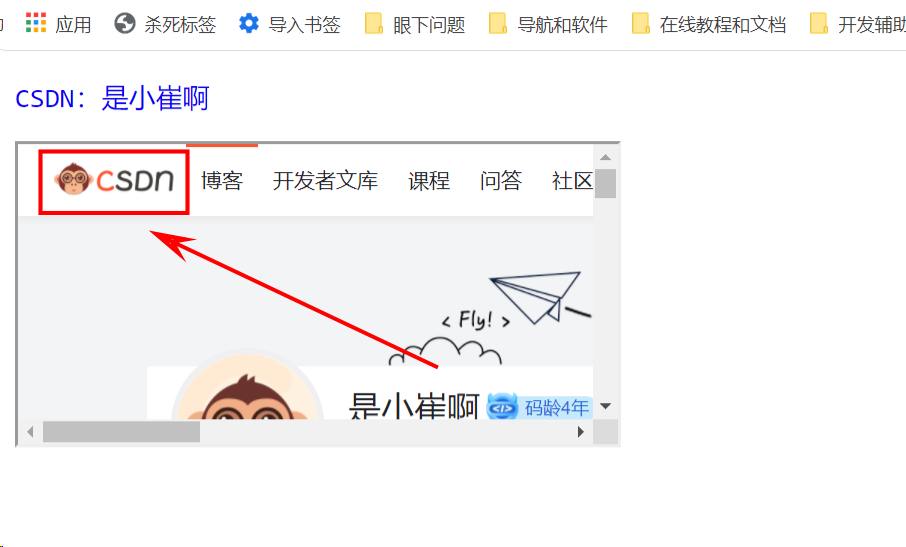
现在我们定位红框中的 CSDN 按钮,可以跳转到 CSDN 首页
python
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
# 读取本地html文件
driver.get('file:///' + str(Path(Path.cwd(), 'iframe测试.html')))
# 1.通过id定位
driver.switch_to.frame('CSDN_info')
# 2.通过name定位
# driver.switch_to.frame('是小崔啊')
# 通过xpath定位
# 3.iframe_label = driver.find_element_by_xpath('/html/body/iframe')
# driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[1]/div/a/img').click()九:弹窗处理
JavaScript 有三种弹窗 alert(确认)、confirm(确认、取消)、prompt(文本框、确认、取消)。
处理方式:
- 先定位(
switch_to.alert自动获取当前弹窗) - 再使用
text、accept、dismiss、send_keys等方法进行操作
html
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<button id="alert">alert</button>
<button id="confirm">confirm</button>
<button id="prompt">prompt</button>
<script type="text/javascript">
const dom1 = document.getElementById("alert");
dom1.addEventListener('click', function(){
alert("alert hello")
});
const dom2 = document.getElementById("confirm");
dom2.addEventListener('click', function(){
confirm("confirm hello")
});
const dom3 = document.getElementById("prompt");
dom3.addEventListener('click', function(){
prompt("prompt hello")
});
</script>
</body>
</html>
python
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get('file:///' + str(Path(Path.cwd(), '弹窗.html')))
sleep(2)
# 点击alert按钮
driver.find_element_by_xpath('//*[@id="alert"]').click()
sleep(1)
alert = driver.switch_to.alert
# 打印alert弹窗的文本
print(alert.text)
# 确认
alert.accept()
sleep(2)
# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="confirm"]').click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
# 取消
confirm.dismiss()
sleep(2)
# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="prompt"]').click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
# 向prompt的输入框中传入文本
prompt.send_keys("Dream丶Killer")
sleep(2)
prompt.accept()
'''输出
alert hello
confirm hello
prompt hello
'''十:百度自动化实例
python
import time
from selenium import webdriver
path = r"E:\centbrowser\chromedriver.exe"
browser = webdriver.Chrome(path)
url = "https://www.baidu.com"
browser.get(url)
time.sleep(2)
# 获取文本框对象
input_object = browser.find_element_by_id("kw")
input_object.send_keys("周杰伦")
time.sleep(2)
# 获取按钮并点击
button_object = browser.find_element_by_id("su")
button_object.click()
time.sleep(2)
# 滑到底部
js_bottom = "document.documentElement.scrollTop=100000"
browser.execute_script(js_bottom)
time.sleep(2)
# 跳转到下一页
next_object = browser.find_element_by_xpath("//a[@class='n']")
next_object.click()
time.sleep(2)
# 回退
browser.back()
time.sleep(3)
# 退出
browser.quit()十一:Chrome handless
Headless 模式是指浏览器在没有图形用户界面(GUI)的情况下运行,Selenium 支持 Chrome 和 Firefox 等主流浏览器的 Headless 模式,非常适合服务器环境和自动化测试/爬虫场景。
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') # 启用无头模式
chrome_options.add_argument('--disable-gpu') # 禁用GPU加速(旧版可能需要)
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://example.com")
print(driver.title)
driver.quit()高级配置选项
python
chrome_options.add_argument('--no-sandbox') # 禁用沙盒
chrome_options.add_argument('--disable-dev-shm-usage') # 解决/dev/shm内存不足问题
chrome_options.add_argument('--window-size=1920,1080') # 设置窗口大小
chrome_options.add_argument('--blink-settings=imagesEnabled=false') # 禁用图片加载
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
# chrome浏览器的文件路径
path = r'E:\centbrowser\chrome.exe'
chrome_options.binary_location = path
return webdriver.Chrome(chrome_options=chrome_options)
if __name__ == '__main__':
browser = share_browser()
# 剩下的部分就一样了
url = "https://www.baidu.com"
browser.get(url)
browser.save_screenshot("baidu.png")
time.sleep(2)
browser.quit()