一、排序算法的概念
排序(Sorting)是指:将一组"无序 "的数据,按照某种"顺序规则 "排列成"有序"的过程。
1、按排序顺序分类:
升序:从小到大排列,如 1, 3, 5, 7, 9
- 降序:从大到小排列,如 9, 7, 5, 3, 1
2、按排序方式分类:
| 分类方式 | 排序类型 | 简要说明 |
|---|---|---|
| 内部排序 | 冒泡、插入、选择、归并、快速等 | 所有数据在内存中进行排序 |
| 外部排序 | 多路归并排序 | 数据量过大时,需借助外部存储 |
二、 常见的排序算法及其特点
| 排序算法 | 时间复杂度(平均) | 空间复杂度 | 是否稳定 | 适用场景 |
|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(1) | 稳定 | 小规模数据、教学演示 |
| 选择排序 | O(n²) | O(1) | 不稳定 | 数据量小、对稳定性要求不高 |
| 插入排序 | O(n²) | O(1) | 稳定 | 基本有序数据、链表排序 |
| 归并排序 | O(n log n) | O(n) | 稳定 | 大数据排序、需要稳定性 |
| 快速排序 | O(n log n) | O(log n) | 不稳定 | 实际中最常用,效率高 |
| 堆排序 | O(n log n) | O(1) | 不稳定 | 不要求稳定性的高效排序 |
| 计数排序 | O(n + k) | O(k) | 稳定 | 数据范围小的整数排序 |
| 桶排序 | O(n + k) | O(n + k) | 稳定 | 分布均匀的数据 |
| 基数排序 | O(nk) | O(n + k) | 稳定 | 位数较小的整数/字符串 |
三、排序算法的应用场景
-
数据库系统:
-
排序是实现 ORDER BY 的核心
-
排序有助于数据压缩和索引创建
-
-
搜索优化:
- 排序之后可以使用二分查找,大幅提高搜索效率
数据分析和可视化:
-
-
排序能帮助找出最大/最小值、前 K 大数等
-
排序数据更容易图表化展示
-
-
去重和统计:
排序后相同数据聚集在一起,方便统计频率或去重
-
工程开发:
排序是实现自动推荐、页面排名、调度优化等系统的基础
四、常用排序算法的实现
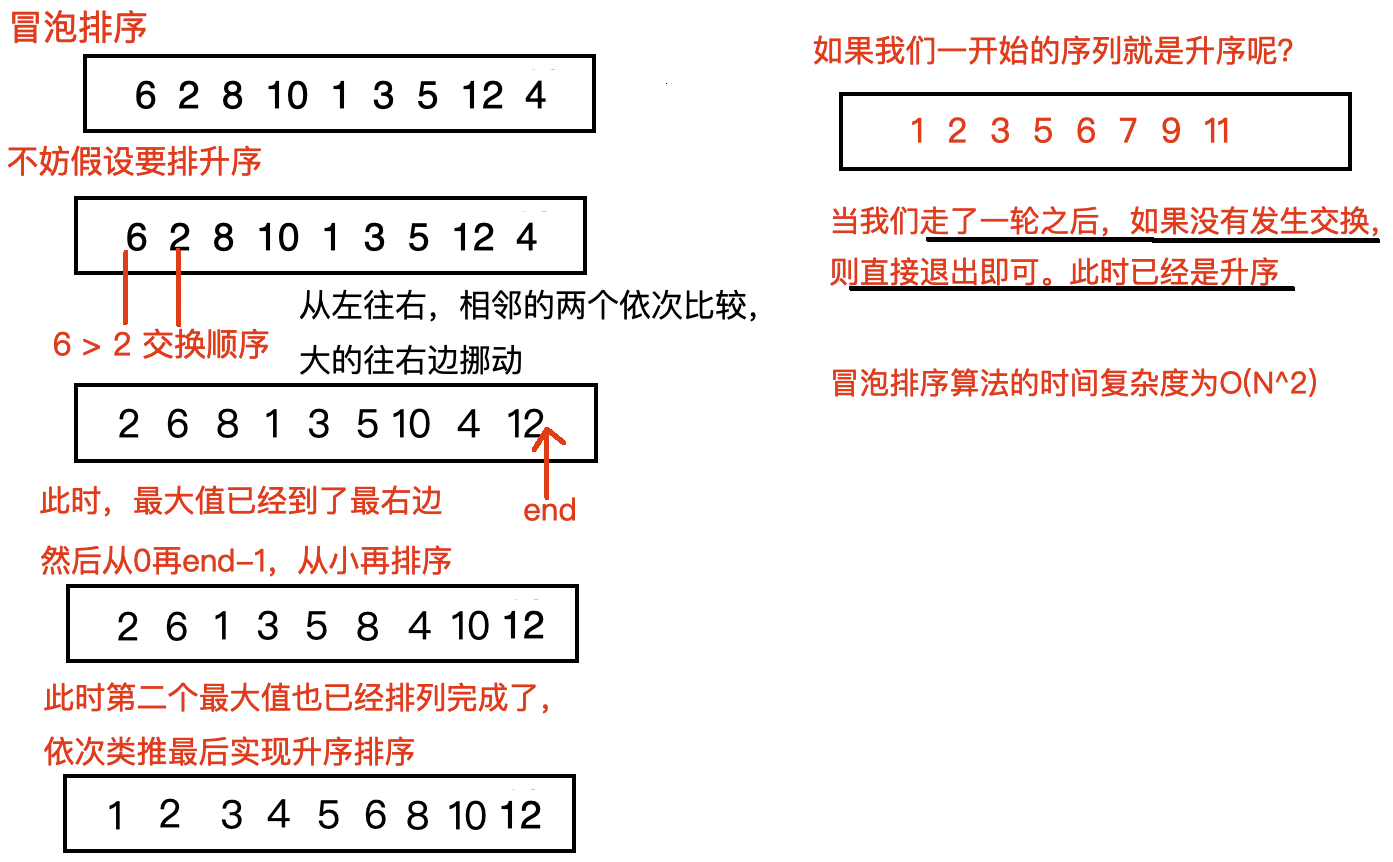
1、冒泡排序🫧
不断比较邻近的元素,将大元素右移,最终排成升序序列
代码实现:
cppvoid Swap(int* p,int* q){ assert(p&&q); int tmp = *p; *p = *q; *q = tmp; return; } void Bubble_sort(int* arr,int size){ assert(arr); int end = size-1; int flag = 0; for (int i = 0;i<end;i++){ for(int j = 0;j<end-i;j++){ if(arr[j]>arr[j+1]){ Swap(&arr[j],&arr[j+1]); flag = 1; } } if(flag == 0){ break; } } return; } //测试函数 int main(){ int arr[]= {6,2,8,10,1,3,5,12,4}; Bubble_sort(arr,9); for(int i = 0;i<9;i++){ printf("%d ",arr[i]); } }
冒泡排序的时间复杂度为,空间复杂度
。
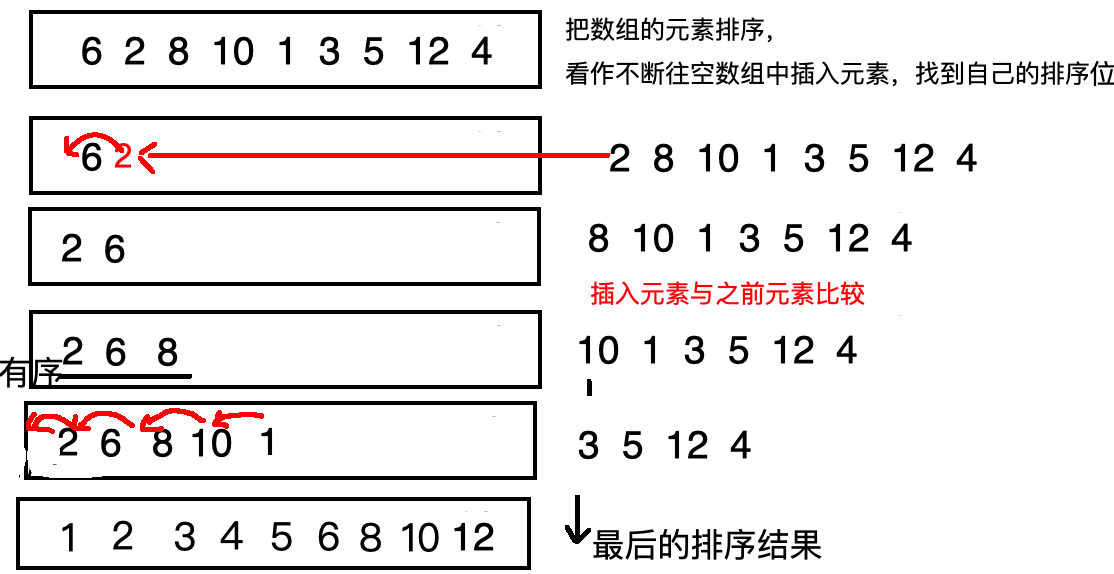
2、插入排序
将数组的每个元素与所在位置之前的元素比较,找到升序(降序)位插入即可。
代码实现:
cppvoid Insert_Sort(int* arr,int size){ assert(arr); for (int end = 1;end<size;end++){ for(int j = end-1;j>=0;j--){ if(arr[j+1]<arr[j]){ Swap(&arr[j],&arr[j+1]); } else{ break; } } } } int main(){ int arr[]= {6,2,8,10,1,3,5,12,4}; // Bubble_sort(arr,9); Insert_Sort(arr,9); for(int i = 0;i<9;i++){ printf("%d ",arr[i]); } }
插入排序的时间复杂度为
,空间复杂度
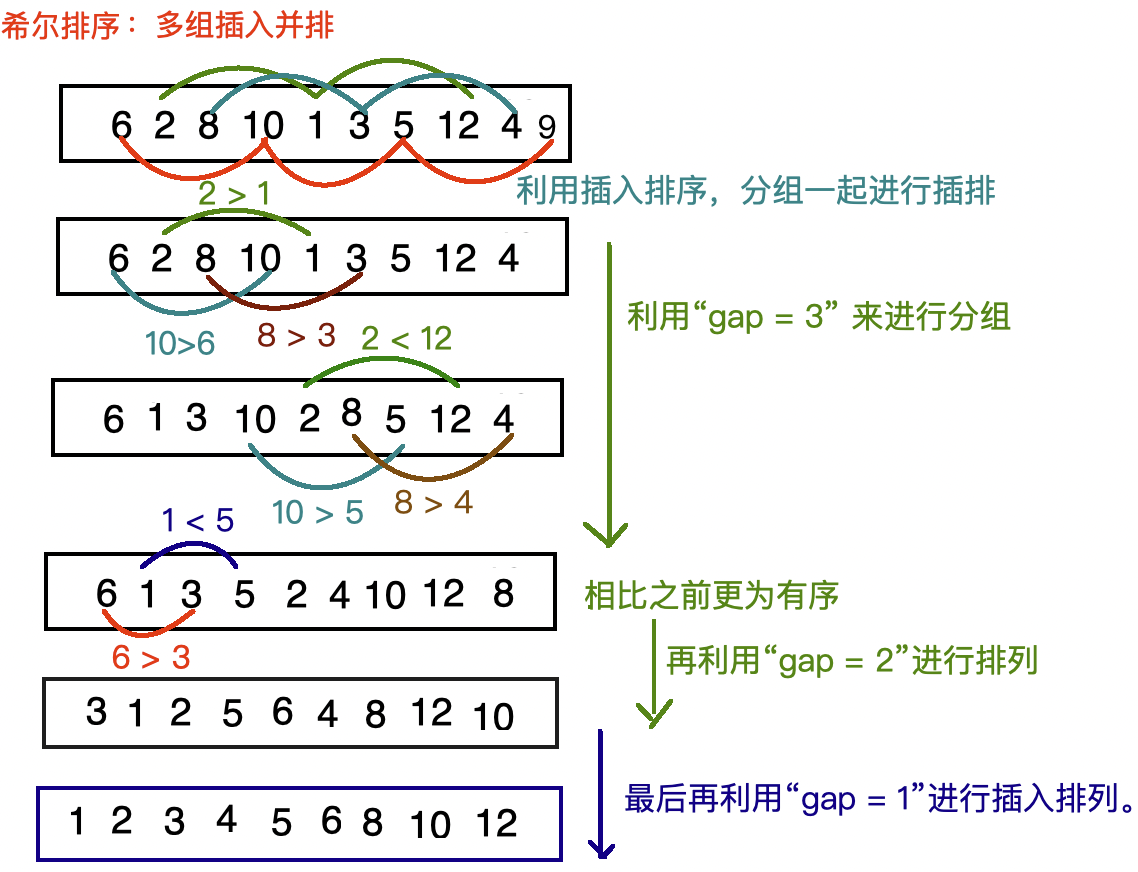
3、希尔排序的基本思想
希尔排序的提出者是 Donald Shell(1959 年),它是第一个突破 O(n²) 时间复杂度的排序算法。
核心思想:
将原始数组按照某个间隔 gap 进行"分组",每组分别进行插入排序,然后逐步减小 gap,最终 gap = 1 时再进行一次插入排序,完成排序。
希尔排序的步骤说明(以升序为例)
-
选择一个初始间隔 gap,通常是数组长度的一半,如 gap = n/2
-
将数组划分为 gap 个子序列(组内元素间隔为 gap)
-
对每个子序列进行插入排序
-
缩小 gap:gap = gap / 2
-
重复步骤 2~4,直到 gap = 1
思维导图
代码实现:
cppvoid Shell_Sort(int* arr,int size){ assert(arr); int gap = size; while(gap > 1) { gap = gap/3+1; for (int end = gap;end<size;end++){ int j = end-gap; int tmp = arr[end]; while (j>=0 && arr[j]>tmp) { arr[j+gap] = arr[j]; j -= gap; } arr[j+gap] = tmp; } } }
希尔排序的时间复杂度:最坏情况视 gap 序列而定,常见为 O(n^(1.3 ~ 2)),比 O(n²) 快很多
希尔排序的特点
| 特性 | 描述 |
|---|---|
| 时间复杂度 | 最坏情况视 gap 序列而定,常见为 O(n^(1.3 ~ 2)),比 O(n²) 快很多 |
| 空间复杂度 | O(1)(原地排序) |
| 稳定性 | 不稳定排序(可能打乱相同元素顺序) |
| 应用场景 | 中等规模、内存受限的排序任务 |
希尔排序与插入排序的对比
| 项目 | 插入排序 | 希尔排序 |
|---|---|---|
| 排序速度 | 慢(O(n²)) | 快(改进版插排) |
| 数据交换次数 | 多 | 少 |
| 排序思想 | 比较相邻元素 | 比较"间隔 gap"的元素 |
| 应对无序数据 | 效率低 | 效率更高 |
好了本期的排序算法内容分享就到这里结束了,谢谢大家的点赞收藏