深度学习 ---神经网络以及数据准备
文章目录
- [深度学习 ---神经网络以及数据准备](#深度学习 ---神经网络以及数据准备)
- 一,深度学习
-
- [1.1 深度学习简介](#1.1 深度学习简介)
- 1.2,深度学习的优势
- 二,神经网络
- 三,数据加载
-
- [3.1 构建数据类](#3.1 构建数据类)
- [3.2 数据加载器](#3.2 数据加载器)
- [3.3 使用数据加载器重构函数最优解案例](#3.3 使用数据加载器重构函数最优解案例)
- [3.4 数据加载器加载案例](#3.4 数据加载器加载案例)
一,深度学习
1.1 深度学习简介
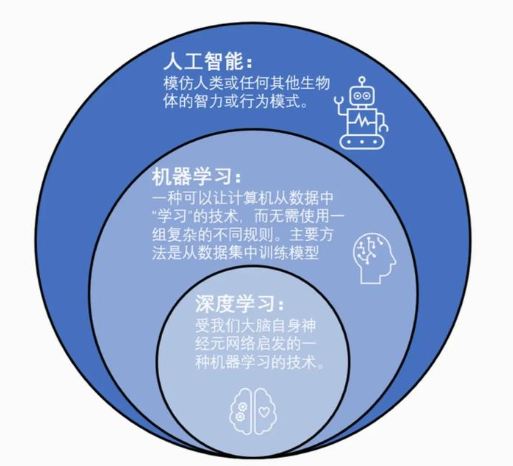
人工智能、机器学习和深度学习之间的关系:
深度学习可以处理图像,文本,音频,视频等各种内容,主要应用领域有:
- 图像处理:分类、目标检测、图像分割(语义分割)
- 自然语言处理:LLM、NLP、Transformer
- 语音识别:对话机器人、智能客服(语音+NLP)
- 自动驾驶:语义分割(行人、车辆、实线等)
- LLM:大Large语言Language模型Model
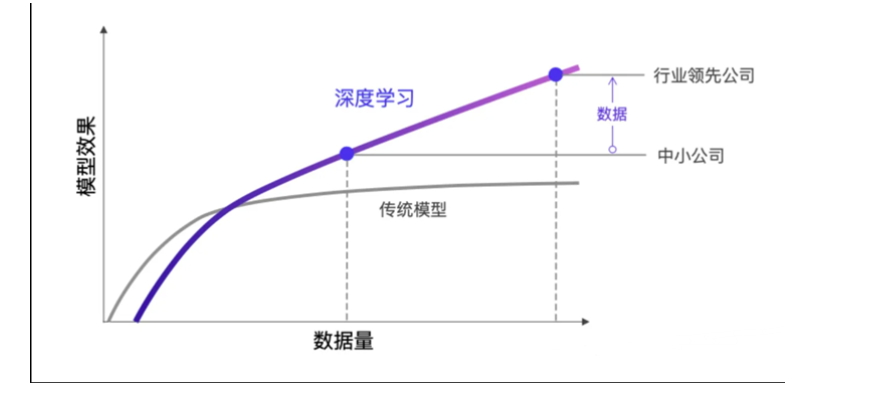
1.2,深度学习的优势
二,神经网络
神经网络(Neural Networks)是一种模拟人脑神经元网络结构的计算模型,用于处理复杂的模式识别、分类和预测等任务
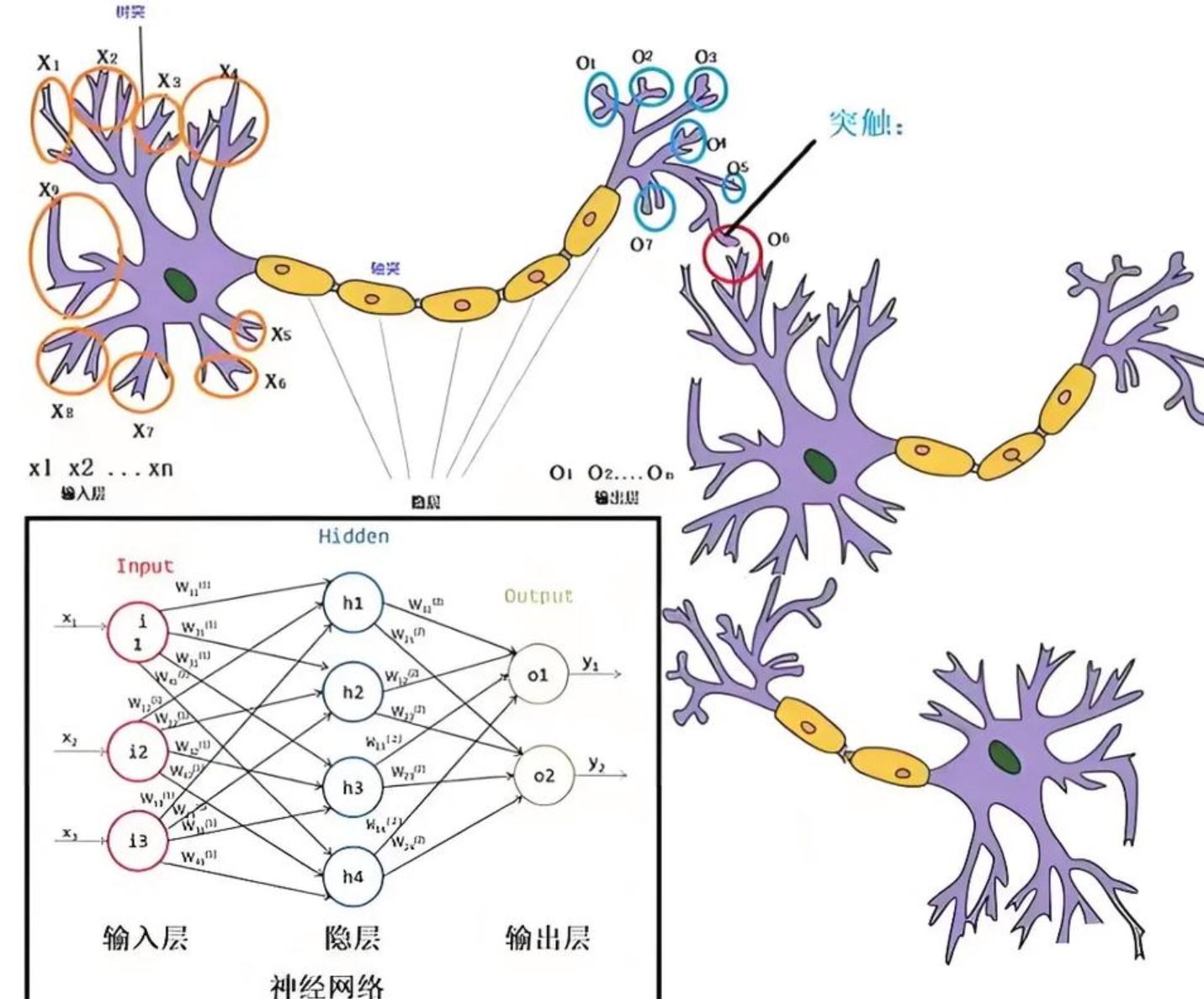
生物学:
人脑可以看做是一个生物神经网络,由众多的神经元连接而成
- 树突:从其他神经元接收信息的分支
- 细胞核:处理从树突接收到的信息
- 轴突:被神经元用来传递信息的生物电缆
- 突触:轴突和其他神经元树突之间的连接
人脑神经元处理信息的过程:
- 多个信号到达树突,然后整合到细胞体的细胞核中
- 当积累的信号超过某个阈值,细胞就会被激活
- 产生一个输出信号,由轴突传递。
神经网络由多个互相连接的节点(即人工神经元)组成。
2.1 人工神经元
人工神经元是神经网络的基本构建单元,模仿了生物神经元的工作原理。其核心功能是接收输入信号,经过加权求和和非线性激活函数处理后,输出结果。
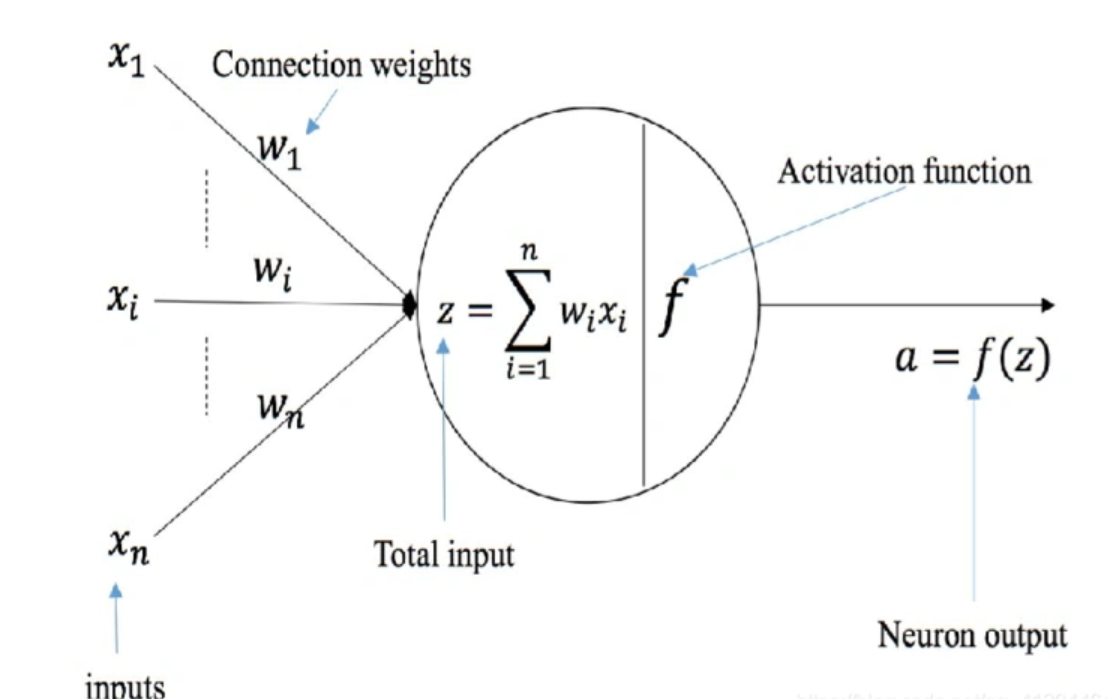
数学表示
x z = ∑ i = 1 n w i ⋅ x i + b y = σ ( z ) xz=\sum_{i=1}^nw_i\cdot x_i+b \\y=\sigma(z) xz=i=1∑nwi⋅xi+by=σ(z)
其中激活函数是: σ ( z ) \sigma(z) σ(z)
线性回归:线性回归不需要激活函数
y = ∑ i = 1 n w i ⋅ x i + b y=\sum_{i=1}^nw_i\cdot x_i+b \\ y=i=1∑nwi⋅xi+b
逻辑回归:
z = ∑ i = 1 n w i ⋅ x i + b y = σ ( z ) = s i g m o i d ( z ) = 1 1 + e − z z=\sum_{i=1}^nw_i\cdot x_i+b \\ y=\sigma(z)=sigmoid(z)=\frac{1}{1+e^{-z}} z=i=1∑nwi⋅xi+by=σ(z)=sigmoid(z)=1+e−z1
2.2 构建神经网络
2.2.1 基本结构
神经网络是由大量人工神经元按层次结构连接而成的计算模型。每一层神经元的输出作为下一层的输入,最终得到网络的输出。
神经网络有下面三个基础层(Layer)构建而成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结果
-
网络构建
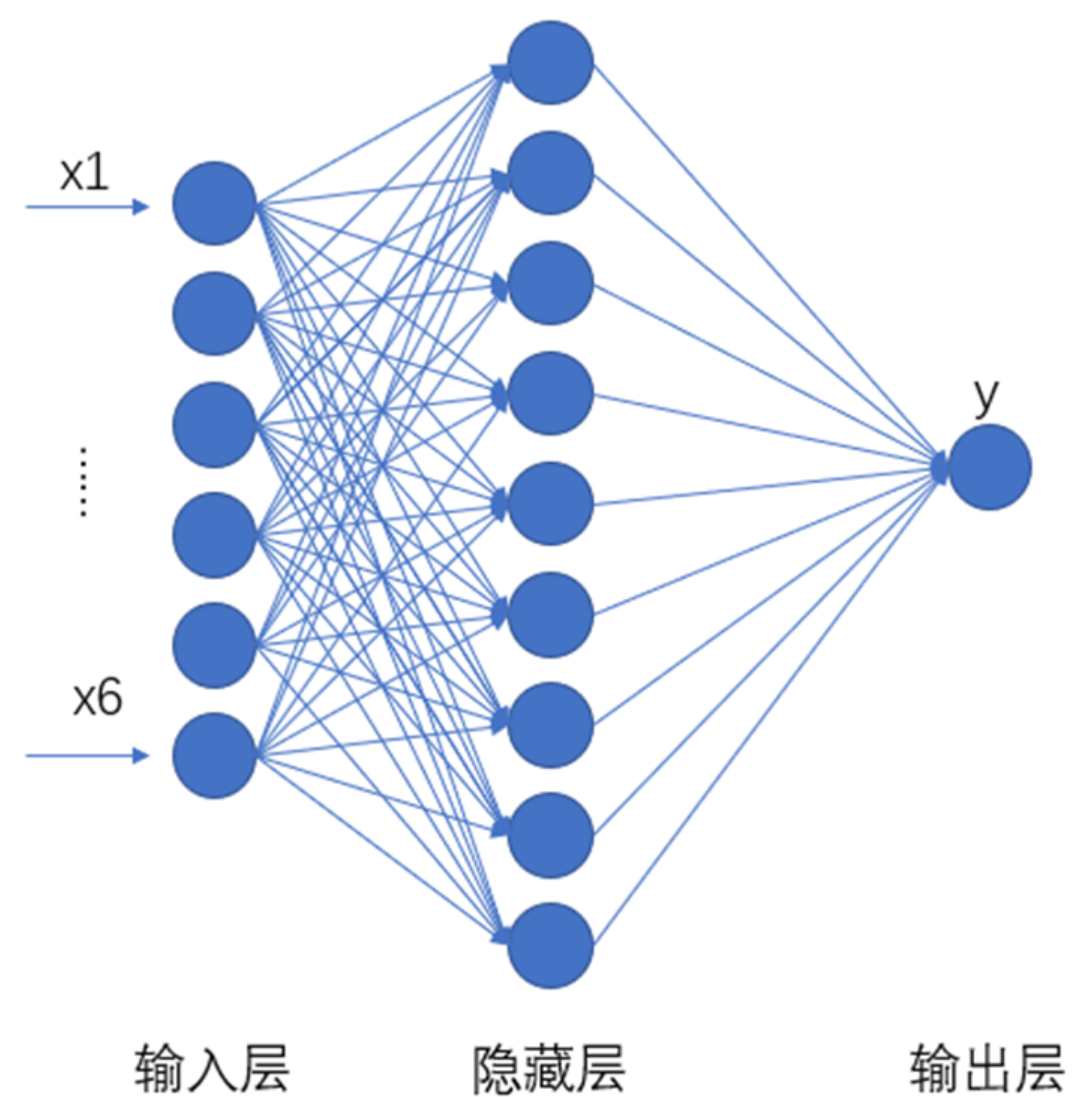
同一层的各个神经元之间没有连接
2.2.2 全连接神经网络
前馈神经网络(Feedforward Neural Network,FNN)是一种最基本的神经网络结构,其特点是信息从输入层经过隐藏层单向传递到输出层,没有反馈或循环连接。
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接,常用于图像分类、文本分类等任务。
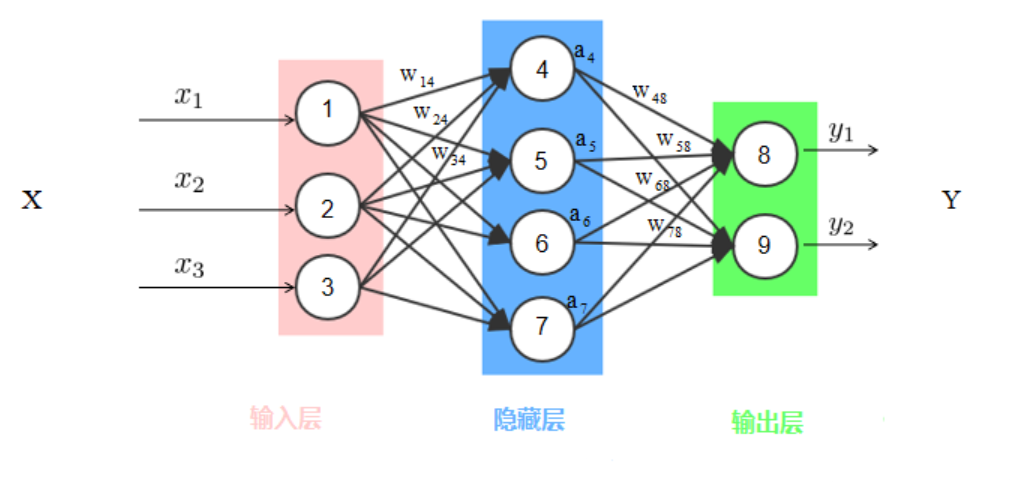
特点
- 全连接层: 层与层之间的每个神经元都与前一层的所有神经元相连。
- 权重数量: 由于全连接的特点,权重数量较大,容易导致计算量大、模型复杂度高。
- 学习能力: 能够学习输入数据的全局特征,但对于高维数据却不擅长捕捉局部特征(如图像就需要CNN)
计算步骤
- 数据传递: 输入数据经过每一层的计算,逐层传递到输出层。
- 激活函数: 每一层的输出通过激活函数处理。
- 损失计算: 在输出层计算预测值与真实值之间的差距,即损失函数值。
- 反向传播(Back Propagation): 通过反向传播算法计算损失函数对每个权重的梯度,并更新权重以最小化损失。
API
torch.nn.Linear(in_features, out_features, bias=True)参数说明:
in_features:
- 输入特征的数量(即输入数据的维度)。
- 例如,如果输入是一个长度为 100 的向量,则 in_features=100。
out_features:
- 输出特征的数量(即输出数据的维度)。
- 例如,如果希望输出是一个长度为 50 的向量,则 out_features=50。
bias:
- 是否使用偏置项(默认值为 True)。
- 如果设置为 False,则不会学习偏置项。
2.2.3 构建全连接神经网络示例
python
from torch import nn
import torch
class Net(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
self.fc1=nn.Linear(in_features,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,64)
def forward(self,x):
x=torch.relu(self.fc1(x))
x=torch.relu(self.fc2(x))
x=torch.relu(self.fc3(x))
return x
def main():
in_features,out_features=784,10
net=Net(in_features,out_features)
print(net)
def test02():
in_features,out_features=784,10
model=nn.Sequential(
nn.Linear(in_features,256),
nn.Linear(256,128),
nn.Linear(128,64)
)
print(model)
#单层神经网络
def test03():
in_features,out_features=784,10
model=nn.Linear(in_features,out_features)
print(model)三,数据加载
3.1 构建数据类
- init 方法
用于初始化数据集对象:通常在这里加载数据,或者定义如何从存储中获取数据的路径和方法。 - len 方法
返回样本数量:需要实现,以便 Dataloader加载器能够知道数据集的大小。 - getitem 方法
根据索引返回样本:将从数据集中提取一个样本,并可能对样本进行预处理或变换。
python
import torch
from torch.utils.data import Dataset, DataLoader, TensorDataset
from sklearn.datasets import make_regression
from torch import nn, optim
# 自定义数据集类步骤:
# 1.继承Dataset类
# 2.实现__init__方法,初始化外部的数据
# 3.实现__len__方法,用来返回数据集的长度
# 4.实现__getitem__方法,根据索引获取对应位置的数据
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample = self.data[index]
label = self.labels[index]
return sample, label
def test01():
x = torch.randn(100, 20)
y = torch.randn(100, 1)
dataset = MyDataset(x, y)
print(dataset[0])
# DataLoader:数据加载器,用来分批次加载数据,返回一个迭代器
# 参数:
# batch_size:设置每批次加载的样本数量
# shuffle:设置是否要打乱数据,True-打乱,False-不打乱
dataloader = DataLoader(
dataset=dataset,
batch_size=20,
shuffle=True
)
for sample, label in dataloader:
print(sample)
print(label)
break
if __name__ == '__main__':
test01()3.2 数据加载器
在训练或者验证的时候,需要用到数据加载器批量的加载样本。
DataLoader 是一个迭代器,用于从 Dataset 中批量加载数据。它的主要功能包括:
- 批量加载:将多个样本组合成一个批次。
- 打乱数据:在每个 epoch 中随机打乱数据顺序。
- 多线程加载:使用多线程加速数据加载。
python
import torch
def test02():
x = torch.randn(100, 20)
y = torch.randn(100, 1)
dataset = TensorDataset(x, y)
dataloader = DataLoader(
dataset=dataset,
batch_size=20,
shuffle=True
)
for sample, label in dataloader:
print(sample)
print(label)
break
if __name__ == '__main__':
test02()3.3 使用数据加载器重构函数最优解案例
python
def train():
# 数据准备
in_features = 10
out_features = 1
x, y, coef, bias = build_data(in_features, out_features)
dataset = TensorDataset(x, y)
dataloader = DataLoader(
dataset=dataset,
batch_size=100,
shuffle=True
)
# 定义网络模型
model = nn.Linear(in_features, out_features)
# 损失函数
criterion = nn.MSELoss()
# 优化器
opt = optim.SGD(model.parameters(), lr=0.1)
epochs = 20
for epoch in range(epochs):
for tx, ty in dataloader:
y_pred = model(tx)
loss = criterion(y_pred, ty)
opt.zero_grad()
loss.backward()
opt.step()
print(f'epoch:{epoch},loss:{loss.item()}')
# detach()、data:作用是将计算图中的weight参数值获取出来
print(f'真实权重:{coef.numpy()}, 训练权重:{model.weight.data.numpy()}')
print(f'真实偏置:{bias},训练偏置:{model.bias.item()}')
if __name__ == '__main__':
train()
3.4 数据加载器加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器
python
import torch
from torch.utils.data import DataLoader,TensorDataset
from torch import nn
import pandas as pd
from torchvision import datasets, transforms
def build_csv_data(filepath):
df = pd.read_csv(filepath)
df.drop(["姓名","学号"],axis=1,inplace=True)
print(df.head())
samples=df.iloc[:,:-1].values
labels=df.iloc[:,-1].values
samples=torch.from_numpy(samples).float()
labels=torch.from_numpy(labels).long()
return samples,labels
#加载csv数据集
def load_csv_data():
filepath="torch-fcnn/fcnn-demo/datasets/大数据答辩成绩表.csv"
samples,labels=build_csv_data(filepath)
dataset=TensorDataset(samples,labels)
dataloader=DataLoader(dataset,
batch_size=32,
shuffle=True
)
for i,data in enumerate(dataloader):
inputs,labels=data
print(inputs.shape,labels.shape)
print(inputs,labels)
#加载图片
def load_image_data():
path="torch-fcnn/fcnn-demo/datasets/animals"
transform=transforms.Compose([
transforms.ToTensor()
])
dataset=datasets.ImageFolder(path,
transforms)
dataloader=DataLoader(dataset,
batch_size=4,
shuffle=True)
for x,y in dataloader:
print(x.shape)
print(y.shape)
if __name__ == '__main__':
load_csv_data()
load_image_data()