一、概念
Keepalived 是一个用 C 语言编写的、轻量级的高可用性和负载均衡解决方案软件。 它的主要目标是在基于 Linux 的系统上提供简单而强大的故障转移 功能,并可以结合 Linux Virtual Server 提供负载均衡。
1、Keepalived 主要提供两大功能:
-
高可用性:
-
原理: 基于 VRRP 协议。
-
工作方式:
-
一组服务器(通常是两台或更多)运行 Keepalived 守护进程,形成一个 VRRP 实例。
-
这些服务器被配置为拥有一个或多个共享的虚拟 IP 地址。这个 VIP 是客户端实际访问的 IP 地址。
-
其中一台服务器被选举为 MASTER ,其他服务器处于 BACKUP 状态。
-
MASTER 节点:
-
持有共享的 VIP。
-
定期发送 VRRP 通告给组内的其他节点,宣告自己还活着。
-
负责处理所有发送到该 VIP 的流量。
-
-
BACKUP 节点:
-
监听 MASTER 发来的 VRRP 通告。
-
如果在一段时间内(
advert_int间隔 + 超时时间)没有收到 MASTER 的通告,BACKUP 节点会认为 MASTER 发生了故障。 -
此时,优先级最高的 BACKUP 节点会发起选举,将自己提升为新的 MASTER,并通过 ARP 广播宣告自己接管了 VIP。
-
-
故障转移: 这个过程实现了自动故障转移。当主服务器宕机时,备份服务器几乎可以瞬间(毫秒级)接管 VIP 和服务,对客户端来说服务几乎是连续的(短暂中断或 TCP 重连)。
-
-
优势: 简单、高效、切换速度快。
-
-
负载均衡:
-
原理: 集成并管理 LVS。
-
工作方式:
-
Keepalived 自身不直接处理负载均衡流量。
-
它利用 Linux 内核的 LVS 框架来实现第四层(传输层,如 TCP/UDP)的负载均衡。
-
Keepalived 负责:
-
配置 LVS 规则: 在 MASTER 节点上,根据配置文件自动设置 LVS 的虚拟服务器、后端真实服务器池、调度算法(如轮询 rr、加权轮询 wrr、最少连接 lc 等)和健康检查机制。
-
管理 LVS 状态: 当发生主备切换时,新的 MASTER 会接管并重新配置 LVS 规则,确保负载均衡服务不中断。
-
健康检查: 对后端真实服务器进行健康检查(支持 TCP_CHECK, HTTP_GET, SSL_GET, MISC_CHECK 等多种方式)。如果检测到某个真实服务器故障,Keepalived 会将其从 LVS 池中移除;当服务器恢复时,再将其添加回来。
-
-
架构: Keepalived 节点(运行 VRRP 的 MASTER)通常作为 LVS Director ,接收客户端请求,并根据调度算法将请求转发给后端的 Real Servers。客户端访问的是 Keepalived 节点持有的 VIP。
-
-
2、主要配置文件
-
/etc/keepalived/keepalived.conf: 核心配置文件,包含:-
global_defs:全局配置(如通知邮件)。 -
vrrp_script:定义用于跟踪接口或进程状态的自定义脚本。 -
vrrp_instance:定义 VRRP 实例(组 ID、虚拟路由器 ID、状态、优先级、认证、VIP 等)。 -
virtual_server:定义 LVS 虚拟服务器(VIP + 端口)及关联的后端真实服务器池、调度算法和健康检查配置。
-
二、实验
1、前期的配置与安装
安装keepalived

安装完后,先修改配置文件:

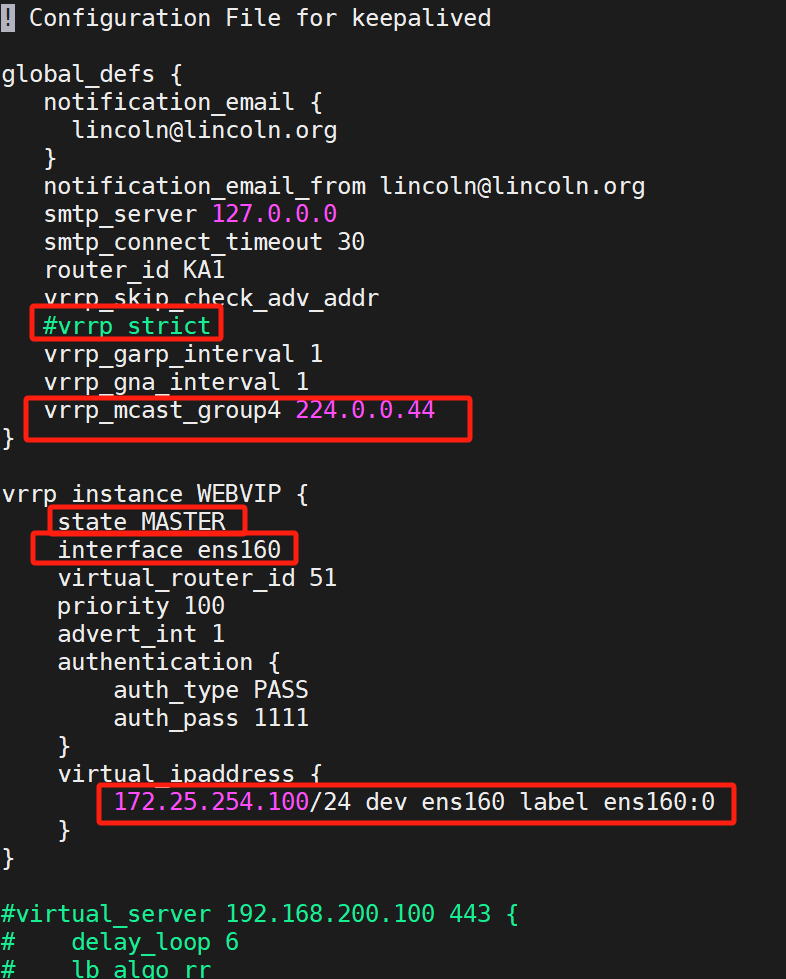
注意:interface那一行是写你的网卡名字,可以ip a查看,写错了的话服务是起不来的
其后面的所有都注释
wq保存
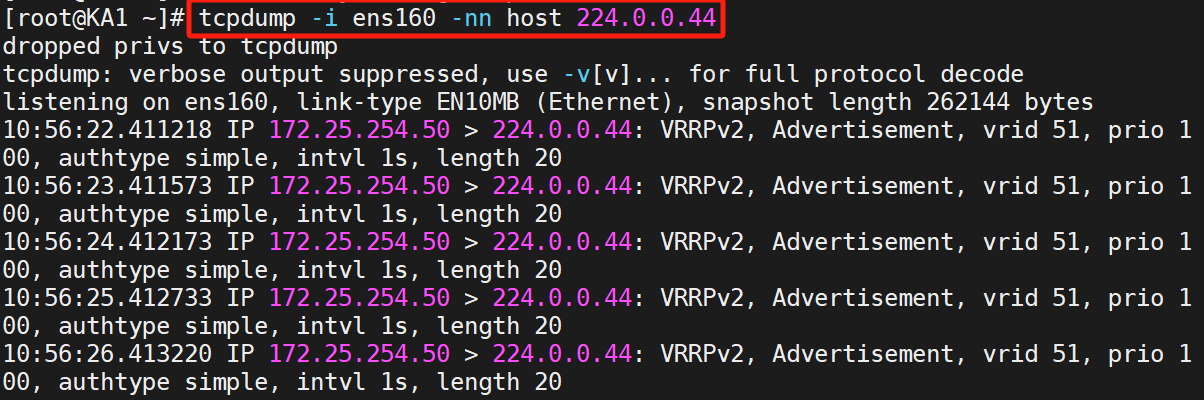
测试
2、独立keepalived日志
将 Keepalived 日志从系统日志(如 /var/log/messages)中分离出来,是生产环境运维的关键实践。
必配独立日志的四大场景
| 场景 | 问题 | 独立日志价值 |
|---|---|---|
| 高频健康检查 | 日志淹没系统日志,掩盖关键告警 | 避免 syslog 洪泛,精准定位问题 |
| 多节点集群排错 | 跨服务器查日志效率低下 | 单节点完整日志流,加速故障定位 |
| 安全审计合规 | 混合日志无法满足等保要求 | 独立存储VIP切换记录,满足审计追溯 |
| 性能瓶颈分析 | 无法统计VRRP报文延迟 | 记录毫秒级事件,定位网络抖动 |
(1)配置独立
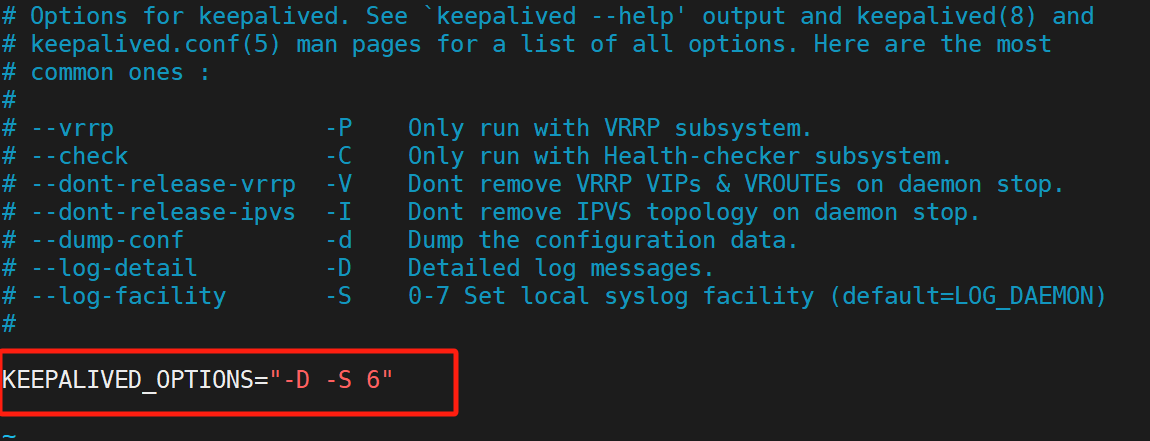

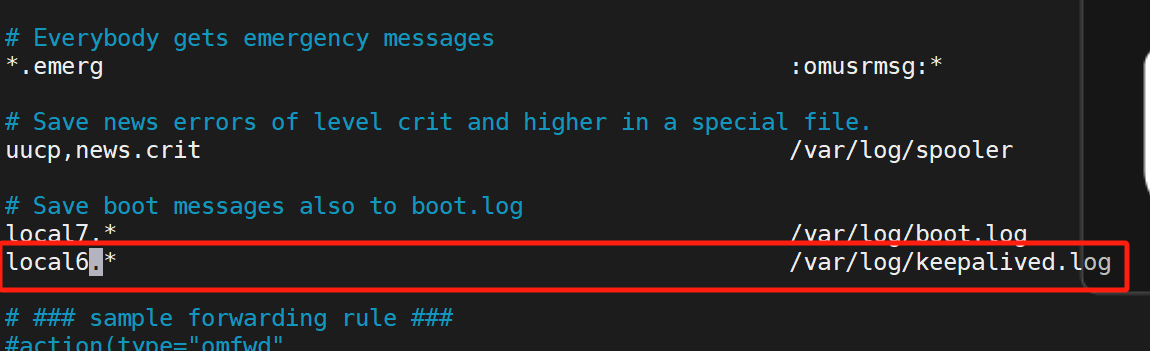

(2)测试
先连通测试,再查看日志
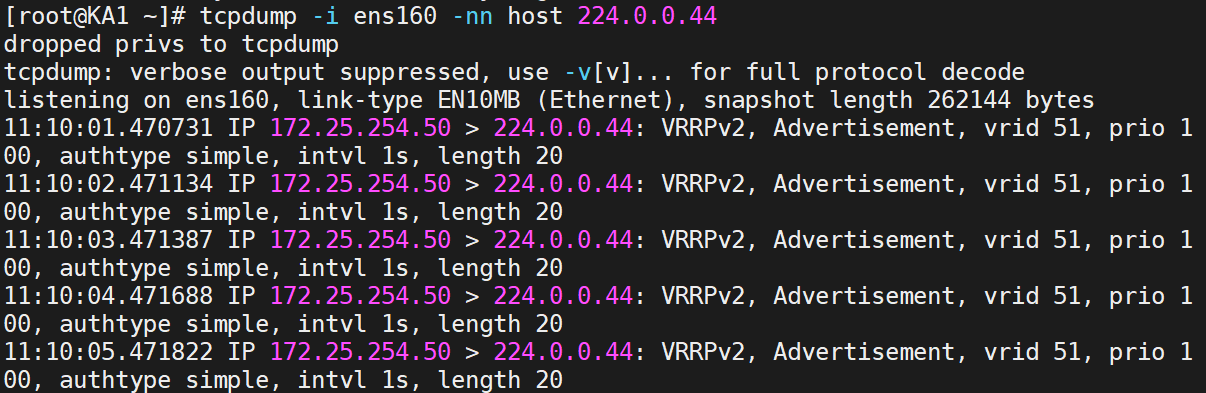
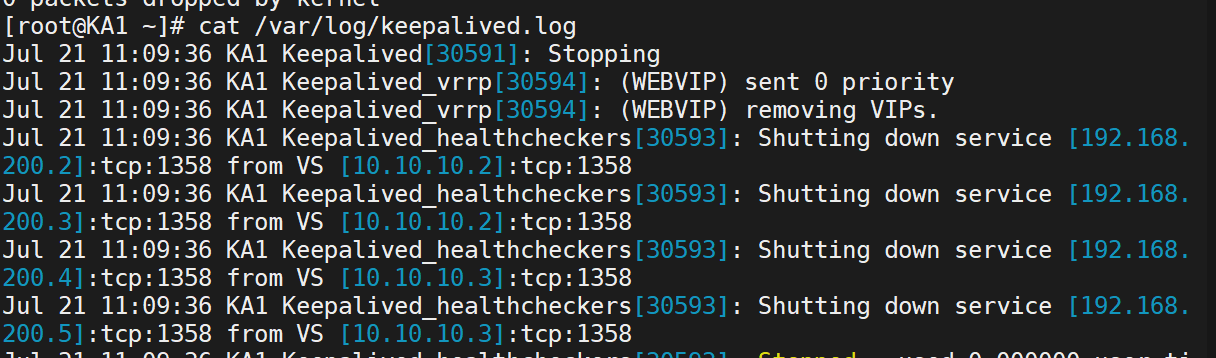
这就是独立keepalived日志
3、独立子配置文件
当生产环境复杂时, /etc/keepalived/keepalived.conf 文件中内容过多,不易管理
将不同集群的配置,比如:不同集群的VIP配置放在独立的子配置文件中利用include 指令可以实现包含子配置文件
在 Keepalived 中配置独立子配置文件是管理复杂架构的核心实践,主要解决以下五大场景的配置痛点:
1. 多 VIP 多业务隔离
场景:单服务器承载多个业务(如 Web/DB 服务),需绑定不同 VIP
2. 多 VRRP 实例(双主/多主)
场景:实现双活架构(如跨机房双主)
3. 差异化健康检查策略
场景:不同业务需要独立检测机制
4. 环境差异化配置(开发/生产)
场景:不同环境使用不同检测阈值
5. 团队协作与权限分离
场景:网络团队管理 VIP,业务团队管理健康检查
子配置文件核心优势
| 优势 | 说明 |
|---|---|
| 故障隔离 | 单配置错误不会导致整个 keepalived 崩溃 |
| 部署效率提升 | 增删 VIP 只需操作独立文件,无需解析主配置 |
| 版本控制友好 | 可独立对 db_vip.conf 进行 Git 管理,不影响其他配置 |
| 动态加载 | 支持 reload 时热加载变更(需主配置开启 enable_dynamic_reload) |
| 安全审计 | 精细化监控关键配置变更(如 VIP 绑定) |
(1)配置独立
设置KA1的配置文件

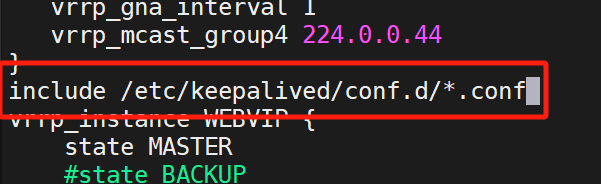

建立一个接收.conf文件的文件

进配置文件,把include下面的这一段(红框框住的)复制,然后删除(目的是为了设置独立子配置文件)
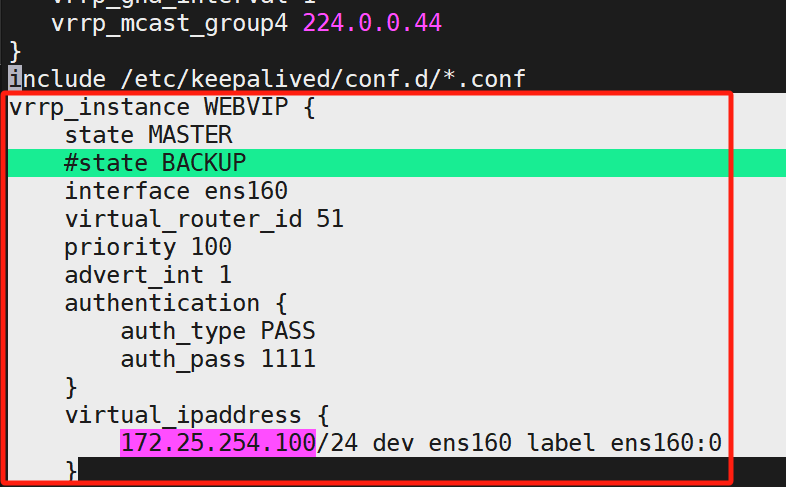
粘贴到这个里面:

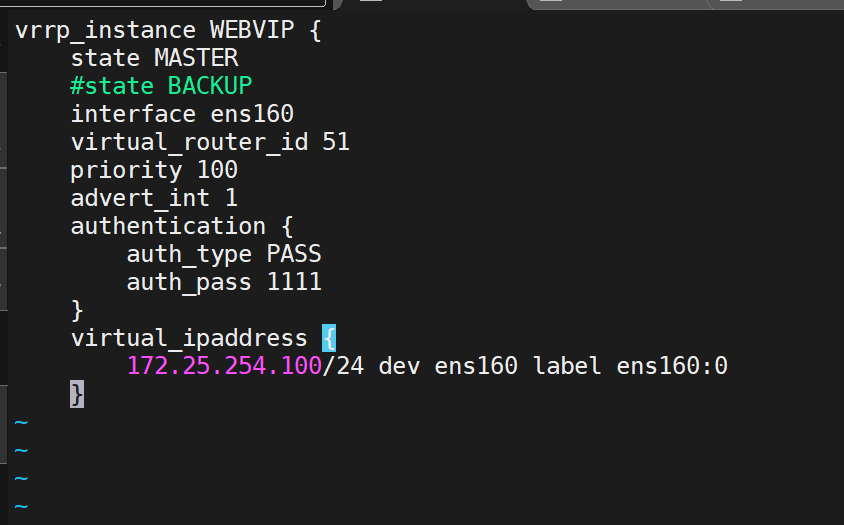
这样就配置了独立子配置文件
(2)还原实验环境
把刚刚更改的全部还原(为了后续实验方便)
全部隐掉
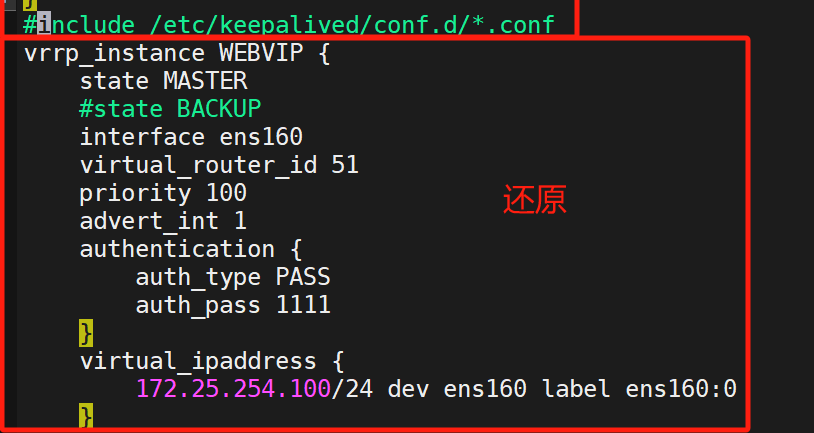
还原完重启


这样就没啥问题了,还原成功
4、延迟抢占
Keepalived 的 延迟抢占(Delayed Preemption) 是一种精细化的故障恢复控制策略,用于解决主节点故障恢复后 立即切换(抢占) 可能引发的服务抖动问题。
抢占延迟模式,即优先级高的主机恢复后,不会立即抢回VIP,而是延迟一段时间(默认300s)再抢回VIP
1. 抢占(Preemption)
-
定义 :高优先级节点恢复后,立即夺回 Master 角色。
-
风险:若服务尚未完全启动,立即切换会导致二次中断。
2. 延迟抢占
-
核心思想 :节点恢复后,等待指定时间再发起抢占,确保服务就绪。
-
价值:提升故障恢复的平滑性。
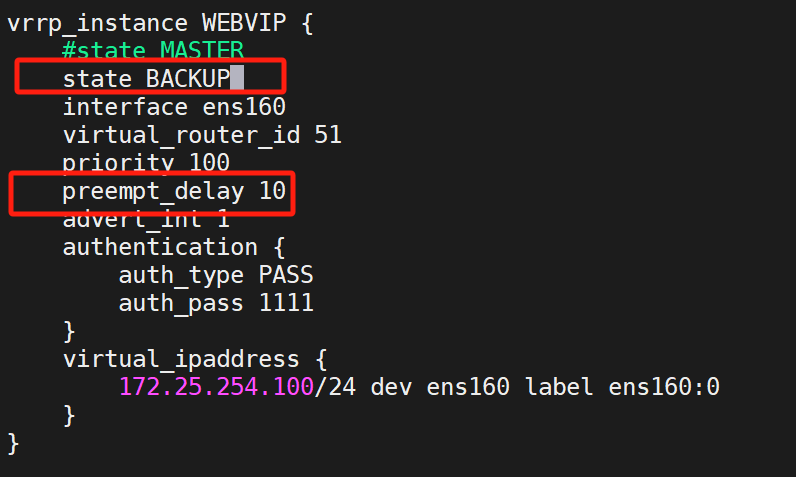
(1)设置配置
两台KA都做
都设置成BACKUP,非抢占模式

(2)测试
先关闭KA1的keepalived服务

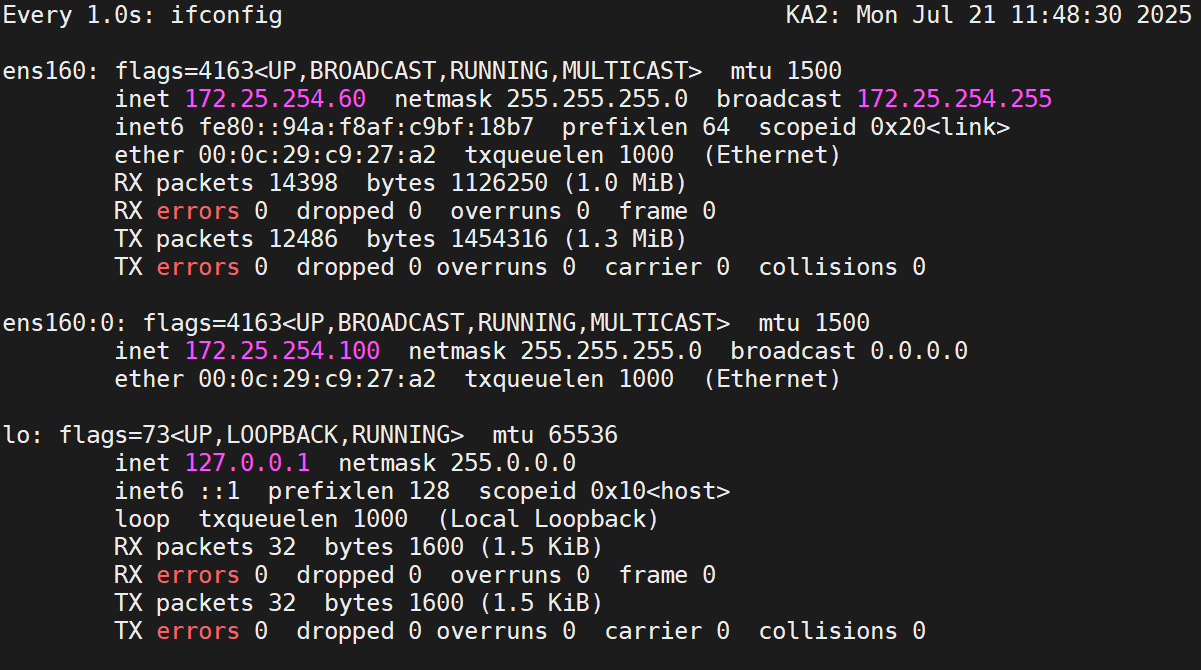
然后开个监视器,监视KA2的变化

目前的监视器是这样:
然后开多个窗口,在KA2上测试

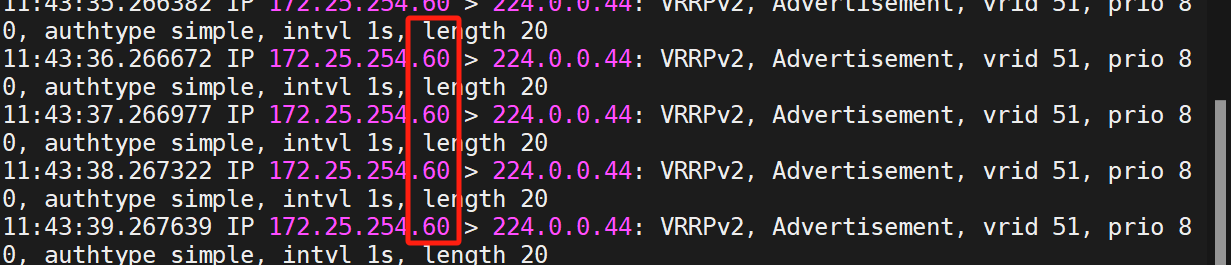
可以发现在KA1关闭的情况下,KA2正在承接服务(都是60)
这时我们再开启KA1的keepalived服务

可以发现监视器变化了
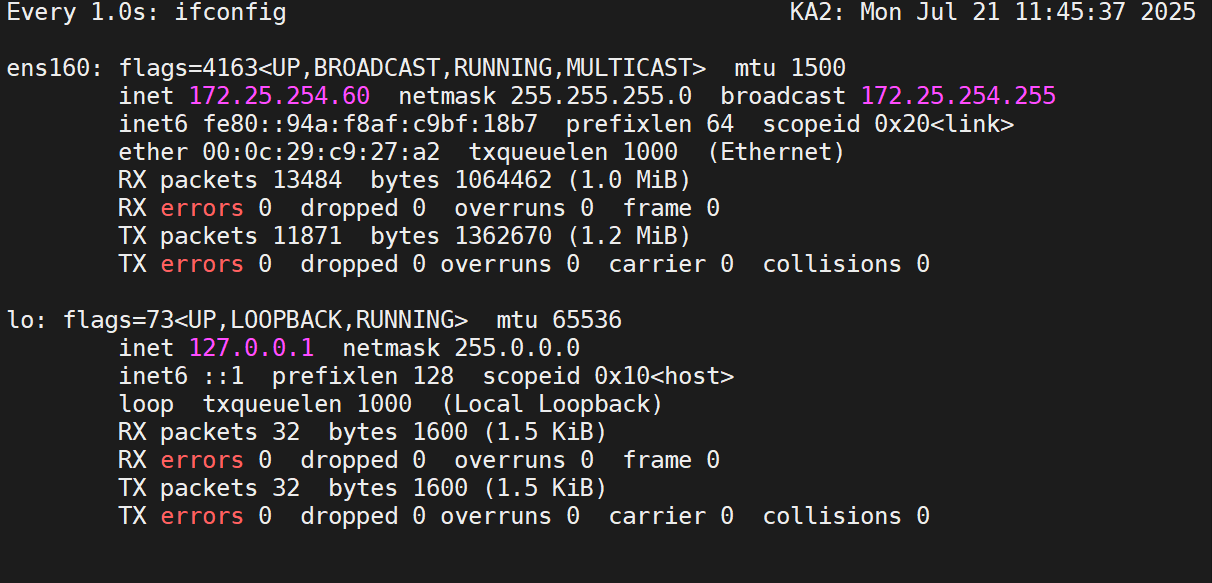
可以看到,10秒过后(即刚刚设定的延迟抢占)由60变成50了,即KA2变成KA1
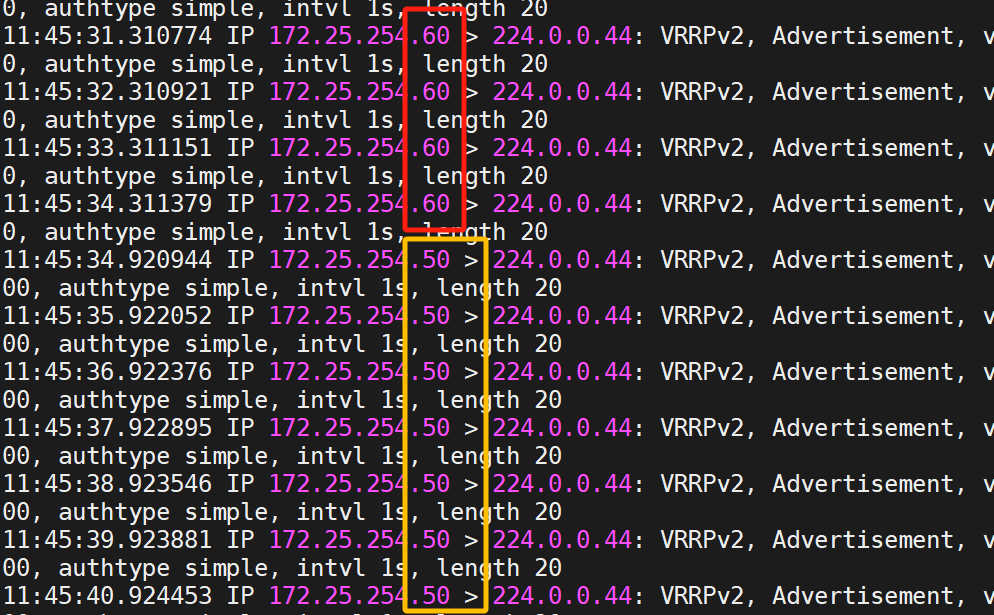
这就是延迟抢占
5、组播变单播
默认keepalived主机之间利用多播相互通告消息,会造成网络拥塞,可以替换成单播,减少网络流量
(1)还原实验环境
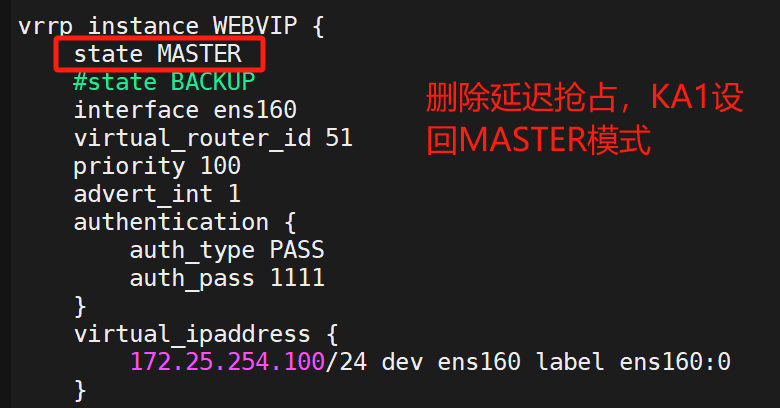

KA2保持不变,就删掉延迟抢占
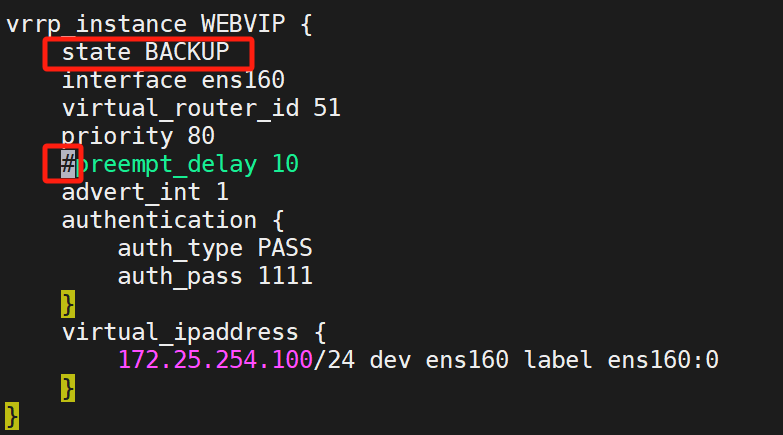

(2)设置单播
KA1与KA2设置单播:
KA1:

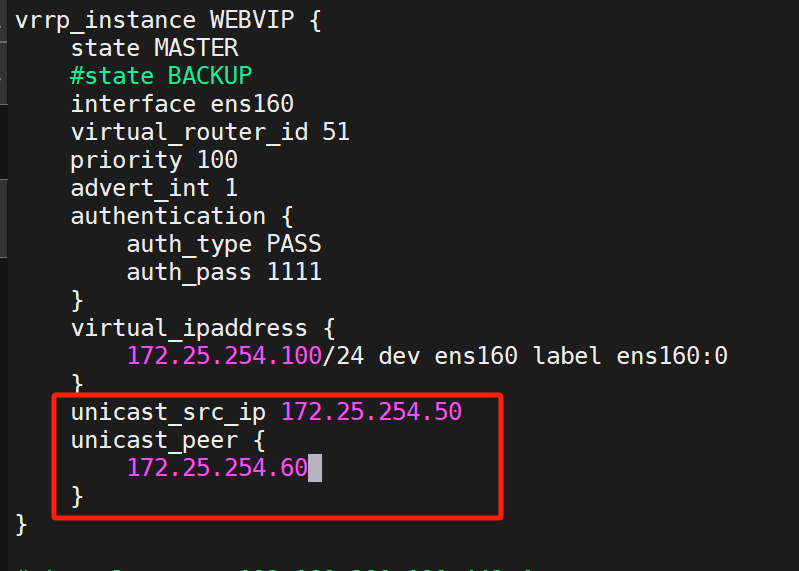

KA2:

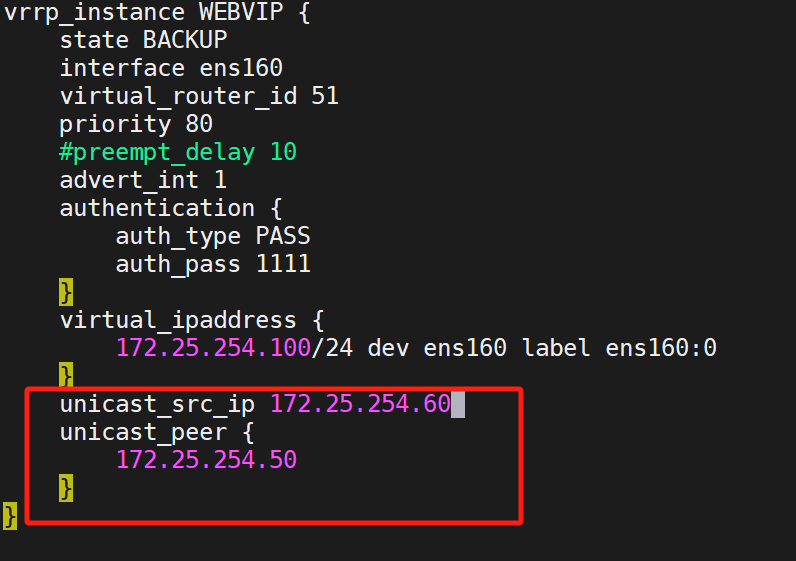

注意KA1与2ip不同,请注意
(3)测试

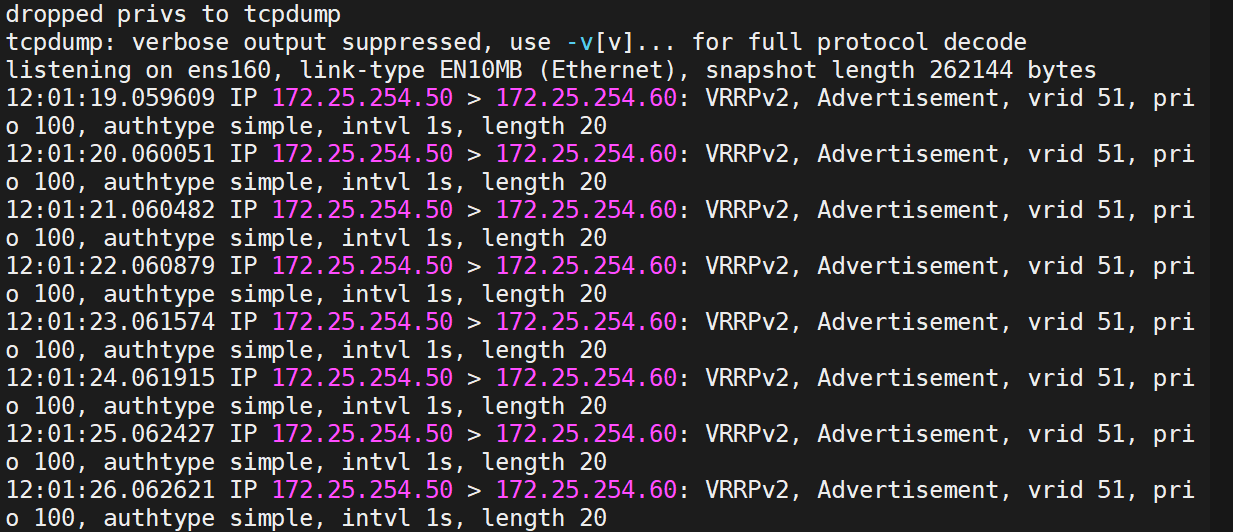
由此,组播变单播
6、邮箱配置
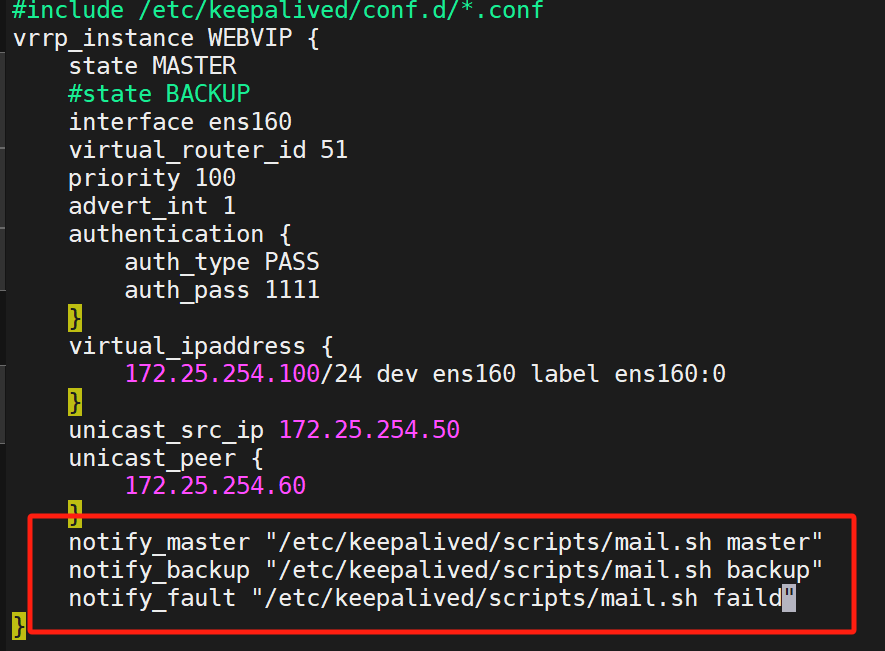
当keepalived的状态变化时,可以自动触发脚本的执行
所以我们做一个综合实验,此实验目的是在两台KA切换主备、或者开启停运时,通过邮箱来通知我们,告知我们他们的模式变化
(1)实验

主机名设置成这种



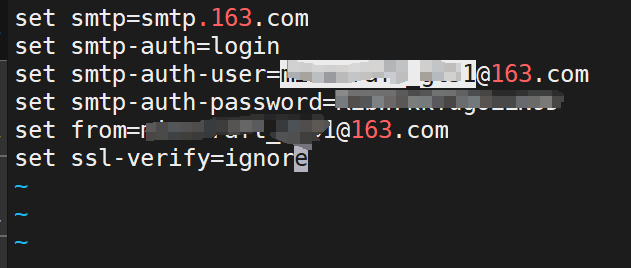
解释:
- set smtp=smtp.163.com ------ 这里的163是因为博主的邮箱是网易的,如果你的是别的,如qq,那就写smtp.qq.com,其他邮箱类似
- set smtp-auth=login ------ 登录
- set smtp-auth-user=XXX@163.com ------ 这里输入自己的邮箱
- set smtp-auth-password=ABCDEFG1234567 ------ 这里的码是你自己的邮箱stmp认证得到的码,待会详细说明怎么获得这个码
- set from=XXX@163.com ------ 这里输入自己的邮箱
- set ssl-verify=ignore ------ 忽略认证
如何获取stmp认证得到的码?(以网易为例)
网页登录你的邮箱官网,点设置里的这个:
点开启,这里博主启动过了,所以显示的是关闭,你们开启上面的那个IMAP/SMTP的,不是红框的那个
然后安装他的提示继续
之后就是输入验证码那些,完成后就会出现那个码了,复制到文件里

(3)测试

然后在自己的邮箱里找未读
测试成功
(4)实战例子:实现keepalived状态切换的通知邮箱脚本


进入输入这些:
#!/bin/bash
mail_dest='XXX@163.com'
mail_send()
{
mail_subj="$HOSTNAME to be $1 vip 转移"
mail_mess="`date +%F\ %T`: vrrp 转移,$HOSTNAME 变为 $1"
echo "$mail_mess" | mail -s "$mail_subj" $mail_dest
}
case $1 in
master)
mail_send master
;;
backup)
mail_send backup
;;
fault)
mail_send fault
;;
*)
exit 1
;;
esac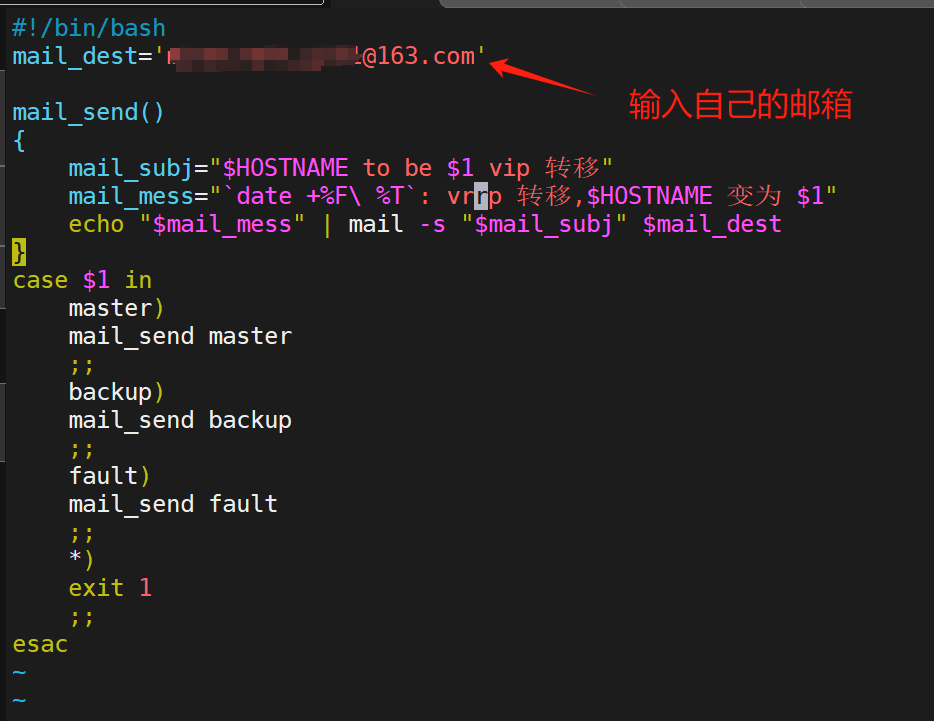
添加可执行权限


设完成之后,就会发现邮箱立马收到了邮件:
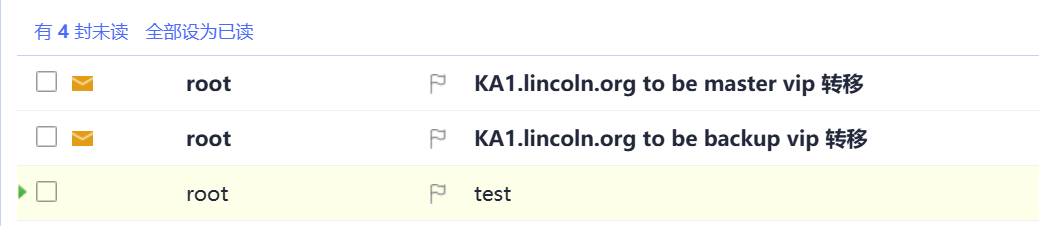
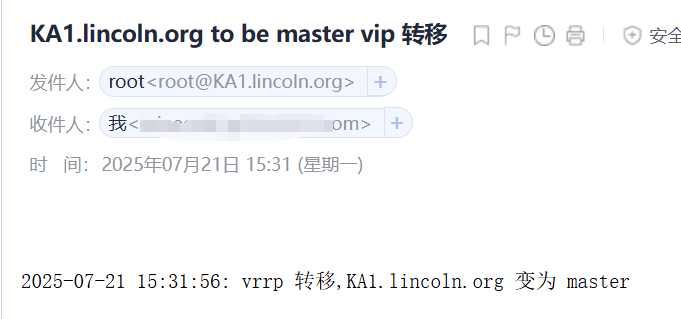
说明成功了,每当服务器主备转换,还有开启停机时,都会收到邮件
这个实验完成后,建议把设置还原:
7、RS的初步配置
我们介绍完了keepalived的基础,准备开始搞Real Server的配置,且为了后面的实验,我们也要把RS做了
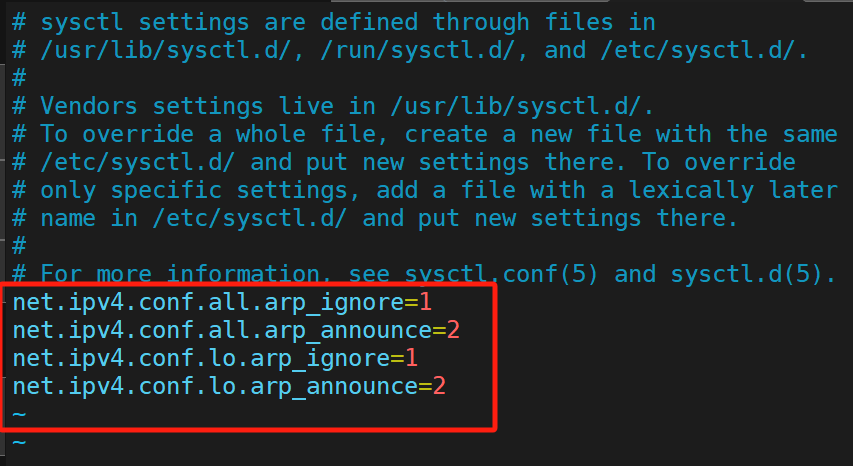
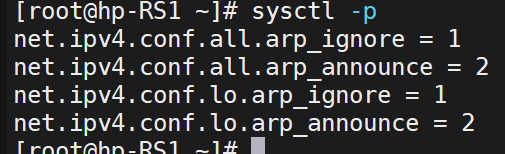
(1)添加新ip
两个RS都做:


(2)配置KA1/2
两个KA都要做:
安装ipvsadm(两台KA都要)


virtual_server 172.25.254.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 172.25.254.10 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 2
retry 3
delay_before_retry 3
}
}
real_server 172.25.254.20 80 {
weight 1
TCP_CHECK {
connect_timeout 2
retry 3
delay_before_retry 3
connect_port 80
}
}
}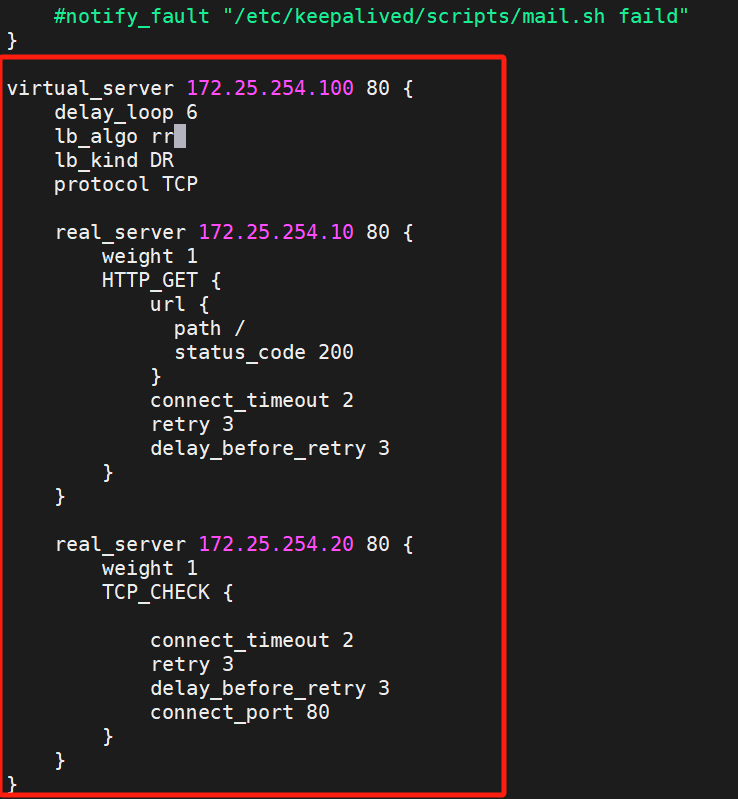

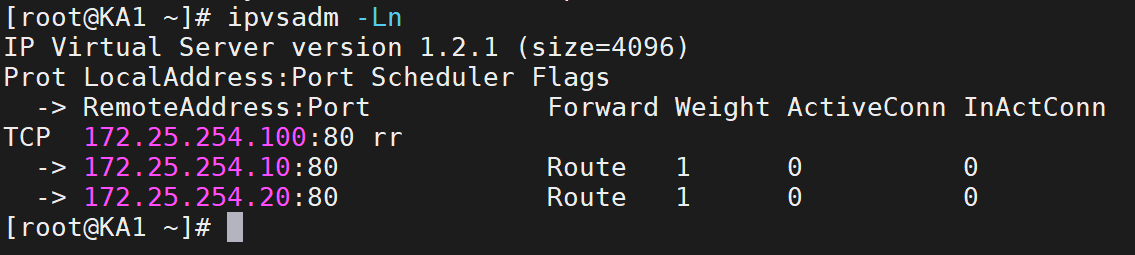
这样就有策略了
(3)测试
在KA1查看一下:
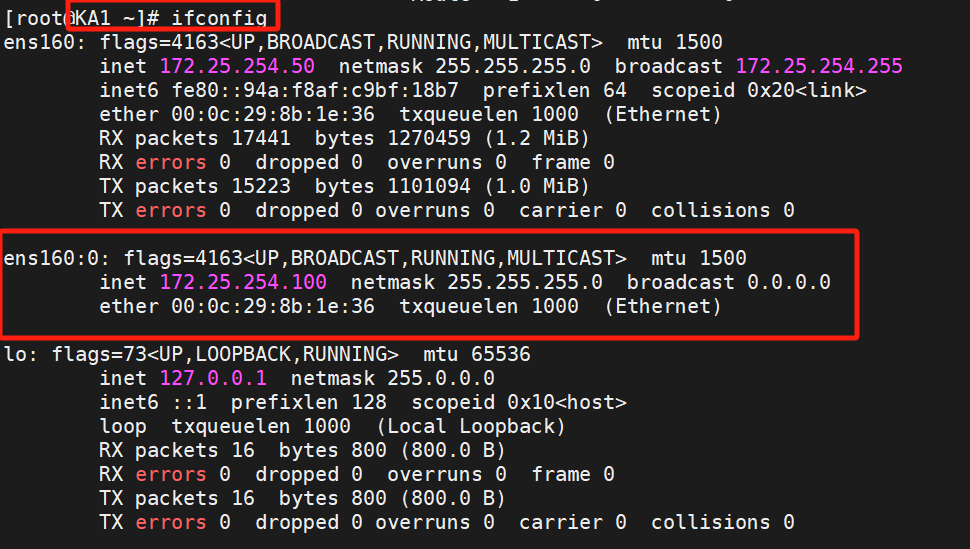
可以看到KA1是100ip的主,KA2是备
我们现在停掉KA1的keepalived,看它会不会自动转到KA2这个备上:

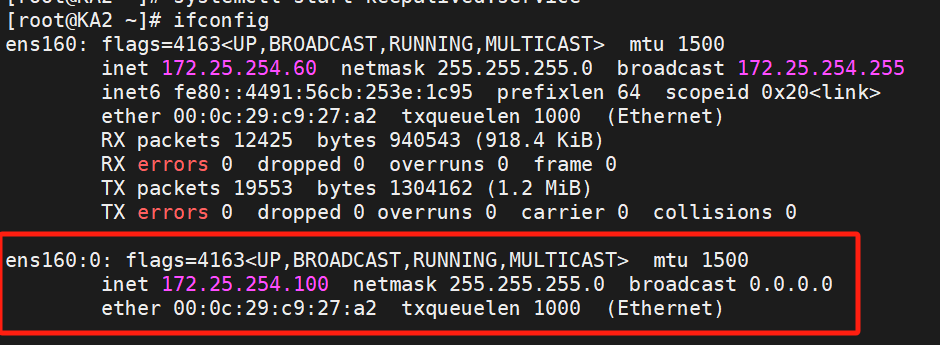
可以看到100ip已经从KA1转移到KA2这个备了
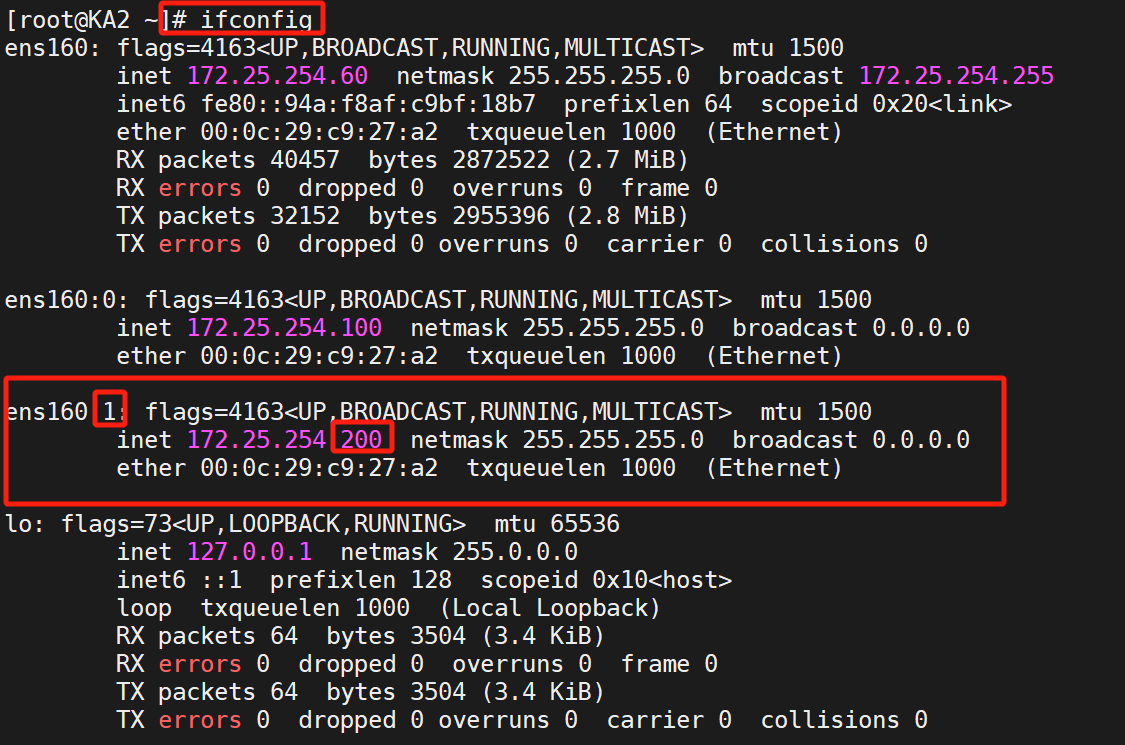
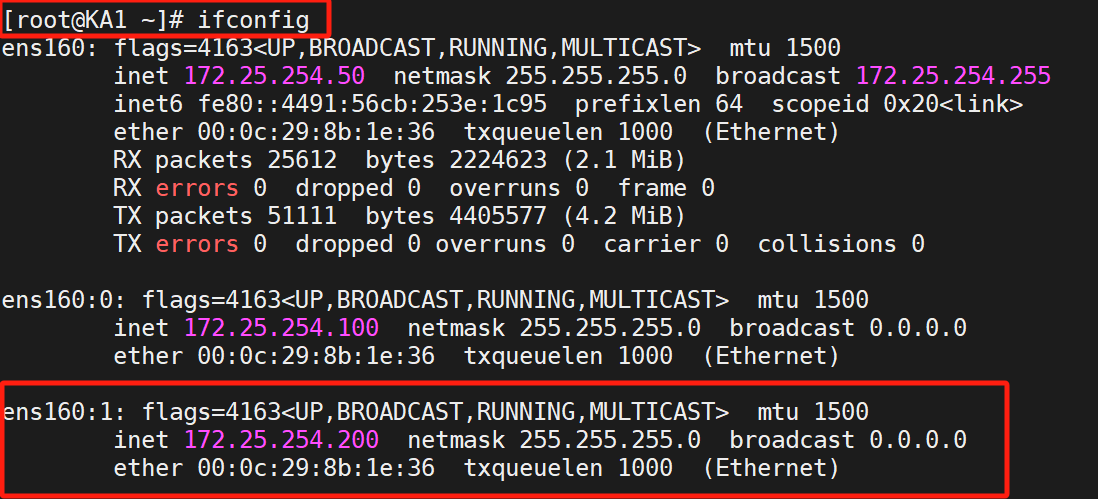
8、双主架构
(1)概念
"双主"(Dual-Master)在技术领域通常指两种不同场景的高可用架构,需根据上下文区分理解。
master/slave的单主架构,同一时间只有一个Keepalived对外提供服务,此主机繁忙,而另一台主机却很空闲,利用率低下,可以使用master/master的双主架构,解决此问题。
master/master 的双主架构:
即将两个或以上VIP分别运行在不同的keepalived服务器,以实现服务器并行提供web访问的目的,提高服务器资源利用率
(2)实验
我们做的是双主组播,所以
关掉单播
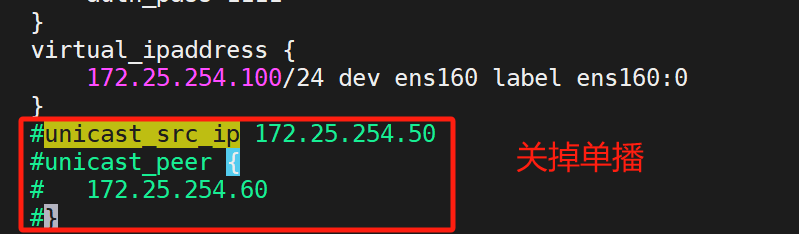
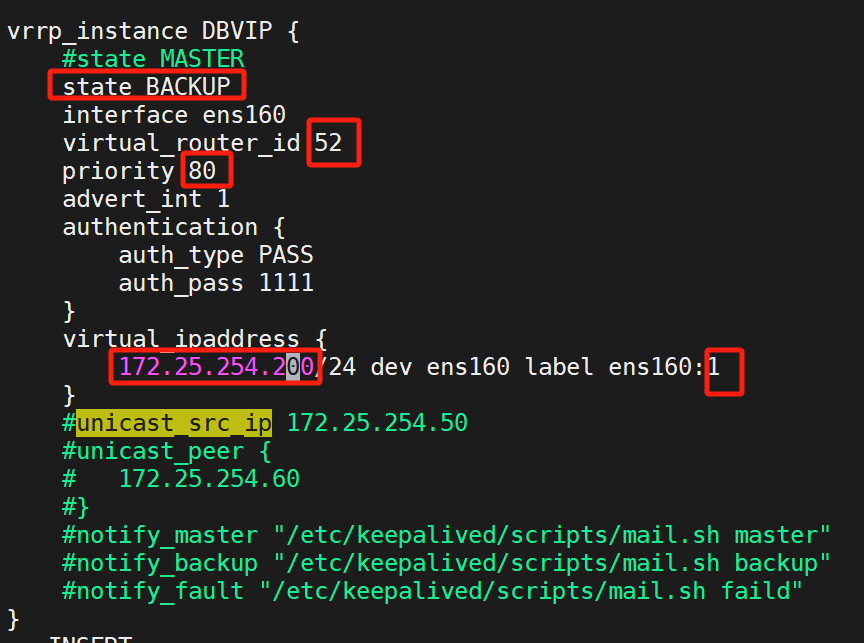
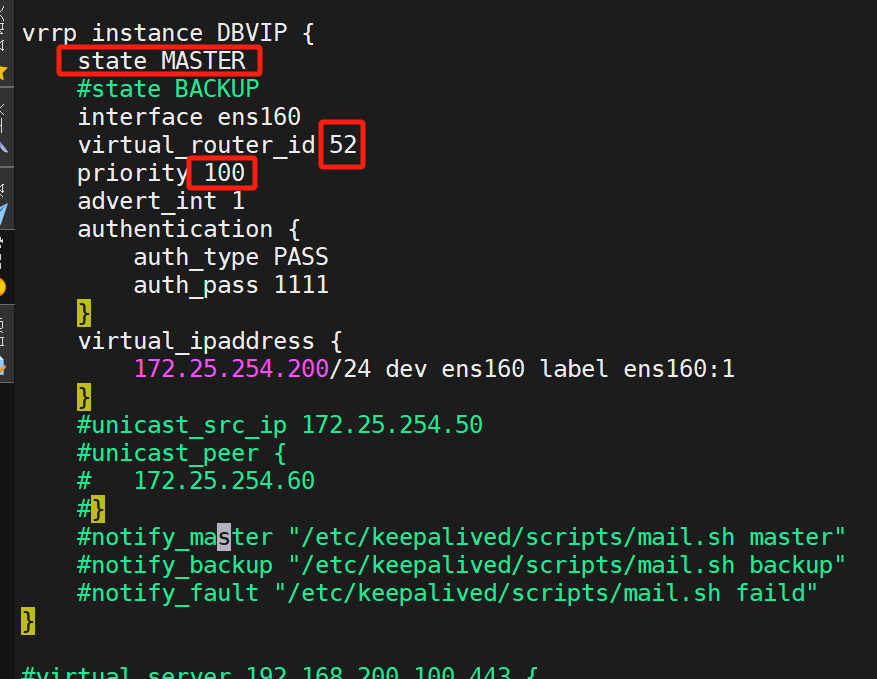
复制多一份上面的模板,改变这些:
让KA1做DBVIP的BACKUP
KA2是DBVIP的master:
(3)测试
在KA2上看,就能发现另一个组播,这就是双主
如果我们把KA2的keepalived关掉

那么就会变成KA1为MASTER:
测试成功
(4)数据库mariadb的双主实验
1)两台RS配置新的ip与启动mariadb服务
两台RS都要做,配置命令相同

然后开启两台RS的mariadb服务,最好systemctl status查看一下mariadb的服务是否开启
两台RS都做,配置命令相同


再搞个开机自启
两台RS都做,配置命令相同

2)两台KA配置数据库双主
两台KA都要做,配置命令相同

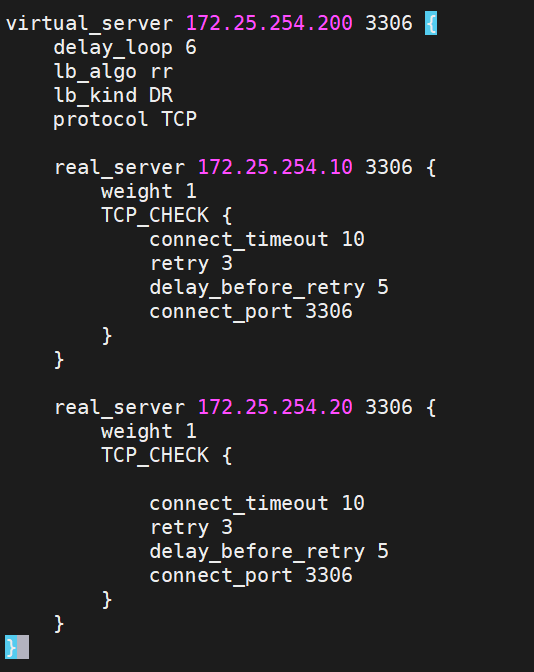
检测一遍,然后重启

查看一下策略
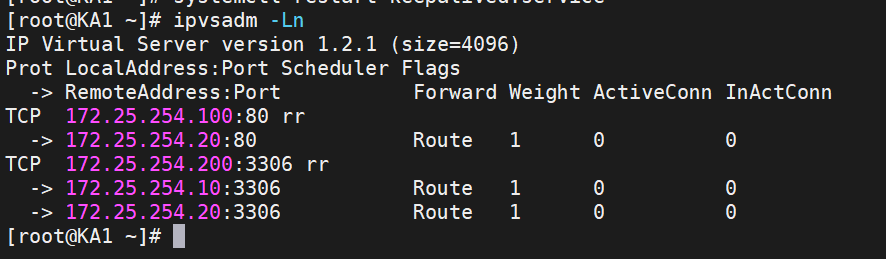
可以发现已有3306端口的策略
3)测试
在Client测试机上测试(该机子已经在先前博客出现过,配置了mariadb)
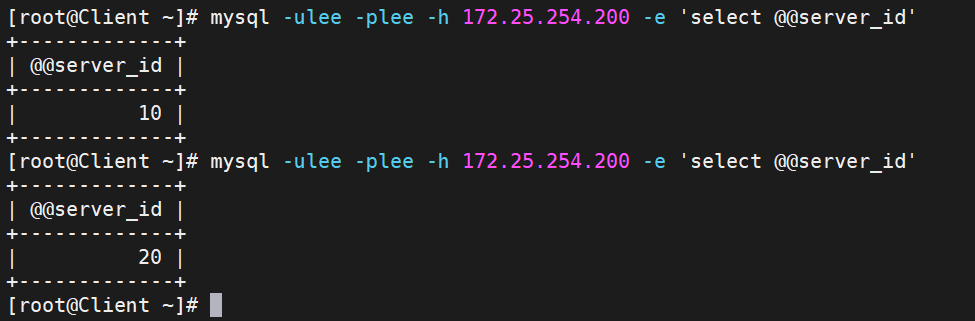
mysql -ulee -plee -h 172.25.254.200 -e 'select @@server_id'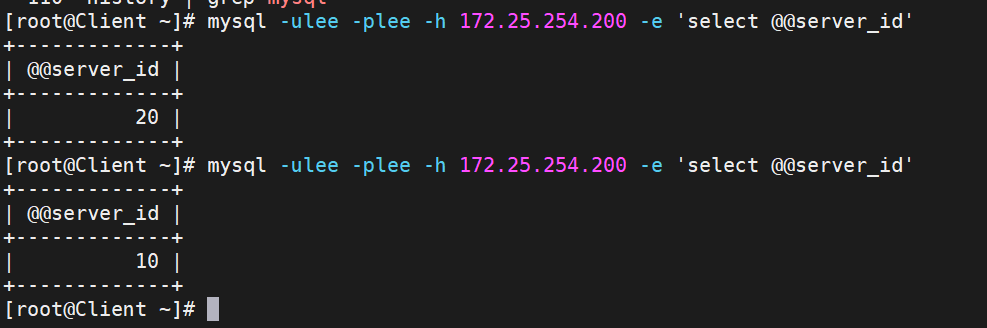
关掉RS2的mariadb服务再测试

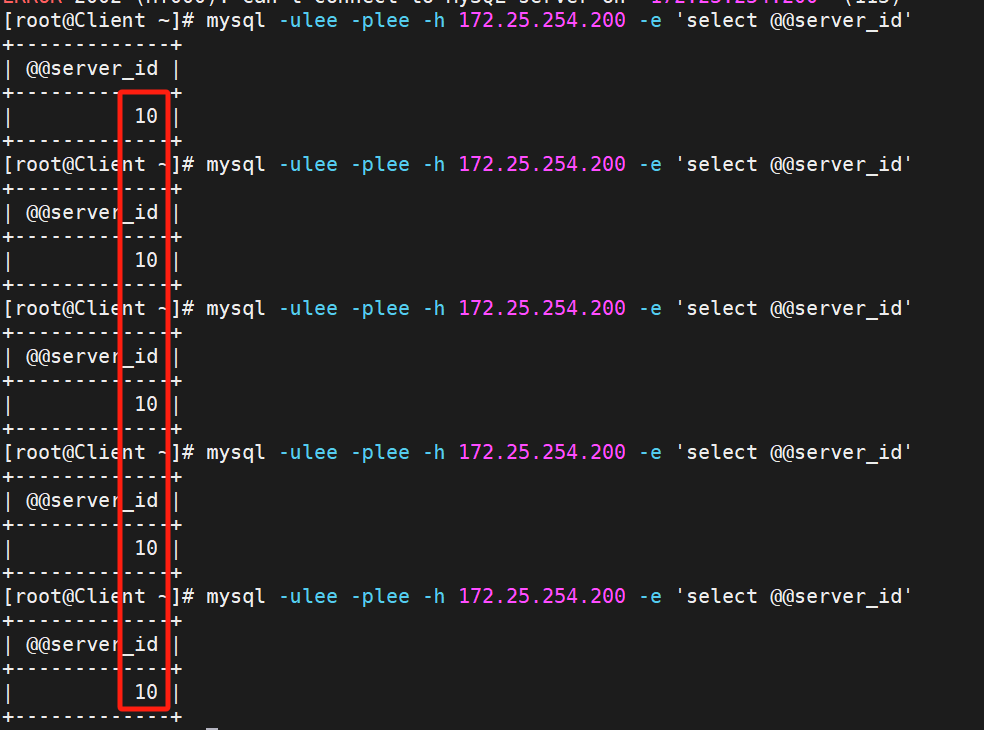
过一会,再测试就会发现只剩RS1的10
重新开开

就又能轮询了
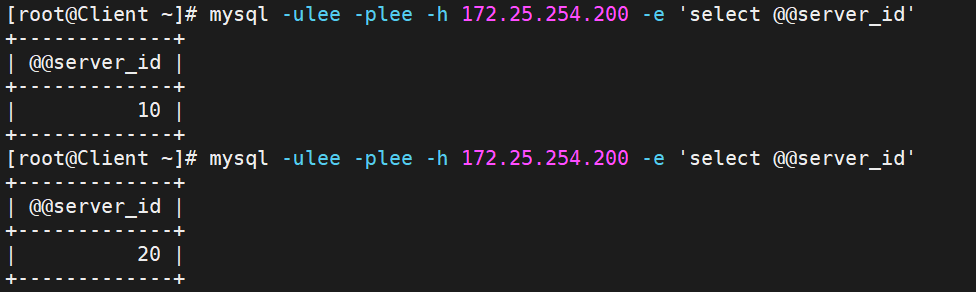
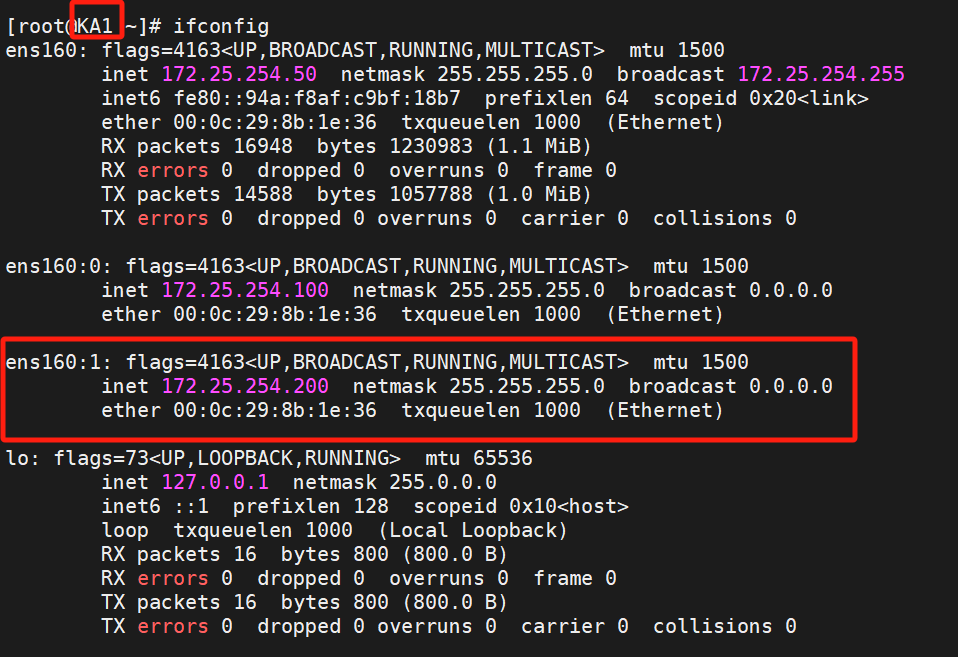
在KA2查看一下,就能看到200ip的主是KA2
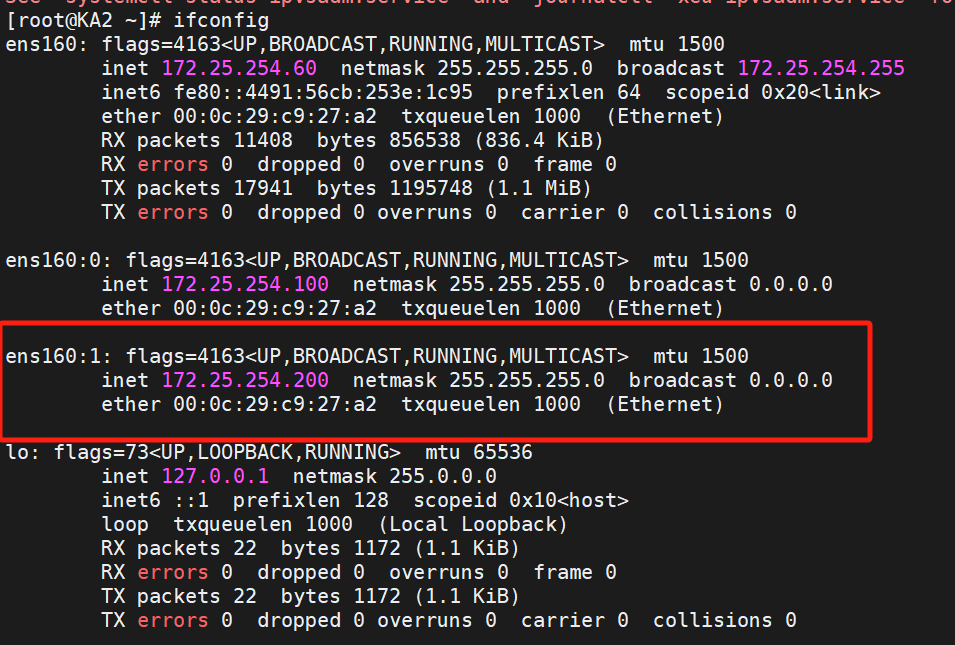
所以我们:
关闭KA2的keepalived服务再测试

这是我们发现服务能够继续,因为服务已经从主迁移到备了,不影响
测试完记得重新起开

9、VRRP Script
(1)概念
VRRP Script 是 Keepalived 中一个极其重要的功能模块,它允许你通过自定义脚本 来动态监控系统状态(如服务进程、资源利用率、网络连通性等),并将监控结果反馈给 VRRP 协议栈,从而影响 Master 节点的选举优先级 或触发状态切换 。它是实现基于应用健康状态的高可用性(HA) 的核心机制。
1)核心作用与原理
-
扩展监控能力:
-
默认的 VRRP 只能监控 Keepalived 守护进程本身和网络接口的存活状态。
-
VRRP Script 让你能够监控任何你关心的东西:例如 Nginx/MySQL 进程是否在运行、Web 页面是否可访问、磁盘空间是否不足、CPU 负载是否过高、到某个关键服务的网络是否通畅等。
-
-
动态调整优先级:
-
你定义一个脚本 (
vrrp_script块) 和一个监控间隔 (interval)。 -
Keepalived 会周期性地(每隔
interval秒)执行这个脚本。 -
脚本的退出状态码 (Exit Code) 决定了监控结果:
-
0(成功 / OK) : 表示被监控项健康。脚本可以什么都不做直接exit 0。 -
1(警告 / WARN) : 通常 也被视为健康(取决于配置),但可能用于记录日志或轻微通知。(实践中较少严格区分 1 和 0 的效果,主要关注非 0 是否触发故障) -
>1(错误 / FAIL): 表示被监控项不健康。
-
-
根据脚本的退出码(特别是非 0),Keepalived 可以动态调整 该节点在 VRRP 实例 (
vrrp_instance) 中的priority值。
-
-
触发状态切换:
-
当一个节点的优先级因为
vrrp_script检测到故障而降低时:-
如果它原来是 Master ,并且降低后的优先级低于某个 Backup 节点的优先级(通常是初始优先级),那么 Backup 节点会感知到 Master 优先级变低。
-
Backup 节点(现在拥有更高优先级)会发起选举,将自己提升为新的 Master,并接管 Virtual IP (VIP)。
-
-
当故障恢复,脚本返回
0时:-
节点的优先级会恢复到初始值。
-
如果这个节点现在的优先级高于 当前 Master 的优先级(通常是因为原 Master 可能也降权了或者这个节点初始优先级就很高),它可能会重新夺回 Master 身份(取决于
nopreempt配置)。
-
-
2)配置选项解释
vrrp_script <SCRIPT_NAME> {
script "<COMMAND_OR_PATH_TO_SCRIPT>" # 要执行的命令或脚本的完整路径
interval <SECONDS> # 执行间隔(秒),如 2, 5, 10
timeout <SECONDS> # 脚本执行超时时间(秒),超时视为失败
weight <-254 TO 254> # 权重值(最重要!决定优先级如何变化)
fall <INTEGER> # 连续失败多少次才认为故障 (默认 1)
rise <INTEGER> # 连续成功多少次才认为恢复 (默认 1)
user <USERNAME> [GROUPNAME] # 以哪个用户(组)身份运行脚本(可选,默认 root)
}
script: 核心指令。可以是:
一个简单的 shell 命令:
script "killall -0 nginx"(检查 nginx 进程是否存在)一个自定义脚本的完整路径:
script "/usr/local/bin/check_mysql.sh" (路径情况最普遍)脚本需要有可执行权限 (
chmod +x)。
interval: 多久执行一次监控脚本。太短增加负担,太长延迟切换。常用 2-10 秒。
timeout: 脚本必须在此时长内完成,否则强制终止并视为失败。应略大于脚本预期执行时间。
weight(核心参数!): 脚本执行结果如何影响优先级 (priority)。
正值 (e.g.,
weight 20):
脚本成功 (
exit 0): 给当前优先级 加上weight值。脚本失败 (
exit > 0): 不改变 当前优先级。作用 : 健康时提高 本节点优先级,更容易成为/保持 Master。故障时只是失去"加分",如果初始优先级够高,可能还是 Master(需结合
fall/rise判断)。负值 (e.g.,
weight -20):
脚本成功 (
exit 0): 不改变 当前优先级。脚本失败 (
exit > 0)): 给当前优先级 加上weight值(即减去绝对值)。作用 : 健康是常态,不额外加分。故障时直接惩罚(降权) 。这是最常用、最直观的方式!故障时优先级降低,更容易被 Backup 超越。
值的大小: 绝对值通常设置为大于 VRRP 实例中 Master 和 Backup 之间初始优先级的差值。例如 Master 初始 prio=100, Backup=90,差值=10。那么
weight -25是合理的,这样 Backup 在 Master 故障后优先级 (90) 会高于降权后的 Master (100 - 25 = 75)。如果weight绝对值太小(比如 -5),降权后 Master(95) 仍高于 Backup(90),就不会切换!
fall: 脚本连续失败多少次才触发降权操作(认为真的故障了)。默认为 1(一次失败就降权)。设置为 2 或 3 可以防止短暂抖动导致的误切换。
rise: 脚本连续成功多少次才触发恢复操作(认为真的恢复了)。默认为 1(一次成功就恢复)。设置为 2 或 3 可以确保服务稳定恢复后才提升优先级/尝试抢占。
user: 以非 root 用户运行脚本,提高安全性(如果脚本不需要 root 权限)。
(2)实验------通过脚本控制haproxy(实现HAProxy高可用)
1)注释之前配置的virtual-server配置
两台KA都配置

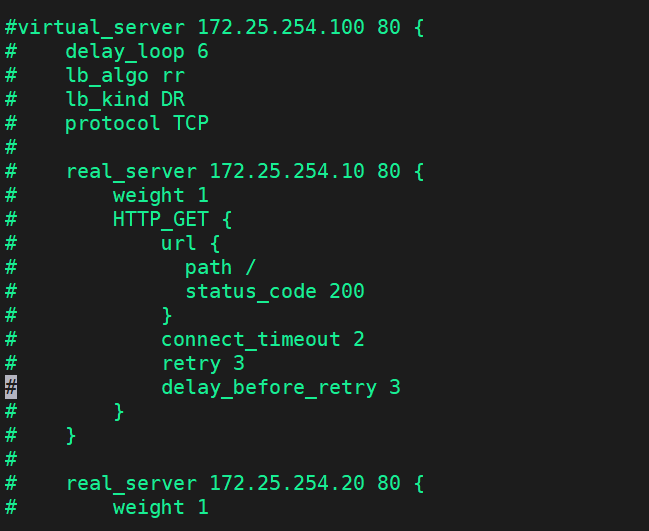

只要是virtual-server开头的都注释掉,两台KA都配置
注释后ipvsadm看一下

像这样没有策略就行
2)安装haproxy和编辑其配置文件
两台KA都安装

进入配置文件,修改编辑:

先注释掉后面这些:
创建新的Listen
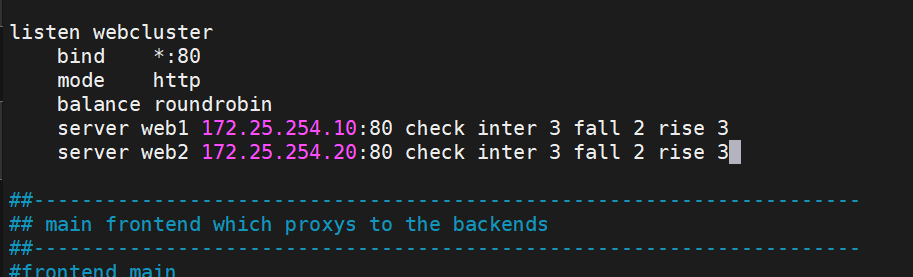

配置开机自启

KA1与2配置命令相同,记得KA2也配置
2)配置非MASTER也有ip
两台KA都配置
复制红框

然后echo写进去:

执行一下

另一台KA一样配置
配置完后,查看一下haproxy的80端口


3)编写脚本

注意:这个keepalived底下的scripts目录是博主自己建立的,你们在做的时候自己记得建立
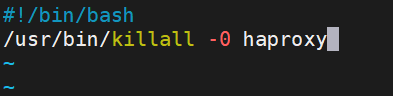
这个脚本写的是检测haproxy服务活不活的命令
wq
给脚本可执行权限

确保所有主机的SELinux和火墙是关闭状态
进入keepalived配置文件配置脚本
在KA1上配置
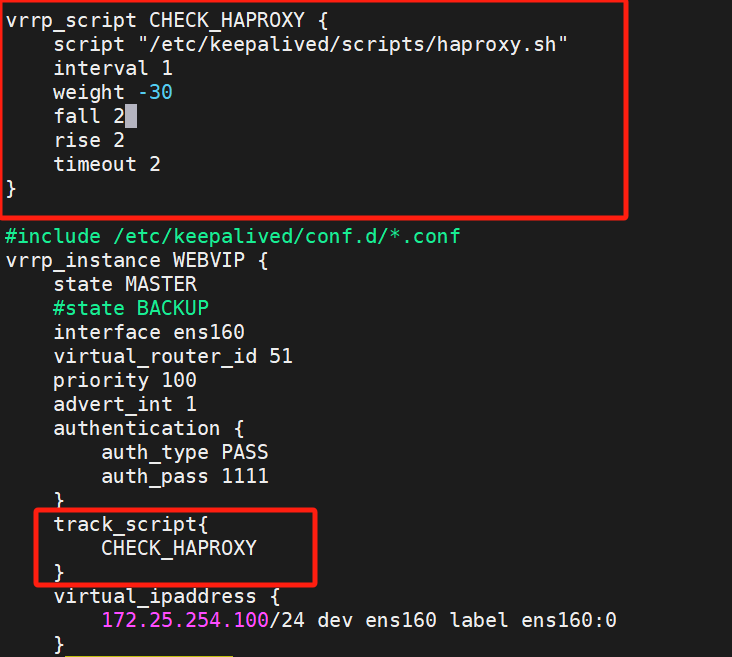
配置完重启:

4)测试
然后运行脚本

此时我们没停止KA1的haproxy时,脚本的返回值是正常,即为0

此时,我们关闭KA1的haproxy服务

脚本就会检测到haproxy停止,这时脚本的返回值应该是变成1
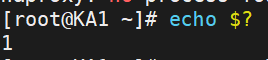
这样就说明脚本运行成功
测试完记得把KA1的haproxy开回来
