温馨提示:
本篇文章已同步至"AI专题精讲 " 一种集合式方法:实现高效且有效的大语言模型零样本排序
摘要
我们提出了一种基于大语言模型(LLMs)的新颖零样本文档排序方法:集合式提示(Setwise prompting)方法。我们的方法补充了现有的用于LLM零样本排序的提示方法:逐点式(Pointwise)、成对式(Pairwise)和列表式(Listwise)。通过首次在一致的实验框架下进行的对比评估,并综合考虑模型大小、token消耗、延迟等因素,我们表明现有方法在效果和效率之间存在固有的权衡。我们发现,虽然逐点式方法在效率上得分较高,但其效果表现较差。相反,成对式方法表现出更优的排序效果,但会带来较高的计算开销。而我们的集合式方法在排序过程中减少了LLM调用次数和提示token的消耗,相较于以往方法大幅提升了LLM零样本排序的效率,同时保持了高水平的排序效果。我们已将代码和实验结果公开:https://github.com/ielab/llm-rankers
CCS 概念
• 信息系统 → 语言模型
关键词
大语言模型零样本排序、集合式提示、排序算法
ACM引用格式
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024. A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models. 收录于第47届国际ACM SIGIR信息检索研究与发展会议论文集(SIGIR '24),2024年7月14日至18日,美国华盛顿。ACM出版社,纽约,美国,共10页。https://doi.org/10.1145/3626772.3657813
1 引言
大语言模型(LLMs),如 GPT-3 3、FlanT5 33、Gemini 24、LLaMa2 27 和 PaLM 4,在零样本设置下在多种自然语言处理任务中表现出极强的能力 1, 3, 10, 32。值得注意的是,这些LLMs也被应用于零样本文档排序任务 12, 15, 20--23。在零样本排序任务中使用LLMs的方法大致可以分为三类:逐点式(Pointwise)12, 22, 37、列表式(Listwise)15, 20, 23 和成对式(Pairwise)21。这些方法采用不同的提示策略,引导LLM对每个候选文档输出相关性评分并据此排序。与传统的神经排序方法 14 相比,这些基于LLM的排序方法无需额外的有监督微调,同时展现出强大的零样本排序能力。尽管这些方法在各自研究中都取得了成功,但文献中缺乏对这些方法在完全一致的实验框架下,特别是在效率方面的公平比较。这包括使用相同大小的LLM、相同的评估基准和计算资源。我们认为建立一个严谨的评估框架来比较这些LLM零样本排序方法是非常关键的,只有这样才能对它们的效果与效率作出有意义的比较结论。
因此,在本文中,我们首先在一致的实验环境下对现有所有方法进行了系统评估。除了评估排序效果之外,我们还比较了这些方法在计算开销和查询延迟方面的效率。我们的研究发现,成对式方法在排序效果方面最优,但即使借助排序算法来提高效率,其效率依然不足。相比之下,逐点式方法在效率上最为出色,但在排序效果上明显落后于其他方法。列表式方法依赖于按顺序生成文档标签,可以在效率与效果之间取得一定平衡,但这一点在很大程度上取决于其配置、实现方式和评估数据集(这也强调了在多种设置下彻底评估模型的重要性)。总体而言,我们的综合评估结果揭示了各类LLM零样本排序方法的优劣势,为现实应用场景中方法的选择提供了有价值的参考。
在考察了不同方法在效率与效果权衡上的表现之后,我们着手设计一种兼顾效率与效果的方法。我们的思路是以最有效的成对式方法为基础,提升其效率(而不严重牺牲其效果)。最终我们提出了一种新颖的集合式提示方法。该方法的灵感来自我们观察到:相比于成对比较,排序算法可以通过一次比较多个文档来加速过程。

我们的 Setwise prompting 方法指示LLM从一组候选文档中选择与查询最相关的文档。这一简单的调整使排序算法能够在每一步中对两个以上的候选文档进行相关性偏好推断,从而显著减少所需的比较次数;这带来了计算资源的显著节约。此外,除了对 Pairwise 方法的改进外,Setwise prompting 还允许利用模型输出的logits来估计文档标签排名的概率,这在现有的 Listwise 方法中是不可行的,后者仅依赖于生成文档标签排序------这一过程既缓慢又效果较差。我们在相同的实验设置下评估了 Setwise 与其他现有方法,以提供清晰且一致的对比结果。我们的实验结果表明,将 Setwise prompting 融入现有方法能够显著提升 Pairwise 与 Listwise 方法的效率。此外,Setwise 排序增强了 Pairwise 与 Listwise 方法在初始排序顺序变化下的鲁棒性:无论用于排序的 top-k 文档最初顺序如何,我们的方法都能提供稳定且有效的结果。这不同于其他方法,它们对初始顺序非常敏感。
总之,本文对我们对基于LLM的零样本排序方法的理解带来了三个主要贡献:
(1) 我们提出了一种创新的 Setwise prompting 方法,增强了 Pairwise 方法中所采用的排序算法,从而实现了高度高效的LLM零样本排序;
(2) 我们在严格且一致的实验条件下系统评估了所有现有的LLM零样本排序方法以及我们提出的 Setwise 方法,包括此前文献中被忽视的效率对比。我们在主流的零样本文档排序基准上进行的全面实证评估为从业者提供了有价值的参考;
(3) 我们进一步将 Setwise prompting 方法的排序计算方式扩展至 Listwise 方法,利用模型输出的logits来估计排序的概率,从而实现更有效且高效的 Listwise 零样本排序。
2 背景与相关工作
当前主要存在三类使用LLM进行零样本文档排序的提示方法:逐点式(Pointwise)12, 22、列表式(Listwise)15, 20, 23 和成对式(Pairwise)21。本节中我们将详细介绍这些方法,并将我们的工作置于现有文献的背景中进行讨论。我们在介绍每种方法时将参考图1作为辅助说明。
2.1 逐点式提示方法
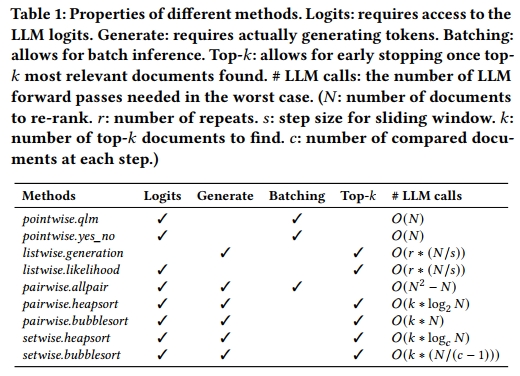
图1a展示了逐点式方法。在逐点提示中,当前主要有两种流行的LLM提示方向:生成式方法与似然法。在生成方法中,使用"yes/no"生成技术:LLM被提示判断候选文档是否与查询相关,并对每个候选文档重复该过程。随后,这些候选文档会根据生成"yes"响应的归一化概率进行重排序 12, 17。而似然方法则采用查询似然建模(query likelihood modelling, QLM)18, 36, 39,即提示LLM为每个候选文档生成一个相关查询,然后根据生成实际查询的似然概率对文档进行重排序 22。值得注意的是,这两种逐点方法都需要访问模型输出的logits,以便计算似然得分。因此,如果对应的API不公开logits值(例如GPT-4),那么就无法使用封闭式LLM实现这些方法。
2.2 列表式提示方法
图1b展示了列表式方法。在此方法中,LLM接收一个查询以及一组候选文档,并被提示根据这些文档与查询的相关性生成一个文档标签的排序列表 15, 20, 23。然而,由于LLM允许的输入长度有限,无法在提示中包含所有候选文档。为了解决这个问题,现有的列表式方法采用滑动窗口技术:从原始排序列表的底部开始对一组候选文档进行重排序,然后逐步向上滑动。该过程可重复多次以获得更优的最终排序,同时还支持早停机制,只关注top-𝑘排序,以节省计算资源。与逐点方法不同,后者利用输出token的似然值进行文档排序,列表式方法则依赖于直接生成排序列表的过程,这一过程效率更高。
2.3 成对式提示方法
图1c展示了成对式方法。LLM被提示同时接收一个查询和一对文档,并要求生成一个标签,指示哪一个文档与查询更加相关 19, 21。为了对所有候选文档进行重排序,一种基本方法称为 AllPairs,它涉及从候选文档集中生成所有可能的文档对。每对文档被独立送入LLM中处理,确定出更优的文档。随后,采用一个聚合函数根据推断出的成对偏好为每个文档分配一个得分,并基于各文档的总得分建立最终排序 19。然而,这种基于聚合的方式会导致较高的查询延迟:对所有文档对进行LLM推理的计算开销非常大。
为了解决成对式方法中的效率问题,已有研究引入了采样 8, 16 和排序 21 算法。在本文中,我们聚焦于排序算法,因为假设LLM能够提供理想的成对偏好信息,那么排序算法可以在理论上保证从候选集中找出top-𝑘个最相关的文档。在先前的研究中 21,使用了两种排序算法 9:堆排序(heap sort)和冒泡排序(bubble sort)。与AllPairs方法不同,这些排序算法利用高效的数据结构来选择性地比较文档对,从而能迅速将最相关的文档从候选集中提取出来并放置于最终排序的顶部。这一点尤其适用于top-𝑘排序任务,即只需对𝑘个最相关文档进行排序即可。这些排序算法提供了一种停止机制,避免了对所有候选文档进行全面排序的需要。
从理论角度来看,这三类使用LLM进行零样本文档排序的方法之间的差异及其相对优势是明确的。然而,从实证角度来看,当前尚未对这些技术在效果与效率之间的权衡,以及在LLM规模、评测基准和计算资源等因素上的表现,进行过公平且全面的评估。
2.4 使用LLM进行排序的其他方向
上述三类方法通过直接对LLM进行提示,从而推断文档相对于给定查询的相关性,在无需任何排序任务训练数据的零样本设置下用于文档重排序。与此同时,另一个使用LLM进行检索的方向也逐渐出现:即将LLM用作文本嵌入模型,用于密集文档检索 2, 11, 30, 31。由于这些方法在生成文档表示时与查询表示相互独立,它们可作为第一阶段的文档检索器(即本质上是一个bi-encoder架构),而不像我们之前回顾的三类方法那样仅限于作为重排序器。然而,这些方法通常需要执行对比学习训练,以使生成式LLM能够作为文本嵌入模型使用。一个例外是最近提出的PromptReps方法 38,它不需要对比训练,而是仅通过prompt工程即可实现文档(和查询)的嵌入。PromptReps的另一个特点是可以同时获得文档和查询的密集表示与稀疏表示。
3 SETWISE排序提示
本节中,我们将讨论当前LLM-based零样本排序方法所存在的局限性。随后我们将介绍我们提出的Setwise方法,并说明它是如何解决这些局限的。
3.1 当前方法的局限性
LLM-based零样本排序方法的效率依赖于两个关键维度。
首先,LLM推理的次数对效率有显著影响。由于LLM是拥有数十亿参数的大型神经网络,推理过程本身计算开销巨大。因此,推理次数的增加会带来可观的计算负担。这一点在当前的Pairwise方法中表现尤为明显:由于需要对大量文档对进行偏好推理,其效率较低。尽管排序算法在一定程度上缓解了这一问题,但并不能完全解决效率瓶颈。
其次,每次推理所生成的LLM token数量也起着关键作用。LLM采用transformer解码器执行自回归token生成,每生成一个新的token都依赖于前面已生成的token。每多生成一个token,就需要进行一次额外的LLM推理。这也正是现有Listwise方法效率低下的原因之一:该方法依赖于生成完整的文档标签排序列表,往往需要生成大量token。
接下来,我们将介绍我们提出的Setwise提示方法,它通过减少所需LLM推理次数并利用LLM产生的logits,有效克服Pairwise与Listwise方法在效率方面的局限性。
3.2 使用 Setwise 提升 Pairwise 的速度
为了解决这些方法中的效率问题,我们提出了一种新颖的 Setwise prompting 方法。如图 1d 所示,我们的提示方式指示 LLM 从一组文档中选择与查询最相关的文档,因此被称为 Setwise prompting。我们特别将文档集合视为一个无序集合,后续实验将表明,Setwise prompting 对文档的排列顺序具有很强的鲁棒性。
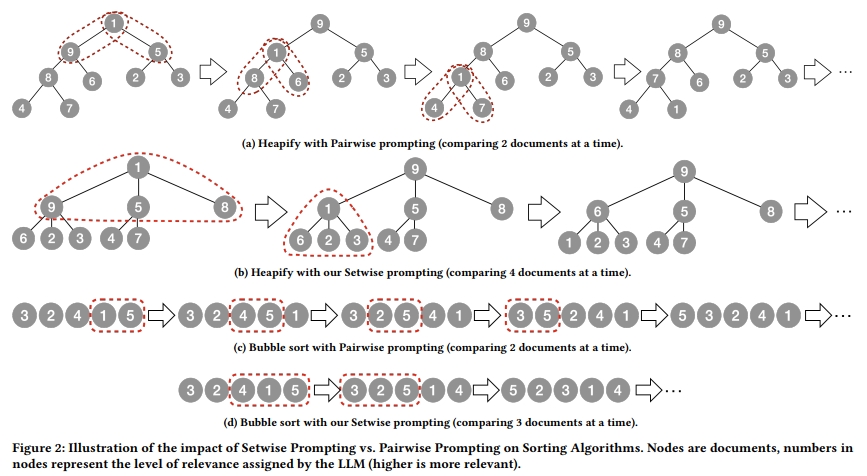
借助该提示方式,基于排序的 Pairwise 方法可以被显著加速。这是因为原始的 Pairwise 方法中使用的 heap sort 和 bubble sort 算法在排序过程中每一步仅比较一对文档,如图 2a 和 2c 所示。而这些排序算法如果能够在每一步比较多于两个文档,就可以大幅提升效率。例如,在 heap sort 算法中,"heapify" 函数需要对每棵子树进行操作,若子节点的值高于父节点,就需要将父节点与具有最大值的子节点交换。在图 2a 的场景下,若使用 pairwise prompting 来进行 "heapify",至少需要进行 6 次比较(每个根节点与其子节点分别配对)。相比之下,若我们将每棵子树的子节点数量增至 3,并且可以一次比较 4 个节点,则仅需 2 次比较即可对包含 9 个节点的树完成 heapify,如图 2b 所示。
类似地,在 bubble sort 算法中,若我们能一次比较多于两个文档,每次的"bubbling"过程也将被加速。例如,在图 2c 中共需进行 4 次比较,而图 2d 中通过一次比较 3 个文档,仅需 2 次比较即可将最大值节点移至顶部。我们的 Setwise prompting 设计就是为了指示 LLM 一次性比较多个文档的相关性,非常适合上述用途。
3.3 使用 Setwise 实现 Listwise Likelihoods
我们的 Setwise prompting 同样可以加速 Listwise 方法中的排序过程。原始的 Listwise 方法依赖于 LLM 的下一个 token 生成机制,在滑动窗口处理的每一步中生成完整的文档标签有序列表,如图 1b 所示。如前所述,生成文档标签列表计算开销大,因为 LLM 需要对每个下一个 token 的预测进行一次推理。
另一方面,LLM 可能会以意料之外的格式生成结果,甚至可能拒绝生成所需的文档标签列表 23,从而影响效果。幸运的是,如果我们能够访问 LLM 的输出 logits,就可以避免这些问题:我们可以评估生成每一个可能文档标签列表的概率,然后选择概率最高的那个作为输出。
遗憾的是,这在理论上可行,但对于现有的 Listwise 方法来说在实践中不可行。因为文档标签的可能排列组合数巨大,导致 likelihood 检查过程本身可能比直接生成列表还要耗时。
Setwise prompting 再次提供了解决方案:我们可以直接从 LLM 输出的 logits 中推导出文档标签的有序列表。具体而言,评估每个文档标签被选为最相关的可能性(如图 1d 所示),就可以得到一个排序。这种简洁的技巧显著加速了 Listwise 排序,只需要一次 LLM 的前向传播,同时还能确保输出与所需的文档标签列表格式一致。
温馨提示:
阅读全文请访问"AI深语解构 " 一种集合式方法:实现高效且有效的大语言模型零样本排序