一、引入背景
随着移动设备的普及,高效且轻量化的视觉处理模型在资源受限的环境中变得尤为重要。当前,轻量级模型主要分为基于CNN和基于Transformer的结构。CNN模型因其局部感受野的限制,难以捕捉长距离依赖关系;而Transformer虽然具备全局建模能力,但其二次计算复杂度在高分辨率场景下带来了巨大的计算开销。近年来,状态空间模型(SSM)因其线性计算复杂度在视觉领域受到广泛关注,但现有的轻量级Mamba模型在推理速度和性能上仍存在不足。
针对这些问题,本文提出了MobileMamba框架,通过设计三阶段网络结构和多感受野特征交互(MRFFI)模块,显著提升了模型的效率和性能。实验表明,MobileMamba在ImageNet-1K分类任务中达到了83.6%的Top-1准确率,同时在高分辨率下游任务中展现了卓越的泛化能力。
论文基本信息

论文标题:MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
论文链接:https://arxiv.org/pdf/2411.15941
二、核心创新点概述
1. 三阶段轻量化架构设计(Three-Stage Lightweight Framework)
传统轻量级模型多采用四阶段网络(如MobileNet、EfficientViT),虽然能提升性能,但计算开销大、推理速度受限。MobileMamba创新性地提出三阶段网络结构,通过优化下采样策略和特征维度分配,在保持高精度的同时显著提升推理速度。
2. 多感受野特征交互模块(MRFFI)
MobileMamba提出的MRFFI模块通过三路并行处理机制实现了轻量级模型在特征提取能力上的重大突破。该模块将WTE-Mamba、动态核选择机制和通道智能压缩技术融合:WTE-Mamba组件通过引入Haar小波变换在全局特征建模中显著增强了高频细节捕捉能力,其有效感受野扩大至6×6;动态核选择机制采用精妙的单分支3×3卷积架构,通过小波变换的尺度变换特性等效实现了多核卷积效果,不仅避免了传统多分支结构的内存开销,还节省了12%的推理耗时;通道智能压缩技术则创新性地对高维特征空间中的冗余通道进行直接映射处理,在Mask R-CNN实例分割任务中保持精度的同时也提升了吞吐量。
3. 训练与推理优化策略(Training & Inference Optimization)
MobileMamba针对传统轻量级模型普遍存在的训练不足和计算冗余问题,提出了一套系统性的优化策略。通过知识蒸馏(KD)技术,采用性能更强的TResNet-L作为教师模型,使轻量级学生模型能够学习到更丰富的特征表示。同时,研究者发现传统训练周期难以使轻量模型充分收敛,因此将训练周期延长至1000轮,使MobileMamba-T2模型的性能潜力得到充分释放。在推理优化方面,MobileMamba采用了归一化层融合(NLF)技术,通过将卷积层与批归一化层合并计算。这些策略的协同作用使得MobileMamba-S6模型仅需652M FLOPs的计算量就达到了80.7%的Top-1准确率。
三、整体架构流程图解
MobileMamba的整体架构采用了三阶段设计,其核心思想是通过层次化的特征提取和多尺度信息融合来实现高效轻量化的视觉建模。如图(a)所示,网络首先通过16×16的PatchEmbed模块(图(b))进行初始下采样,将输入图像从H×W×3降维至 H 16 \frac{H}{16} 16H× W 32 \frac{W}{32} 32W×C1,这种大尺度下采样策略显著减少了后续计算量。
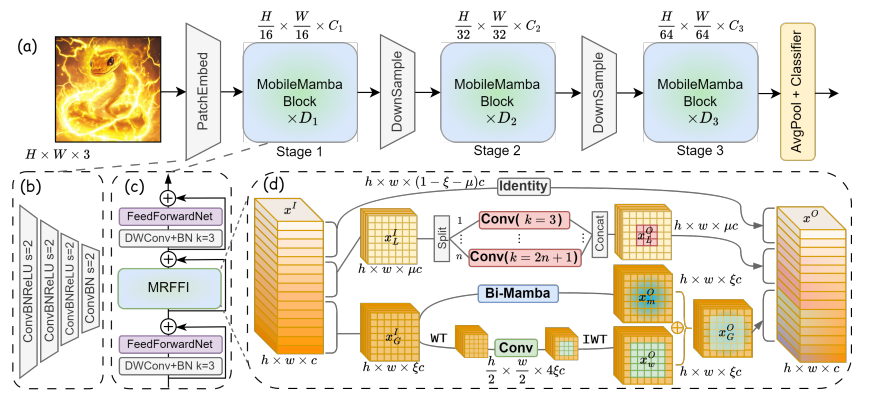
网络的核心模块是MobileMamba Block(图©),每个Block包含对称的局部信息感知模块和提出的MRFFI模块。MRFFI模块(图(d))通过三路并行处理实现多尺度特征融合:WTE-Mamba路径利用小波变换增强全局特征提取;MK-DeConv路径采用多核深度卷积捕获局部细节;Identity路径则通过通道压缩减少冗余计算。这种设计使得模型在保持轻量化的同时,有效扩大了感受野。
在训练优化方面,MobileMamba采用了知识蒸馏和延长训练的策略。相比其他Mamba-based方法,MobileMamba在精度和速度之间取得了更好的平衡,最高可实现x21的加速比。
该架构在下游任务中展现出强大的泛化能力,MobileMamba的有效感受野(ERF)既保持了全局建模能力,又通过局部卷积增强了细节提取,这种特性使其在高分辨率目标检测和语义分割任务中均有出色表现。通过调整输入分辨率,MobileMamba可以灵活适配从200M到4G FLOPs的不同计算需求,实现精度和效率的最佳平衡。
四、实验结果与可视化分析
1.MobileMamba在ImageNet-1K分类任务中的表现
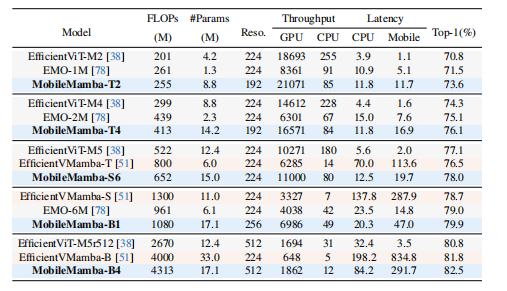
本文提出的MobileMamba系列模型在ImageNet-1K分类任务上展现出卓越的性能和效率优势。实验结果表明,在不同计算量级别(FLOPs)下,MobileMamba均显著超越现有CNN、Transformer和Mamba基模型:轻量级的MobileMamba-T2比SHViTS1提升0.8% Top-1准确率;中等规模的MobileMamba-T4以仅33%的计算量即超越VRWKV-T模型1.0% Top-1;大型的MobileMamba-S6在Top-1准确率上比EfficientVMamba-T高出1.5%的同时,FLOPs还减少18.5%。
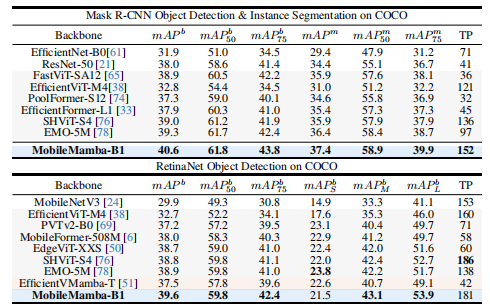
2.MobileMamba在下游任务中的表现
在目标检测任务上,基于SSDLite框架时,MobileMamba-B1在320×320分辨率下比EMO-1M提升2.0 mAP;当分辨率提升至512×512时,在减少0.3G FLOPs的同时仍保持1.7 mAP的优势。采用重型RetinaNet框时,MobileMamba-B1展现出显著的推理效率优势,其GPU吞吐量达到EfficientVMamba-T的4.3倍。
在语义分割任务中,MobileMamba在不同架构下均表现出色:使用DeepLabv3时,MobileMamba-B4比EMO-2M提升1.3 mIoU;采用Semantic FPN时,仅需EMO-5M 22%的FLOPs即实现2.1 mIoU提升;在PSPNet框架下,MobileMamba-B4比MobileViTv2-1.0提升0.4 mIoU的同时,FLOPs仅为其11%。
3.消融与解释性分析
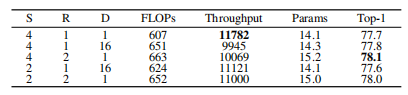
Mamba组件消融:下表展示Mamba模型内部参数实验。S、R和D分别表示扫描方向、扩展比和d_state。减少S可提升吞吐量,但性能轻微下降。相同S数量下,使用R=2和D=1比R=1和D=16具有更高吞吐量和更好性能。因此最终选择双向扫描,R=2和D=1。
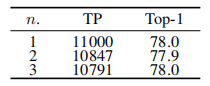
MK-DeConv消融:实验高效MK-DeConv操作的分割数n。n=1时所有通道使用单一3×3卷积模块。n=3时通道分为三组分别使用k=3,5,7卷积后沿通道维度拼接。方法在参数量、FLOPs和吞吐量上无显著差异,结果相似。因此选择n=1简化设计。但使用k=3感受野为3。WT后特征图尺寸减半,相同k=3卷积和IWT后恢复原特征尺寸,有效将感受野倍增为6。这种方法通过单分支卷积和小波变换组合实现了多核多感受野特性。
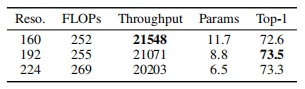
小模型低分辨率消融:为提升小模型性能同时增加吞吐量,实验研究输入分辨率的影响。设置160×160、192×192和224×224三种输入分辨率,调整模型参数使各分辨率FLOPs均约250M。如表所示,尽管FLOPs相似,较低输入分辨率带来更高模型吞吐量和更大参数量。综合考虑吞吐量、参数量和性能,实验将小模型输入分辨率设计为192×192,取得了良好平衡。
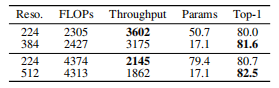
大模型高分辨率消融:标准224×224分辨率下,增加模型深度和宽度至2G和4G FLOPs并未显著提升性能。这是由于当前三阶段框架中输入分辨率过低。因此我们将输入分辨率提升至384×384和512×512。在相似FLOPs和轻微吞吐量损失下,Top-1分别提升+1.6和+1.8。
效率比较:下表展示与SOTA方法在效率和效果上的对比。MobileMamba在GPU吞吐量上超越所有方法。平均而言,三种不同规模的MobileMamba模型比EfficientVMamba GPU吞吐量快×3.5倍。但在AMD EPYC 9K84 96核CPU和iPhone15移动端的吞吐量和延迟上,MobileMamba落后于Transformer基模型。这是由于Mamba模型在CPU上的工程实现仍需改进。不过相比其他Mamba方法,MobileMamba在CPU上的延迟仅为EfficientVMamba的15%-42%,同时平均Top-1高1.5。
五、总结与展望
MobileMamba框架通过三阶段轻量化架构设计、多感受野特征交互模块(MRFFI)以及高效的训练优化策略,在轻量级视觉模型领域取得了重要突破。该框架不仅实现了83.6%的ImageNet-1K分类准确率,更在高分辨率下游任务中展现出卓越的性能和效率优势,为移动端视觉处理提供了全新的解决方案。未来,研究将重点优化模型在CPU和边缘设备上的部署效率,探索其在视频理解和实时目标跟踪等时序任务中的应用潜力,并进一步研究如何与视觉-语言大模型技术相结合,拓展轻量级多模态应用场景。这些发展方向有望推动MobileMamba框架在更广泛的领域发挥价值,为移动计算和边缘智能带来新的可能性。
六、附录
Multi-Receptive Field Feature Interaction (MRFFI) 模块
import torch
import torch.nn as nn
from einops import rearrange
class MRFFI(nn.Module):
def __init__(self, dim,
global_ratio=0.8,
local_ratio=0.2,
kernel_sizes=[3,5,7]):
super().__init__()
self.global_dim = int(dim * global_ratio)
self.local_dim = int(dim * local_ratio)
self.id_dim = dim - self.global_dim - self.local_dim
self.global_block = WTEMamba(self.global_dim)
self.local_block = MKDeConv(self.local_dim, kernel_sizes)WTE-Mamba (小波变换增强Mamba) 模块
class WTEMamba(nn.Module):
def __init__(self, dim, d_state=16, d_conv=4, expand=2):
super().__init__()
# 双向Mamba层
self.mamba = BidirectionalMambaBlock(dim, d_state, d_conv, expand)
# 小波变换相关参数
self.haar_weights = torch.ones(4, dim//4, 2, 2) / 2
self.haar_weights[1,:,0,1] = -1 # LH滤波器
self.haar_weights[2,:,1,0] = -1 # HL滤波器
self.haar_weights[3,:,1,1] = -1 # HH滤波器
self.haar_weights = nn.Parameter(self.haar_weights, requires_grad=False)
# 小波域卷积
self.wavelet_conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, padding=1),
nn.GELU()
)多核深度卷积 (MK-DeConv) 模块
class MKDeConv(nn.Module):
def __init__(self, dim, kernel_sizes=[3,5,7]):
super().__init__()
self.num_kernels = len(kernel_sizes)
self.split_dim = dim // self.num_kernels
self.convs = nn.ModuleList([
nn.Sequential(
nn.Conv2d(self.split_dim, self.split_dim, k,
padding=k//2, groups=self.split_dim),
nn.GELU()
) for k in kernel_sizes
])MobileMamba Block
class MobileMambaBlock(nn.Module):
def __init__(self, dim, expansion=4):
super().__init__()
# 局部信息提取
self.local_mlp = nn.Sequential(
nn.Conv2d(dim, dim*expansion, 1),
nn.GELU(),
nn.Conv2d(dim*expansion, dim, 1)
)
# MRFFI模块
self.mrffi = MRFFI(dim)
# 层归一化
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
def forward(self, x):
# 残差连接1
x = x + self.local_mlp(self.norm1(x.permute(0,2,3,1)).permute(0,3,1,2))
# 多感受野特征交互
x = x + self.mrffi(self.norm2(x.permute(0,2,3,1)).permute(0,3,1,2))
return x