前言
在AI技术飞速发展的今天,大语言模型(LLM)、多模态模型等前沿技术正深刻改变行业格局。推理服务是大模型从"实验室突破"走向"产业级应用"的必要环节,需直面高并发流量洪峰、低延时响应诉求、异构硬件优化适配、成本精准控制等复杂挑战。
阿里云人工智能平台 PAI 致力于为用户提供全栈式、高可用的推理服务能力。在本系列技术专题中,我们将围绕分布式推理架构、Serverless弹性资源全球调度、压测调优和服务可观测等关键技术方向,展现 PAI 平台在推理服务侧的产品能力,助力企业和开发者在AI时代抢占先机,让我们一起探索云上AI推理的无限可能,释放大模型的真正价值!
在大模型推理的实际应用中,"高计算量、长时延"的推理场景(如AIGC、视频理解、长文档摘要等)往往需要数十秒甚至分钟级的计算时间。传统同步推理模式导致客户端长时间阻塞,不仅造成连接资源浪费,更可能因网络抖动造成请求失败。行业数据表明,当推理耗时超过15秒时,同步请求的超时率会陡增至62%,严重制约了AI服务在高延迟场景下的可用性。
对于上述提到的推理耗时比较长或者推理时间无法确定的场景,同步等待结果会带来HTTP长连接断开、客户端超时等诸多问题。在AI推理领域通常使用异步推理来解决上述问题,即请求发送至服务端,客户端不再同步等待结果,而是选择定期去查询结果,或通过订阅的方式在请求计算完成后等待服务端的结果推送。业界在异步推理的使用过程中,也会出现如下常见的问题:
-
异步推理的负载均衡无法使用round robin算法,需要根据各个实例的实际负载情况进行请求的分发。
-
异步推理计算实例异常,该实例尚未完成计算的任务需要重新分配给其他实例进行计算。
基于对如上问题的思考,阿里云人工智能平台PAI推出了一套基于独立的队列服务异步推理框架,用来解决上述的请求分发的问题。
实现原理
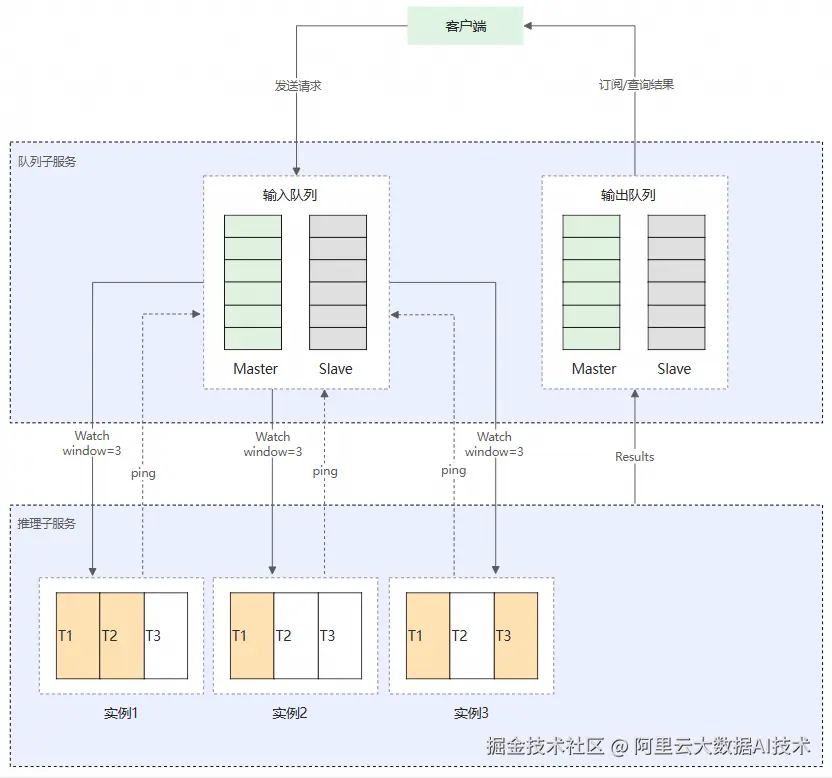
-
在创建异步推理服务时,会在服务内部集成两个子服务,分别是推理子服务 和队列子服务。队列子服务拥有两个内置的消息队列,即输入(input)队列和输出(sink)队列。服务请求会先发送到队列子服务的输入队列中,推理子服务实例中的EAS服务框架会自动订阅队列以流式地方式获取请求数据,调用推理子服务中的接口对收到的请求数据进行推理,并将响应结果写入到输出队列中。
-
当输出队列满时,即无法向输出队列中写入数据时,服务框架也会停止从输入队列中接收数据,避免无法将推理结果输出到输出队列。如果您不需要输出队列,例如将推理结果直接输出到OSS或者您自己的消息中间件中,则可以在同步的HTTP推理接口中返回空,此时输出队列会被忽略。
-
创建一个高可用的队列子服务,用于接收客户端发送的请求。推理子服务的实例根据自己所能承受的并发度来订阅指定个数的请求,队列子服务会保证每个推理子服务实例上处理的请求不会超过订阅的窗口大小,通过该方式来保证不会存在实例过载,最终将订阅或查询的数据返回给客户端。
-
队列子服务通过检测推理子服务实例的连接状态,对其进行健康检查,如果因该实例异常导致连接断开,队列子服务会将该实例标记为异常,已经分发给该实例进行处理的请求会重新推送给其他正常实例进行处理,以此来保证在异常情况下请求数据不会丢失。
使用方式
-
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
-
在推理服务 页签,单击部署服务 ,选择自定义模型部署 >自定义部署。
-
在环境信息 的区域,勾选异步队列的开关配置即可。
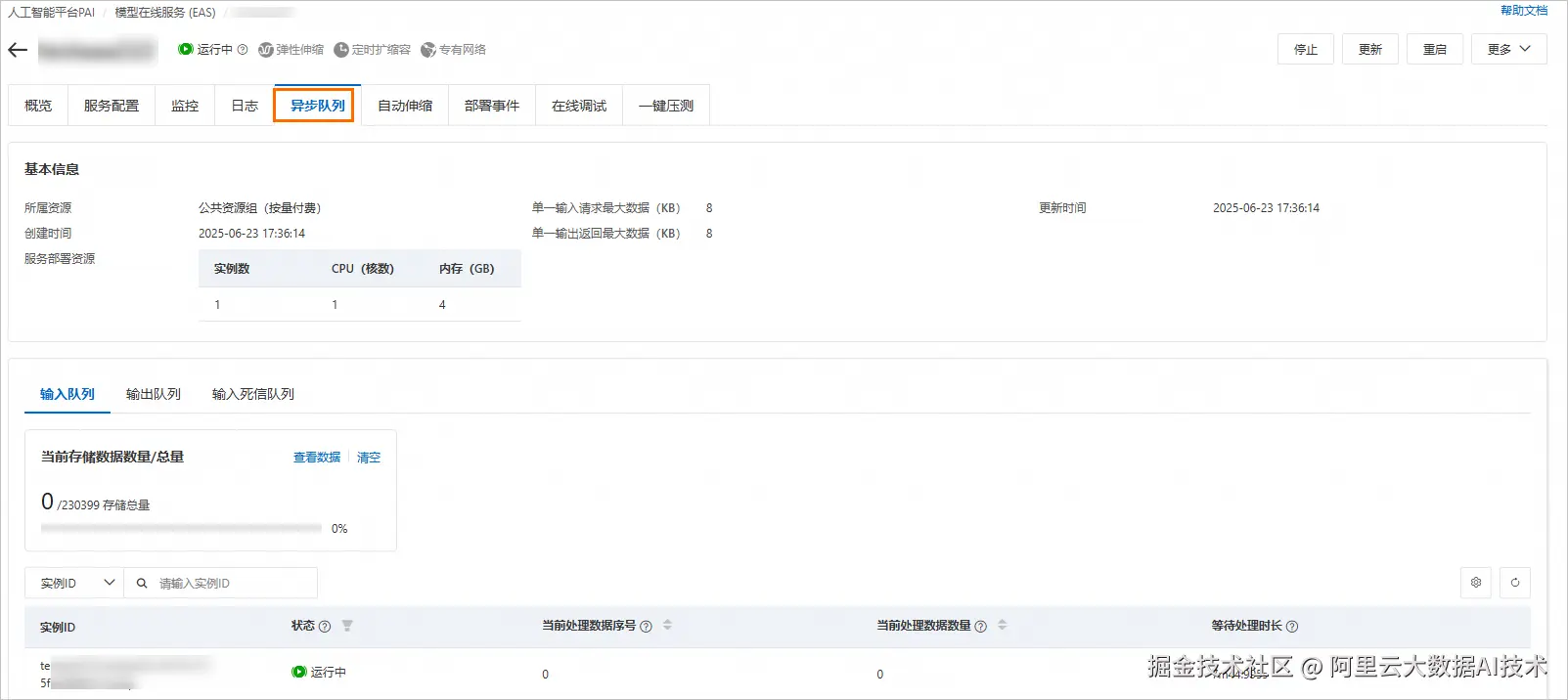
异步推理服务部署完成后,您可在服务的详情页中查看异步队列里面的相关信息,包括输入与输出队列的当前数据量及总量,并可以查看访问服务的每一个请求数据的处理情况。
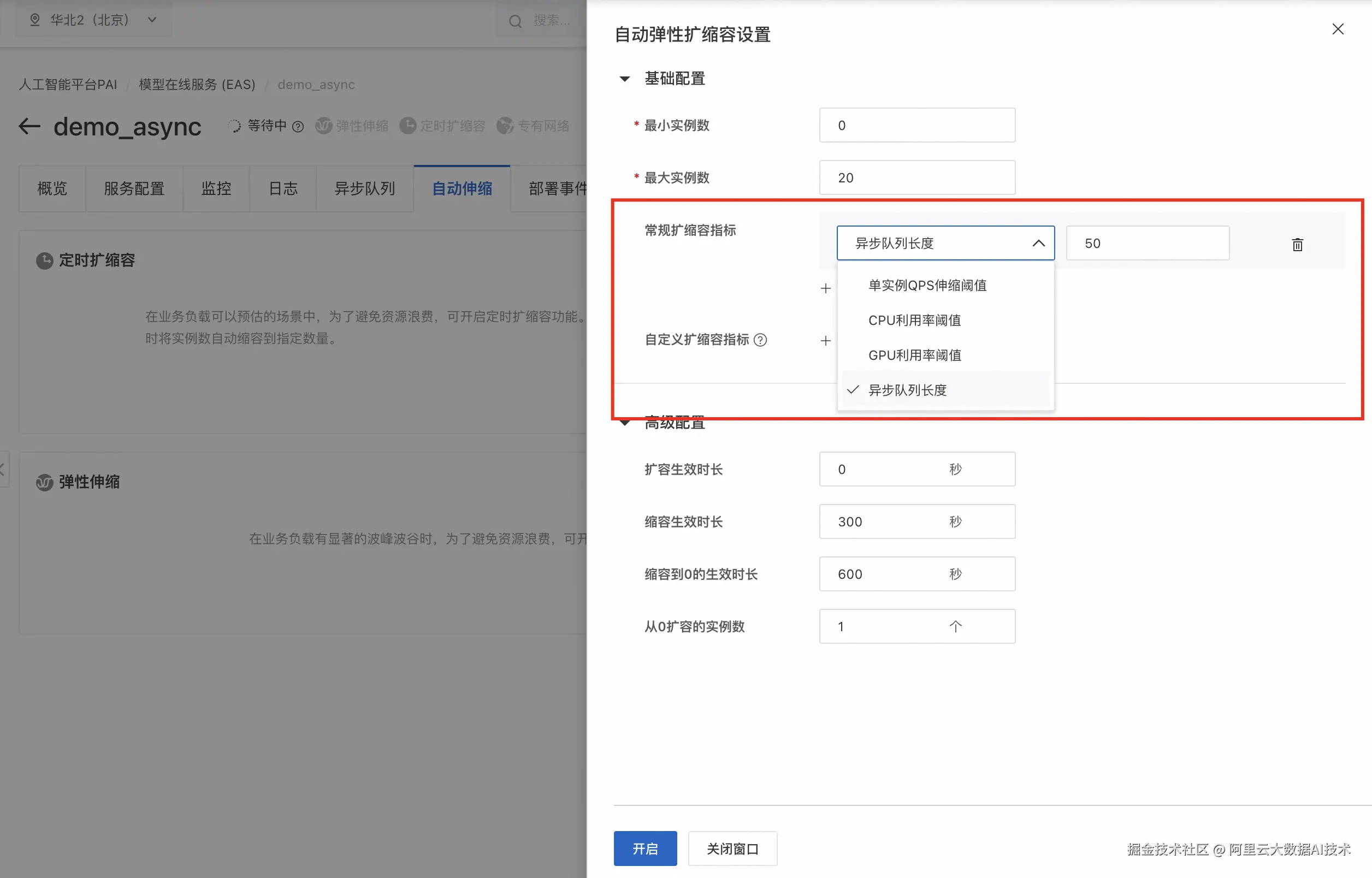
自动扩缩容
在异步推理场景中,系统可以根据队列的状态动态地对推理服务的实例数量进行伸缩,并且支持在队列为空时将推理服务的实例数缩容到0以进一步降低成本。
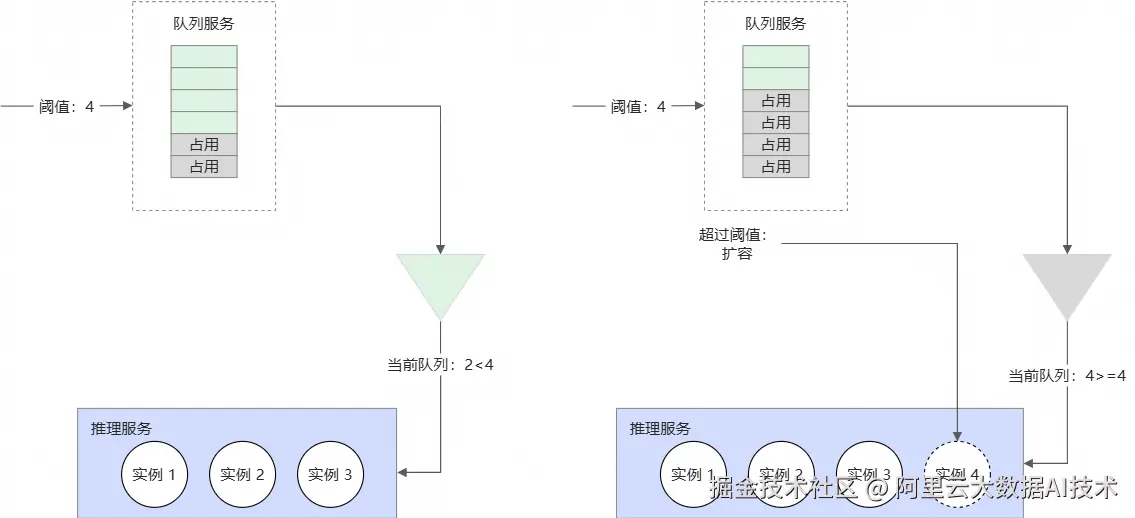
异步推理服务部署完成后,您可在服务的详情页来配置异步服务的自动扩缩容策略,通过异步队列长度来自定义服务的弹性配置。
系列简介:云上AI推理平台全掌握
本系列 《云上AI推理平台全掌握》 将深度解析阿里云AI推理平台的技术架构、最佳实践与行业应用,涵盖以下核心内容:
-
技术全景:从分布式推理、动态资源调度到Serverless,揭秘支撑千亿参数模型的底层能力。
-
实战指南:通过压测调优、成本优化、全球调度等场景化案例,手把手教你构建企业级推理服务。
-
行业赋能:分享金融、互联网、制造等领域的落地经验,展示如何通过云上推理平台加速AI业务创新。
无论客户是AI开发者、架构师,还是企业决策者,本系列都将为客户提供从理论到实践的全方位指导,助力客户在AI时代抢占先机。让我们一起探索云上AI推理的无限可能,释放大模型的真正价值!
立即开启云上 AI 推理之旅,就在阿里云人工智能平台PAI。