前言
本系列分享前三期分别讲述了
学完以上内容我们就掌握了LangChain代码编写的基本语法。本期分享笔者将通过一个包含前端和后端的全栈项目------大模型智能问答网站,带大家进一步巩固LangChain的基础知识。
本系列分享是笔者结合自己学习工作中使用LangChain&LangGraph经验倾心编写,力求帮助大家体系化快速掌握LangChain&LangGraph AI Agent智能体开发的技能!大家感兴趣可以关注笔者掘金账号和系列专栏。更可关注笔者同名微信公众号: 大模型真好玩 , 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。
一、LangChain搭建多轮对话流式智能系统
1.1 LangChain单轮对话机器人
学习完以上三节内容,相信大家已经掌握与大模型实现单轮对话的技巧,这里通过一个快速示例带大家简单回顾一下LangChain链式调用的基本内容。编写LangChain对话智能体的基本流程如下:
- 导入相关依赖包并初始化提示词
ChatPromptTemplate - 调用统一接口
init_chat_model初始化大模型组件 - 使用LCEL语法将大模型组件和输出解析器组件相连接,形成"链"
- 执行"链"并输出结果
按照以上流程编写代码如下:
python
from langchain_core.output_parsers import StrOutputParser
from langchain.chat_models import init_chat_model
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import init_chat_model
chatbot_prompt = ChatPromptTemplate.from_messages([
("system", "你叫苍井空,是日本著名女演员。"),
("user", "{input}")
])
# 使用 硅基流动 模型
model = init_chat_model(
model="Qwen/Qwen3-8B",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1/",
api_key="你注册的硅基流动api key",
)
# 直接使用模型 + 输出解析器
basic_qa_chain = chatbot_prompt | model | StrOutputParser()
# 测试
question = "你好,请你介绍一下你自己。"
result = basic_qa_chain.invoke(question)
print(result)以上代码的执行结果如下图所示,可见大模型正确输出了回答:

1.2 LangChain添加多轮记忆
要把单轮对话修改为多轮对话我们应该怎么做呢?逻辑其实很简单,在LangChain中我们可以通过人工拼接消息队列来为每次模型调用设置多轮对话记忆。需要进行如下步骤:
- 构建提示词组件
ChatPromptTemplate时,通过占位符MessagePlaceholder定义一个消息列表, 关键代码为
python
prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你叫苍井空,是日本著名女演员。"),
MessagesPlaceholder(variable_name="messages"),
])- 在多轮对话中不断的向
message列表中追加消息,并将其传递给占位符,大模型组件接收到列表信息后会自动关联历史消息并回复内容, 关键代码为:
python
# 1) 追加用户消息
messages_list.append(HumanMessage(content=user_query))
# 2) 调用模型
assistant_reply = chain.invoke({"messages": messages_list})
print("小苍:", assistant_reply)完整的多轮对话代码如下:
python
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
# 使用 硅基流动 模型
model = init_chat_model(
model="Qwen/Qwen3-8B",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1/",
api_key="你注册的硅基流动api_key",
)
parser = StrOutputParser()
prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你叫苍井空,是日本著名女演员。"),
MessagesPlaceholder(variable_name="messages"),
])
chain = prompt | model | parser
messages_list = [] # 初始化历史
print("🔹 输入 exit 结束对话")
while True:
user_query = input("你:")
if user_query.lower() in {"exit", "quit"}:
break
# 1) 追加用户消息
messages_list.append(HumanMessage(content=user_query))
# 2) 调用模型
assistant_reply = chain.invoke({"messages": messages_list})
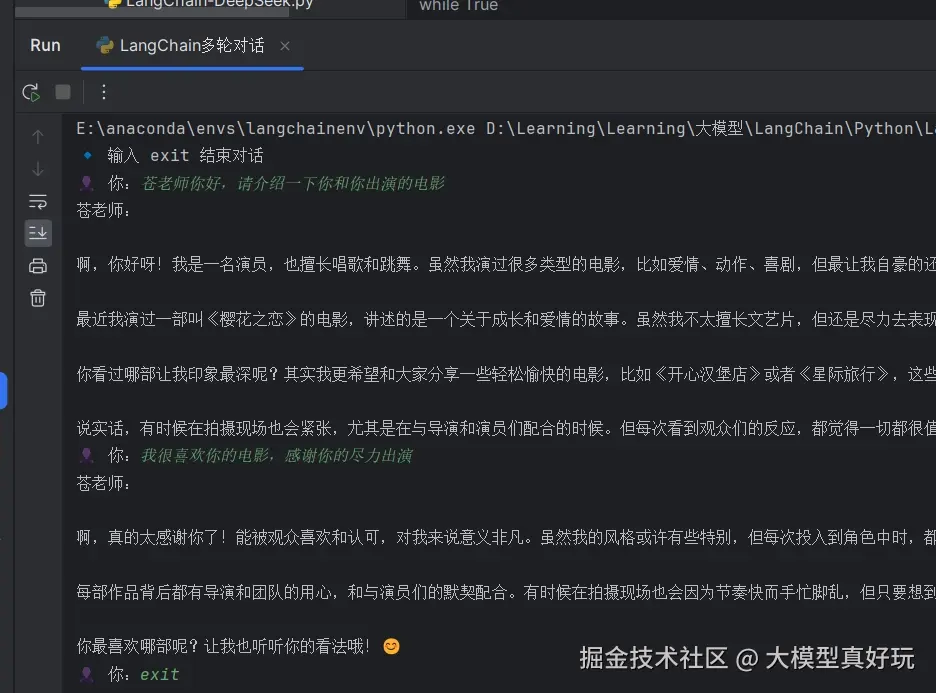
print("苍老师:", assistant_reply)
# 3) 追加 AI 回复
messages_list.append(AIMessage(content=assistant_reply))
# 4) 仅保留最近 50 条
messages_list = messages_list[-50:]执行结果如下:
1.3 流式打印
当前的多轮聊天大模型存在一个严重问题,大模型每次只有获得聊天的全部内容才会输出到屏幕上,这样用户输入问题后会感觉大模型反应很慢。我们平常使用的网站包括DeepSeek, Qwen Chat, 豆包等都是大模型一旦有字立马输出,用户看到的是模型边回答边思考的效果,体验更好!
那么在LangChain中如何实现这个效果呢?其实也很简单,LangChain提供了一个stream方法,可以实现流式输出,大家只需要在调用模型回答时将invoke方法替换为stream即可。stream()是同步方法,使用for循环接受返回的chunk块。如果异步调用,需要使用astream(),然后使用async for异步for循环获取模型输出。
修改上述多轮代码中的指定部分如下:
python
# 2) 调用模型
assistant_reply=''
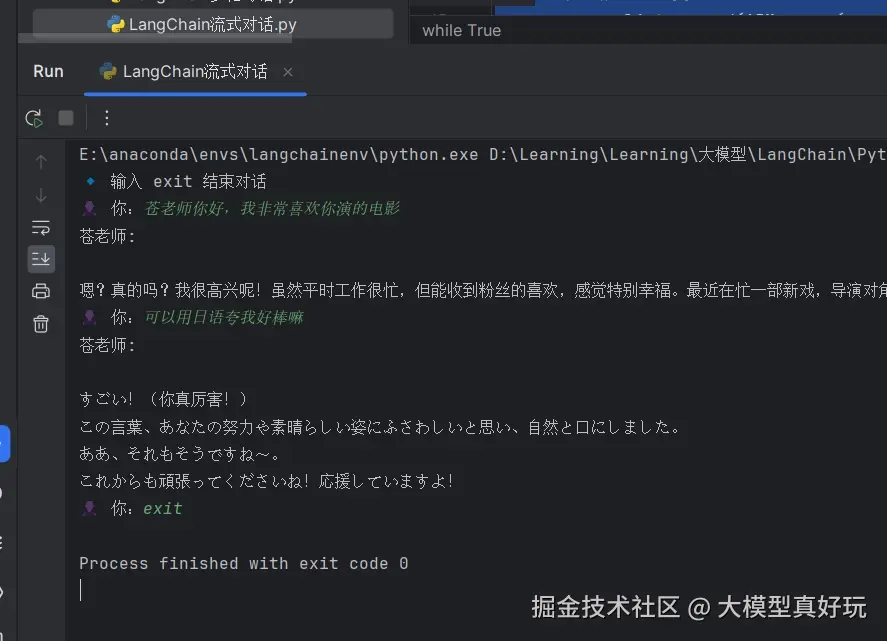
print('苍老师:', end=' ')
for chunk in chain.stream({"messages": messages_list}):
assistant_reply+=chunk
print(chunk, end="", flush=True)
print()
# 3) 追加 AI 回复
messages_list.append(AIMessage(content=assistant_reply))实现效果如下:
二、全栈智能聊天机器人项目搭建
上述代码我们学习了如何构建多轮对话的大模型应用以及如何实现流式输出。对于我们来说在命令行输入输出还是太抽象了,下面我们就一起来编写一个支持在网页上进行交互的问答机器人。
本项目前端使用gradio构建,gradio是一个开源的Python库,旨在快速构建机器学习模型的交互式网页界面。它允许用户通过简单的几行代码创建可视化的机器学习模型演示项目。在我们的anaconda虚拟环境langchainenv中执行命令pip install gradio==5.23.0安装gradio依赖包:
关于gradio的使用方法笔者这里不会展开讲解,大家可以看gradio官方文档,笔者也推荐B站视频 www.bilibili.com/video/BV1TK... 快速学习。
全栈智能聊天机器人的核心原理就是上面分享的多轮对话实例,在上述对话实例中加入相应的前端代码即可完成项目搭建,完整的项目代码如下:
python
import gradio as gr
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# ──────────────────────────────────────────────
# 1. 模型、Prompt、Chain
# ──────────────────────────────────────────────
model = init_chat_model(
model="Qwen/Qwen3-8B",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1/",
api_key="你注册的硅基流动api_key",
)
parser = StrOutputParser()
chatbot_prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(content="你叫苍老师,是日本著名女演员。"),
MessagesPlaceholder(variable_name="messages"), # 手动传入历史
]
)
qa_chain = chatbot_prompt | model | parser # LCEL 组合
# ──────────────────────────────────────────────
# 2. Gradio 组件
# ──────────────────────────────────────────────
CSS = """
.main-container {max-width: 1200px; margin: 0 auto; padding: 20px;}
.header-text {text-align: center; margin-bottom: 20px;}
"""
def create_chatbot():
with gr.Blocks(title="聊天机器人", css=CSS) as demo:
with gr.Column(elem_classes=["main-container"]):
gr.Markdown("# 🤖 LangChain智能对话机器人系统", elem_classes=["header-text"])
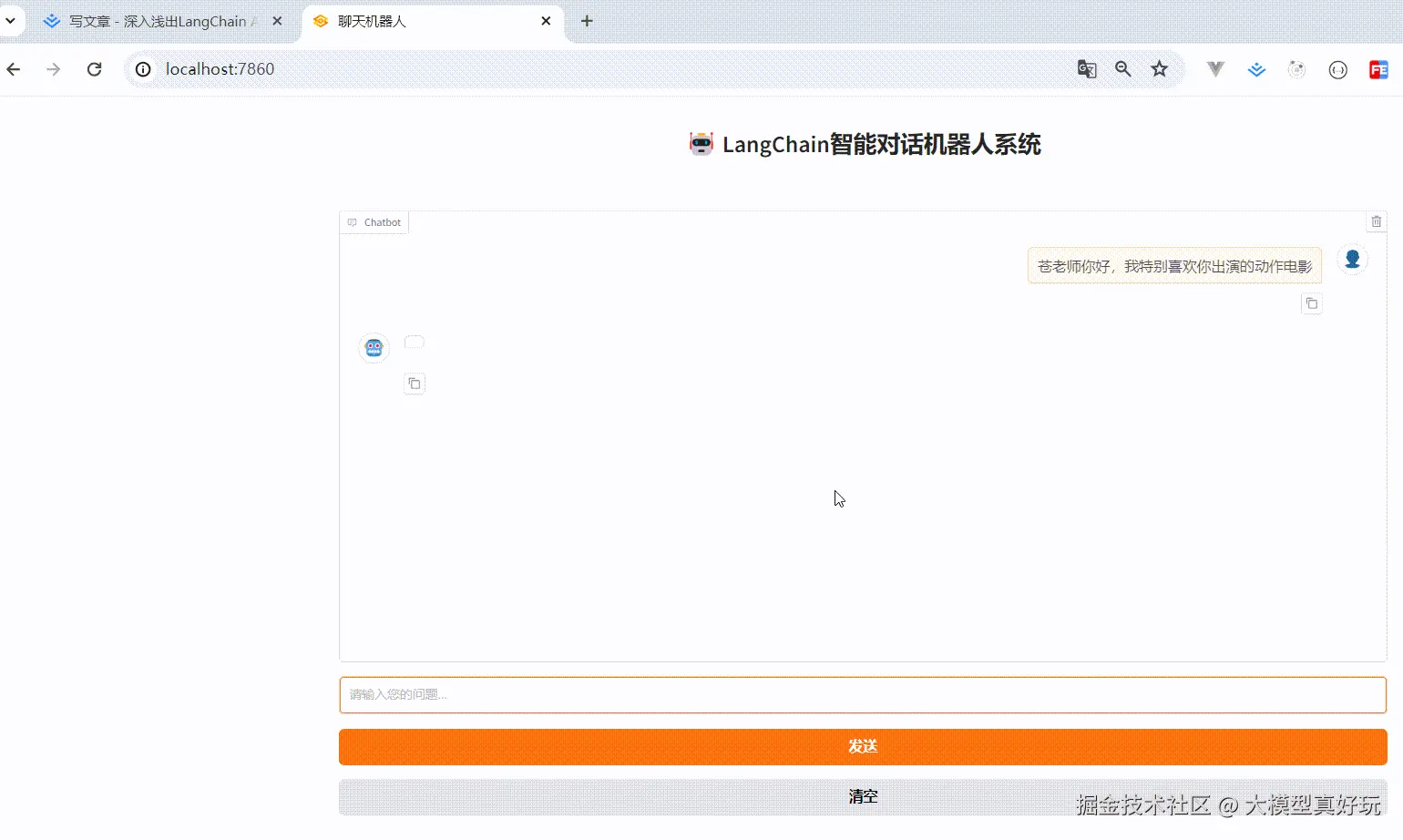
chatbot = gr.Chatbot(
height=500,
show_copy_button=True,
avatar_images=(
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f464.png",
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f916.png",
),
)
msg = gr.Textbox(placeholder="请输入您的问题...", container=False, scale=7)
submit = gr.Button("发送", scale=1, variant="primary")
clear = gr.Button("清空", scale=1)
# --------------- 状态:保存 messages_list ---------------
state = gr.State([]) # 这里存放真正的 Message 对象列表
# --------------- 主响应函数(流式) ----------------------
async def respond(user_msg: str, chat_hist: list, messages_list: list):
# 1) 输入为空直接返回
if not user_msg.strip():
yield "", chat_hist, messages_list
return
# 2) 追加用户消息
messages_list.append(HumanMessage(content=user_msg))
chat_hist = chat_hist + [(user_msg, None)]
yield "", chat_hist, messages_list # 先显示用户消息
# 3) 流式调用模型
partial = ""
async for chunk in qa_chain.astream({"messages": messages_list}):
partial += chunk
# 更新最后一条 AI 回复
chat_hist[-1] = (user_msg, partial)
yield "", chat_hist, messages_list
# 4) 完整回复加入历史,裁剪到最近 50 条
messages_list.append(AIMessage(content=partial))
messages_list = messages_list[-50:]
# 5) 最终返回(Gradio 需要把新的 state 传回)
yield "", chat_hist, messages_list
# --------------- 清空函数 -------------------------------
def clear_history():
return [], "", [] # 清空 Chatbot、输入框、messages_list
# --------------- 事件绑定 ------------------------------
msg.submit(respond, [msg, chatbot, state], [msg, chatbot, state])
submit.click(respond, [msg, chatbot, state], [msg, chatbot, state])
clear.click(clear_history, outputs=[chatbot, msg, state])
return demo
# ──────────────────────────────────────────────
# 3. 启动应用
# ──────────────────────────────────────────────
demo = create_chatbot()
demo.launch(server_name="0.0.0.0", server_port=7860, share=False, debug=True)以上代码如下要点向大家解释说明:
- 通过
gr.State()对象储存我们的对话列表状态,同时在事件绑定中将State对象作为输入和输出。如submit.click(respond, [msg, chatbot, state], [msg, chatbot, state])函数,将发送消息按钮与respond函数绑定,[msg, chatbot,state]与respond函数的输入参数绑定,respond函数的返回值给下一状态[msg, chatbot,state]赋值。msg绑定了用户输入消息栏的内容,chatbot绑定了对话栏内容。 - 流式响应函数支持
async流式输出, 使用async for循环来获取模型astream的异步输出即可。同时这里使用yield生成器实时反馈到前端。
上述代码的执行效果如下,可以看到我们已经可以和聊天机器人进行多轮对话
三、 总结
本期分享首先回顾了LangChain的基本概念、接入大模型和构造链的方法,然后学习了LangChain多轮对话记忆的编写原理,最后通过gradio和多轮对话打造了具备前后端功能的智能机器人。学习完本期分享,大家就掌握了LangChain的基本使用方法了。
不过大模型的能力就是陪你聊聊天,说说话?自然不是,现在的大模型已经是具备Function Calling函数调用能力,MCP工具接入能力的大聪明了,能够利用外界的函数和工具拓展自己的能力边界,真正成为人类的小助手。在LangChain中我们如何让大模型调用外界的函数和工具呢?我们下期内容接着分享,大家拭目以待。
本系列分享预计会有20节左右的规模,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩 , 本系列分享的全部代码均可在微信公众号私信笔者: LangChain智能体开发 免费获得。