前言
pprof是GoLang中最常用的性能分析工具,本篇文章主要来聊聊pprof该怎么用
1 实践Demo
1.1 前置准备
github.com/wolfogre/go... 是非常经典 go pprof 学习案例,本文将直接引用该项目作为性能分析的实战素材.
环境准备:使用Linux系统,安装好 graphviz(pprof图形化展示时依赖的软件)
sudo apt install graphvizMac用户可以通过brew安装graphviz
arduino
brew install graphviz // 安装graphviz
dot -V // 验证是否安装成功观察一下 go-pprof-practice 的 main 函数,其中有几个关键的地方:
- 匿名导入了 net/http/pprof pkg
- 调用 runtime.SetMutexProfileFraction 和 runtime.SetBlockProfileRate,启用 block 和 mutex 性能分析(默认是关闭的)
- 异步启动默认的 http server(http.DefaultServerMux,与pprof联动)
- 循环调用一系列 animal 的 live 方法(里面已经提前埋设好一系列的性能炸弹,等待使用 pprof 将之一一逮捕)
go
package main
import (
"log"
"net/http"
// 启用 pprof 性能分析
_ "net/http/pprof"
"os"
"runtime"
"time"
"github.com/wolfogre/go-pprof-practice/animal"
)
func main() {
// ...
runtime.GOMAXPROCS(1)
// 启用 mutex 性能分析
runtime.SetMutexProfileFraction(1)
// 启用 block 性能分析
runtime.SetBlockProfileRate(1)
go func() {
// 启动 http server. 对应 pprof 的一系列 handler 也会挂载在该端口下
if err := http.ListenAndServe(":6060", nil); err != nil {
log.Fatal(err)
}
os.Exit(0)
}()
// 运行各项动物的活动
for {
for _, v := range animal.AllAnimals {
v.Live()
}
time.Sleep(time.Second)
}
}启动项目
go
go run main.go1.2 pprof页面总览
进入 http/pprof 页面:(端口与启动的 http server 一致)
bash
http://localhost:6060/debug/pprof/ 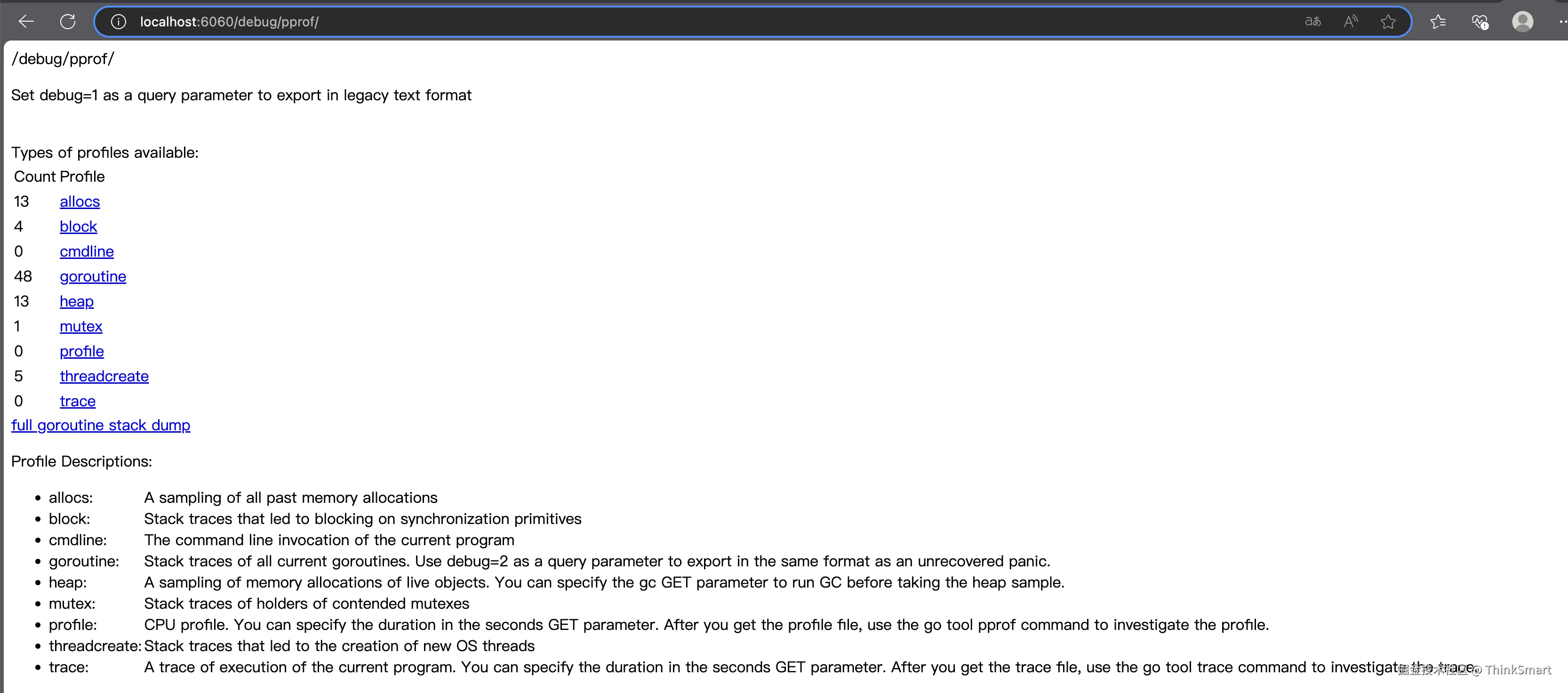
页面中包含各项内容,我们重点关注下面几项指标,下文中逐一展开分析:
- profile:探测各函数对 cpu 的占用情况
- heap:探测内存分配情况
- block:探测阻塞情况 (包括 mutex、chan 等)
- mutex:探测互斥锁占用情况
- goroutine:探测协程使用情况
1.3 CPU分析
cpu 分析是在一段时间内进行打点采样,通过查看采样点在各个函数栈中的分布比例,以此来反映各函数对 cpu 的占用情况.
点击页面上的 profile 后,默认会在停留 30S 后下载一个 cpu profile 文件.
通过交互式指令打开文件后,查看 cpu 使用情况:
go
go tool pprof {YOUR PROFILE PATH}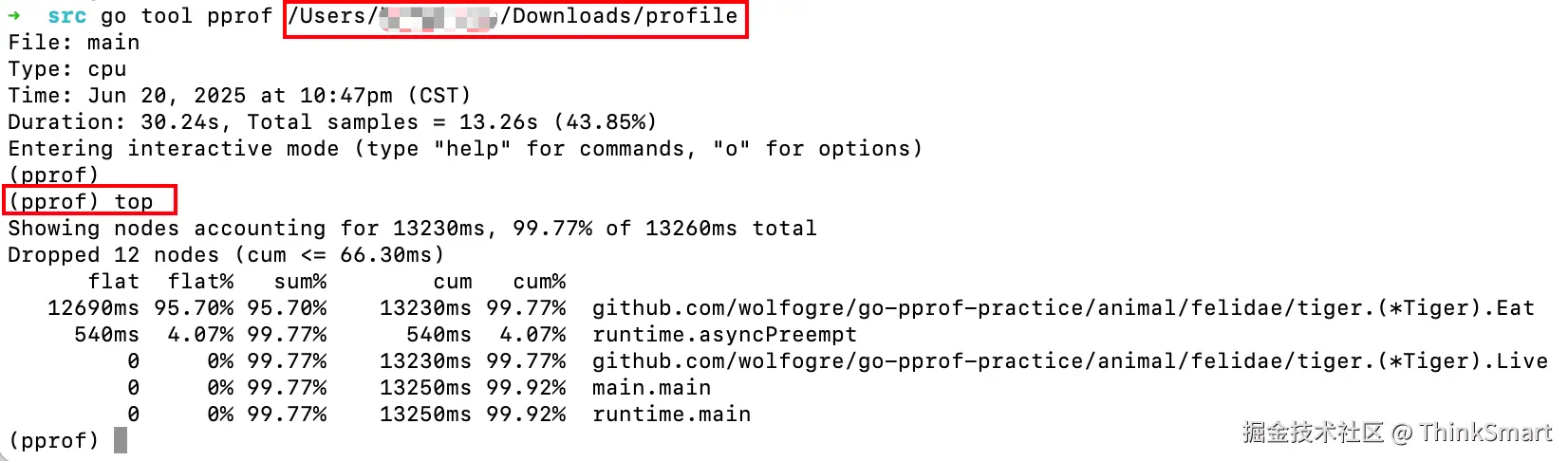
erlang
(pprof) top
Showing nodes accounting for 13230ms, 99.77% of 13260ms total
Dropped 12 nodes (cum <= 66.30ms)
flat flat% sum% cum cum%
12690ms 95.70% 95.70% 13230ms 99.77% github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat
540ms 4.07% 99.77% 540ms 4.07% runtime.asyncPreempt
0 0% 99.77% 13230ms 99.77% github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Live
0 0% 99.77% 13250ms 99.92% main.main
0 0% 99.77% 13250ms 99.92% runtime.main
(pprof) 信息拆解:
-
12690 ms ------ 采样点大约覆盖了 12690 ms 的时长
-
flat:某个函数执行时长(只聚焦函数本身,剔除子函数部分)
- 12690 ms ------ Tiger.Eat 这个方法本身的调用时长
-
flat%:某个函数执行时长(只聚焦函数本身,剔除子函数部分)
-
sum%:某个函数及其之上父函数的总时长占比
-
cum:某个函数及其子函数的总调用时长
- 13230ms ------ Tiger.Eat 加上其调用子函数 runtime.asyncPreempt 的总时长
-
cum%:某个函数及其子函数的调用时长在总时长中的占比
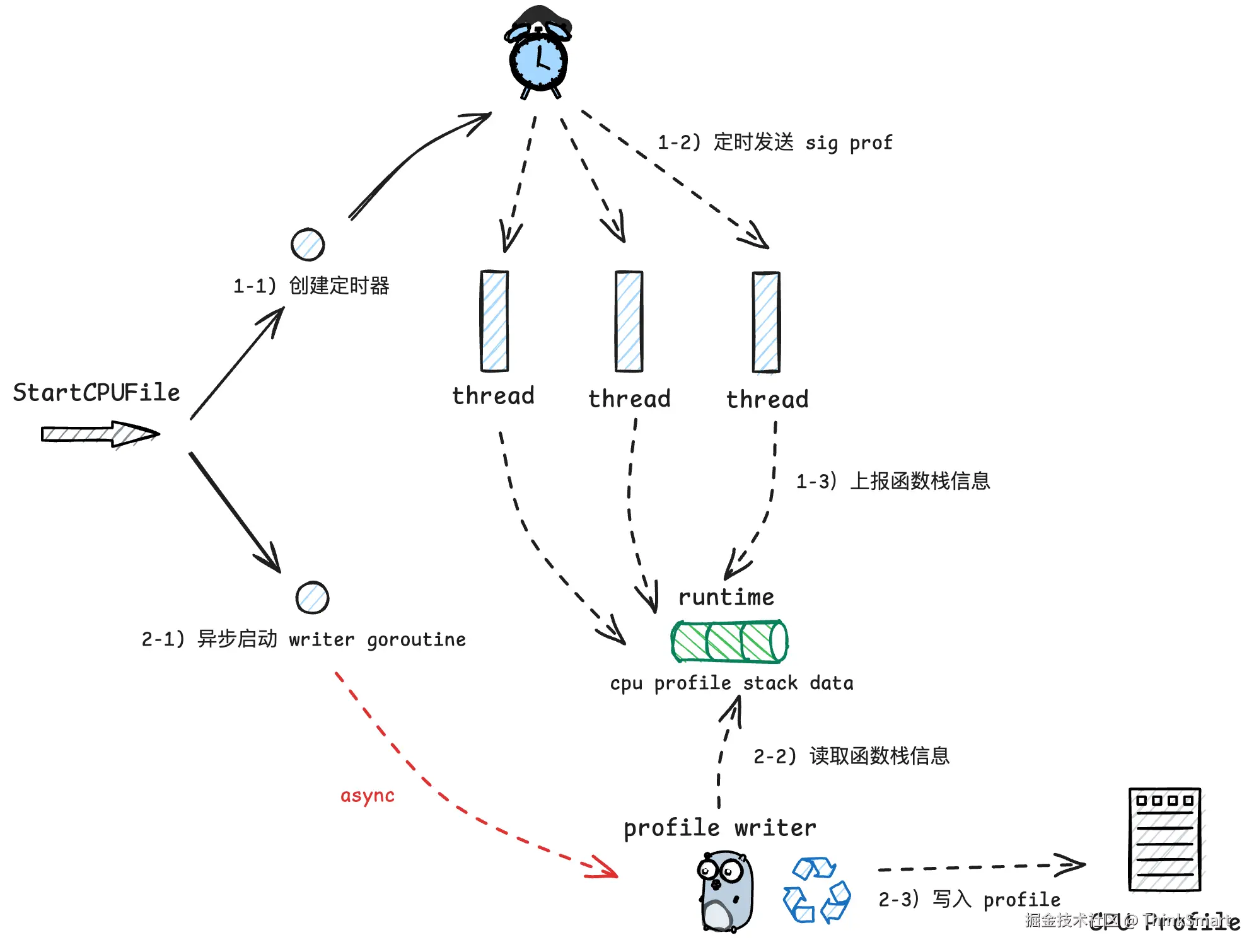
看看 cpu 分析流程,其实现原理是:
- 创建一个 timer,定时向 go 进程中的各个 thread 发送信号
- thread 接收到信号后,会将记录当前函数栈信息
- 通过一个异步 goroutine 持续接收函数栈信息,将其写入到 cpu profile 文件返回给用户
除此之外,还可以通过图形化界面来展示 cpu profile 文件中的内容:
ini
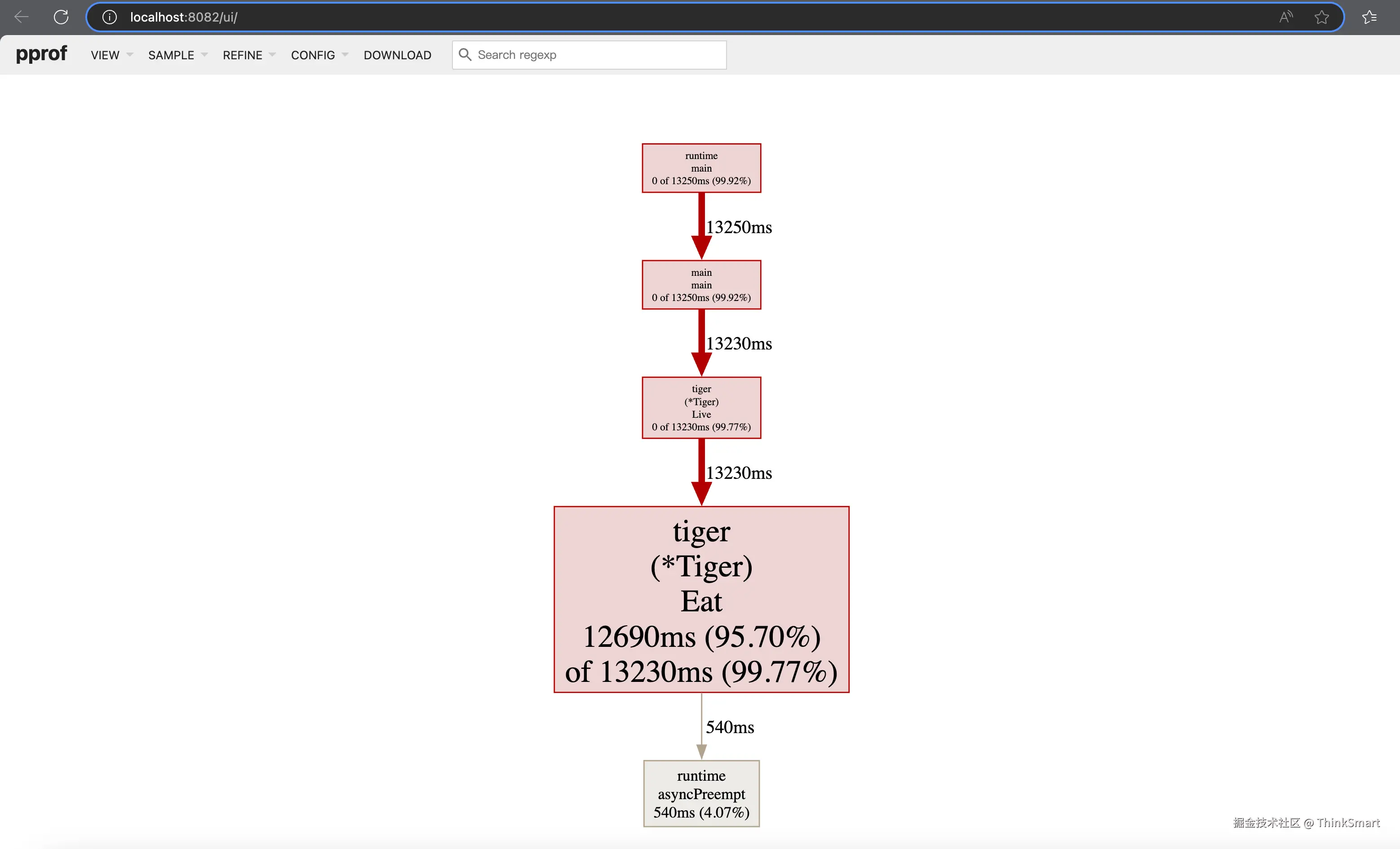
go tool pprof -http=:8082 {YOUR PROFILE PATH}如下图所示,在调用链的拓扑结构中,几项指标是和上述所介绍的内容一一对应的:
此外,如果对于火焰图使用比较习惯,这里也可以启用火焰图的格式: VIEW -> Flame Graph
在 CPU 性能分析中,要定位性能瓶颈可以核心看 flat% 这个指标,在这个案例中不难看出问题症结产生于 Tiger.Eat 函数,我们打开项目代码一探究竟:
go
func (t *Tiger) Eat() {
log.Println(t.Name(), "eat")
loop := 10000000000
for i := 0; i < loop; i++ {
// do nothing
}
}可以看到,作者在这里埋了个炸弹,通过 for 循环大量空转打满 CPU.
另外,这里我们主要注意到另一个细节,是 pprof 告诉我们 Tiger.Eat 中还有个子函数 runtime.asyncPreempt 花费了大约 540 ms 的时间,但是这一点在代码中并没有体现,这又是怎么回事呢?
这里我们需要简单一下在 golang 中关于 goroutine 超时抢占机制的设定:
-
监控线程:在 go 进程启动时,会启动一个 monitor 线程,作为第三方观察者角色不断轮询探测各 g 的执行情况,对于一些执行时间过长的 g 出手干预
- 协作式抢占:当 g 在运行过程中发生栈扩张时(通常由函数调用引起),则会触发预留的检查点逻辑,查看自己若是因为执行过长而被 monitor 标记,则会主动让渡出 m 的执行权
-
在 Tiger.Eat 方法中,由于只是简单的 for 循环空转无法走到检查点,因此这种协作式抢占无法生效
- 非协作式抢占:在 go 1.14 之后,启用了基于信号量实现的非协作抢占机制. Monitor 探测到 g 超时会发送抢占信号,g 所属 m 收到信号后,会修改 g 的 栈程序计数器 pc 和栈顶指针 sp 为其注入 asyncPreempt 函数. 这样 g 会调用该函数完成 m 执行权的让渡
go
// 此时执行方是即将要被抢占的 g,这段代码是被临时插入的逻辑
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
// mcall 切换至 g0,然后完成 g 的让渡
mcall(gopreempt_m)
gp.asyncSafePoint = false
}我在之前发布的文章:温故知新---Golang GMP 万字洗髓经 5.3 小节中对有关 g 超时抢占相关内容展开了详细的分析,大家感兴趣的话可以展开了解.
1.4 heap分析
下面是关于内存的分析流程,点击 heap 进入 http://localhost:6060/debug/pprof/heap?debug=1
在页面的路径中能看到 debug 参数,如果 debug = 1,则将数据在页面上呈现;如果将 debug 设为 0,则会将数据以二进制文件的形式下载,并支持通过交互式指令或者图形化界面对文件内容进行呈现. block/mutex/goroutine 的机制也与此相同,后续章节中不再赘述.
从页面中获取到有关 heap 的信息
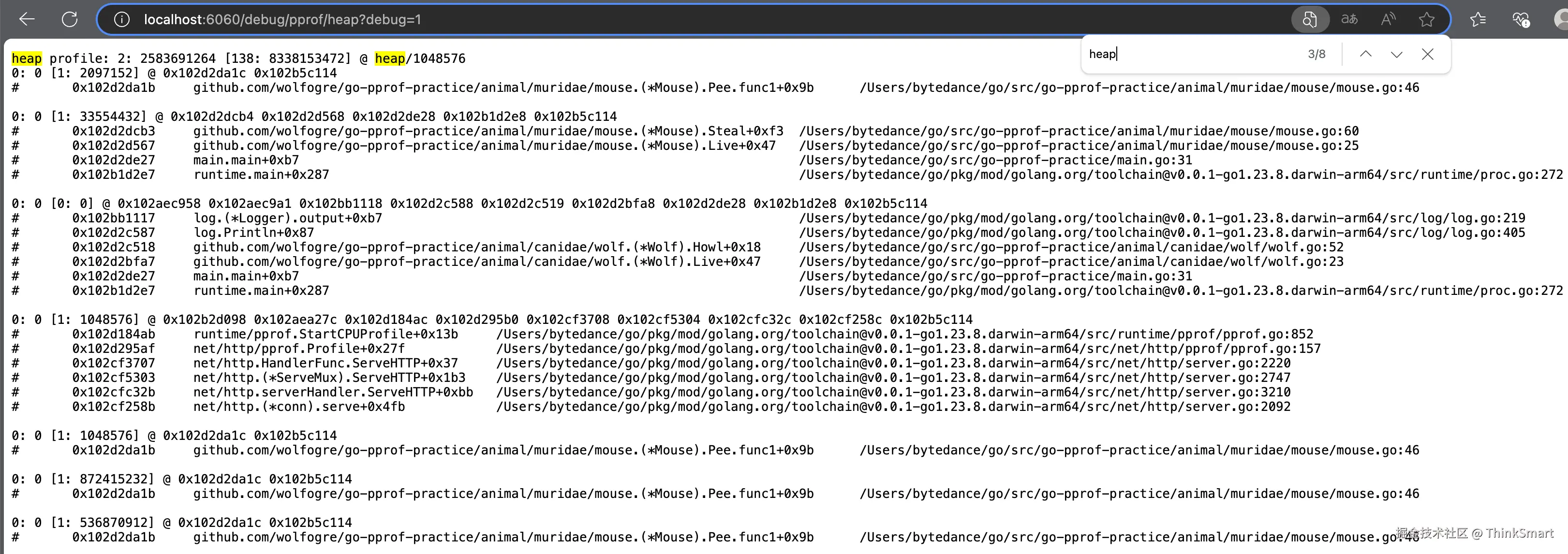
先看内容的第一行:
yaml
heap profile: 2: 2583691264 [138: 8338153472] @ heap/1048576内容含义是在全局视角下的一些信息:
- 2---活跃对象个数
- 2583691264---活跃对象大小(单位 byte)
- 21---历史至今所有对象个数
- 3371171968---历史至今所有对象总计大小(byte)
- 1048576---内存采样频率(约每 M 采样一次)
再看下面的内容:
less
1: 1291845632 [1: 1291845632] @ 0x102d2dcb4 0x102d2d568 0x102d2de28 0x102b1d2e8 0x102b5c114
# 0x102d2dcb3 github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Steal+0xf3 /Users/bytedance/go/src/go-pprof-practice/animal/muridae/mouse/mouse.go:60
# 0x102d2d567 github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Live+0x47 /Users/bytedance/go/src/go-pprof-practice/animal/muridae/mouse/mouse.go:25
# 0x102d2de27 main.main+0xb7 /Users/bytedance/go/src/go-pprof-practice/main.go:31
# 0x102b1d2e7 runtime.main+0x287 /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/proc.go:272对应为某个函数栈中的信息:
- 1-该函数栈上当前存活的对象个数
- 1291845632-当前存活对象总大小(byte)
- \[\] 内的内容也表示历史至今,不再赘述
于是得以定义问题所在的地方是 Mouse.Steal 函数,此处在不断的对 buffer 追加内容:
arduino
func (m *Mouse) Steal() {
log.Println(m.Name(), "steal")
max := constant.Gi
for len(m.buffer)*constant.Mi < max {
m.buffer = append(m.buffer, [constant.Mi]byte{})
}
}1.5 block分析
下面进行阻塞分析,首先明确block分析的含义:
查看某个 goroutine 陷入 waiting 状态(被动阻塞,通常因 gopark 操作触发,比如因加锁、读chan条件不满足而陷入阻塞)的触发次数和持续时长.
pprof 默认不启用 block 分析,若要开启则需要进行如下设置:
scss
runtime.SetBlockProfileRate(1)此处的入参能够控制 block 采样频率:
- 1:始终采用
- <=0:不采样
-
1:当阻塞时长(ns)大于该值则采样,否则有阻塞时长/rate的概率被采样
下面点击页面中的 block,进入 http://localhost:6060/debug/pprof/block?debug=1 查看阻塞信息:
shell
--- contention:
cycles/second=1000000000
206303883866 206 @ 0x102ae9734 0x102d2cbf0 0x102d2c818 0x102d2de28 0x102b1d2e8 0x102b5c114
# 0x102ae9733 runtime.chanrecv1+0x13 /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/chan.go:489
# 0x102d2cbef github.com/wolfogre/go-pprof-practice/animal/felidae/cat.(*Cat).Pee+0x9f /Users/bytedance/go/src/go-pprof-practice/animal/felidae/cat/cat.go:39
# 0x102d2c817 github.com/wolfogre/go-pprof-practice/animal/felidae/cat.(*Cat).Live+0x37 /Users/bytedance/go/src/go-pprof-practice/animal/felidae/cat/cat.go:19
# 0x102d2de27 main.main+0xb7 /Users/bytedance/go/src/go-pprof-practice/main.go:31
# 0x102b1d2e7 runtime.main+0x287 /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/proc.go:272- cycles/second=1000002977------是每秒钟对应的cpu周期数. pprof在反映block时长时,以cycle为单位
- 206303883866------阻塞的cycle数. 可以换算成秒:206303883866/1000002977 ≈ 206s
- 206------发生的阻塞次数
于是我们定位到其中一处引起阻塞的代码是 Cat.Pee,每当函数被调用时会简单粗暴地等待 timer 1S,里面会因读 chan 而陷入阻塞:
scss
func (c *Cat) Pee() {
log.Println(c.Name(), "pee")
<-time.After(time.Second)
}1.6 mutex分析
mutex 分析看的是某个 goroutine 持有锁的时长(mutex.Lock -> mutex.Unlock 之间这段时间),且只有在存在锁竞争关系时才会上报这部分数据.
pprof 默认不开启 mutex 分析,需要显式打开开关:
scss
runtime.SetMutexProfileFraction(1)入参控制的是 mutex 采样频率:
- 1------始终进行采样
- 0------关闭不进行采样
- <0------不更新这个值,只是把之前设的值结果读出来
-
1 ------有 1/rate 的概率下的事件会被采样
点击 mutex 进入 http://localhost:6060/debug/pprof/mutex?debug=1 页面查看信息:
shell
--- mutex:
cycles/second=1000000000
sampling period=1
250337419543 250 @ 0x102d2c714 0x102d2c6d5 0x102b5c114
# 0x102d2c713 sync.(*Mutex).Unlock+0x73 /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/sync/mutex.go:225
# 0x102d2c6d4 github.com/wolfogre/go-pprof-practice/animal/canidae/wolf.(*Wolf).Howl.func1+0x34 /Users/bytedance/go/src/go-pprof-practice/animal/canidae/wolf/wolf.go:58- 1000000000 ------ 每秒下的 cycle 数
- 250337419543 ------ 持有锁的 cycle 总数
- 250 ------ 采样了 250 次
于是定位到占有锁较多的方法是 Wolf.Howl,每次加锁后都睡了一秒:
scss
func (w *Wolf) Howl() {
log.Println(w.Name(), "howl")
m := &sync.Mutex{}
m.Lock()
go func() {
time.Sleep(time.Second)
m.Unlock()
}()
m.Lock()
}1.7 goroutine分析
最后针对 goroutine 进行分析,点击 goroutine 进入http://localhost:6060/debug/pprof/goroutine?debug=1页面获取信息:
shell
goroutine profile: total 48
40 @ 0x102b53d88 0x102b57f10 0x102d2c7b8 0x102b5c114
# 0x102b57f0f time.Sleep+0xdf /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/time.go:300
# 0x102d2c7b7 github.com/wolfogre/go-pprof-practice/animal/canidae/wolf.(*Wolf).Drink.func1+0x27 /Users/bytedance/go/src/go-pprof-practice/animal/canidae/wolf/wolf.go:34
4 @ 0x102b53d88 0x102b57f10 0x102d2d9b0 0x102b5c114
# 0x102b57f0f time.Sleep+0xdf /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/time.go:300
# 0x102d2d9af github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Pee.func1+0x2f /Users/bytedance/go/src/go-pprof-practice/animal/muridae/mouse/mouse.go:43先看第一行:
yaml
goroutine profile: total 48total 173------总计有 173 个 goroutine
然后能够定位到几个创造 goroutine 数量较大的方法:
scss
40 @ 0x102b53d88 0x102b57f10 0x102d2c7b8 0x102b5c114
# 0x102b57f0f time.Sleep+0xdf /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/time.go:300
# 0x102d2c7b7 github.com/wolfogre/go-pprof-practice/animal/canidae/wolf.(*Wolf).Drink.func1+0x27 /Users/bytedance/go/src/go-pprof-practice/animal/canidae/wolf/wolf.go:34
4 @ 0x102b53d88 0x102b57f10 0x102d2d9b0 0x102b5c114
# 0x102b57f0f time.Sleep+0xdf /Users/bytedance/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.8.darwin-arm64/src/runtime/time.go:300
# 0x102d2d9af github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Pee.func1+0x2f /Users/bytedance/go/src/go-pprof-practice/animal/muridae/mouse/mouse.go:43
func (w *Wolf) Drink() {
log.Println(w.Name(), "drink")
for i := 0; i < 10; i++ {
go func() {
time.Sleep(30 * time.Second)
}()
}
}
func (m *Mouse) Pee() {
log.Println(m.Name(), "pee")
go func() {
time.Sleep(time.Second * 30)
max := constant.Gi
for len(m.slowBuffer)*constant.Mi < max {
m.slowBuffer = append(m.slowBuffer, [constant.Mi]byte{})
time.Sleep(time.Millisecond * 500)
}
}()
}最后来到 goroutine 分析流程,比较简单,直接取得 g 的数量并且遍历各个 g 的栈信息即可:

至此,我们把 pprof 中常用的性能分析流程串联了一遍,实战 demo 到此为止.