CI/CD与模型监控平台集成MLOps系统实现的全面路径
随着人工智能(AI)和机器学习(ML)技术在企业和各行业中的快速发展,如何高效地进行模型的开发、部署和持续监控,成为了一个亟待解决的问题。在这个背景下,MLOps(机器学习运维)应运而生,它融合了传统的DevOps理念与机器学习开发的特点,提供了一套完善的解决方案。本篇文章将探讨如何通过CI/CD与模型监控平台的结合,构建高效的MLOps系统。
什么是 MLOps?
MLOps(Machine Learning Operations)是将DevOps理念扩展到机器学习模型的生命周期管理中。其目标是通过自动化的方式提升机器学习模型的开发、部署、维护以及监控效率。MLOps体系通常包括以下几方面:
- CI/CD:持续集成和持续部署,自动化代码测试与部署。
- 模型监控:对模型的性能进行实时监控,及时发现并处理模型的偏差、衰退等问题。
- 数据管理:保证数据的质量、版本控制和监控。
- 自动化流程:对机器学习管道进行自动化,从数据预处理到模型训练再到部署和推理。
MLOps 的关键组成部分
1. CI/CD 流水线
CI/CD 流水线是MLOps的核心部分之一,涉及到持续集成(CI)和持续部署(CD)两个方面。具体来说,CI/CD流水线可以帮助团队实现以下功能:
- 自动化的代码集成:开发人员可以将代码提交到版本控制系统(如Git),CI系统会自动构建、测试并验证代码的有效性。
- 自动化的模型部署:一旦模型经过测试并验证其有效性,CD系统可以自动将其部署到生产环境中,减少人工干预,提高部署效率。
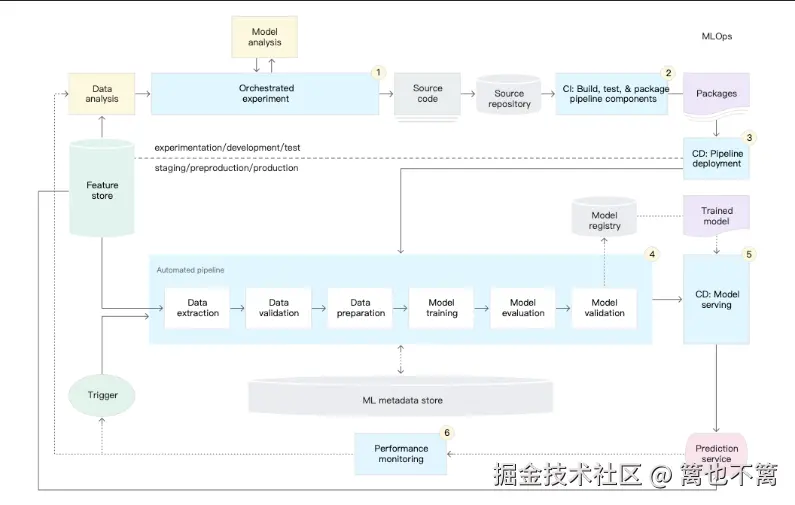
CI/CD 系统设计
CI/CD 流水线设计通常涉及以下步骤:
- 代码提交与自动化构建:开发者将代码推送到Git仓库,CI系统(如Jenkins、GitLab CI)会自动拉取代码并进行构建。
- 单元测试与验证:自动运行单元测试,确保模型和代码的稳定性。
- 模型训练与测试:通过自动化脚本训练机器学习模型,并进行验证。
- 容器化与部署:使用Docker等工具将模型容器化,便于在生产环境中进行部署。
代码示例(基于GitLab CI):
yaml
stages:
- build
- test
- deploy
build:
stage: build
script:
- echo "Building the model..."
- python train_model.py
test:
stage: test
script:
- echo "Testing the model..."
- python test_model.py
deploy:
stage: deploy
script:
- echo "Deploying the model..."
- docker build -t my_model .
- docker run -d -p 5000:5000 my_model2. 模型监控平台
模型部署到生产环境后,监控其性能是确保模型持续有效的重要环节。模型监控平台可以实时跟踪模型的行为、性能以及预测的准确性,并能够自动发现模型衰退或偏差问题。
监控指标
常见的模型监控指标包括:
- 精度与召回率:对分类模型的性能进行评估。
- AUC (Area Under the Curve):用于二分类模型的性能评估。
- 模型漂移与数据漂移:监控模型输出结果与训练数据分布之间的差异。
- 预测延迟与吞吐量:评估模型在生产环境中的响应速度。
构建模型监控系统
在实际操作中,常用的监控工具包括Prometheus和Grafana等。通过Prometheus收集模型性能指标,并使用Grafana展示监控数据,形成一个可视化的监控面板。
代码示例(使用Prometheus进行监控):
python
from prometheus_client import start_http_server, Summary
import random
import time
# 创建一个用来监控请求延迟的Prometheus摘要指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
@REQUEST_TIME.time()
def process_request():
"""模拟处理请求的延迟"""
time.sleep(random.uniform(0.1, 1.0))
if __name__ == '__main__':
# 启动Prometheus HTTP服务器
start_http_server(8000)
while True:
process_request()集成监控与报警机制
监控不仅仅是为了观察数据,还要及时预警并触发相应的处理机制。例如,如果检测到模型的性能下降,系统可以自动启动重训练流程,或者通过Webhook通知开发人员。
代码示例(基于Slack的报警通知):
python
import requests
def send_alert(message):
slack_url = 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
payload = {'text': message}
response = requests.post(slack_url, json=payload)
if response.status_code != 200:
raise Exception(f"Failed to send alert: {response.text}")
# 模拟模型精度下降,发送报警
model_accuracy = 0.85
if model_accuracy < 0.9:
send_alert(f"Warning: Model accuracy is below threshold: {model_accuracy}")构建高效的 MLOps 系统
构建一个高效的MLOps系统,不仅仅依赖于CI/CD与监控平台,还需要确保数据管理、版本控制、自动化流程等环节的无缝衔接。以下是几个关键的实践建议:
1. 自动化模型训练与部署
通过CI/CD流水线实现自动化的训练与部署流程,减少人工干预,提升开发效率。
2. 建立健全的数据管理机制
数据是机器学习模型的核心。构建一个完善的数据管理体系,包括数据的版本控制、质量控制以及实时更新。
3. 强化模型监控与反馈机制
确保模型在生产环境中的表现稳定,并及时发现性能问题。利用监控平台实时反馈,及时调整和优化模型。
4. 持续集成与反馈
通过CI/CD的快速反馈机制,不断迭代与优化模型,确保模型的长期有效性。
MLOps 实现路径中的挑战与应对
在实现 MLOps 系统的过程中,往往会遇到一系列挑战,主要包括模型的可重现性、跨团队协作问题以及大规模数据和模型的管理问题。本文将继续探讨这些挑战以及如何有效应对。 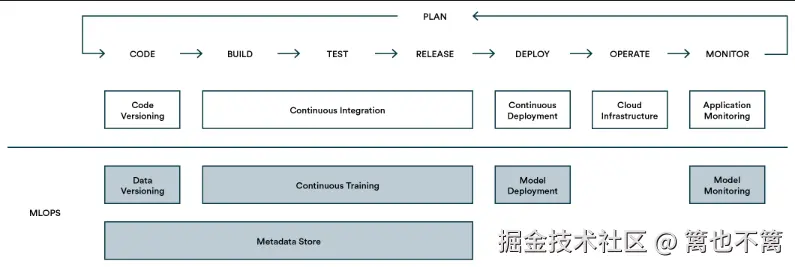
1. 模型的可重现性与可追溯性
在机器学习项目中,模型的可重现性是一个关键问题。模型训练过程中的随机性(例如初始化权重、训练数据的划分等)可能导致相同的代码、相同的数据集产生不同的结果。为了保证模型的可重现性,必须使用合适的版本控制和数据管理工具。
解决方案:
-
模型和代码版本管理:通过Git进行代码版本控制,同时使用DVC(Data Version Control)管理数据集和训练结果。DVC能够为每次模型训练生成唯一的哈希值,使得每次训练都具有可追溯性。
-
环境管理:通过Docker容器化环境,确保训练和推理环境的一致性。使用Dockerfile来定义训练环境,避免环境的不同导致结果的不可重现。
代码示例(使用DVC管理数据):
bash
# 初始化DVC仓库
dvc init
# 跟踪数据集文件
dvc add data/dataset.csv
# 提交数据文件
git add data/dataset.csv.dvc
git commit -m "Add dataset for model training"2. 跨团队协作与模型开发
机器学习项目通常涉及多个团队,包括数据科学团队、开发团队和运维团队。如何使这些团队在不同阶段顺畅协作,是一个重要挑战。特别是在模型的开发、测试和部署之间,往往需要频繁的沟通与协作。
解决方案:
-
团队协作工具:使用Jupyter Notebooks、Colab等工具进行数据科学实验的协作,同时结合Git进行版本管理,确保不同团队能够在同一代码库上进行工作。
-
敏捷开发与迭代:采用敏捷开发方法,确保每个阶段都能快速反馈并调整。在CI/CD流水线中集成自动化测试,帮助开发团队和数据科学团队保持一致。
代码示例(在GitHub中协作开发):
bash
# 拉取远程代码库
git pull origin main
# 创建新的分支进行开发
git checkout -b feature/new-model
# 提交开发结果
git commit -m "Add new model version"3. 数据和模型的规模化管理
随着数据量的增大和模型复杂度的提高,如何高效地管理大规模数据和复杂模型,成为MLOps系统中一个重要问题。传统的单机环境已经无法满足大规模数据处理和模型训练的需求。
解决方案:
-
分布式数据存储:采用分布式存储系统(如HDFS、S3)来存储大规模数据,并结合DVC来管理数据版本。
-
分布式训练:通过分布式训练框架(如TensorFlow、PyTorch等)来加速大规模模型的训练,同时使用Kubernetes等容器编排工具进行资源的动态调度。
-
模型压缩与优化:为了在生产环境中提高推理速度,采用模型压缩技术(如剪枝、量化等)来减小模型体积,提升推理效率。
代码示例(使用Kubernetes进行分布式训练):
bash
# 创建Kubernetes集群
kubectl create -f kubernetes/deployment.yaml
# 启动分布式训练作业
kubectl apply -f kubernetes/job.yaml4. 模型的安全性与合规性
在生产环境中,模型的安全性和合规性是一个重要问题,尤其是在处理敏感数据时。如何防止模型遭受攻击、如何确保模型的公平性和透明性,成为了越来越受关注的议题。
解决方案:
-
模型加密:对模型进行加密存储和传输,防止模型被恶意攻击者篡改或窃取。
-
审计日志:记录每一次模型的训练、更新和推理过程,确保整个模型生命周期的透明性。审计日志可以帮助回溯模型行为,发现潜在的合规问题。
-
模型公平性与偏差检测:定期检查模型的公平性,确保不同群体的用户都能公平地使用模型。同时,监控模型输出,发现可能存在的偏差问题,进行修复。
5. 模型重训练与自动化更新
模型在部署后,可能会因为数据变化、业务需求变动或其他原因而导致性能下降。因此,模型需要定期进行重训练与更新。
解决方案:
-
自动化重训练:根据监控指标(如模型精度、召回率等),当模型性能下降到一定阈值时,自动触发重训练流程。这个过程可以通过CI/CD流水线来实现。
-
增量学习:通过增量学习的方法,使得模型能够在新数据到达时进行在线学习,而不需要从头开始训练。
代码示例(使用Airflow定时任务进行模型重训练):
python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def retrain_model():
print("Retraining the model...")
dag = DAG(
'model_retraining',
description='Automated model retraining',
schedule_interval='@daily', # 每天进行一次重训练
start_date=datetime(2025, 7, 28),
catchup=False,
)
retrain_task = PythonOperator(
task_id='retrain_model_task',
python_callable=retrain_model,
dag=dag,
)
retrain_task未来展望
MLOps作为一个发展中的领域,未来有很大的发展空间。随着人工智能技术的不断进步,MLOps系统将进一步优化,覆盖更多的应用场景。未来的MLOps系统将会更加智能化,能够自适应不同的业务需求,并提供更加高效、自动化的解决方案。
1. 自动化模型调优
未来的MLOps系统将不再仅仅是模型的部署与监控工具,而是一个集成了自动化调优、智能分析的系统。例如,通过自动化超参数调优工具(如Hyperopt、Optuna等),结合自动化监控与反馈,能够实时调整模型参数,提高模型的性能。
2. 异构平台的支持
随着云计算、边缘计算等技术的发展,未来的MLOps系统将能够支持更多的计算平台。无论是在云端进行大规模的模型训练,还是在边缘设备上进行实时推理,MLOps系统都能够进行灵活配置与部署。
3. 无监督与自监督学习
随着无监督学习和自监督学习的不断进步,未来的MLOps系统将能够更好地处理没有标签的数据,通过无监督学习的方法减少对人工标注数据的依赖,降低数据准备的成本。
4. 增强现实与人工智能结合
未来,MLOps可能与增强现实(AR)和虚拟现实(VR)等技术结合,为企业提供更具创新性的解决方案。例如,基于深度学习的视觉识别系统可以结合AR技术,在生产线上提供实时反馈,帮助生产过程优化。
总结
MLOps是机器学习模型在生产环境中持续优化、部署和维护的关键。通过CI/CD流水线和模型监控平台的结合,可以大大提高模型开发和运维的效率,实现高效、稳定的模型服务。随着AI技术的快速发展,MLOps将在企业级AI应用中发挥越来越重要的作用。