TL;DR
- 场景:想用 SQL 写实时任务,同时复用到批处理;需要一个能 3 分钟跑起来的"最小闭环"。
- 结论 :用本文的依赖与样例,直接跑通 Table API ⇄ SQL 的互操作;数据从 DataStream 转表,输出用
toChangelogStream(新写法)打印验证。 - 产出:MRE 工程骨架、现代依赖清单、流式窗口/时态表的写法对照、常见坑速查卡。


Flink SQL
Flink SQL 是 Apache Flink 提供的一种高层次的查询语言接口,它基于 SQL 标准,为开发者提供了处理流式数据和批处理数据的能力。Flink SQL 允许用户使用标准 SQL 查询语言在数据流和数据表上执行复杂的操作,适用于多种应用场景,如实时分析、数据流处理、机器学习等。
流与批统一的查询模式
Flink SQL 的一大特点是流处理和批处理的统一性。通过同一套 SQL 语法,用户可以同时处理静态数据(批处理)和动态数据(流处理)。这使得应用程序的开发更加简化,因为可以用相同的逻辑编写实时流数据处理和历史数据的查询。
动态表 (Dynamic Tables)
Flink SQL 通过动态表的概念将流数据建模为不断变化的表。这种动态表随着时间推移不断更新,数据的每个变化(插入、更新、删除)都会影响表的状态。通过动态表的概念,Flink 可以使用 SQL 查询连续的流数据,并在查询执行时获得不断更新的结果。
窗口操作 (Windowing)
在流式数据处理场景中,窗口操作非常重要。Flink SQL 提供了多种类型的窗口操作,包括:
流处理中的窗口类型详解
滚动窗口 (Tumbling Window)
滚动窗口是将数据流按照固定长度分割成一系列不重叠的时间段。每个事件只属于一个窗口,窗口之间没有重叠。这种窗口类型特别适合需要定期计算统计指标的场景。
特点:
- 窗口大小固定且不重叠
- 每个数据元素只属于一个窗口
- 窗口边界对齐整点时间(如整秒、整分钟)
应用场景:
- 每小时计算网站PV/UV
- 每分钟统计交易金额总和
- 每10秒计算传感器平均值
示例: 设置5秒的滚动窗口,系统会在00:00-00:05、00:05-00:10等时间点触发计算,每个5秒时间段内的数据会被独立处理。
滑动窗口 (Sliding Window)
滑动窗口允许窗口之间存在重叠部分,数据可能被分配到多个窗口中。这种窗口通过两个参数定义:窗口大小和滑动步长。
特点:
- 窗口可以重叠
- 单个数据可能出现在多个窗口
- 需要定义窗口长度和滑动间隔
应用场景:
- 每1分钟计算过去5分钟的平均温度(窗口5分钟,滑动1分钟)
- 实时计算最近1小时内每10分钟的活跃用户数
- 金融交易中的移动平均线计算
实现方式:
- 当滑动步长小于窗口长度时产生重叠
- 例如:10分钟窗口,5分钟滑动 → 每个数据会出现在2个窗口中
会话窗口 (Session Window)
会话窗口根据活动事件之间的间隔动态确定窗口边界,适合于分析用户行为会话的场景。
特点:
- 窗口大小不固定
- 由活动间隔(会话超时)参数控制
- 适合分析用户行为模式
工作方式:
- 当新事件到达时,检查是否在现有会话的超时范围内
- 如果是,则扩展该会话窗口
- 如果不是,则关闭当前会话并开启新会话
应用场景:
- 用户网站访问会话分析(30分钟无活动则结束会话)
- 游戏玩家行为分析
- 物联网设备间歇性数据传输
配置参数:
- 会话间隔(Session Gap):决定会话结束的超时时间
- 最大持续时间:避免异常情况导致会话无限延长
连接操作 (Joins)
Flink SQL 支持多种连接操作:
- 流与流的连接:允许用户将多个流结合在一起,基于时间或键进行匹配。
- 流与表的连接:将静态表与流数据进行匹配,从而使流式数据处理能够结合历史数据或参考数据。
- 时态表连接 (Temporal Table Join):用于将流数据与一个时态表进行连接,时态表会随着时间不断更新。
内置函数和自定义函数
Flink SQL 提供了丰富的内置函数,涵盖了字符串操作、数学运算、时间日期处理、聚合操作等。此外,Flink SQL 还支持用户自定义函数(UDF、UDTF、UDAF),用户可以根据具体需求扩展 SQL 的功能。
Table API 与 SQL API 的互操作性
Flink 提供了两种高级数据处理 API:
- Table API:一种与关系代数类似的编程接口,支持链式调用,功能类似于 SQL。
- SQL API:用户可以直接使用标准 SQL 语句进行数据处理。
Table API 和 SQL API 具有很高的互操作性,用户可以在同一个程序中混合使用这两者。例如,可以先用 Table API 进行表定义和部分操作,再通过 SQL 语句执行复杂的查询。
支持多种数据源和数据接收器
Flink SQL 支持连接多种数据源和数据接收器,如 Kafka、文件系统、数据库(如 MySQL、PostgreSQL)、Hive、HBase 等。通过 SQL 语法,用户可以轻松地将流数据写入这些外部系统,也可以从这些系统中读取数据进行处理。
状态管理与容错机制
Flink SQL 继承了 Flink 强大的状态管理和容错机制。在流处理任务中,Flink SQL 能够有效地处理有状态的计算,并保证在失败时自动恢复。基于 Flink 的检查点(Checkpointing)和保存点(Savepoint)机制,Flink SQL 提供了 Exactly-Once 的状态一致性保障。
实时分析与 ETL
Flink SQL 可以用于实时数据的分析与处理,常用于构建实时 ETL (Extract, Transform, Load) 流程。例如,用户可以通过 SQL 查询对从 Kafka、数据库等数据源接收到的流数据进行清洗、过滤、转换,并将结果写入到其他系统中(如 Elasticsearch、HDFS、JDBC)。
HelloWorld
添加依赖
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<type>pom</type>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>依赖说明:
- flink-table-api-java-bridge_2.12:桥接器,主要负责 TableAPI 和 DataStream/DataSetAPI 的连接支持,按照语言分Java和Scala。
- flink-table-planner-blink_2.12:计划期,是TableAPI最主要的部分,提供了运行时环境和生成程序执行计划的Planner。
- 如果是生产环境,则已经有 planner,就只需要有bridge就可以了
- flink-table:基础依赖
编写代码
java
package icu.wzk;
public class TableApiDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
DataStreamSource<Tuple2<String, Integer>> data = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (true) {
ctx.collect(new Tuple2<>("name", 10));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
});
// =======================
// Table 方式
Table table = tableEnvironment.fromDataStream(data, $("name"), $("age"));
// 对Table的数据查询
Table name = table.select($("name"));
// 将数据输出到控制台
DataStream<Tuple2<Boolean, Row>> result = tableEnvironment.toRetractStream(name, Row.class);
result.print();
System.out.println("=========================");
// =======================
// SQL 方式
tableEnvironment.createTemporaryView("users",data, $("name"), $("age"));
String sql = "select name from users";
table = tableEnvironment.sqlQuery(sql);
result = tableEnvironment.toRetractStream(table, Row.class);
result.print();
System.out.println("=========================");
env.execute("TableApiDemo");
}
}运行代码
控制台会一直不间断的输出如下的内容:
shell
1> (true,name)
6> (true,name)
...
2> (true,name)
6> (true,name)
3> (true,name)控制台的运行结果如下所示: 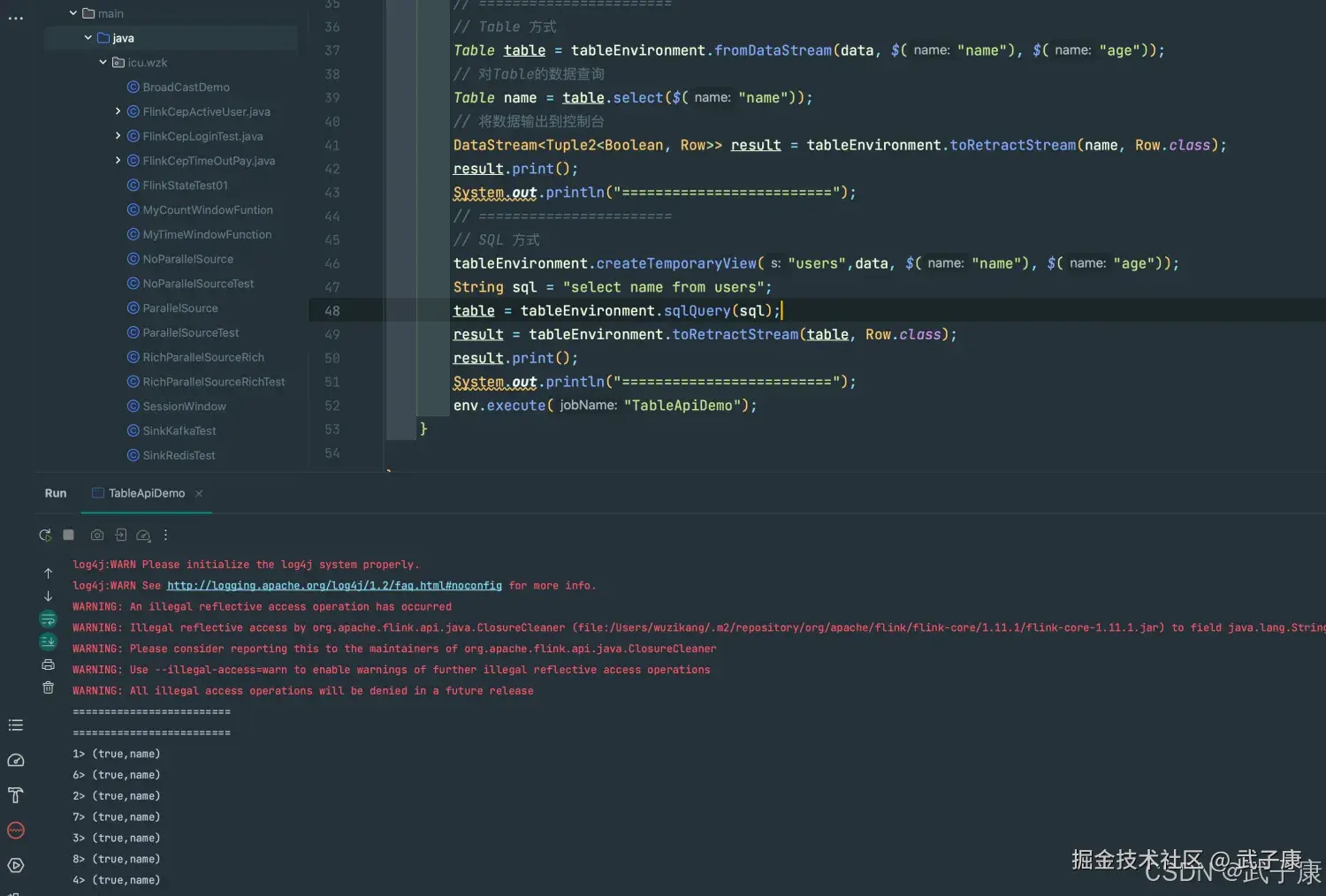
新版本
Maven
xml
<!-- 统一使用同一版本号 -->
<properties>
<flink.version>1.20.0</flink.version> <!-- 按你实际装的版本改 -->
<java.version>17</java.version>
</properties>
<dependencies>
<!-- 基础流处理 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Table API(Java) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- DataStream ⇄ Table 的桥接 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Planner(提供运行期支持;通常标 provided 交给集群环境) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>编写代码
java
package icu.wzk;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
public class TableApiDemo {
public static void main(String[] args) throws Exception {
// 1) 基本环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 2) 准备一组确定性数据(便于验证)
var ds = env.fromElements(
Tuple2.of("alice", 10),
Tuple2.of("bob", 20),
Tuple2.of("alice", 30)
);
// 3) DataStream -> Table(起列名)
Table t = tEnv.fromDataStream(ds).as("name", "age");
// 4) Table API:只选 name
Table namesByApi = t.select($("name"));
// 5) SQL:注册临时视图 + 查询
tEnv.createTemporaryView("users", t);
Table namesBySql = tEnv.sqlQuery("SELECT name FROM users");
// 6) 输出:用新写法 toChangelogStream 验证增量结果
tEnv.toChangelogStream(namesByApi, Row.class).print("API");
tEnv.toChangelogStream(namesBySql, Row.class).print("SQL");
env.execute("Flink SQL HelloWorld");
}
}预期结果
shell
API> +I[alice]
API> +I[bob]
API> +I[alice]
SQL> +I[alice]
SQL> +I[bob]
SQL> +I[alice]其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接