本章内容包括:
- 什么是智能代理式RAG(Agentic RAG)
- 为什么我们需要智能代理式RAG
- 如何实现智能代理式RAG
在前面的章节中,我们已经了解了如何使用不同的向量相似度搜索方法找到相关数据。利用相似度搜索,我们可以在无结构数据源中检索相关数据,但结构化数据往往比无结构数据更有价值,因为结构本身就包含了信息。
为数据添加结构可以是一个渐进的过程。我们可以从简单的结构开始,逐步增加更复杂的结构。上一章中我们已经看到,从简单的图数据开始,逐步添加了更复杂的结构。
智能代理式RAG系统(见图5.1)是指拥有多种检索代理的系统,用于检索回答用户问题所需的数据。智能代理式RAG系统的起始接口通常是一个检索器路由器(retriever router),其职责是找到最适合执行当前任务的检索器(或多个检索器)。
实现智能代理式RAG系统的一种常见方法是利用大型语言模型(LLM)调用工具的能力(有时称为函数调用)。并非所有LLM都具备此能力,但OpenAI的GPT-3.5和GPT-4拥有,且本章将以此为基础进行讲解。大多数LLM也可以通过ReAct方法实现此功能(参见 arxiv.org/abs/2210.03...),预计未来所有LLM都会支持这一特性。
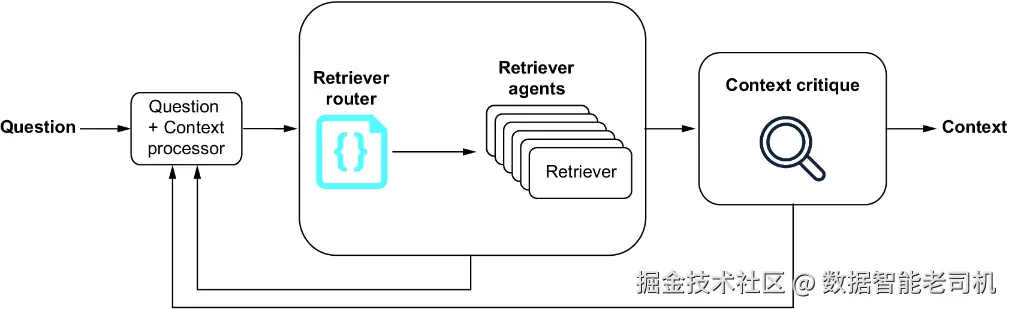
5.1 什么是智能代理式RAG?
智能代理系统的复杂度和功能各不相同,但核心理念是系统能够代表用户执行任务。本章将介绍一个基础的智能代理系统,其中系统只需选择使用哪个检索器,并判断所找到的上下文是否能回答问题。在更高级的系统中,系统甚至可能制定解决当前任务所需执行的操作计划。从基础入手是理解智能代理系统核心概念的好方法,而对于RAG任务来说,这通常已足够。
智能代理式RAG系统是指具备多种检索代理的系统,用于检索回答用户问题所需的数据。成功的智能代理式RAG系统需要以下几个基础组件:
- 检索器路由器(Retriever router)------接受用户问题,返回最适合使用的检索器或检索器集合。
- 检索器代理(Retriever agents)------实际执行数据检索的检索器,用以回答用户问题。
- 答案评判器(Answer critic)------接收检索器返回的答案,判断是否正确回答了原始问题。
5.1.1 检索器代理
检索器代理即用于检索数据以回答用户问题的实际检索器。这些检索器可能非常宽泛,比如向量相似度搜索;也可能非常具体,比如接受参数的硬编码数据库查询模板(见5.1.2节关于检索器路由器的内容)。
多数智能代理RAG系统会用到一些通用检索器,如向量相似度搜索和text2cypher。前者适合无结构数据源,后者适合图数据库中的结构化数据。但在现实生产环境中,要使它们达到用户期望的表现并非易事。
因此,我们需要专门的检索器,虽然覆盖范围窄,但在其擅长的领域表现极佳。这些专用检索器可以随着时间积累,当发现通用检索器难以生成正确查询时逐步构建。
5.1.2 检索器路由器
为了选择合适的检索器,我们引入了检索器路由器这一概念。检索器路由器是一个函数,接受用户问题,返回最佳检索器或检索器组合。路由器的决策方式各异,通常采用LLM辅助判断。
举例来说,假设有问题"法国的首都是什么?",且已编写两个可用的检索器代理(均从数据库中检索答案):
- capital_by_country------接受国家名称,返回该国首都。
- country_by_capital------接受首都名称,返回对应国家。
这两个检索器均为带参数的硬编码数据库查询。
检索器路由器可以是一个接受用户问题的LLM,并返回应使用的检索器及参数。在此例中,LLM可返回capital_by_country检索器,并提取参数"France",最终调用形式为 capital_by_country("France")。
该示例较简单,现实中可能有多个检索器可选。检索器路由器往往是复杂函数,借助LLM选择最合适的检索器执行任务。
5.1.3 答案评判器
答案评判器是一个函数,接受检索器返回的答案,判断是否正确回答了原始问题。答案评判器是阻塞型函数,若答案不正确或不完整,可阻止答案返回给用户。
当阻止返回错误或不完整答案时,答案评判器应生成一个新的问题,用以重新检索正确答案,进入新一轮检索过程。若正确答案在数据源中不存在,则需设计退出条件,答案评判器应能识别此类情况并向用户返回"答案不可用"的提示信息。
5.2 为什么我们需要智能代理式RAG?
智能代理式RAG的一个重要应用场景是当我们拥有多种数据源,希望根据任务选择最佳数据源时。另一个常见场景是数据源非常广泛或复杂,需要专门的检索器来持续准确地检索所需数据。
如书中前面所述,通用检索器如向量相似度搜索能在无结构数据中找到相关信息;而对于结构化数据源(如图数据库),我们可能会使用第4章介绍的text2cypher这类通用检索器。如果数据非常复杂,text2cypher可能难以生成正确查询,这时就需要专门的检索器来精准获取正确数据,例如更窄领域的text2cypher检索器或带参数的硬编码数据库查询。
随着时间推移,我们可以识别出text2cypher等工具难以生成查询以回答的问题,针对这些问题构建专门检索器,并将text2cypher作为"兜底"检索器,用于没有合适专门检索器匹配的情况。
这正是智能代理式RAG大显身手的地方。系统拥有多种检索器,能够为每个任务选择最合适的检索器,并在返回结果前评估答案。在生产环境中,这有助于保持系统性能和答案质量的稳定。
5.3 如何实现智能代理式RAG
本节将介绍智能代理式RAG系统的基础实现。您可以参照配套Jupyter笔记本进行实践:github.com/tomasonjo/k...。
注意:本章示例使用我们称为"电影数据集"的数据集。有关数据集详情及多种加载方式,请见附录。
5.3.1 实现检索器工具
在将用户输入路由给合适的检索器之前,需要先准备好可供路由器选择的检索器。检索器可以非常宽泛,比如向量相似度搜索,也可以非常具体,比如带参数的硬编码数据库查询模板。
本实践示例使用一个简单的检索器列表:两个使用Cypher模板的检索器(分别根据电影标题和演员姓名检索电影信息),以及一个针对所有其他问题使用的text2cypher检索器。如前所述,检索器的有效组合因系统而异,应根据实际需求逐步添加以优化应用性能。
代码示例5.1 可用检索器工具描述
python
text2cypher_description = {
"type": "function",
"function": {
"name": "text2cypher",
"description": "Query the database with a user question. When other tools don't fit, fallback to use this one.",
"parameters": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "The user question to find the answer for",
}
},
"required": ["question"],
},
},
}
def text2cypher(question: str):
"""用用户问题查询数据库。"""
t2c = Text2Cypher(neo4j_driver)
t2c.set_prompt_section("question", question)
cypher = t2c.generate_cypher()
records, _, _ = neo4j_driver.execute_query(cypher)
return [record.data() for record in records]
movie_info_by_title_description = {
"type": "function",
"function": {
"name": "movie_info_by_title",
"description": "Get information about a movie by providing the title",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The movie title",
}
},
"required": ["title"],
},
},
}
def movie_info_by_title(title: str):
"""根据电影标题返回电影信息。"""
query = """
MATCH (m:Movie)
WHERE toLower(m.title) CONTAINS $title
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Person)
OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Person)
RETURN m AS movie, collect(a.name) AS cast, collect(d.name) AS directors
"""
records, _, _ = neo4j_driver.execute_query(query, title=title.lower())
return [record.data() for record in records]
movies_info_by_actor_description = {
"type": "function",
"function": {
"name": "movies_info_by_actor",
"description": "Get information about a movie by providing an actor",
"parameters": {
"type": "object",
"properties": {
"actor": {
"type": "string",
"description": "The actor name",
}
},
"required": ["actor"],
},
},
}
def movies_info_by_actor(actor: str):
"""根据演员返回电影信息。"""
query = """
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Person)
OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Person)
WHERE toLower(a.name) CONTAINS $actor
RETURN m AS movie, collect(a.name) AS cast, collect(d.name) AS directors
"""
records, _, _ = neo4j_driver.execute_query(query, actor=actor.lower())
return [record.data() for record in records]请注意,neo4j_driver和text2cypher是本书代码仓库中已实现的导入模块。
注意:上述检索器定义遵循了本书撰写时OpenAI工具的格式规范。
在向LLM描述检索器时需谨慎,确保LLM理解各检索器功能,并能正确判断使用哪个检索器。参数的描述同样非常重要,方便LLM正确调用检索器。
需要注意的是,LLM本身不能直接调用检索器;它只能决定使用哪个检索器及传递哪些参数。真正调用检索器的操作由调用LLM的系统执行,下一节将展示相关实现。
关于通用检索工具的说明
在我们的智能代理式RAG系统中,几乎总会包含一个通用检索工具,用于当问题的答案已经包含在问题本身或上下文其他部分时直接提取答案。这个工具通常是一个简单的函数,从问题或上下文中提取答案并返回。
例如,针对问题"Dave Smith的姓是什么?",该检索工具的实现示例如下:
代码示例5.2 已在上下文中给出答案的通用检索工具
python
answer_given_description = {
"type": "function",
"function": {
"name": "answer_given",
"description": "If a complete answer to the question is already provided in the conversation, use this tool to extract it.",
"parameters": {
"type": "object",
"properties": {
"answer": {
"type": "string",
"description": "The answer to the question",
}
},
"required": ["answer"],
},
},
}
def answer_given(answer: str):
"""从给定文本中提取答案。"""
return answer5.3.2 实现检索器路由器
检索器路由器是智能代理式RAG系统的核心部分,负责接收用户问题并返回最合适的检索器。
在实现路由器时,我们将使用大型语言模型(LLM)辅助。具体做法是将可用检索器列表和用户问题传入LLM,LLM返回最佳检索器。为简化实现,我们使用支持官方工具调用(function-calling)的LLM,如OpenAI的GPT-4o。其他LLM也能实现类似功能,但具体实现方式可能不同。
在深入路由函数前,需要准备以下几个关键模块:
- 处理LLM发起的工具调用
- 持续更新查询
- 将问题路由到相关检索器
------处理LLM工具调用
当LLM返回最佳检索器后,系统需要实际调用该检索器。可以通过一个函数实现,传入检索器名称和参数,调用对应函数。示例如下:
ini
def handle_tool_calls(tools: dict[str, any], llm_tool_calls: list[dict[str, any]]):
output = []
if llm_tool_calls:
for tool_call in llm_tool_calls:
function_to_call = tools[tool_call.function.name]["function"]
function_args = json.loads(tool_call.function.arguments)
res = function_to_call(**function_args)
output.append(res)
return output其中,tools是检索器字典,键为工具名,值为对应函数;llm_tool_calls是LLM决定调用的工具及参数列表。LLM可能会为一个问题调用多个函数。llm_tool_calls的示例结构:
python
[
{
"function": {
"name": "answer_given",
"arguments": "{"answer": "Dave Smith"}"
}
}
]------持续更新查询
后续章节中,我们将发现路由器会按顺序将问题逐一发送给LLM。这种设计便于LLM逐个处理问题,也便于问题被路由到正确的检索器。
顺序处理还有一个好处:可以用前一个问题的答案来重写后续问题,特别是当用户问依赖先前答案的追问时。
示例:问题"谁获得过最多奥斯卡?那人还活着吗?"可拆成"谁获得最多奥斯卡?"和"那个人还活着吗?"两个问题,后者依赖前者答案。
获取首个问题答案后,我们需用新信息更新剩余问题。通过调用查询更新器实现,输入为原始问题和检索器答案,输出为更新后的问题。示例如下:
python
query_update_prompt = """
You are an expert at updating questions to make them more atomic, specific, and easier to find the answer to.
You do this by filling in missing information in the question, with the extra information provided to you in previous answers.
You respond with the updated question that has all information in it.
Only edit the question if needed. If the original question already is atomic, specific, and easy to answer, you keep the original.
Do not ask for more information than the original question. Only rephrase the question to make it more complete.
JSON template to use:
{
"question": "question1"
}
"""
def query_update(input: str, answers: list[any]) -> str:
messages = [
{"role": "system", "content": query_update_prompt},
*answers,
{"role": "user", "content": f"The user question to rewrite: '{input}'"},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages, model = "gpt-4o", config=config, )
try:
return json.loads(output)["question"]
except json.JSONDecodeError:
print("Error decoding JSON")
return []这样,我们能随着进展实时更新问题,保证问题尽可能完整,方便找到准确答案。
------问题路由
检索器路由器的最后一步是将问题路由给合适的检索器。具体做法是将问题和可用工具传入LLM,LLM返回每个问题应使用的最佳检索器。
首先,需要将工具整理成字典,便于传给LLM,也方便实际调用时查找。示例如下:
makefile
tools = {
"movie_info_by_title": {
"description": movie_info_by_title_description,
"function": movie_info_by_title
},
"movies_info_by_actor": {
"description": movies_info_by_actor_description,
"function": movies_info_by_actor
},
"text2cypher": {
"description": text2cypher_description,
"function": text2cypher
},
"answer_given": {
"description": answer_given_description,
"function": answer_given
}
}然后,向LLM描述任务的提示示例如下:
ini
tool_picker_prompt = """
Your job is to choose the right tool needed to respond to the user question.
The available tools are provided to you in the request.
Make sure to pass the right and complete arguments to the chosen tool.
"""这是一个简短提示,但足够指导支持工具调用的LLM选出正确检索器。
接下来是调用LLM的函数示例:
python
def route_question(question: str, tools: dict[str, any], answers: list[dict[str, str]]):
llm_tool_calls = tool_choice(
[
{
"role": "system",
"content": tool_picker_prompt,
},
*answers,
{
"role": "user",
"content": f"The user question to find a tool to answer: '{question}'",
},
],
model = "gpt-4o",
tools=[tool["description"] for tool in tools.values()],
)
return handle_tool_calls(tools, llm_tool_calls)该函数接收单个问题、可用工具和之前问题的答案。调用LLM后,LLM返回该问题应使用的最佳检索器,最后调用前文的handle_tool_calls函数实际执行检索。
------整体流程整合
检索器路由器的最终任务是将上述各部分串联起来,从用户输入一路处理到返回答案。需要确保系统遍历所有问题,并随着信息更新逐步完善问题。
示例代码如下:
python
def handle_user_input(input: str, answers: list[dict[str, str]] = []):
updated_question = query_update(input, answers)
response = route_question(updated_question, tools, answers)
answers.append({"role": "assistant", "content": f"For the question: '{updated_question}', we have the answer: '{json.dumps(response)}'"})
return answers这里需要注意,handle_user_input函数可选接收之前的答案列表,便于多轮交互。相关内容将在5.3.3节详细介绍。
至此,我们实现了一个完整的智能代理式RAG系统,可以接收用户输入并返回答案。该系统架构支持按需扩展更多检索器。
下一步,我们还需实现答案评判器,完善整个系统。
5.3.3 实现答案评判器
答案评判器的职责是收集所有检索器返回的答案,检查是否正确回答了原始问题。由于大型语言模型(LLM)具有非确定性,在重写问题、更新问题和路由问题时可能会出错,因此需要通过答案评判器来确保我们真正获得了所需的答案。
以下代码示例展示了给LLM的答案评判指令。
代码示例5.10 答案评判器指令
css
answer_critique_prompt = """
You are an expert at identifying if questions have been fully answered or if there is an opportunity to enrich the answer.
The user will provide a question, and you will scan through the provided information to see if the question is answered.
If anything is missing from the answer, you will provide a set of new questions that can be asked to gather the missing information.
All new questions must be complete, atomic, and specific.
However, if the provided information is enough to answer the original question, you will respond with an empty list.
JSON template to use for finding missing information:
{
"questions": ["question1", "question2"]
}
"""我们继续使用前文相同的JSON格式和对LLM的指令。
接下来是调用LLM的函数示例。
代码示例5.11 答案评判器函数
python
def critique_answers(question: str, answers: list[dict[str, str]]) -> list[str]:
messages = [
{
"role": "system",
"content": answer_critique_prompt,
},
*answers,
{
"role": "user",
"content": f"The original user question to answer: {question}",
},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages, model="gpt-4o", config=config)
try:
return json.loads(output)["questions"]
except json.JSONDecodeError:
print("Error decoding JSON")
return []该函数接收原始问题和检索器返回的答案,调用LLM判断是否已正确回答原始问题。如果未正确回答,LLM会返回一组新问题,用以收集缺失信息。
若返回了新问题列表,我们可以再次通过检索器路由器获取缺失信息。同时,需设计退出机制,避免在检索器无法回答原问题时陷入死循环。
5.3.4 整合所有部分
到目前为止,我们已经实现了检索器代理、检索器路由器和答案评判器。最后一步是将它们整合到一个主函数中,该函数接收用户输入,并在答案可用时返回给用户。
以下代码示例展示了主函数的大致结构。先看给LLM的指令:
代码示例5.12 智能代理式RAG主指令
ini
main_prompt = """
Your job is to help the user with their questions.
You will receive user questions and information needed to answer the questions
If the information is missing to answer part of or the whole question, you will say that the information
is missing. You will only use the information provided to you in the prompt to answer the questions.
You are not allowed to make anything up or use external information.
"""这里强调LLM只能使用提示中提供的信息来回答问题,确保系统输出的一致性和答案的可信度。
接下来是主函数示例:
代码示例5.13 智能代理式RAG主函数
python
def main(input: str):
answers = handle_user_input(input)
critique = critique_answers(input, answers)
if critique:
answers = handle_user_input(" ".join(critique), answers)
llm_response = chat(
[
{"role": "system", "content": main_prompt},
*answers,
{"role": "user", "content": f"The user question to answer: {input}"},
],
model="gpt-4o",
)
return llm_response主函数将用户输入传入智能代理式RAG系统,返回答案。如果答案不完整或错误,评判函数会返回一组新问题,用以收集缺失信息。
我们只对答案进行一次评判;若评判后答案仍不完整或错误,则直接将现有答案返回给用户,并依赖LLM告知用户哪些信息不完整。
总结:
- 智能代理式RAG系统拥有多种检索器代理,用以检索回答用户问题所需的数据。
- 系统的主要接口通常是用例路由器或检索器路由器,负责选择最适合的检索器执行任务。
- 智能代理式RAG的基础组件包括检索器代理、检索器路由器和答案评判器。
- 系统主要部分可用支持工具/函数调用的LLM来实现。
- 检索器代理既可以是通用的,也可以是专门定制的,应根据需求逐步增加以提升应用性能。
- 答案评判器负责核查检索器返回的答案是否正确完整。