1. Transformer 模型基础
1.1 Tokenizer 基础
-
Token:可以理解为最小语义单元,表达的意义可以是 word/char/subword。中文翻译的话可以理解为词元、令牌、词。对于多模态模型,图像也可以经过一些处理变为 image tokens embedding 向量。
-
Tokenizer:分词器,作用是将输入文本转换为神经网络可识别的 token-ids(也叫 input ids)。
-
Input ids:LLM 必须的输入,本质是 tokens 索引,即整数向量。
-
Attention Mask:是二进制张量类型,针对 batch 输入中序列长度不一的场景,值为 1 表示实际的内容 token,0 表示填充 token。
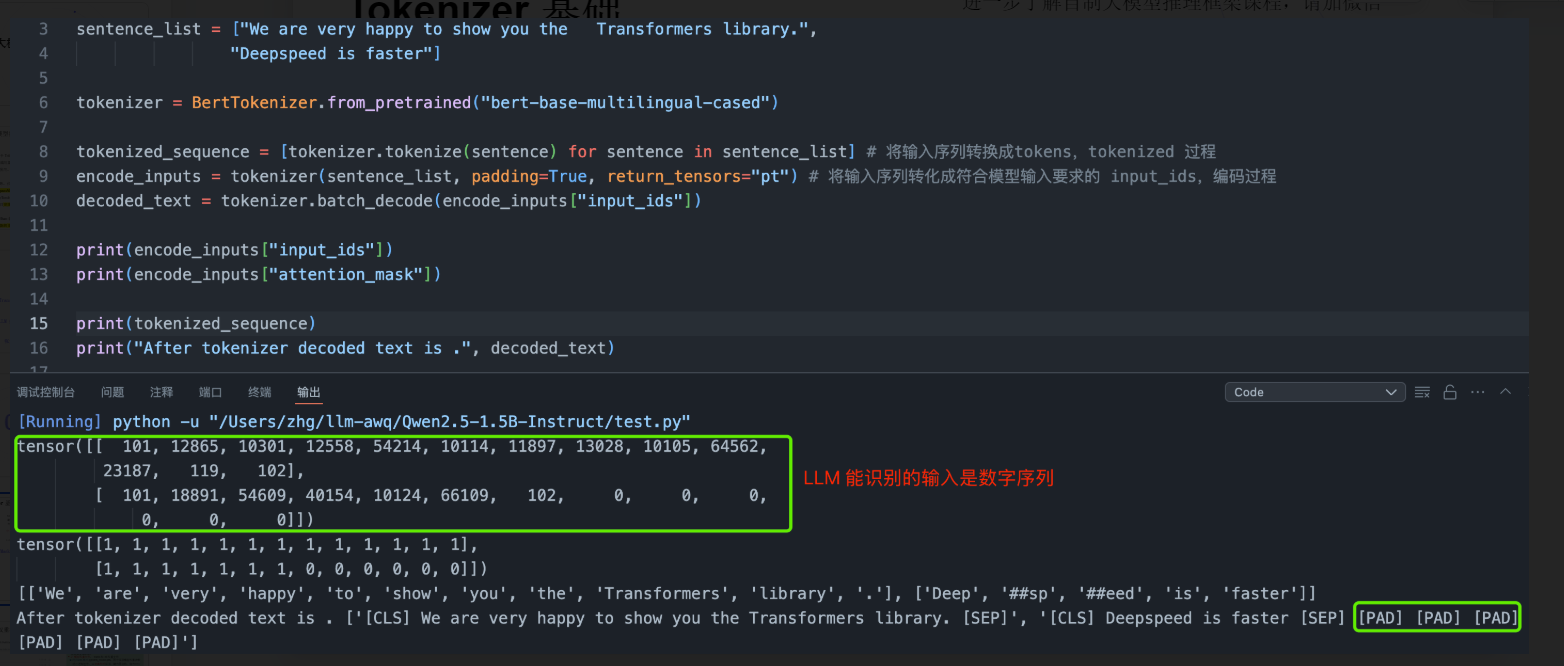
1.2 HF 模型权重拆解
模型配置文件
- config.json:存储模型架构的元数据,包括网络层数、隐藏层维度、注意力头数、词表大小、激活函数类型等参数。
模型权重文件
-
PyTorch 格式 :
pytorch_model.pth,用于保存模型权重参数的二进制文件,以字典形式保存,键为层名称,值为对应的权重张量数据。 -
SafeTensors 格式 :
model.safetensors,和 pth 权重文件功能相同,区别是采用安全序列化格式,避免反序列化漏洞风险。 -
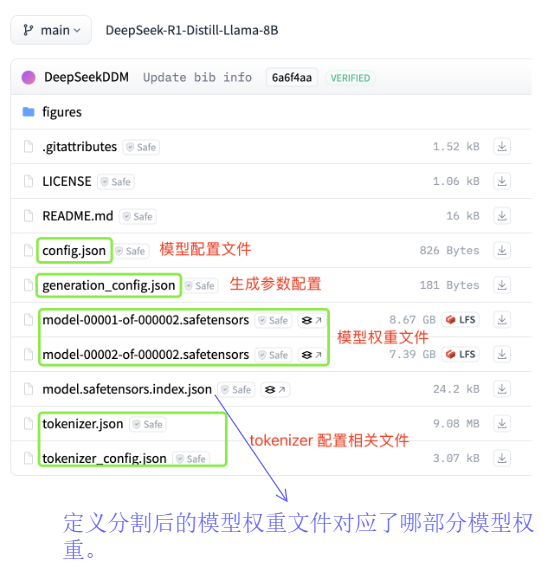
分片权重文件:对于超大型模型权重,会被分割为多个文件,解决文件体积限制问题。
分词相关器文件
-
tokenizer_config.json:分词器类型(如 Qwen2Tokenizer)、特殊标记(CLS、SEP)定义。
-
tokenizer.json:将分词器的所有配置信息(包括词汇表 vocab、合并规则 merges、归一化、预分词、后处理等)打包在一起,目的是让训练和推理过程中的分词行为完全一致。
文本生成参数配置文件
- generation_config.json:定义文本生成策略,包括温度(temperature)、Top-P 采样等超参数。
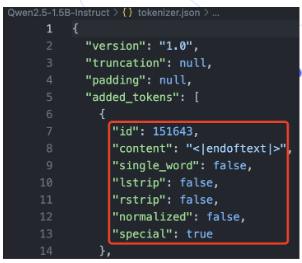
Tokenizer.json 解析及特殊 tokens
tokenizer.json 文件定义了分词器的所有配置:
-
added_tokens:原有词汇表基础上额外添加的特殊 token(PAD、CLS)。
-
post_processor:后处理模板,设置单句、双句对输入时自动添加 CLS 和 SEP 等特殊标记。
-
decoder:解码器类型。
-
model:底层分词模型的类型及其参数。如 qwen2.5-1.5B 模型采用 BPE 分词算法。
-
vocab:定义了词汇表,其中 key 为 token 字符串,value 为对应的 id。
-
special_merges:定义了 BPE 合并规则,合并成更复杂 token 的特殊 token。
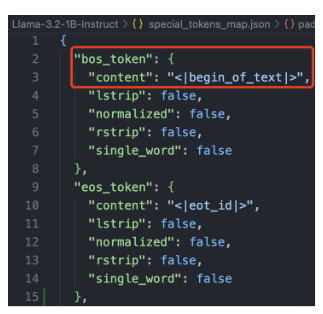
特殊 tokens 说明
-
bos_token(Beginning of Sentence Token):序列开始标记,文本序列的起始位置。
-
eos_token(End of Sentence Token):序列结束标记,表示文本序列的结束位置。
-
eop_token(End of Paragraph Token):段落结束的特殊标记。
-
pad_token(Padding Token):填充标记,它用于将 batch 形式文本序列填充到相同长度时使用的特殊 token。
1.3. Transformer 模型结构
Transformer 结构
-
Transformer:由 encoder 和 decoder 组成。
-
encoder:更适合理解型任务如 Bert。
-
decoder:带掩码,更适合生成型任务如 GPT。
-
Self-attention:Multi-Head Attention
-
Self-attention:能捕捉到句子内部 tokens 之间的语义关系。
- Q 表示当前输入 token 的特征向量,K 表示特征名字,V 表示特征值。
MLP 结构
-
MLP:通常由两个线性层(升维 and 降维)+ 1 个激活函数 + 一个残差连接组成。
-
非线性激活函数形式有效增强了模型的非线性表达能力。
-
更宽的线性层设计进一步增强了模型的表达能力。
-
MLP 层往往占据了 transformer 模型 2/3 的参数量和计算量。
-
Embedding
-
Embedding:单词 Embedding + 位置 Embedding。
-
词嵌入层通过学习一个嵌入矩阵,将每个 token 离散数字 id 映射为一个固定维度的连续向量。
-
Attention 层的输出本身是不具备时序信息的,Position encoding 层使得生成的 embedding vectors 值跟位置相关。
-
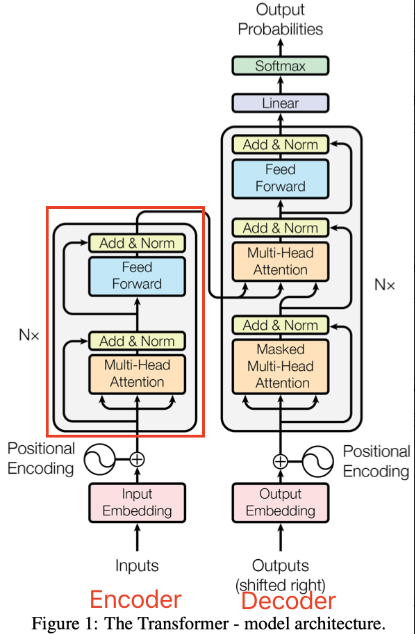
Token Embedding 和 Positional Embedding 层
Token Embedding 层作用可视化
Token Embedding 层将输入的文本转换为向量表示。每个 token(如单词或字符)被映射到一个固定维度的向量空间中。图示展示了不同 token 的嵌入向量。
Positional Embedding 层作用可视化
Positional Embedding 层为每个 token 提供位置信息,使得模型能够理解序列中 token 的顺序。图示展示了如何将位置信息添加到 token 嵌入向量中。
TransformerEmbedding 类
TransformerEmbedding 类结合了 token embedding 和 positional encoding:
class TransformerEmbedding(nn.Module):
def __init__(self, vocab_size, max_len, d_model, drop_prob, device):
super(TransformerEmbedding, self).__init__()
self.tok_emb = nn.Embedding(vocab_size, d_model)
self.pos_emb = nn.Embedding(max_len, d_model)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(torch.arange(x.size(1), device=x.device).unsqueeze(0).expand_as(x))
return self.drop_out(tok_emb + pos_emb)
Self-Attention 结构
QKV 的计算和作用
在 Self-Attention 中,Q(Query)、K(Key)、V(Value)是在同一输入序列中的一个单词上计算得到的三个向量。Query 负责与 Key 进行点积计算,量化当前位置 token 与其他位置 token 的相似程度。
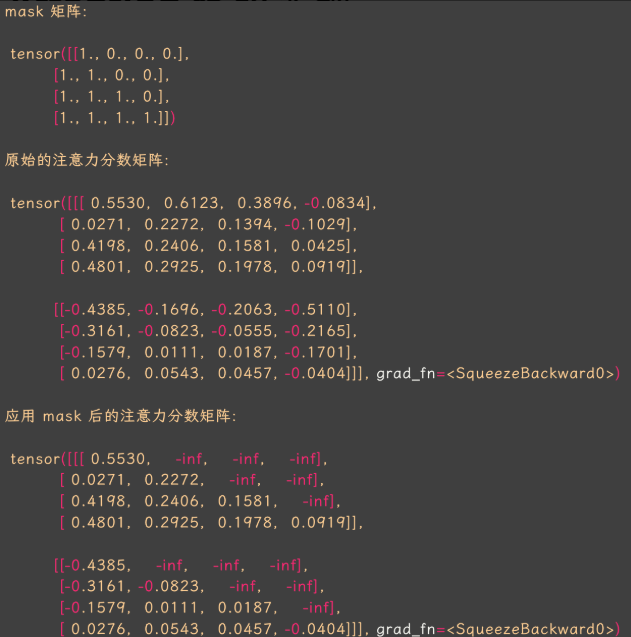
Causal Mask 原理和作用
**Causal Mask 是一个尺寸为 seq_len, seq_len 的矩阵,用于构建下三角注意力分数矩阵,从而实现因果模型只关注当前 token 与之前 token 的注意力关系,而不理会它与后续 token 的关系。**代码实现如下:
def generate_causal_mask(seq_length):
"""生成一个因果遮罩的下三角矩阵,上三角为0,下三角为1"""
mask = torch.tril(torch.ones((seq_length, seq_length))).unsqueeze(0)
return mask # 1表示可见,0表示遮罩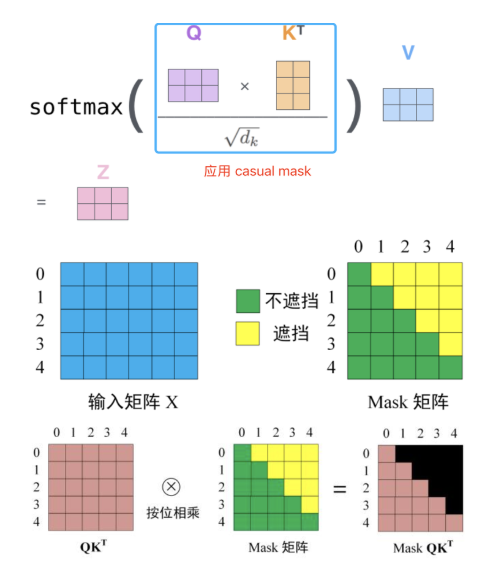
Mask-Attention 代码实现
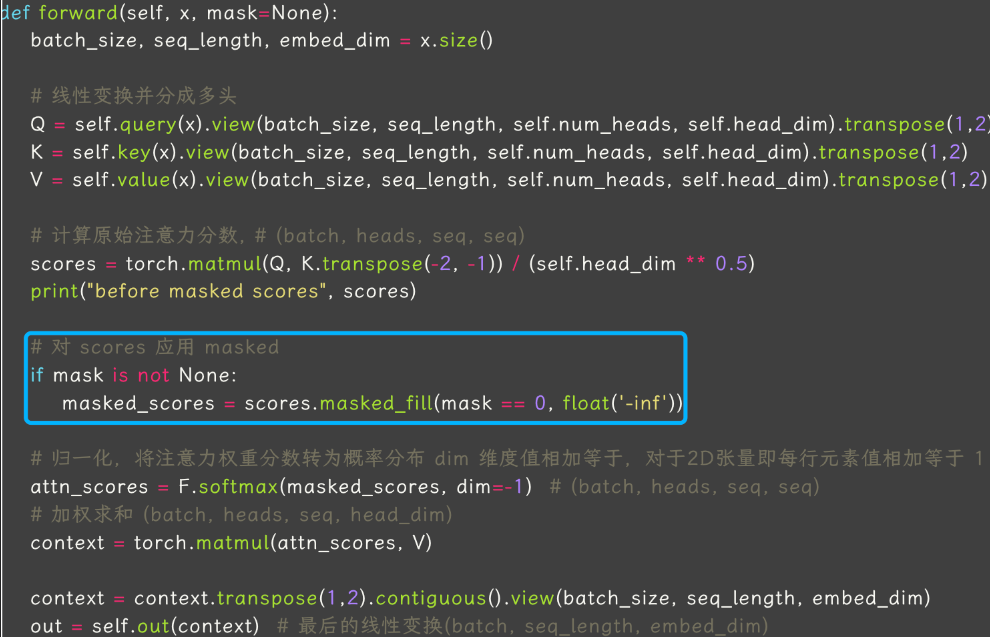
MHA 过程拆解
-
QKV 线性变换:将输入 x 通过线性变换得到 Q、K、V。
-
QKV 张量拆分:把输入的表征拆分成多个 group(head),分别独立计算 self-attention。
-
Self-attention 计算:每个 token 和其他 token 的相似度计算:
-
计算原始注意力分数矩阵,形状为 batch_size, seq_length, seq_length。
-
加权求和:注意力分数矩阵 * V。
-
-
输出线性变化:多头输出线性变换。
生成 Causal Mask 下三角矩阵
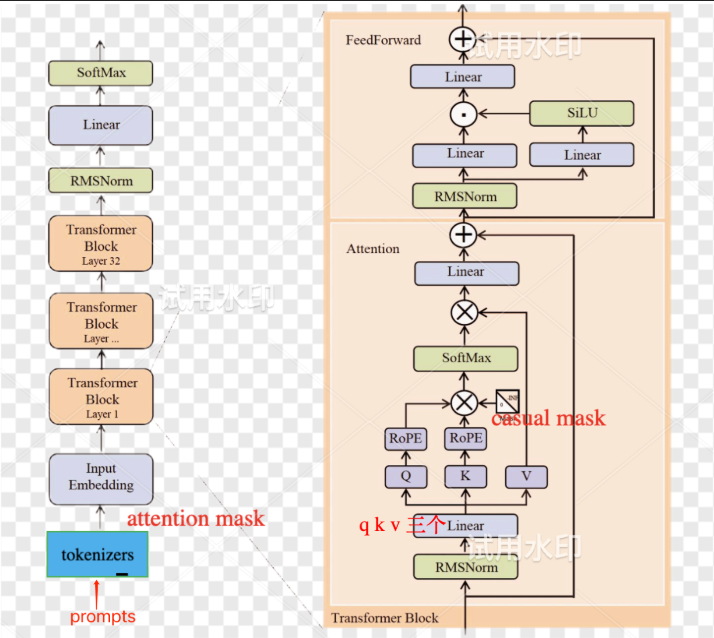
2. Llama 模型结构介绍
2.1 类 Llama 的 LLM 架构
Llama 模型采用了类似 GPT 的 Decoder-only 架构,主要包括以下几个关键组件:
-
RMSNorm:对每个 Transformer 子层的输入进行归一化,提高训练稳定性,速度提升约 40%。
-
FFN_SiLU:使用 SiLU 激活函数替代 ReLU,增强模型的非线性表达能力。
-
Rotary Embeddings:将经过线性变换后的 Q、K 应用 rope 位置编码,提升模型对位置信息的处理能力。
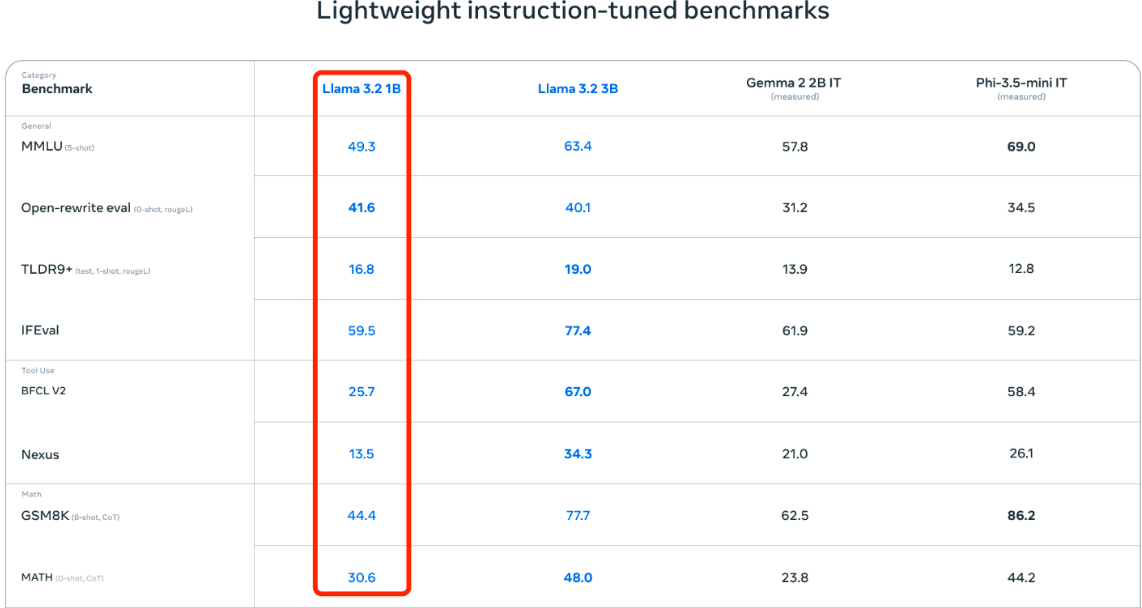
2. 2.Llama1-3 的升级点
模型细节
Llama1-3 模型在多个方面进行了改进:
-
支持的最大输入序列长度:分别为2k、4k、8k。
-
Tokenizer配置:与Llama1-2的Tokenizer配置完全相同,分词使用sentencePiece库实现的BPE算法,vocabulary size为32k。
-
KV cache优化技术:Llama2针对70B模型引入了KV cache优化技术-GQA,大幅度减少计算量和参数量。
-
词汇量增加:Llama3 tokenizer的词汇量从32k增加到128k,增加了4倍。更大的词汇库能够更高效地编码文本,增加编码效率。但这也导致和Llama2相比,Llama3的词嵌入层的输入和输出矩阵尺寸增大,模型参数量和计算量也随之增大。
-
上下文长度增加:Llama3在长度为8,192的文本序列上训练(之前是4K),即模型输入上下文长度从4096(Llama 2)和2048(Llama 1)增加到8192(8k),但相对于qwen2.5的32K来说还是比较小。
Qwen2.5模型细节
Qwen2.5模型在以下方面进行了优化:
-
Attention层的q、k、v的线性层的bias为True。
-
相比Llama3,存在qkv线性层bias和rmsnorm权重值大于1的情况。
-
支持的最大上下文长度为32k。
FFN到FFN_SiLU的转换
FFN_SiLU结构通过引入SiLU激活函数替代传统的ReLU激活函数,增强了模型的非线性表达能力,同时提高瑞丽速度。公式如下:
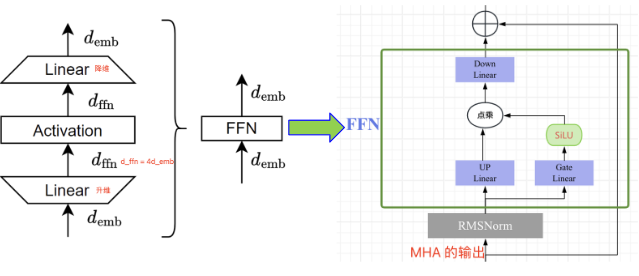
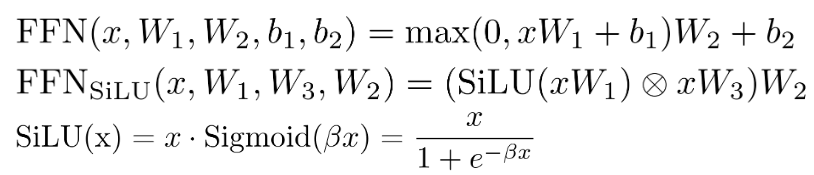
注意:Llama1-3.3 系列所有模型的线性层都是没有 bias 的。
FusedMLP类通过合并SiLU和*算子,减少计算量,提高模型效率。代码如下:
class FusedMLP(nn.Module):
def __init__(self, config: LlamaConfig, dtype=torch.float16):
super().__init__()
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False, dtype=dtype)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False, dtype=dtype)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False, dtype=dtype)
def forward(self, x):
"""使用 silu 和 * 算子融合"""
return self.down_proj(F.silu(self.gate_proj(x)) * self.up_proj(x))Sinusoida到RoPE位置编码
Sinusoida位置编码理解
Sinusoida正弦位置编码层的输出是一个矩阵,矩阵的每一行表示一个token的位置信息。
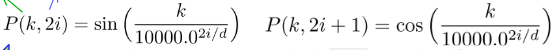

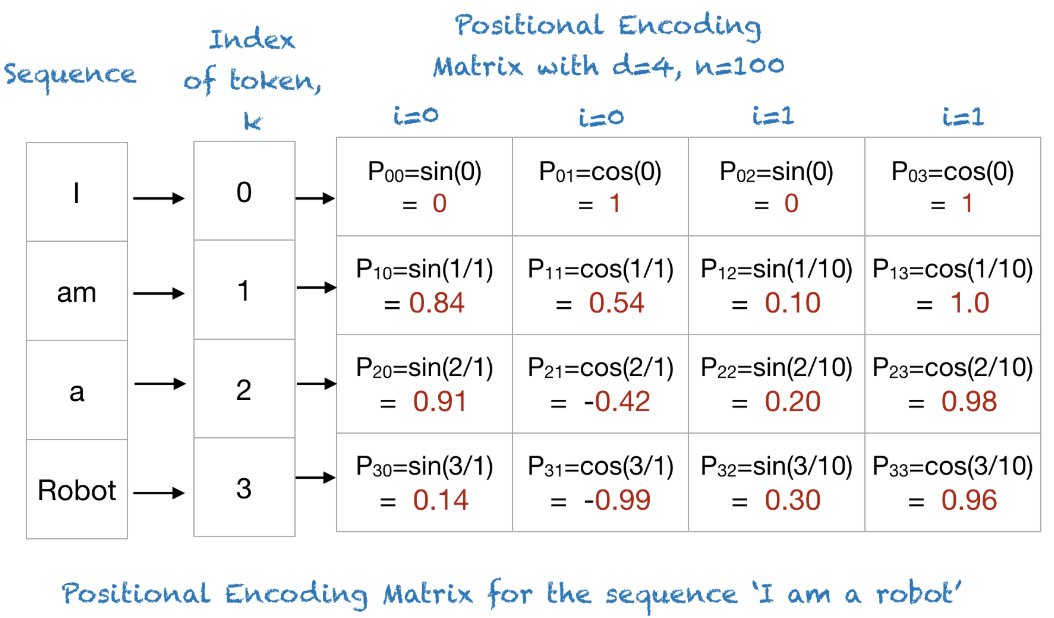
RoPE位置编码理解
RoPE旋转位置编码将相对位置信息依赖集成到self-attention中,具有更好的外推性。核心思想是构建旋转矩阵,并将q、k向量分别和旋转矩阵相乘。

3. LLM 参数量-显存占用分析
3.1 MHA 块参数量分析

3.2 MLP/FFN 块参数量分析

3.3Layer Norm 层参数量分析
LN层有两个,分别连接在MHA和MLP块的后面,layer_norm层有两个可训练参数:μB 和 σB(scale factor and offset),参数大小都是 h。2个Layer Norm层的总参数量计算如下: 参数量LN=4h
3.4 Embedding 层参数量分析
Embedding层同样也有参数,Embedding层包括两部分:Token Embedding(TE)和Positional Embedding(PE)。TE层的嵌入张量形状是 bs,V,输出维度是 bs,h,对应的TE层权重矩阵形状为 V,h,即TE层参数量 = Vh。另外,最后的输出层通常是和TE层共享权重矩阵的。
4. LLM 计算量分析
4.1 prefill 阶段 MHA 块计算量分析

4.2 prefill 阶段 MLP 层计算量分析

4.3. LLM 分析定性定量结论
(1)定性结论

(2)定量结论
-
一次迭代训练中,对于每个token和每个模型参数,需要进行6次浮点数运算。
-
随着模型变大,MLP和Attention层参数量占比越来越大,最后分别接近66%和33%。
-
有文档指出,13B的LLM推理时,每个token大约消耗1MB的显存。
5. 大型语言模型(LLM)推理部署概述
5.1传统CV模型推理部署
- 模型架构设计主要是:CNN + 任务网络,如 Faster R-CNN = ResNet + RPN + RoI Heads。
- 核心组件是卷积层,模型相对较小(MB级别),嵌入式设备经过优化可支持。
- 需要编写的自定义算子较多,主要是计算密集型算子。
- 输入输出参数简单且固定,基本都是是结构化数据。
- 适合单卡部署,性能主要依赖显卡计算能力。
- 大规模化的应用都是针对固定场景的图像数据。
5.2 LLM模型推理部署
- 模型架构主要是 Transformer 架构的自回归模型,计算密集型和内存密集型算子并存。
- 核心是自注意力机制结构,模型相对较大(起步 1B 级别),需要大量计算资源。
- 适合多卡部署,性能依赖很多因素:显卡显存容量、算力、卡内、卡间互联带宽等等。
- LLM 拓展性很高,可统一处理多模态和大规模任务,万物皆可 tokens?
- 输入可以是文本、语音、图像、视频多模态数据,输出是一段文本。
- 非常适合以服务形式提供接口。
5.3 常见LLM推理服务框架

LLM 推理服务重点关注两个指标:吞吐量和时延。
6. 优化技术-张量并行
集合通信是机器学习集群中实现分布式训练推理系统的基础,其作为并行计算的一个重要概念,经常被用来构建高性能的单程序多数据流(SPMD)程序。集合通信本质上是一个进程组的所有进程都参与的全局通信操作。
常见的集合通信算子包括:Broadcast、Reduce、AllGather、Scatter和AllReduce。
-
单点到多点:广播(broadcast)、发散(scatter);
-
多点到单点:收集(gather)、规约(reduce);
-
多点到多点:全收集(all-gather)、全规约(all-reduce)、全交换(all-to-all)、规约发散(reduce-scatter)。
Scatter是数据的1对多分发,它将一张XPU/GPU卡上的数据进行分片再分发到其他所有的XPU/GPU卡上,他的反向操作对应Gather。
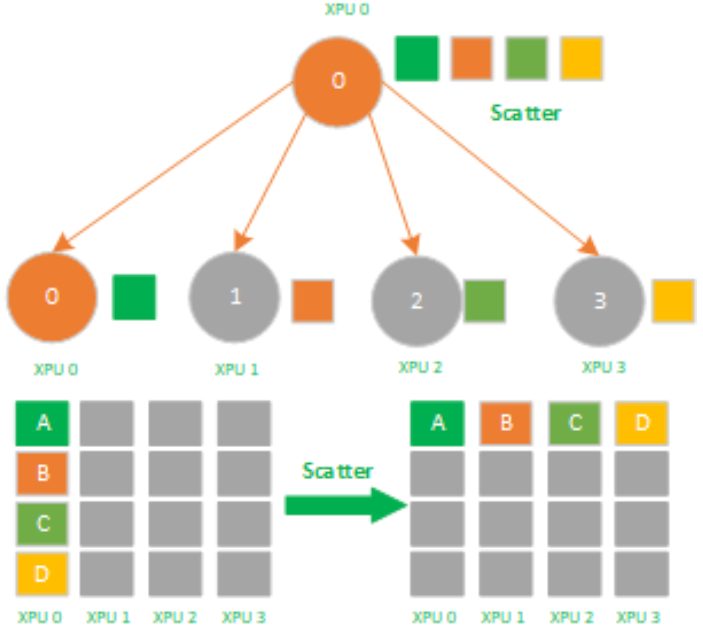
其中 AllGather 和 AllReduce 是多对多的集合通信算子,图中的 AllReduce算子,作用是将 Reduce 规约函数-加法的结果存至所有设备上。
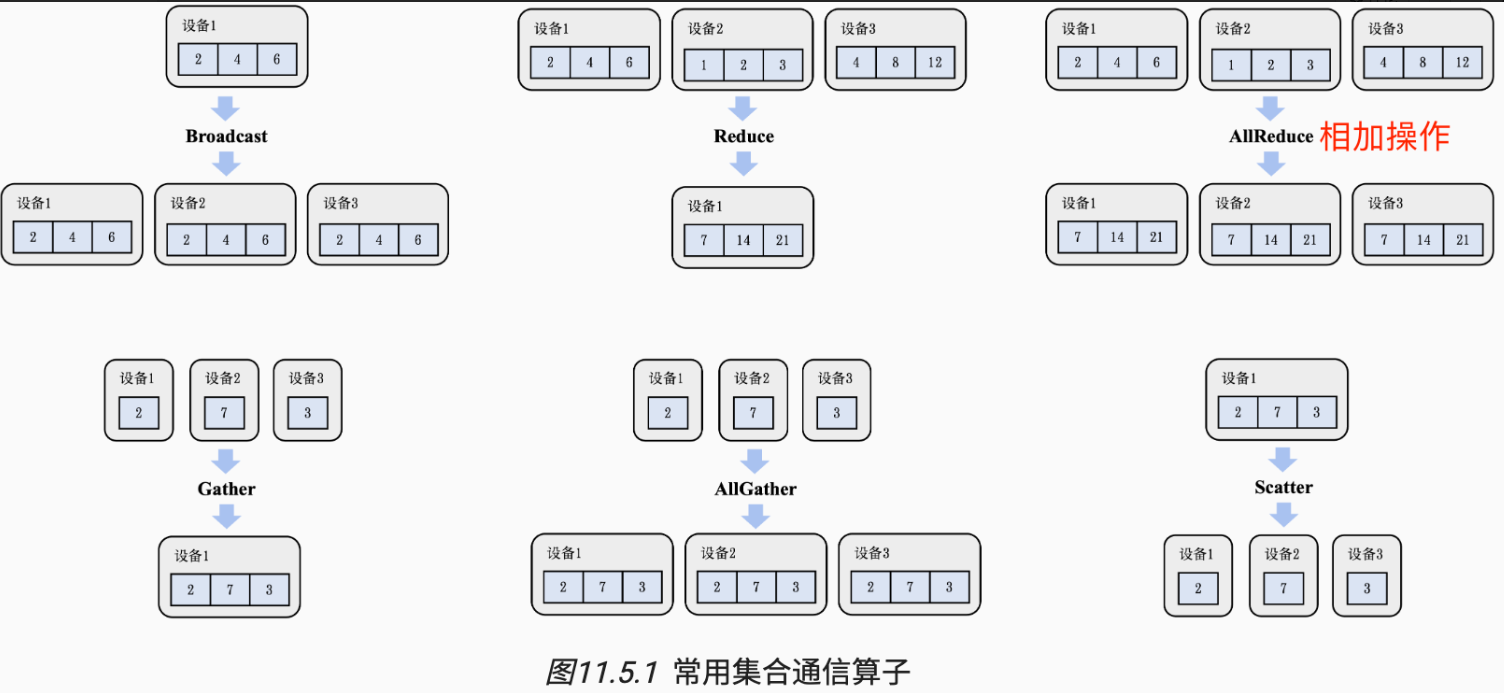
6.1 AllReduce算子原理
通信算子AllReduce的目标是将所有进程的数据通过特定操作**(如求和、取最大值)聚合后,将结果同步到所有进程。常见实现方式包括Ring AllReduce和Tree AllReduce。**
AllReduce的实现主要分为两个过程Reduce-Scatter和All-Gather。
-
分块传输:将待传输的数据切分为N块(N为进程数也是设备数),形成逻辑环状结构。
-
Reduce-Scatter阶段:每个进程依次向右邻进程发送下一块数据,并进行局部聚合(如累加、累减等)。经过N-1次传递后,每个设备上都有一块数据拥有了对应位置完整的聚合。
-
AllGather阶段:每个进程聚合后的数据块都在环中传播,按照"相邻设备对应位置进行通讯"的原则,最终所有进程获得完整结果。
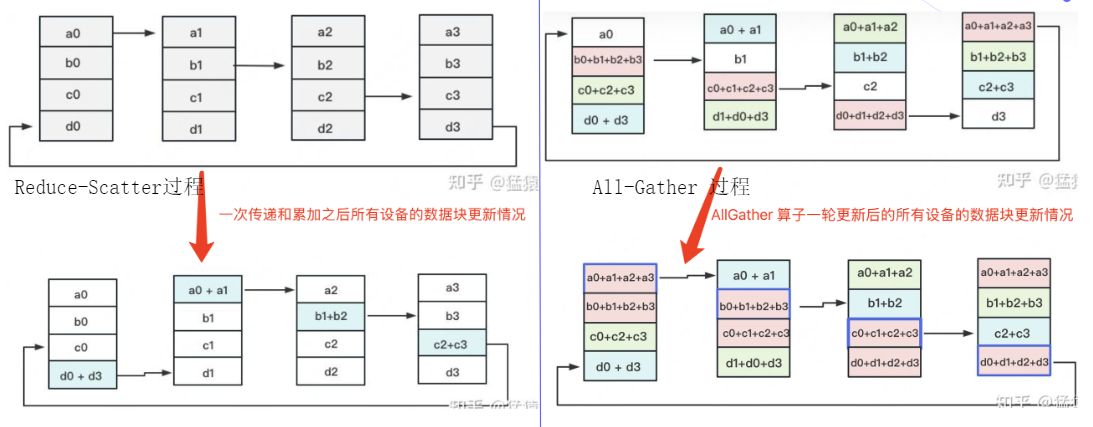
6.2AllReduce通信成本分析
假设有N个设备,输入(也是Reduce)总数据大小为K,一次AllReduce过程中,会进行N-1次Scatter-Reduce操作和N-1次Allgather操作,每一次操作所需要传递的数据大小为K/N,所以整个Allreduce过程所传输的数据大小为2(N-1) * K/N,随着N的增大,Ring AllReduce通信算子的通信量可以近似为2K。
分布式系统AllReduce的通信速度只受限于逻辑环中最慢的两个GPU的连接;每次需要通信的数据大小仅为K/N,随着N增大,通信量减少;总结:Ring Allreduce的通信速度恒定,和设备数量无关,完全由系统中GPU之间最慢的连接决定。
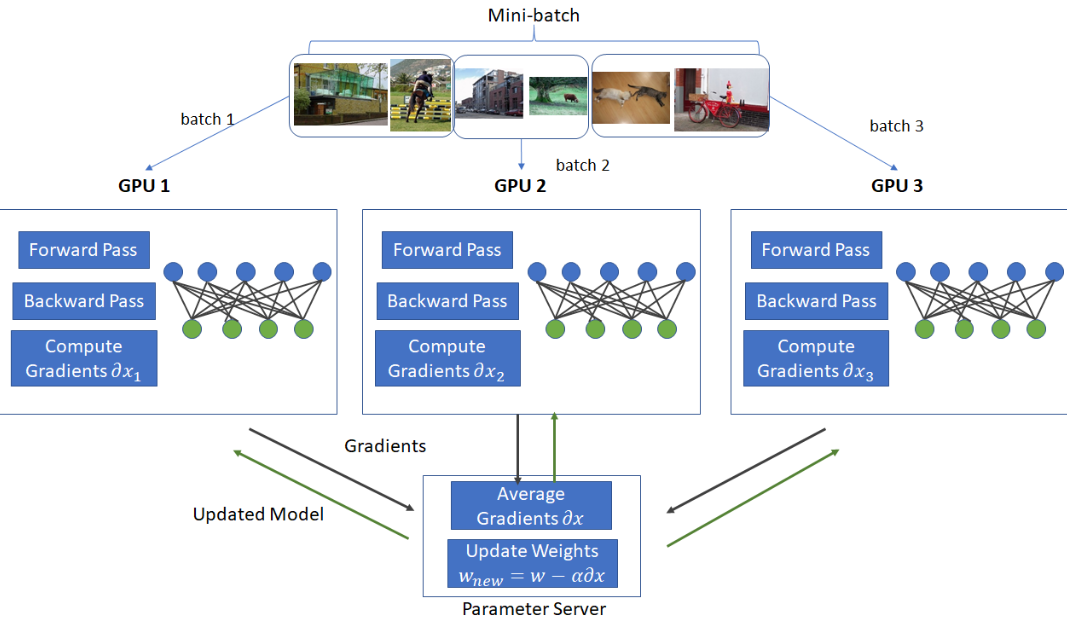
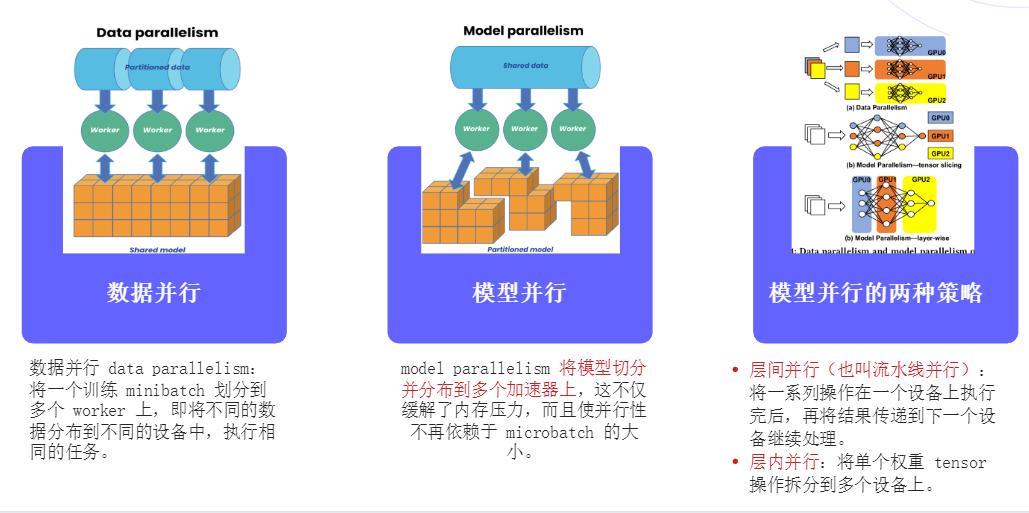
7. 数据并行与模型并行
数据并行(Data Parallelism)和模型并行(Model Parallelism)是分布式训练中的两种主要策略。数据并行涉及将一个训练minibatch分割到多个worker上,每个worker处理不同的数据分片。模型并行则是将模型切分并分布到多个加速器上,这不仅缓解了内存压力,而且使并行性不再依赖于minibatch的大小。
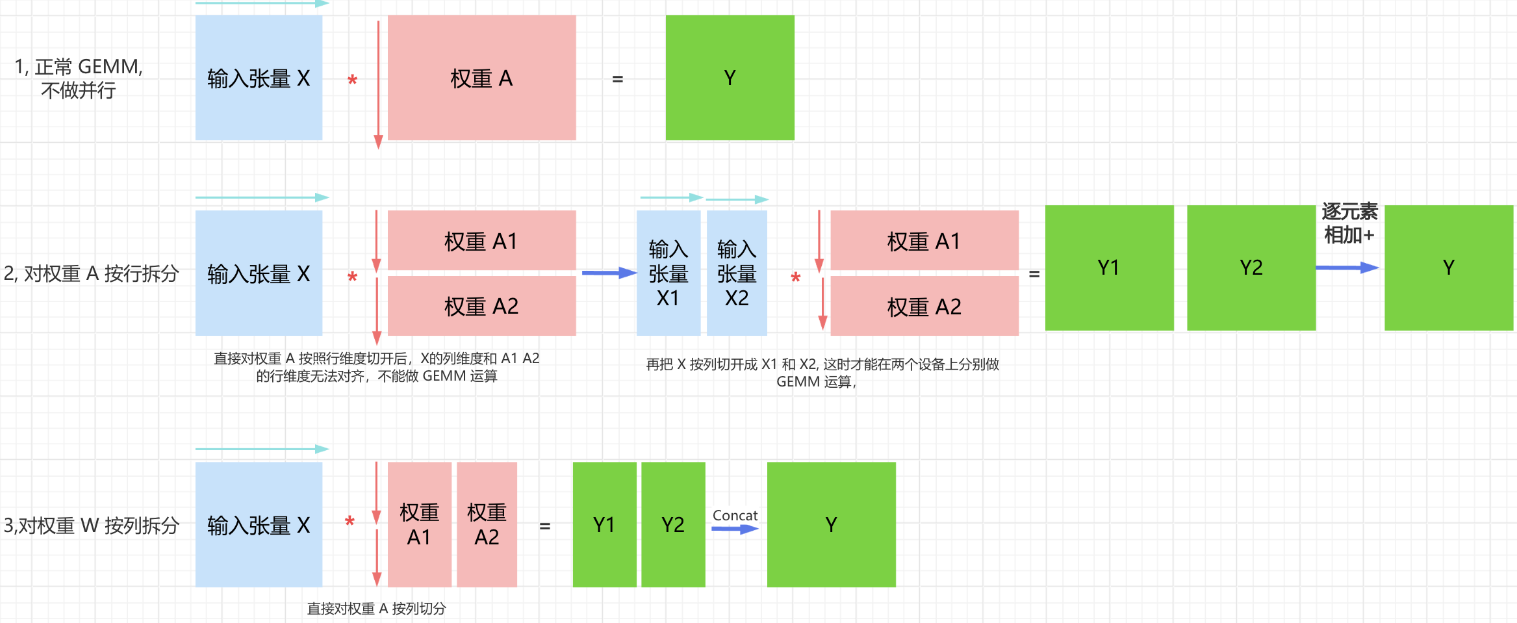
张量并行-线性层权重不同切分方式
线性层是MLP的核心kernel,其本质上是一种GEMM(通用矩阵乘法)操作。在张量并行加速方法中,权重切分有两种方式:按行切分和按列切分。
-
按行切分:将权重矩阵A按行拆分为多个子矩阵,每个GPU设备独立完成部分GEMM运算。这种方式避免了前向传播中一次全局同步通信,因为激活函数是非线性操作。
-
按列切分:将权重矩阵A按列拆分,直接对权重A按列切分。这种方式使得每个GPU设备能独立完成部分GEMM运算,并应用GELU激活函数。列切分方式的优势在于避免了前向传播中一次全局同步通信。
在MLP层中,将第一个线性层权重矩阵A沿列方向切分为A=A1, A2。这种切分方式使得每个GPU设备能独立完成部分GEMM运算,并应用GELU激活函数。列切分第一个线性层权重方法的优势在于避免了前向传播中一次全局同步通信。
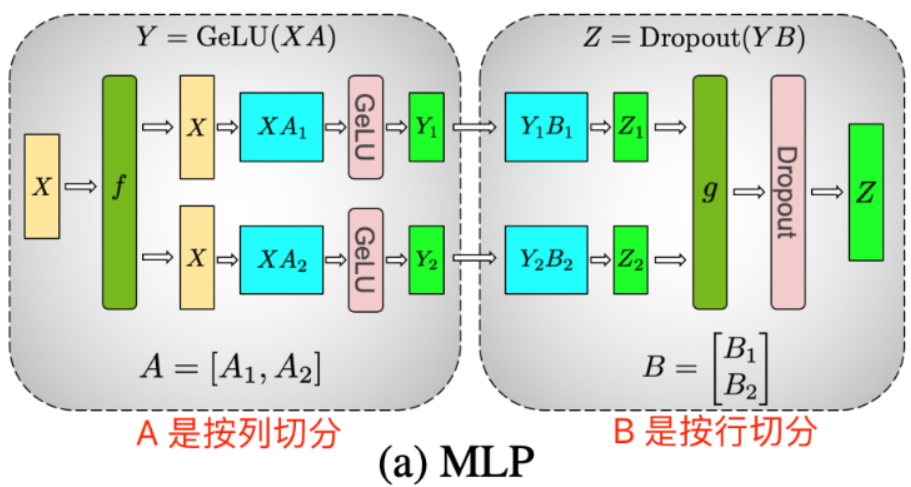
MLP模块中两个线性层权重先列后行的切分方法,其张量并行的前向传播过程拆解如下:
-
第一个GEMM(如XA1和XA2):每个GPU独立计算,无需通信。
-
第二个GEM(如Y1B1和Y2B2)之后,需要一次All-Reduce操作合并结果,再将结果输入Dropout层。之所以需要 All-Reduce 归约操作,是因为第二个线性层的权重是按行切分得到 Z_1 和 Z_2,所以需要执行加法操作得到最终的 Z。具体来说,第二个 GEMM(如 Y_1B_1 和 Y_2B_2) 之后,需要一次 All-Reduce 操作合并结果(对 Y_1B_1 和 Y_2B_2 求和)。
-
激活函数(如GeLU):本地计算,无需通信。
MLP 的张量并行过程的形状变换公式拆解如下:
- GPU0 上计算 Z1: b, s, h * h, h/2 -> b, s, h/2 * h/2, h -> b, s, h;
- GPU1 上计算 Z2: b, s, h * h, h/2 -> b, s, h/2 * h/2, h -> b, s, h;
- Z1 + Z2 = Z: b, s, h + b, s, h -> b, s, h
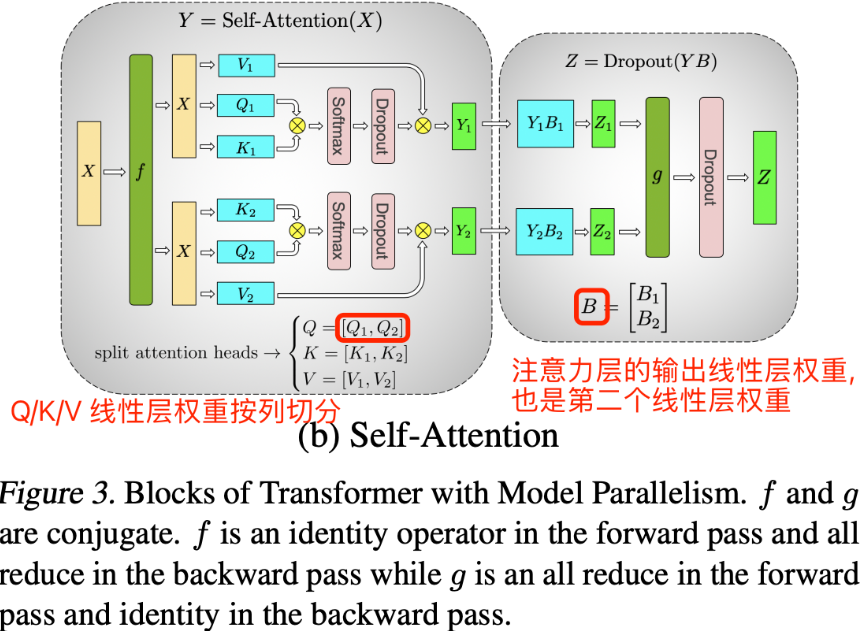
MHA 层的张量并行- 原理和过程
多头注意力模块(MHA)对于每个头(head),都有独立的q/k/v三个线性变换层以及对应的self-attention计算结构,然后将每个head输出的结果做拼接concat,最后将拼接得到结果做线性变换得到最终的注意力层输出张量。
从多头注意力结构看,其计算机制真的是天然适合模型的张量并行计算,即每个头上都可以在每个设备上独立计算,这也意味着可以把每个头(也可以是n个头)的参数放到一块GPU上,最后将子结果concat后得到最终的张量。
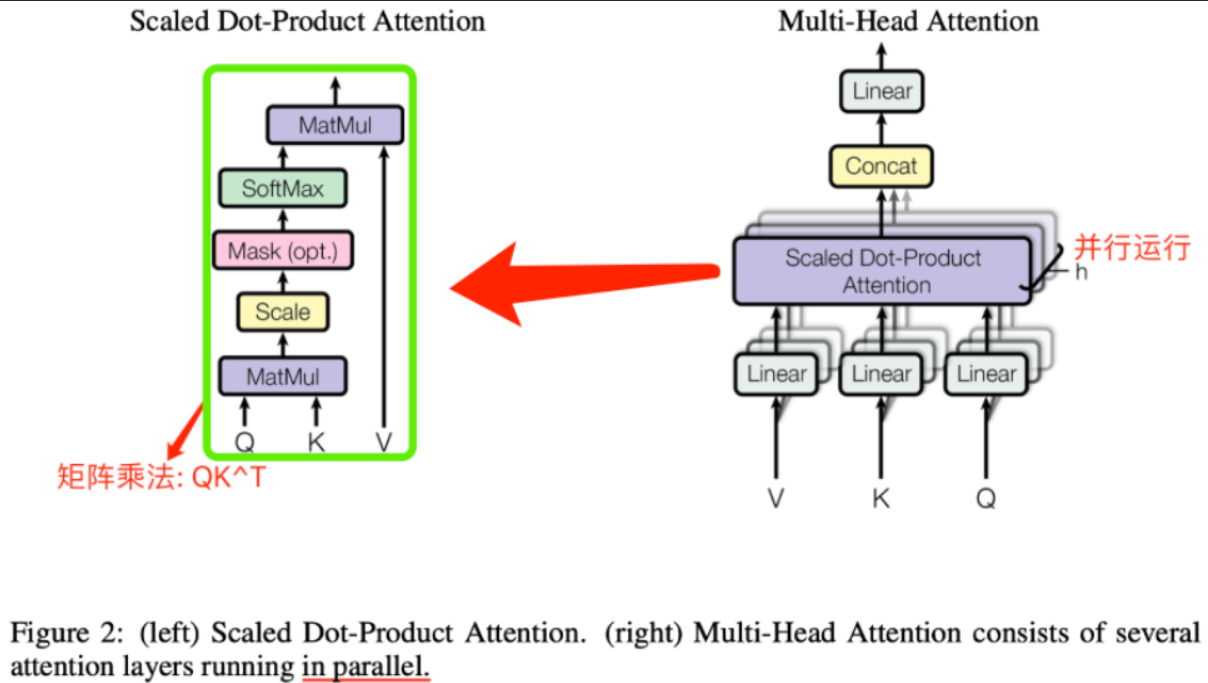
MHA层的张量并行-过程
多头注意力结构的张量并行计算过程拆解如下:
- 对三个权重参数矩阵W_Q、W_K、W_V,按照"列切割",每个头放到一块GPU上,即每个注意力头的Q/K/V线性变换的矩阵乘法可以在单个GPU上独立完成。对注意力输出线性层B,按照"行切分"。
MHA 层的张量并行通信量如下所示:
- 模型训练时,包含前向传播和反相传播两个过程,即两次 All-Reduce 操作,所以 MLP 层的总通讯量为:4bsh。模型推理时,只有前向传播过程,即一次 All-Reduce 操作,所以 MLP 层的总通讯量为:2bsh。
PS:All-Reduce 的过程分为两个阶段,Reduce-Scatter 和 All-Gather,每个阶段的通讯量是相等的。如果输入张量大小为 b, s, h,则每个阶段的通讯量为 bsh,每次 All-Reduce 操作通讯量自然为 2bsh。MLP 层在 forward(前向推理时) 做一次 All-Reduce 操作,在 backward(前向推理时) 做一次 All-Reduce 操作。