word2vec改进
word2vec:单词向量化
-
trouble
- 当语料库很大时,仅one-hot本身就需要占用非常多元素的内存大小,还需要计算one-hot表示和输入权重矩阵的乘积:引入新的Embedding层
- 当语料库很大时,中间层和输出权重矩阵的成绩需要大量计算,Softmax层的计算量也大:引入Negative Sampling损失函数
-
Embedding层:单词ID对应行
在forward时,提取单词ID对应的向量
-
Negative Sampling:负采样
用二分类问题来拟合多分类问题
负采样方法既可以求将正例作为目标词时的损失,同时也可以采样若干个负例,对这些负例求损失,然后将上述的两种损失加起来,作为最终的损失
-
如何选出若干个负例?
基于语料库的统计数据进行采样,计算语料库中各个单词的出现次数,表示为概率分布,使用概率分布对单词进行采样,让语料库中经常出现的单词容易被抽到
-
-
word2vec的应用
-
迁移学习:先在大规模语料库上学习,将学习好的分布式表示应用于某个单独的任务
-
单词向量化

-
RNN 循环神经网络
-
概念区分:
前馈神经网络:网络的传播方向是单项的,比如,输入层将输入信号传给隐藏层,接收到后又传给下一层,然后再传给下一层,,,,信号在一个方向上传播
这种网络不能很好地处理时间序列数据,RNN循环神经网络用来解决这类问题
-
语言模型 language model
给出单词序列发生的概率,使用概率来评估一个单词序列发生的可能性,即在多大程度上是自然的单词序列
-
马尔科夫性:未来的状态仅依存于当前状态
-
RNN Recurrent Neural Network 循环神经网络
-
循环:反复并持续
-
rnn拥有一个环路,可以使数据不断循环,通过循环,rnn一边记住过去的数据,一边更新到最新的数据
-
结构
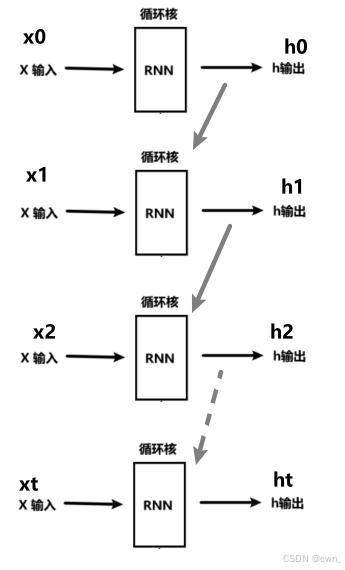
Wh:前一个RNN层的输出转化为当前时刻的输出的权重
Wx:输入x转为化输出h的权重
b:偏置
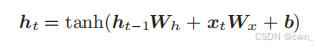
-
BPTT
基于时间的反向传播:按时间顺序展开的神经网络的误差反向传播法
-
Truncated BPTT
截断的BPTT:处理长时序数据时,通常将网络连接截成适当的长度,对截出来的小型网络执行误差反向传播法
但只是网络的反向传播的连接被截断,正向传播的连接依然被维持
-
Truncated BPTT的mini_batch学习
对各个批次中的输入数据的开始位置进行偏移
-
-
RNNLM RNN Language Model RNN 语言模型
Embedding -> rnn -> Affine -> Softmax
-
评价
困惑度(平均分叉度):概率的倒数;困惑度越小越好