------ 工业自动驾驶感知系统的进阶之路
在自动驾驶开发的早期或教学阶段,我们通常通过模块化的方式学习:用 OpenCV 做透视变换,用 YOLO 做检测。但在真实的工业落地中(港口、矿山、L4级自动驾驶),感知系统早已不再是散装的"拼盘",而是进化为了多模态融合(Multi-modal Fusion)多任务学习(Multi-task Learning)的有机整体。
1 模块设计:从"串行处理"到"统一特征流"
1.1 传统设计(教材视角)
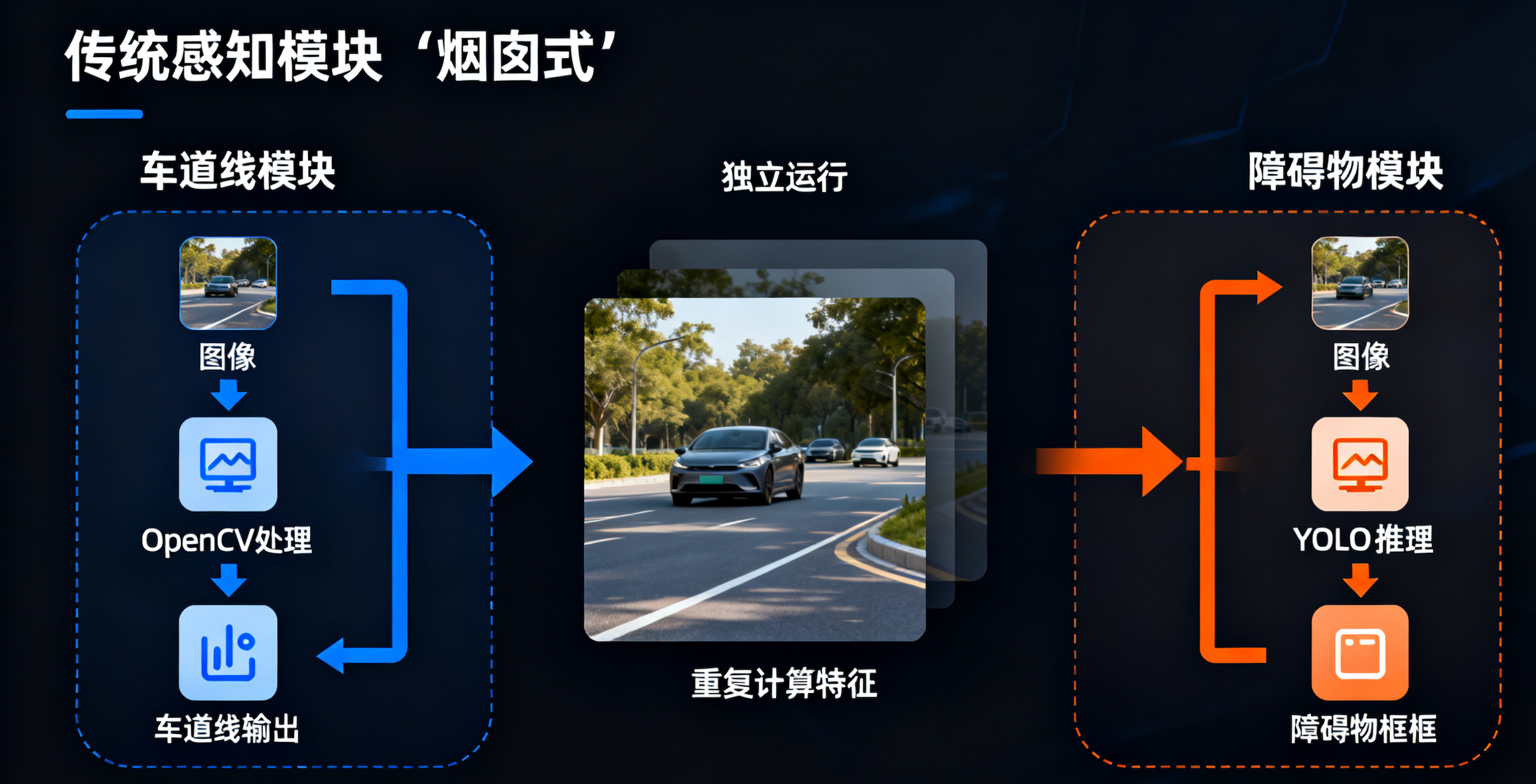
传统的感知模块设计往往是"烟囱式"的:
-
车道线模块:读取图像 -> OpenCV 处理 -> 输出线。
-
障碍物模块:读取图像 -> YOLO 推理 -> 输出框。
-
弊端:每个任务独立运行,重复计算图像特征,且无法处理传感器之间的协同(比如雷达看到了障碍物,但摄像头因为过曝没看到)。
1.2 现代设计(工业视角)
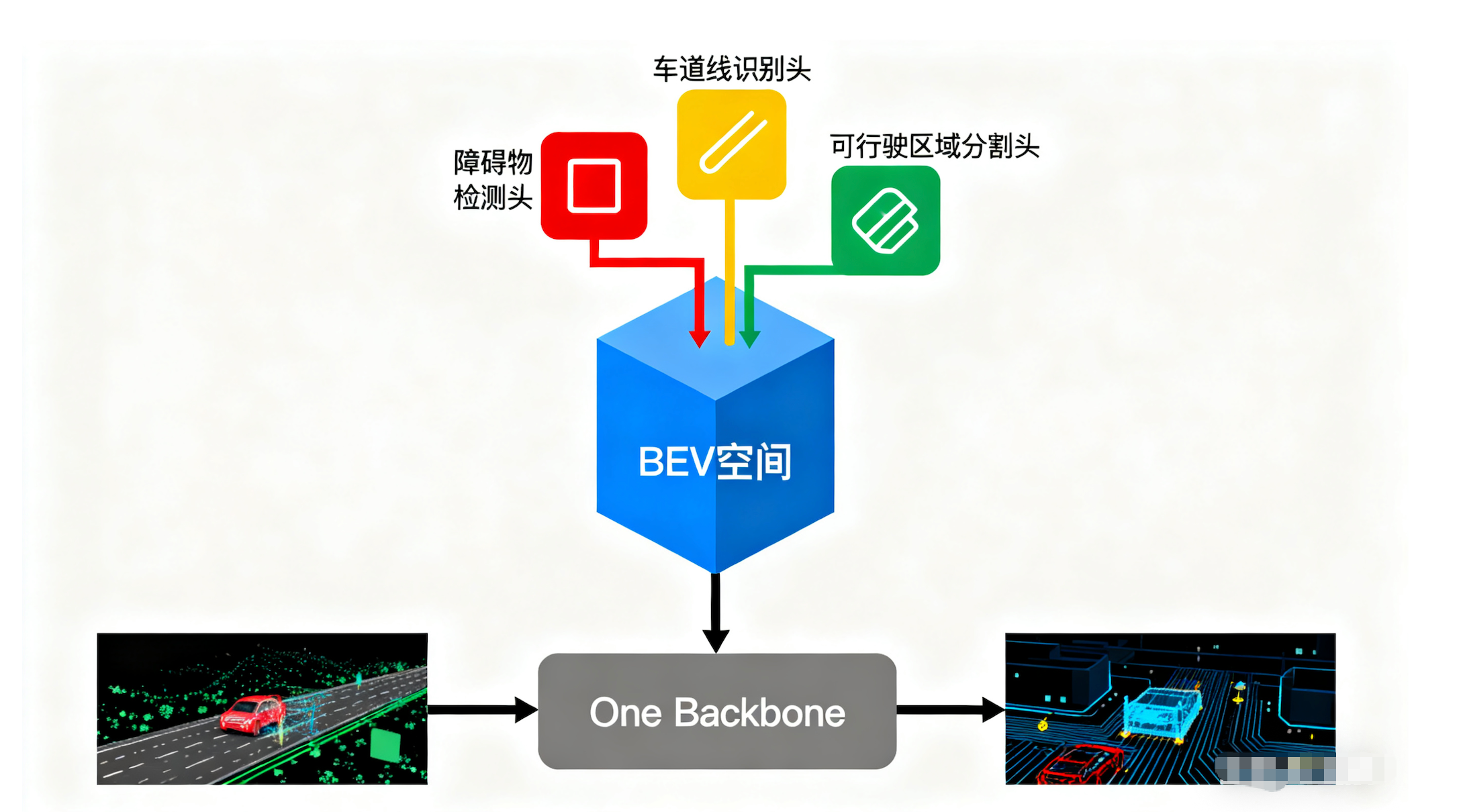
现代感知架构的核心是 "One Backbone, Multiple Heads"。
-
共享骨干 (Backbone):只提取一次特征(无论是图像还是点云)。
-
统一空间 (BEV):将特征投影到统一的 3D 空间。
-
多任务头 (Multi-Task Heads):在同一套特征图上,同时输出车道线、障碍物、可行驶区域。
2 代码实战与架构升维
2.1 BEV 透视变换:从几何投影到神经网络
【基础实战】使用 OpenCV 进行 BEV 变换
在基础代码中,我们使用 cv2.getPerspectiveTransform 和 cv2.warpPerspective。
-
原理:假设地面绝对平坦,利用 4 个标定点计算单应性矩阵(Homography Matrix)。
-
局限:在矿山或港口,地面颠簸、车辆俯仰(Pitch)变化大,基于固定矩阵的 OpenCV 变换会产生剧烈拉伸和误差。
【工业进阶】基于学习的 View Transformation
在现代架构中,我们不再手动写 OpenCV 变换,而是引入 LSS (Lift-Splat-Shoot) 或 BEVFormer 层:
-
深度估计:网络预测图像每个像素的深度分布。
-
特征投影:将 2D 图像特征根据预测的深度,"抛射"到 3D Voxel 空间中。
-
优势:这种方式能容忍车辆颠簸,并且是可微分的,可以通过反向传播优化。

2.2 任务融合:从独立检测到多任务学习
【基础实战】YOLO 检测 + OpenCV 道路检测
通常做法是跑一个 YOLOv8 进程检测车,再跑一个传统图像处理进程检测路。
- 算力浪费:两套程序都在对同一张图片做计算。
【工业进阶】多任务感知模型 (Multi-Task Model)
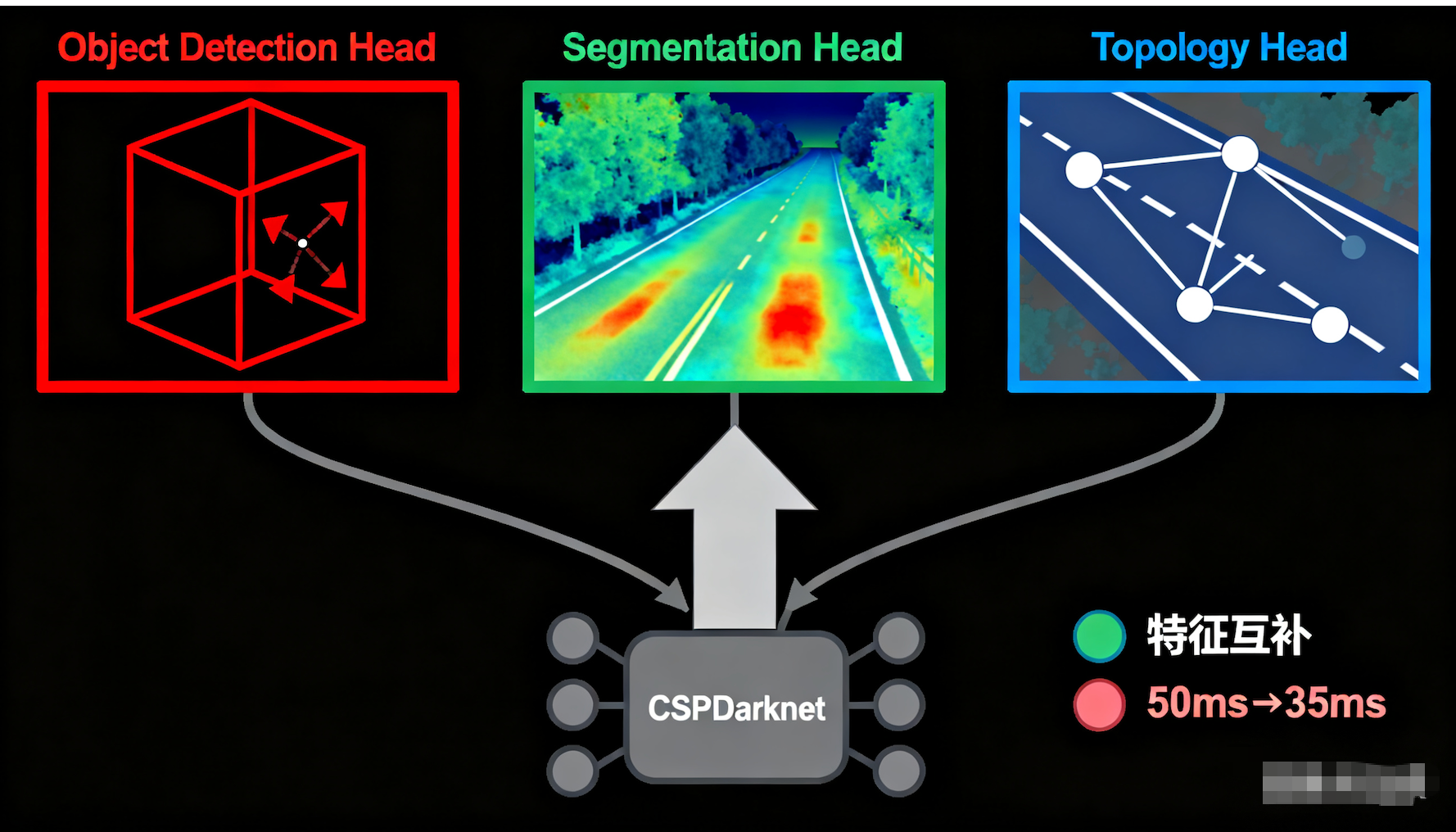
我们将 YOLO 的 Backbone(如 CSPDarknet)保留,但改造其 Head 部分,构建一个"全能网络":
-
Object Detection Head:输出 3D 框(位置、尺寸、航向角)。
-
Segmentation Head:输出道路分割掩码(解决 5.2.2 的问题)。
-
Topology Head:预测车道线之间的连接关系。
技术价值:
-
特征互补:学习"路"的特征有助于更准地检测"路上的车"。
-
速度提升:原本跑两个模型需要 50ms,现在合并后只需要 35ms。
2.3 时序融合:从单帧识别到目标跟踪
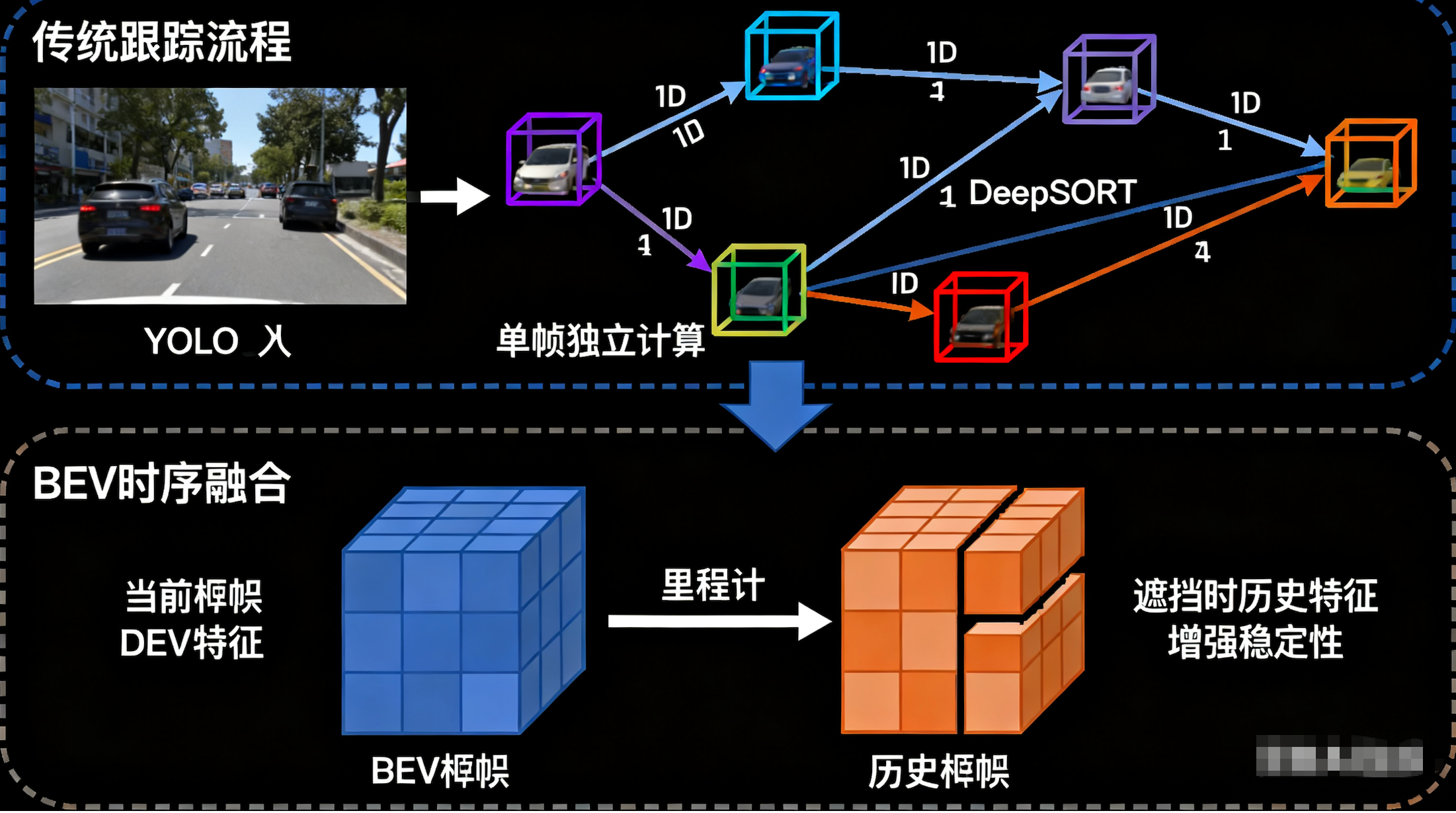
【基础实战】YOLO + DeepSORT
传统方法是"检测-匹配-跟踪"。每一帧都是独立的,下一帧还得重新检测一遍。
【工业进阶】BEV 时序融合 (Temporal Fusion)
在 BEV 空间中,利用车辆的里程计(Odometry)信息,将上一帧的历史 BEV 特征 对齐并拼接到当前帧。
- 效果:即使当前帧物体被遮挡(Occlusion),历史帧的特征依然存在。这不仅实现了跟踪,更增强了检测的稳定性,解决了工业现场常见的"障碍物闪烁"问题。
3 终极形态:多模态融合感知模型
在教材的 2.3 节"完成感知模块"中,如果仅停留在纯视觉,无法满足全天候作业需求。我们需要引入激光雷达(LiDAR)或毫米波雷达。
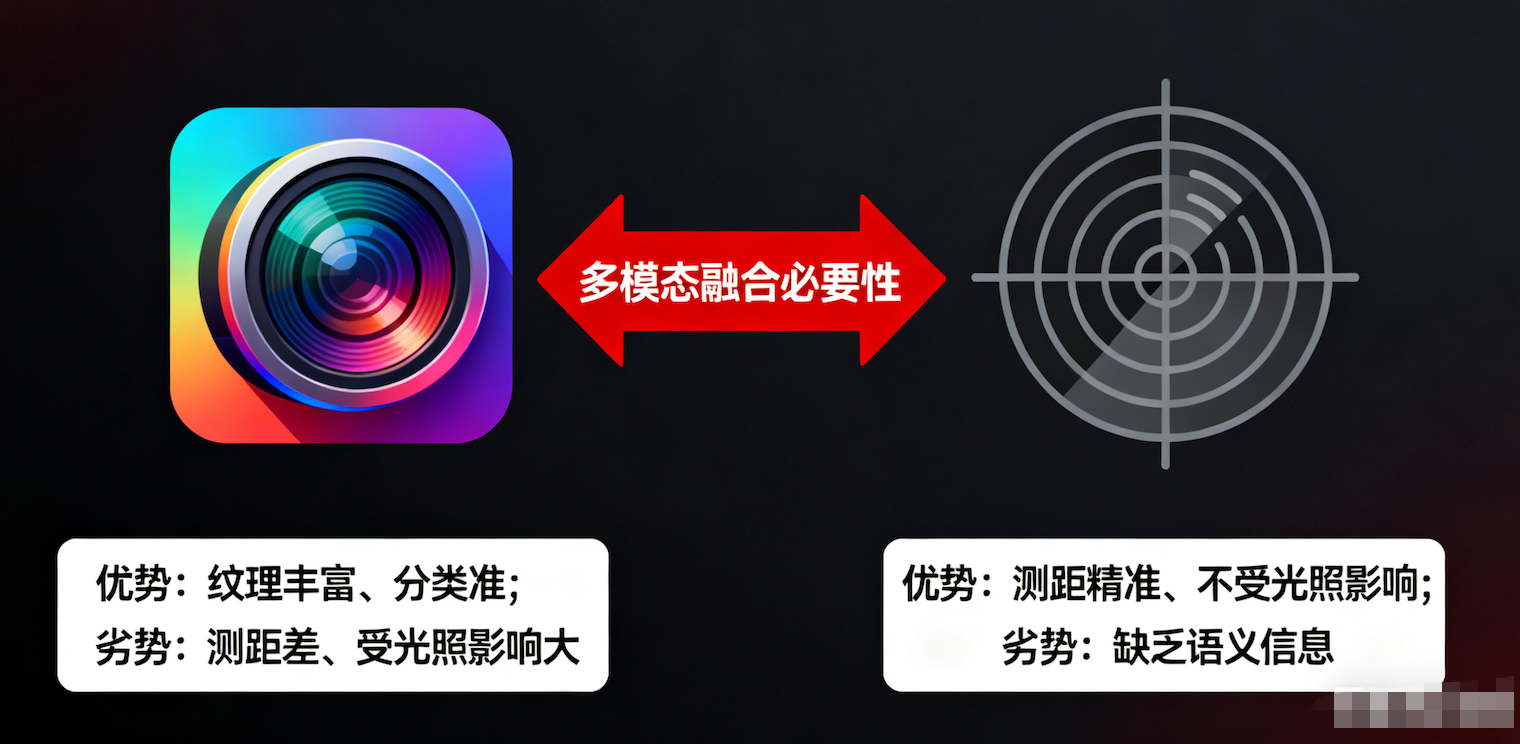
3.1. 为什么要做融合?
-
摄像头:纹理丰富,分类准,但测距差,受光照影响大。
-
雷达:测距精准,不受光照影响,但缺乏语义信息(分不清石头还是纸箱)。
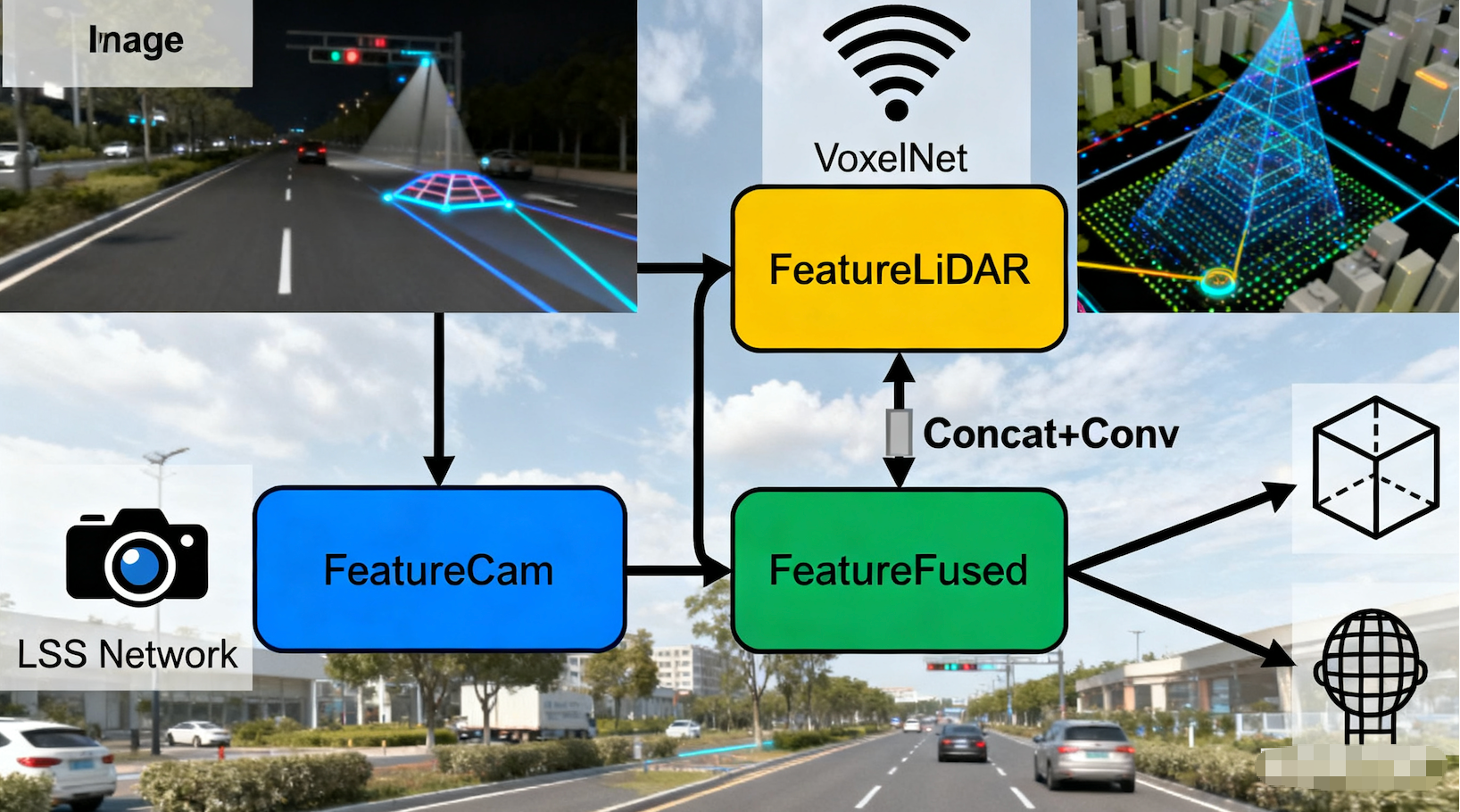
3.2. 怎么做融合?
拒绝简单的"结果融合"(即摄像头出一个框,雷达出一个框,然后取交集),工业界采用 BEV 特征级融合:
-
Step 1:图像分支通过 LSS 转换到 BEV 空间,得到 FeatureCamFeatureCam
-
Step 2:点云分支通过 VoxelNet/PointPillars 处理,得到 FeatureLiDAR
-
Step 3:在 BEV 空间直接拼接或通过 Cross-Attention 融合:FeatureFused=Conv(Concat(FeatureCam,FeatureLiDAR))
-
Step 4:基于融合后的特征,送入 Detection Head 和 Occupancy Head。
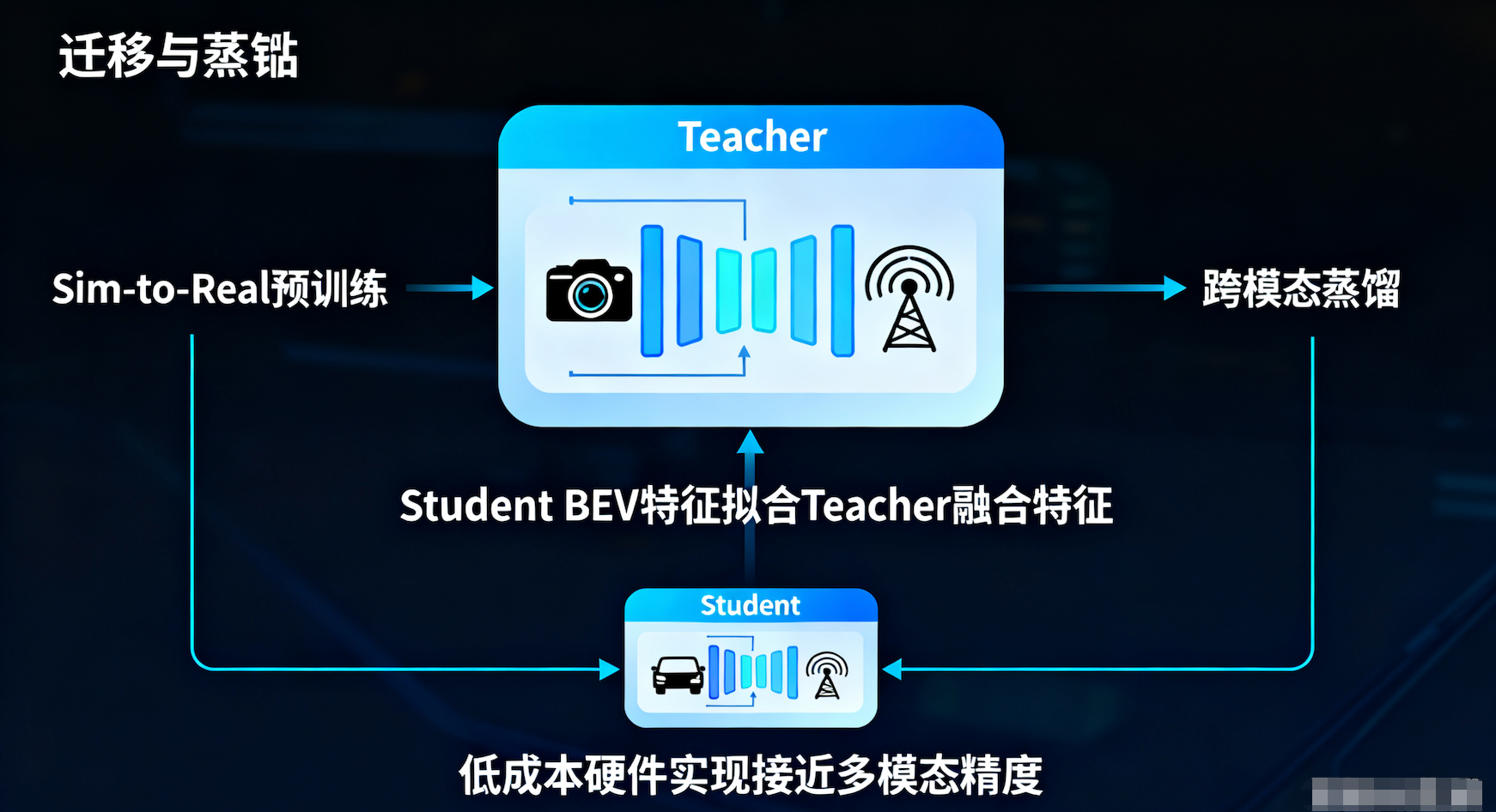
4 贯穿全流程的"迁移与蒸馏"
结合我们之前的讨论,这套复杂的架构在落地时需要配合工程化手段:
-
大模型预训练(迁移学习):
-
先用海量数据训练这个庞大的 多模态融合模型(Teacher),让它学会如何结合图像和雷达信息。
-
利用 Sim-to-Real 技术,让模型在仿真环境中"看惯"各种天气。
-
-
小模型部署(跨模态蒸馏):
-
在量产车端(可能只有摄像头),我们强制 纯视觉 Student 模型 的 BEV 特征去拟合 Teacher 模型 的融合特征。
-
结果:Student 模型虽然只看图,但它"脑补"出了雷达般的深度信息,从而在低成本硬件上实现了接近多模态的高精度。
-
总结:从代码到架构
|-----------------------|--------------------------------|-------------|
| 基础版实战 (The "Old" Way) | 工业级架构 (The "Pro" Way) | 核心技术点 |
| OpenCV 透视变换 | LSS / Transformer BEV | 深度估计、可微分投影 |
| 传统边缘检测/阈值分割 | Semantic Segmentation Head | 语义理解、抗干扰 |
| YOLO 2D 检测 | 3D Object Detection Head | 空间感知、尺寸估算 |
| 独立的多进程任务 | Multi-Task Learning | 共享骨干、特征互补 |
| 单一传感器模块 | 多模态融合 + 知识蒸馏 | 全天候能力、端侧轻量化 |
通过这一章的学习与进阶,我们不仅掌握了感知的基本代码实现,更构建了一套能够应对复杂工业环境、具备 BEV 空间理解能力 、多模态融合能力 且 算力高效 的现代化感知系统。