基于 LangChain + RAG + LLM 实现数据资产自动化治理,核心是通过 "检索业务知识 + 调用工具获取元数据 + LLM 推理决策" 的闭环,解决标签归类和重复识别问题。以下是具体实现方案,分架构设计、核心模块、流程步骤三部分展开:
一、整体架构设计
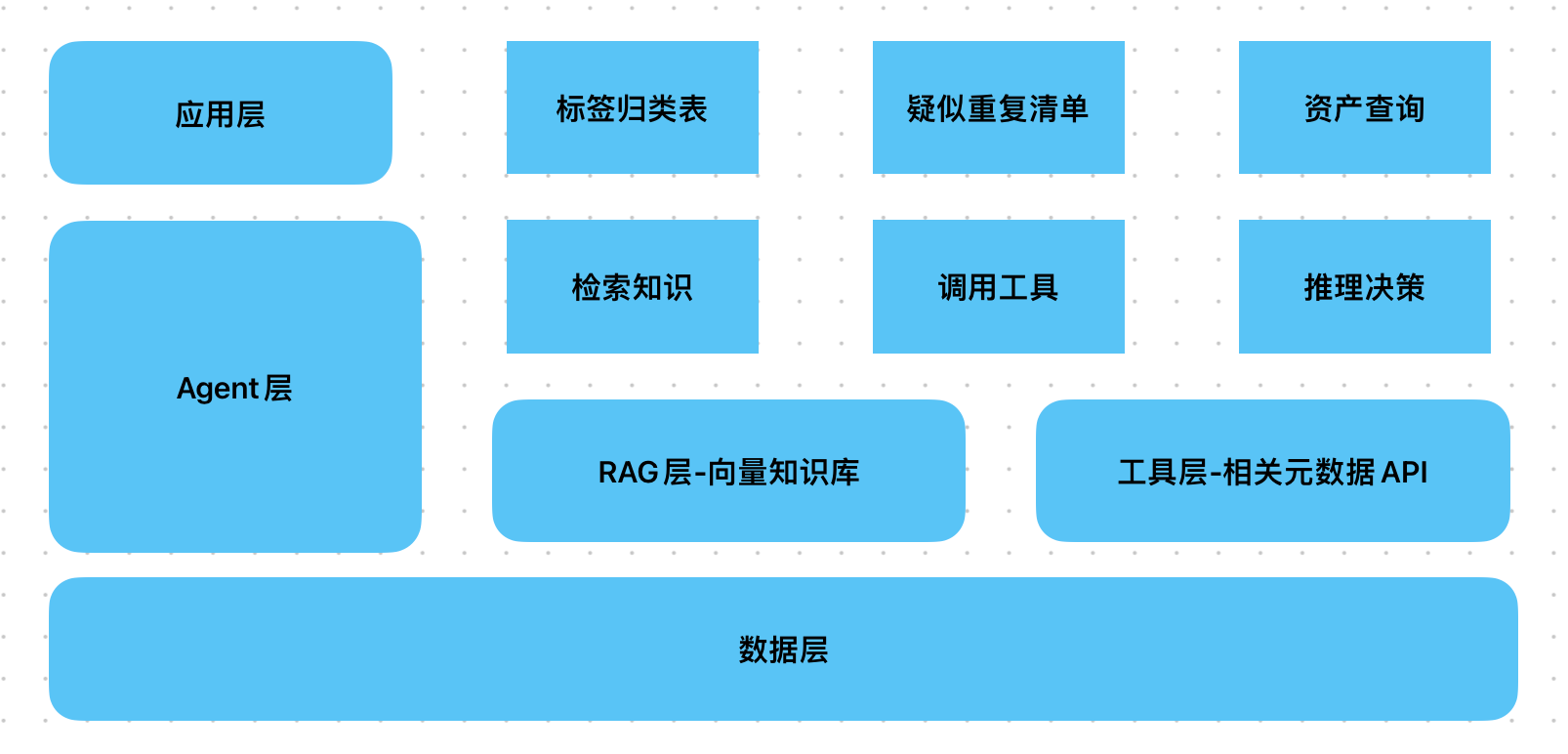
- 数据层:存储待治理的元数据(表名、字段名、注释)、业务知识(标签体系、白皮书、口径规范)、依赖关系数据;
- 工具层:封装元数据查询 API、依赖关系查询工具,供 Agent 调用;
- RAG 层:构建业务知识向量库,支持快速检索标签规则、白皮书定义、口径标准;
- Agent 层:基于 LangChain 的工具调用型 Agent,协调 "检索知识→调用工具→推理决策" 的流程;
- 输出层:生成结构化治理结果(标签归类表、疑似重复资产清单)。
二、核心模块实现(基于 LangChain)
1. 数据层与 RAG 知识准备
目标:将业务知识(标签体系、白皮书)转化为可检索的向量,为 Agent 提供 "治理依据"。
-
数据收集:
- 业务标签体系:如 "用户域""订单域""指标类""维度类" 等标签的定义、层级关系(例:"用户活跃度" 属于 "用户域→核心指标");
- 业务白皮书:包含指标口径规范(例:"日活" 定义为 "自然日登录用户数,去重")、数据资产建设标准(例:"重复资产判定:表字段重合度≥80% 且业务含义一致");
- 历史治理案例:过往人工标记的重复资产、标签归类案例(用于 LLM 学习判断逻辑)。
-
RAG 构建:
pythonfrom langchain.document_loaders import TextLoader, PDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma # 1. 加载业务知识文档(标签体系、白皮书、案例) loaders = [ PDFLoader("业务标签体系白皮书.pdf"), TextLoader("指标口径规范.txt"), TextLoader("历史重复资产判定案例.txt") ] documents = [] for loader in loader: documents.extend(loader.load()) # 2. 拆分文档(按语义拆分,chunk_size=500适合短文本规则) text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) splits = text_splitter.split_documents(documents) # 3. 构建向量库(用业务知识初始化RAG) embeddings = OpenAIEmbeddings() # 或用开源模型如BGE vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings, persist_directory="./rag_data_governance") retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # 检索Top3相关知识
2. 工具层:封装元数据与依赖关系查询工具
目标:让 Agent 能主动调用工具获取实时元数据(表名、字段等)和依赖关系,避免依赖静态数据。
-
工具 1:元数据查询工具(调用用户提供的 API)功能:输入表名,返回表的字段名、字段注释、数据类型等元数据。
pythonfrom langchain.tools import tool @tool def get_table_metadata(table_name: str) -> dict: """获取指定数据表的元数据(字段名、字段注释、数据类型)。 当需要分析某个表的业务含义或判断重复时,必须调用此工具。 参数:table_name-数据表名称(如'dw_user_active') """ # 调用用户提供的元数据API import requests response = requests.get(f"http://metadata-api.com/table?name={table_name}") return response.json() # 示例返回:{"fields": [{"name": "user_id", "comment": "用户唯一标识"}, ...]} -
工具 2:依赖关系查询工具功能:输入表名,返回其上游依赖表(被它依赖的表)和下游表(依赖它的表),用于辅助判断重复(重复表通常依赖相同上游)。
python@tool def get_table_dependencies(table_name: str) -> dict: """获取指定数据表的上下游依赖关系。 当判断两个表是否重复时,需调用此工具获取依赖关系辅助分析(重复表通常依赖相同上游)。 参数:table_name-数据表名称 """ import requests response = requests.get(f"http://dependency-api.com/table?name={table_name}") return response.json() # 示例返回:{"upstream": ["ods_user_login"], "downstream": ["ads_user_analysis"]} -
工具集整合:
pythontools = [get_table_metadata, get_table_dependencies]
3. Agent 层:构建数据治理 Agent
目标:基于 LangChain 的 Agent 框架,让 LLM 能根据治理目标,自主决定 "何时检索业务知识、何时调用工具、何时推理决策"。
-
核心逻辑:
- 对于 "标签归类":先调用元数据工具获取表的字段 / 注释→检索 RAG 中的标签规则→LLM 判断标签;
- 对于 "重复识别":获取两个表的元数据 + 依赖关系→检索 RAG 中的重复判定标准→LLM 计算相似度并标记疑似重复。
-
Agent 初始化:
pythonfrom langchain.chat_models import ChatOpenAI from langchain.agents import initialize_agent, AgentType from langchain.memory import ConversationBufferMemory # 1. 初始化LLM(需强推理能力,推荐GPT-4或Qwen-14B) llm = ChatOpenAI(model_name="gpt-4", temperature=0) # temperature=0确保决策稳定 # 2. 初始化记忆(保存上下文,用于多轮处理同批次资产) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) # 3. 初始化Agent(结构化工具调用,适合多工具协同) agent = initialize_agent( tools=tools, llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, memory=memory, verbose=True, # 调试模式,输出思考过程 handle_parsing_errors=True # 处理工具调用格式错误 )
4. 治理逻辑封装:定义 Prompt 模板
目标:通过 Prompt 约束 Agent 的治理流程,确保输出符合目标(标签归类、重复识别)。
-
标签归类 Prompt:
pythontag_prompt = """ 任务:为数据表{table_name}分配业务标签(基于业务标签体系)。 步骤: 1. 调用get_table_metadata获取该表的字段名和字段注释,理解表的业务含义; 2. 检索业务标签体系(通过RAG),确定可用标签(如"用户域""订单域""指标表""维度表"等); 3. 对比表的业务含义与标签定义,输出最匹配的1-2个标签及理由(若不确定,标记"待人工确认")。 输出格式:{"table_name": "{table_name}", "tags": ["标签1", "标签2"], "reason": "..."} """ -
重复识别 Prompt:
pythonduplicate_prompt = """ 任务:判断数据表{table1}和{table2}是否为疑似重复资产。 步骤: 1. 调用get_table_metadata获取两表的字段名、注释,计算字段重合度(字段名+注释语义相似); 2. 调用get_table_dependencies获取两表的上下游依赖,判断是否依赖相同上游; 3. 检索RAG中的重复判定标准(如"字段重合度≥80%+依赖相同上游→疑似重复"); 4. 综合分析,输出是否疑似重复及理由(重合度、依赖关系、业务含义对比)。 输出格式:{"table1": "{table1}", "table2": "{table2}", "is_duplicate": True/False, "reason": "..."} """
三、完整治理流程步骤
1. 批量获取待治理资产清单
通过元数据 API 获取全量数据表名称(如调用http://metadata-api.com/tables),得到待处理清单(例:["dw_user_active", "dw_user_login_count", "ods_order_info", ...])。
2. 执行业务标签归类(批量处理)
python
# 假设待治理表清单为tables_list
tag_results = []
for table in tables_list:
# 生成针对该表的标签归类任务
task = tag_prompt.format(table_name=table)
# 调用Agent执行任务(结合RAG检索和工具调用)
result = agent.run(task)
tag_results.append(eval(result)) # 解析为字典,存入结果列表
# 输出标签归类表(可导出为Excel/数据库)
import pandas as pd
pd.DataFrame(tag_results).to_csv("数据资产标签归类结果.csv", index=False)3. 执行疑似重复资产识别(两两对比或聚类)
python
duplicate_results = []
# 取前100张表进行两两对比(实际可按业务域分组对比,减少计算量)
for i in range(len(tables_list[:100])):
for j in range(i+1, len(tables_list[:100])):
table1 = tables_list[i]
table2 = tables_list[j]
# 生成重复识别任务
task = duplicate_prompt.format(table1=table1, table2=table2)
# 调用Agent执行任务
result = agent.run(task)
duplicate_results.append(eval(result))
# 筛选出疑似重复资产
duplicate_df = pd.DataFrame(duplicate_results)
suspicious_duplicates = duplicate_df[duplicate_df["is_duplicate"] == True]
suspicious_duplicates.to_csv("疑似重复数据资产清单.csv", index=False)4. 人工校验与闭环优化
- 对 Agent 输出的标签和重复清单,由数据治理团队抽样校验,将错误案例(如标签错误、漏检重复)补充到 RAG 的 "历史案例" 文档中;
- 重新训练 RAG 向量库,提升后续治理精度(迭代优化)。
四、关键优化点
-
效率提升:
- 对大批量表,采用 "先聚类再对比"(如用表名 + 字段名的嵌入向量聚类,同类表内对比),减少两两对比次数;
- 缓存高频调用的元数据(如用 Redis 缓存,避免重复调用 API)。
-
精度提升:
- 在 RAG 中加入 "反例"(如 "看似相似但不重复的表:订单表 vs 支付表,因业务含义不同");不断提高精准度
- 对模糊案例(如标签不确定),加入 "人工校验" 节点,避免误判。
-
扩展性:
- 后续可新增 "指标口径标准化" 工具(调用 API 修改字段注释),让 Agent 具备 "自动修正" 能力;
- 集成数据质量工具(如检测空值率),扩展治理维度。
通过这套方案,可实现数据资产治理的 "半自动化":Agent 负责 80% 的标准化工作(标签归类、初步重复识别),人工聚焦 20% 的复杂案例,大幅提升治理效率。
推荐阅读