1. 前言
在UDP编程接口基本使用已经介绍过UDP编程相关的接口,本篇开始介绍TCP编程相关的接口。有了UDP编程的基础,理解TCP相关的接口会更加容易,下面将按照两个方向使用TCP编程接口:
- 基本使用TCP编程接口实现服务端和客户端通信
- 使用TCP编程实现客户端控制服务器执行相关命令的程序
学习本文前,简易先阅读并跟着代码实现:
废话不多说,几乎就是照着UDP的模板来执行:
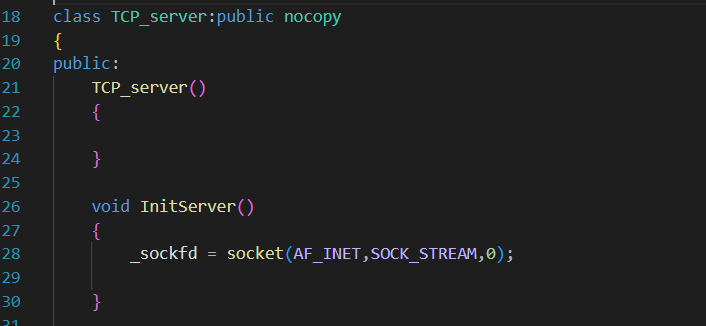
2. 创建服务器TCPServer
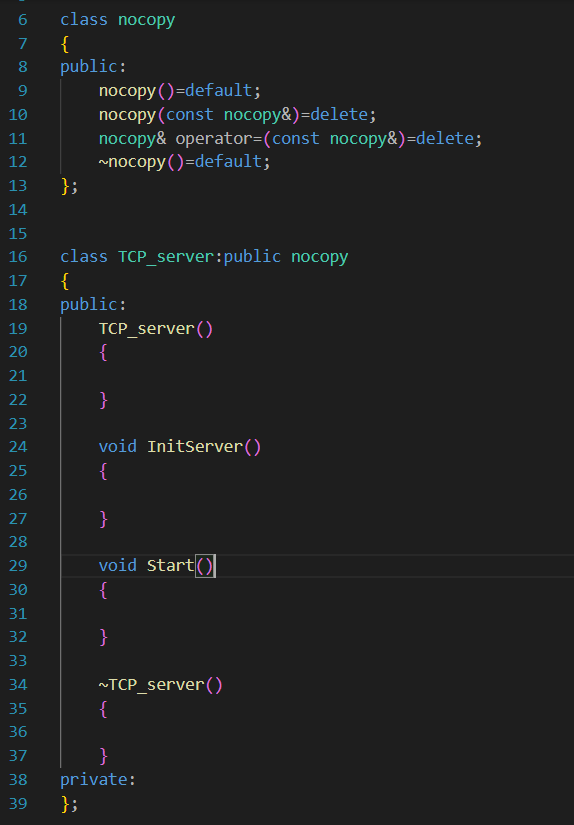
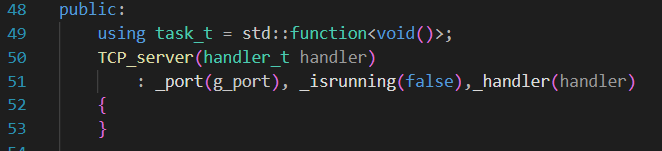
服务器一般是不希望被拷贝或者赋值的。
我们计划在主程序中启动这个服务器就不停下来:
先完成InitServer。
依然是老套路,打开一个socket文件描述符,至于这个文件描述符描述的是什么,先不着急确定,当前我们还处于学习使用代码阶段,暂时无需关心_sockfd的底层实质:
一个服务器当然需要一个socket的文件描述符作为成员函数,域依然选择AF_INET,但是通信方式需要选择SOCK_STREAM,表示面向流的传输协议
UDP和TCP还有诸多明显的不同,比如此处的数据传输方式(SOCK_STREAME而非SOCK_DGRAM)以及马上要遇到的连接方式等。
复习:

完善代码健壮性:
注意,枚举类不能隐式转换成其他类型,此处的错误代码想用在exit中(被我们宏成了DIE,具体可以去末尾的全部代码中查看)直接使用普通enum来列举各种XXX_ERR即可。
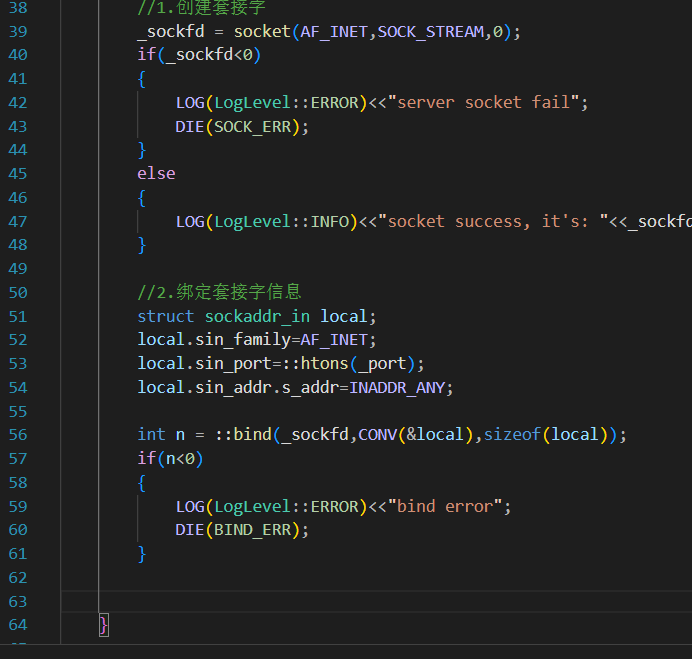
进行第二步:绑定信息
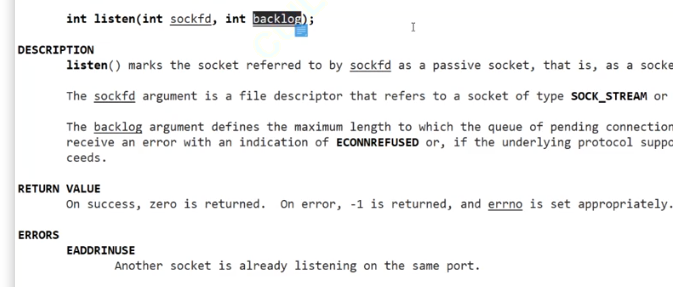
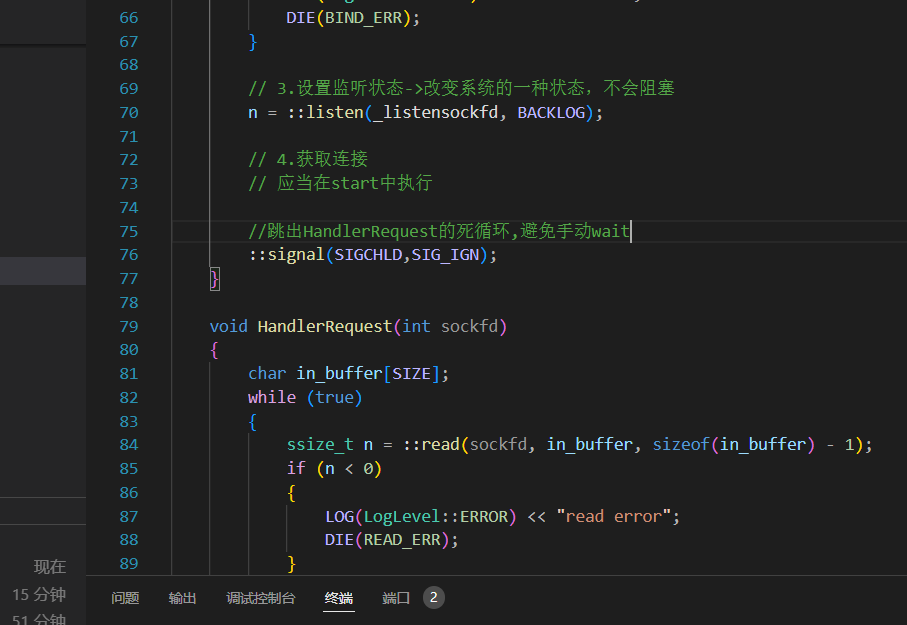
不同于UDP的是,TCP是需要在通信之前建立连接的 ------UDP是无连接的,TCP是有连接的,是面向连接的,是需要"握手"的同样作为 cs模式(Client/Server),tcp服务器会随时等待被连接 ,因此需要将TCP的socket设置成为监听状态
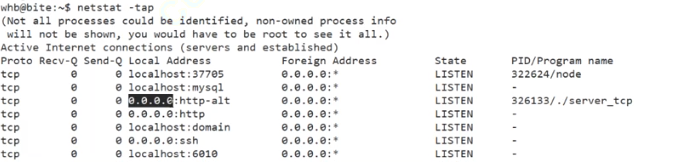
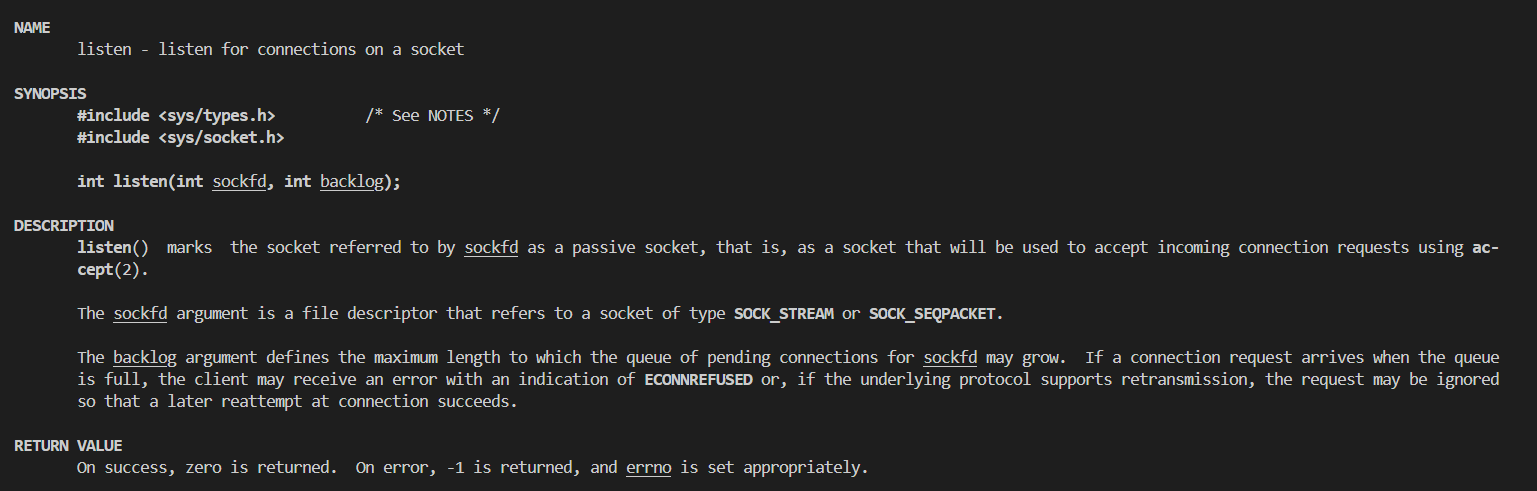
所谓监听状态,是可以在netstat的state状态栏中查询到的一种状态表示tcp正在监测是否被连接,我们描述的这个sockfd也需要被我们用相应的listen函数修饰
该接口的第一个参数表示当前需要被用于传输的套接字,第二个参数表示等待中的客户端的最大个数。
之所以会有第二个参数是因为一旦请求连接的客户端太多但是服务器又无法快速得做出响应,就会导致用户一直处于等待连接状态从而造成不必要的损失。一般情况下第二个参数不建议设置比较大,而是因为应该根据实际情况决定,但是一定不能为0,本次大小定为16。
当监听成功,该接口会返回0,否则返回-1并设置对应的错误码
backlog表示积压量,BACKLOG不能太长,关于backlog的具体解释会在以后学习,这里我们暂时设计成16、32等 2的次方数并且listen也不会阻塞式进行(以后会学到如何阻塞式listen),相当于改变一下服务器的系统状态。
创建套接字还需要accept才能启动
accept是TCP对应的接口中最重要也最有特色的一个
其实,TCP并不像UDP那样使用我们打开的sockfd执行功能,现在用socket打开的这个sockfd更像是景区门口拉你去他家吃饭的人,把你拉到他的餐厅后会招呼其他人来执行具体的服务功能(端茶倒水、点菜)
有点类似于UDP中的recvfrom接口,后两个参数都是输出型参数,如果成功返回一个新的文件描述符,这个返回的文件描述符才会真的提供通信服务。
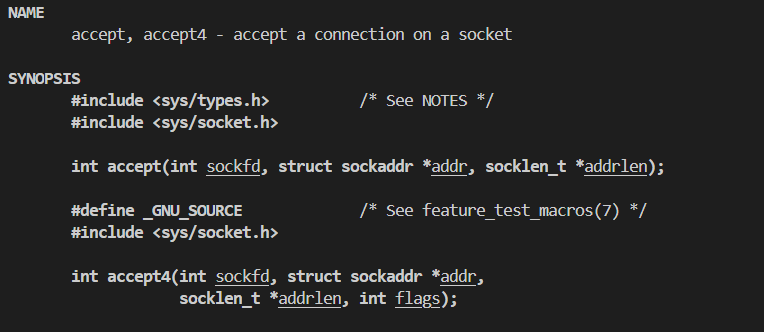
后两个参数的作用: 用于知道是谁在连接我们,谁被我们accept了。
被别人链接时,需要知道被谁连接了。
addr会获得此时连接的客户端的信息。

如果没人连接,会阻塞在这个accept函数处,直到连接成功或者连接失败
3. accept启动服务
所以说,前面创建的套接字,本质创建的是一个特殊的listensockfd,是用来给我们提供服务的一个"包工头"
accept应该是写在Start中的,把之前的sockfd变量名都改成listensockfd。
如果accept失败(想象成饭店门口拉客,拉客成功了就让创建的套接字------餐厅里面的服务员去服务;拉客失败就继续尝试拉下一桌),充其量就算是个warning,"拉客失败,无非是拉下一桌子"
cpp
void Start()
{
if(!_isrunning)
{
_isrunning = true;
}
else
{
LOG(LogLevel::ERROR)<<"run error";
exit(RUNNING_ERR);
}
while(true)
{
struct sockaddr_in peer;
socklen_t peer_len = sizeof(peer);
int sockfd = ::accept(_listensockfd,CONV(&peer),&peer_len);
if(sockfd<0)
{
LOG(LogLevel::ERROR)<<"accept error"<<::strerror(errno);
//拉客失败,不过是重新寻找新顾客
continue;
}
//走到这里就是sockfd创建成功
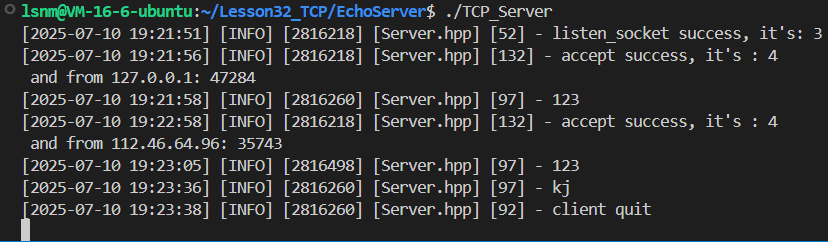
LOG(LogLevel::INFO)<<"accept success, it's :"<<sockfd;
}
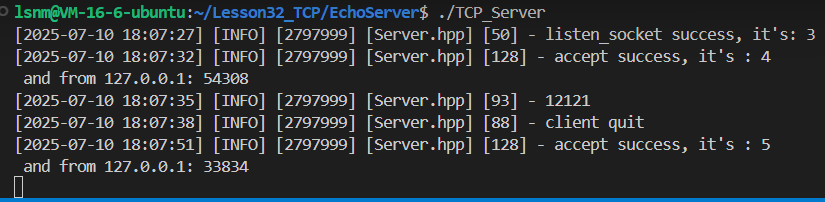
}直接运行现在的tcp服务端:

博主开放了自己云服务器的端口,直接用浏览器访问:xxx.xxx.xxx.xxx:port
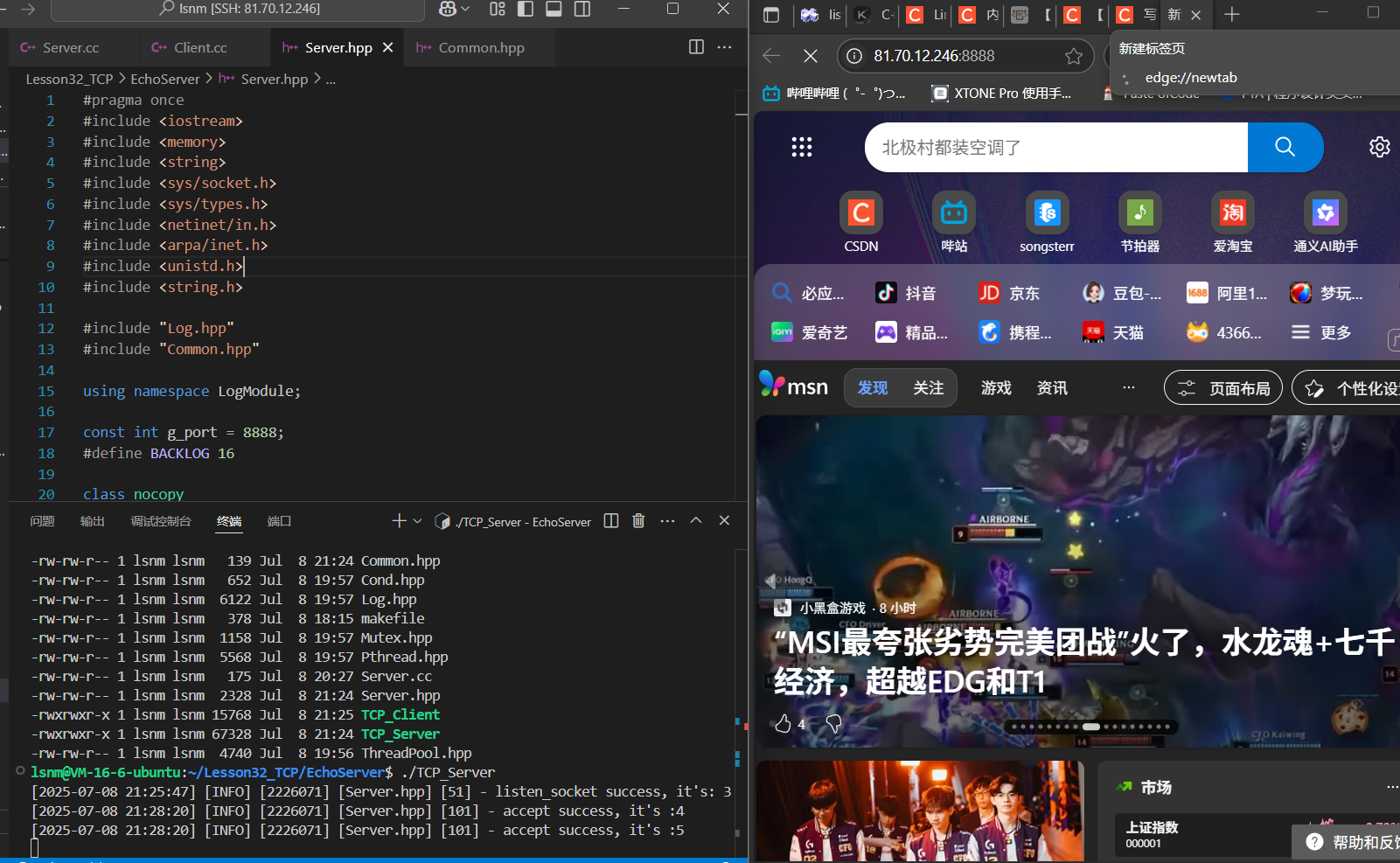
accept处多了两个被打开的文件描述符,并且浏览器右上角的新建标签页就是我们希望打开的,只不过现在没有任何服务可以被找到,所以卡住了。因为浏览器有很多资源需要被访问,所以开了多个文件描述符。
并且可以查看到state是LISTEN
bashnetstat -tnap
4. TCP如何收发消息------实现简单的ECHO逻辑
大部分的生活日常或者实用项目中,都是TCP,原因在于TCP是面向字节流的并且也是全双工的,整个收发消息的过程更像是对文件进行操作,会更加简单
直接使用文件接口::read 、::write接口来操作accept返回的sockfd:
cpp
void HandlerRequest(int sockfd)
{
char in_buffer[SIZE];
while (true)
{
ssize_t n = ::read(sockfd, in_buffer, sizeof(in_buffer) - 1);
if (n < 0)
{
LOG(LogLevel::ERROR) << "read error";
DIE(READ_ERR);
}
in_buffer[n]=0;
std::string echo = "echo# ";
echo+=in_buffer;
::write(sockfd,echo.c_str(),echo.size());
}
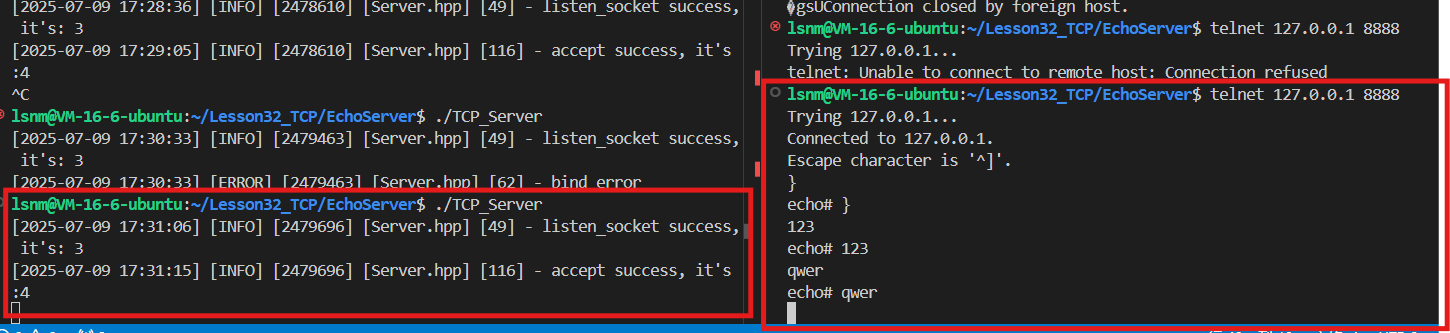
}不需要写TCP的客户端,直接用telnet指令就能访问
也可以在机器上直接telnet去连接、访问,也能观察到多了一个sockfd被打开
当前代码存在死循环,在HandlerRequest中死循环后无法脱离循环执行新的accept,所以暂时还不能加入新用户,不过整体概念已经能看见了

面向字节流的特点
上一次谈面向字节流是管道,再上一次是文件
至于什么是面向字节流或者面向数据报的,只有在协议的原理里才能知道,今天再次在概念层面理解一下
面向字节流"是一种网络通信中的数据传输方式,指的是数据被视作一连串的无结构字节,而不是按照特定的数据块或记录进行传输。这种传输方式是TCP协议的一个重要特性。
无消息边界:在面向字节流的协议(如TCP)中,数据被视为连续的字节流,没有明确定的消息边界。发送方可以将数据拆分成多个TCP报文段进行传输,接收方需要根据报文段的序号和确认机制重新组装数据。
数据完整性与顺序性:TCP协议保证数据的可靠传输,确保接收端收到的数据无损坏、无间隔、非冗余且按序。
粘包问题:由于TCP不区分消息边界,发送方的多个消息可能会被合并到同一个TCP报文段中,或者一个消息被拆分成多个报文段,导致接收方无法直接区分消息的边界,这就是所谓的"粘包"问题。
与面向报文的对比
面向报文(如UDP):UDP协议是面向报文的,每个UDP报文都是一个独立的消息,具有明确的消息边界。UDP不会对应用层交下来的报文进行拆分或合并,而是保留报文的边界。
面向字节流(如TCP):TCP将数据视为连续的字节流,不关心消息的含义或边界,只保证字节的顺序和完整性。
5. 客户端
类似于UDP处的客户端,我们直接在客户端.cc文件中写。
第一版客户端代码:
cpp
#include "Client.hpp"
using namespace LogModule;
int main(int argc, char *argv[])
{
if (argc != 3)
{
std::cout << "usage like ./TCP_Client 81.70.12.246 8888";
exit(SERVERUSING_ERR);
}
// 1.接受参数
int server_port = std::stoi(argv[2]);
std::string server_IP = argv[1];
// 2.创建客户端套接字
int sockfd = ::socket(AF_INET, SOCK_STREAM, 0);
// 3.绑定服务端信息
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = ::htons(server_port);
server_addr.sin_addr.s_addr = ::inet_addr(server_IP.c_str());
// 4.连接客户端
int n = ::connect(sockfd, CONV(&server_addr), sizeof(server_addr));
// 客户端调用connect会自动进行绑定
if (n != 0)
{
LOG(LogLevel::FATAL) << "connect fail";
exit(CONNECT_ERR);
}
else
{
LOG(LogLevel::INFO)<<"connect success";
}
// 5.message
while (true)
{
std::string message;
LOG(LogLevel::INFO)<<"PLEASE ENTER#";
std::getline(std::cin, message);
int n = ::write(sockfd,message.c_str(),message.size());
if(n>0)
{
char in_buffer[SIZE];
int m = ::read(sockfd,in_buffer,SIZE-1);
LOG(LogLevel::INFO)<<in_buffer;
in_buffer[m] = 0;
}
else
{
//write失败
break;
}
}
::close(sockfd);
}以下是注意要点:
同UDP理。客户端不需要显式bind,操作系统会自动绑定
更不需要监听,客户端是用来连接别人的
但是客户端有新的接口:connect

简单测试如下:
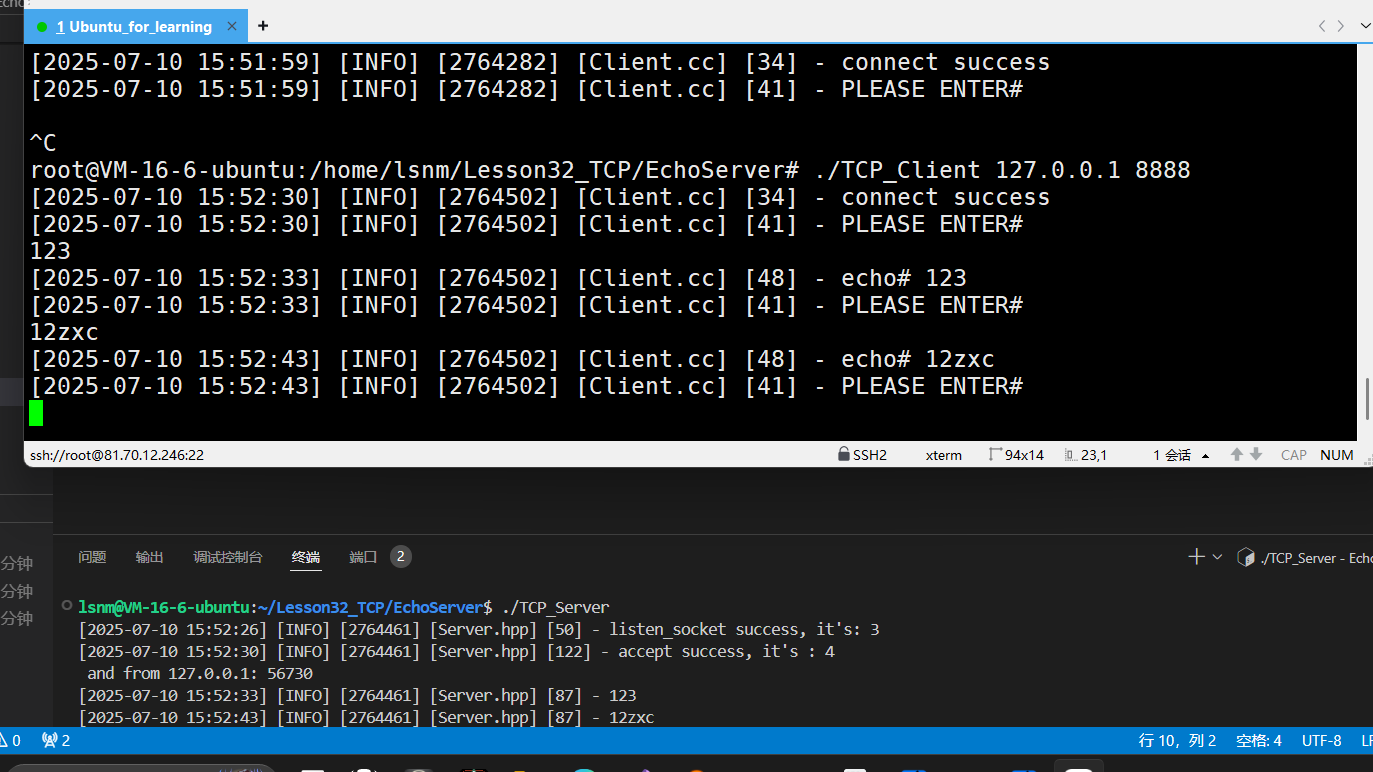
0.处理两个有学习价值的bug
现在的问题有:
1、直接退出客户端会导致服务器也退出
2、打开一个服务器,再打开一个客户端,如果退出客户端,重新连接是连接不上的。
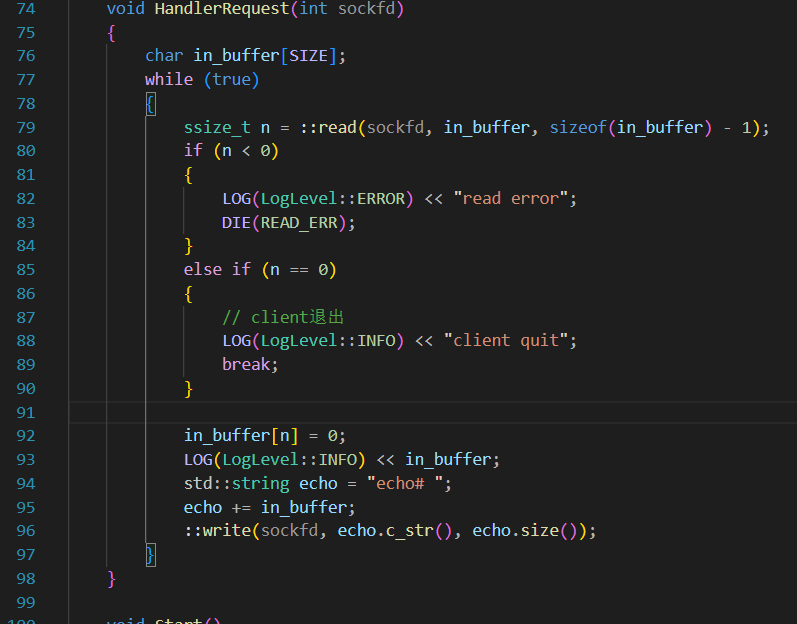
究其本质,是因为服务器的执行具体逻辑中的read函数写的有问题:
- 到达文件末尾(EOF)
如果从文件中读取数据,当读取到文件末尾时,
read函数会返回0。这是最常见的返回0的情况。
- 无数据可读
当从输入流(如标准输入流
std::cin或网络流)读取数据时,如果当前没有可用数据,read函数可能会返回0。例如,从标准输入流读取时,如果没有用户输入,
read函数可能会返回0。
- 流状态异常
如果输入流的状态异常(如文件打开失败、流被关闭等),
read函数可能会返回0
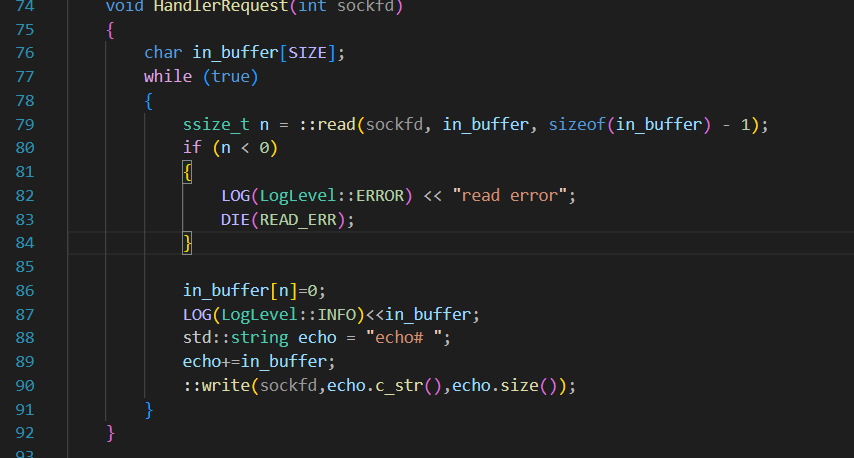
再echo$?一下,发现退出码是141:
退出码是141,就该思考是不是和管道中流关闭有关引起的进程被杀死的问题了。
当客户端退出时,服务端读取数据会得到0(EOF ,END OF FILE)。此时服务端仍尝试向已退出的客户端发送消息,由于目标客户端已不存在,这种操作没有实际意义。操作系统会检测到这种情况,并发送SIGPIPE信号终止服务端进程。
错误码141印证了上述原因。
SIGPIPE触发条件: 当进程向已关闭的管道(Pipe)、套接字(Socket)或文件描述符写入数据时,内核会发送SIGPIPE信号,该信号的默认处理方式是终止进程。
服务器端"收到了空"也可以作证。
处理一下read的返回值即可:
现在服务器只能处理一个客户端,必须要退一个客户端,才能处理下一个请求。并且会一直打开新的文件描述符我们在另一个终端上不停的发消息、退出、再重新连接:
文件描述符一直在涨!这是标准的文件描述符泄露。
关于文件描述符:
文件描述符是有限的、有用的资源。
文件描述符本质就是一个数组下标,文件生命周期随进程,如果不手动关,就存在文件描述符泄露问题
一个进程本身对应一张文件描述符表,既然文件描述符表有限,一个进程又肯定不止只能处理32、64个文件等,说明进程肯定是可以扩容的,可以使用
bashulimate -a查看当前的企业级云服务器可以打开的最大文件描述符个数
之所以会出现这个问题就是因为在上面的逻辑中:只有接收成功了才会发送消息,而一旦接收成功后,就在写入和读取中死循环,此时就导致accept不能继续接收。解决这个问题就需要考虑到使用子进程或者新线程,将接收和读写分别放在两个执行进程或者执行流中,根据这个思路下面提供三种解决方案:1、子进程版本
2、新线程版本
3、线程池版本
1.多进程版本
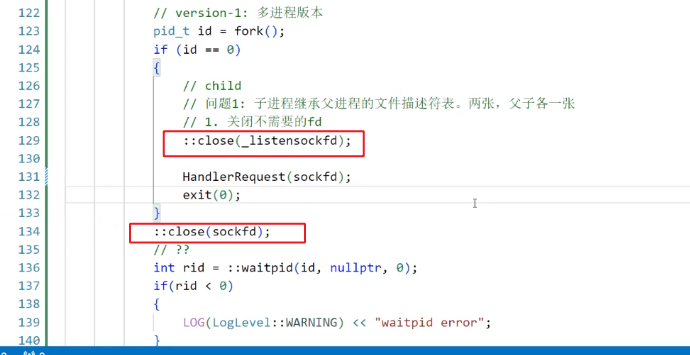
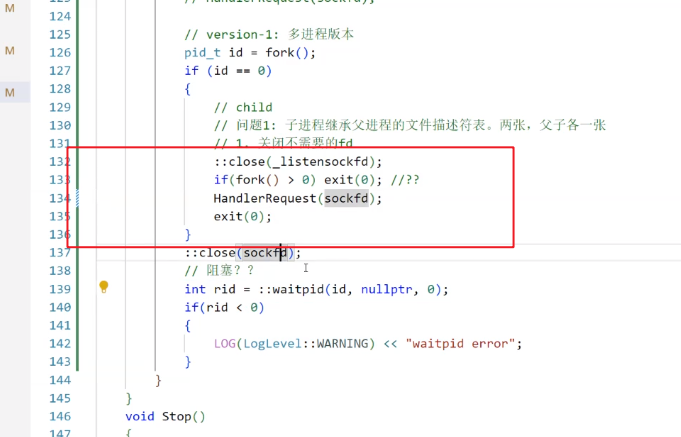
因为子进程继承文件描述符,所以打开的sockfd作为一个文件描述符也是能被看到的
所以子进程也能看到listensocket,子进程应该关闭他父进程也应该关闭核父进程不相干的、已经传给子进程的sockfd
不用担心这样是否会关闭文件,在文件系统部分有讲过,close不过是减少了文件的引用计数。
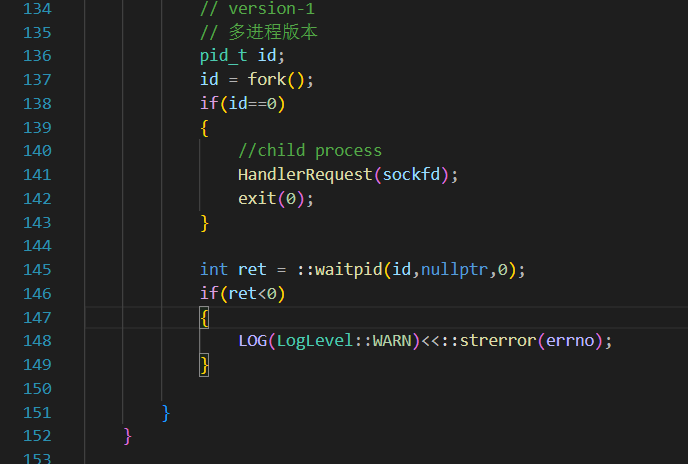
不过如果只是单纯的这样搞一个分支去执行任务,父进程依然在等待子进程 ,本质依然是一个"单进程"模式但是又必须要wait,否则会有僵尸进程问题;又不愿意一直等,效率太低。
解决办法1:
使用signal,让父进程忽略子进程退出时的SIGCHILD,操作系统自行回收,避免僵尸进程:76行
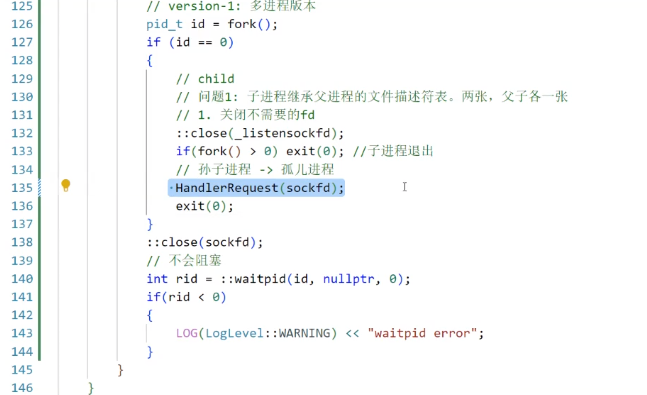
解决办法2:利用孤儿进程
在子进程中执行下述代码,创造一个孙子进程,然后退出"子进程",这下孙子进程就归系统管了,无需父进程手动释放
cppif(fork()>0) exit(0);执行效果就很好了
运行现在的程序,会发现如果查进程的话,会有一个进程的父进程是1,这个就是刚刚我们所说的孙子进程,他是一个孤儿进程,所以父进程是1
进程毕竟是一个成本比较高的办法,下面尝试一下多线程。
2. 多线程版本
主线程和新线程是如何看待文件描述符表的?
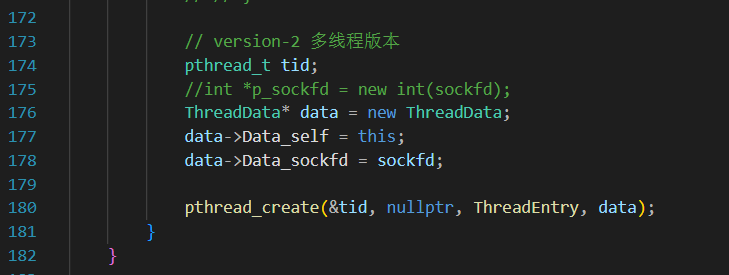
多线程之间直接共享一张表,但是需要我们把现在哪个fd是正在用于服务的给传到新线程工作的fd上去,可以直接:pthread_create(&tid,nullptr,HandlerRequest,&sockfd)吗?
sockfd可能在被传回来的时候就直接释放掉或者被覆盖 ,建议使用一个堆上的Int传进去来避免生命周期的问题。同时,HandleRequest作为收发消息的函数,最好是封装一层满足void* xxx(void* args)函数格式的函数入口,来作为Pthread_create调用的函数(或者直接C++的thread(func,args)也可以)。
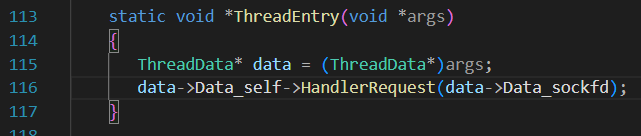
此处遇到了"老问题",必须要给ThreadEntry加static,避免参数里隐藏着的this指针
可是static修饰的函数又没法调用类内函数
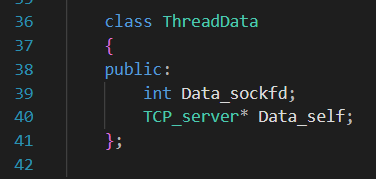
所以,现在需要又传sockfd,又传this,构造一个ThreadData类来作为传输介质。


最后,为了让线程自动完成任务,使用detach(而非join!!!)来剥离线程
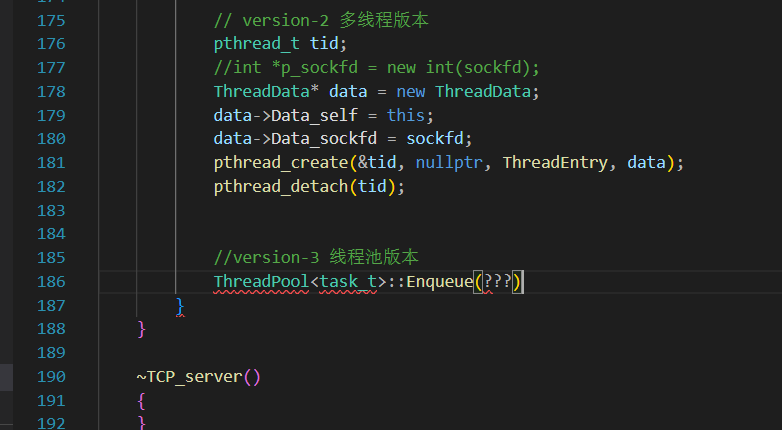
3.线程池版本
为了避免来一个请求才创建线程的低效问题,我门可以创建线程池(所有引用的库、内容都和UDP中写的一样,都是博主在之前的文章中自己封装的)
我们封装的线程池都是单例模式:
直接一个lambda表达式就解决了。

3.1 长任务-短任务(了解)
之前线程池的设计中,HandlerTask(线程池中执行任务的函数)是一执行就不停止的,所以此处的线程池被设计成了长任务模式,其实聊天更应是一个短任务。线程池版本比较适合处理短任务,或者是用户量少的情况。
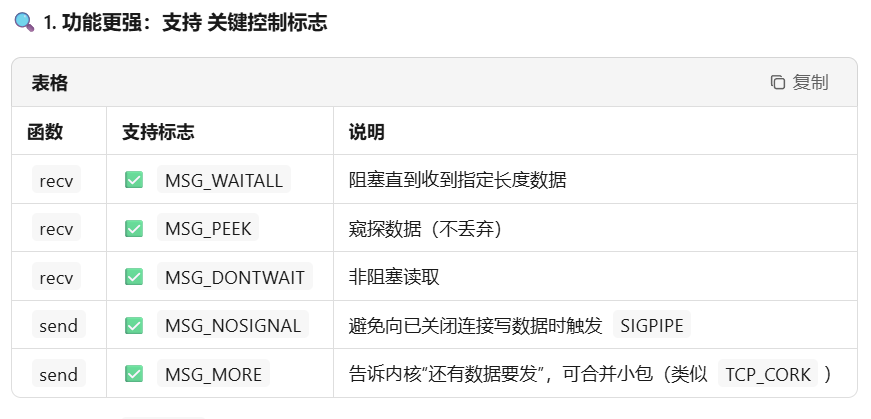
3.2 recv 与 send
区别于recvfrom&sendto 、read&write的第三组概念:
总结 :
recv/send是套接字的"专业工具",而read/write是"通用扳手"。专业的事应该交给专业的函数。
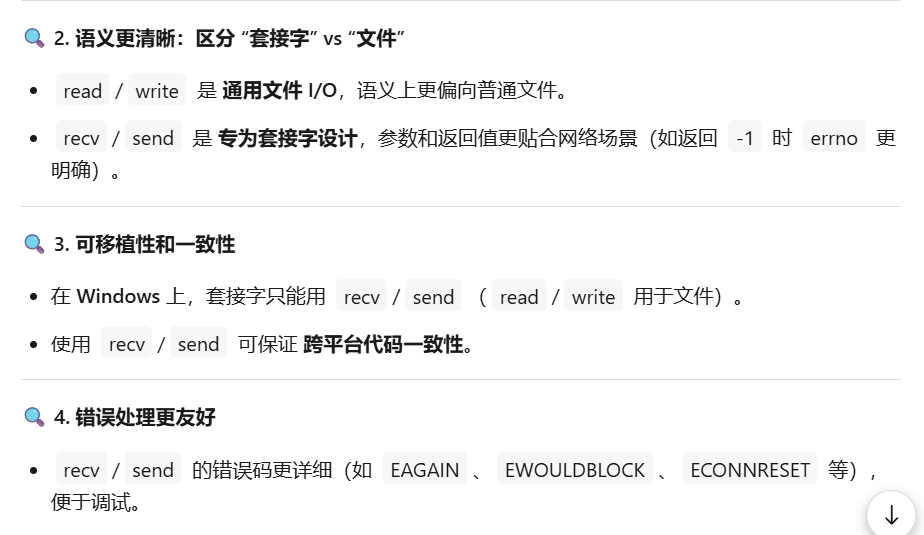
read其实是不完善的,我们需要修改。
正如前文所提,客户端发过来信息统一当字符串处理是有问题的------不过鉴于现在还没有学协议,所以我们在把read\write改成专用接口时,最后的flags只需要直接设计成0。
默认用0,表示阻塞的。

测试中的小tips:
如果客户端连着服务器,服务器自己先挂了,服务器会进入一个过度字段TIME_WAIT,必须等大概60-120秒才能再使用这个端口
6. 在EchoServer中加入业务
实现业务:客户端输入一个指令,服务器执行这个指令,并且返回这个指令的执行结果。
很明显,上层的业务依然利用回调函数去执行。
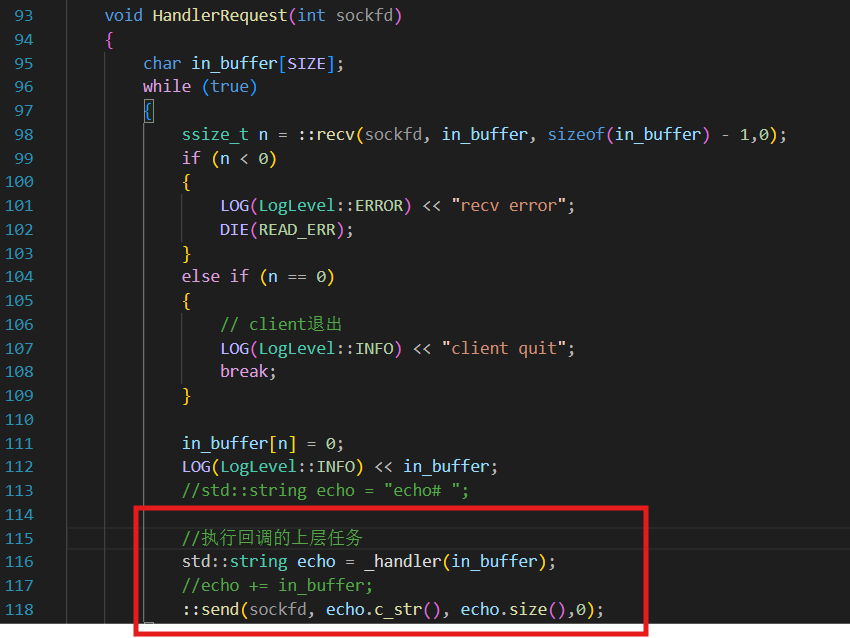
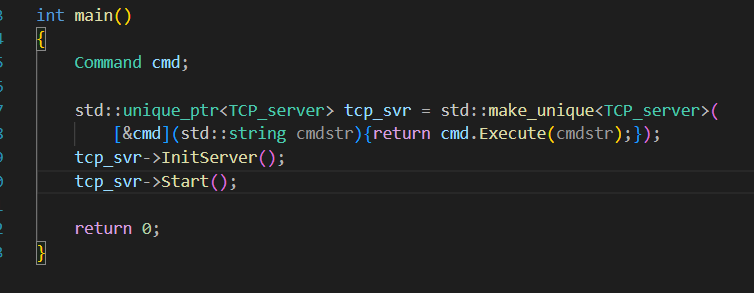
记得在主程序中是要写lambda来传进来的:
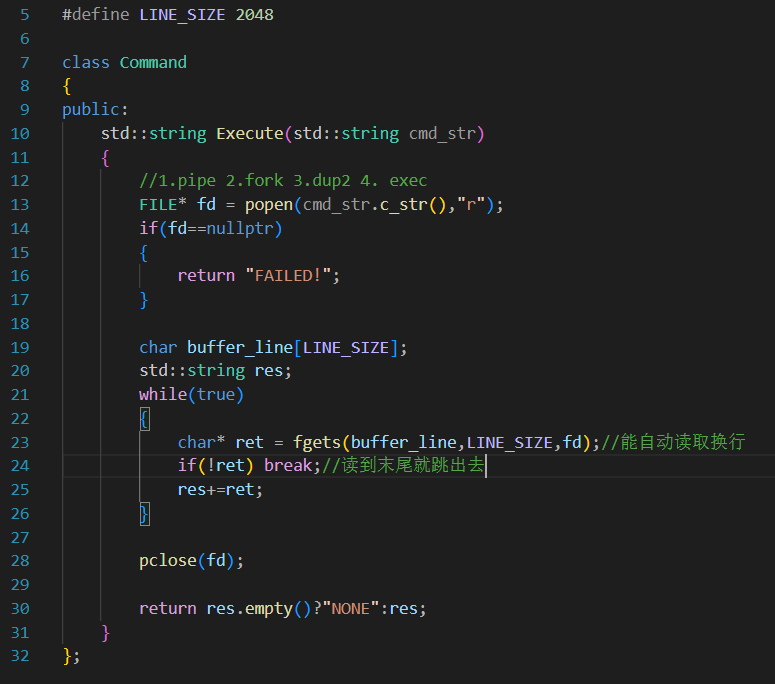
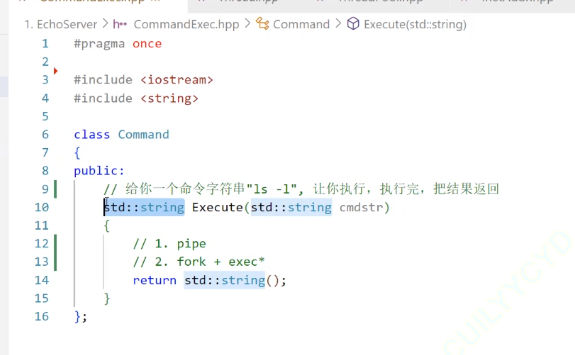
command的具体逻辑实现: 本次我们使用接口popen。popen的内涵是1.pipe 2.fork 3.dup2 4. exec的封装,我们一个一个来看:
作为一个线程,我们再fork的话,其实就相当于父进程fork一个子进程出来
标准输出重定向到管道的写端dup2(pipe1,1)
popen
1.pipe 创建管道
2.fork+dup(pipe1,1)+exec*-----对命令做分析,交给子进程的exec*家族,并且希望执行结果返回给父进程
3.return
让子进程执行一个命令,并且把命令的执行结果返回给父进程
popen返回的就是一个文件流,可以通过这个文件流向管道进行读写 ,至于是读还是写,就是popen第二个参数决定的。
popen,直接在一个新的进程中执行新命令并返回。
然后我们再创建一个buffer用于去popen打开的 文件描述符中使用fgets一行一行的读取内容。
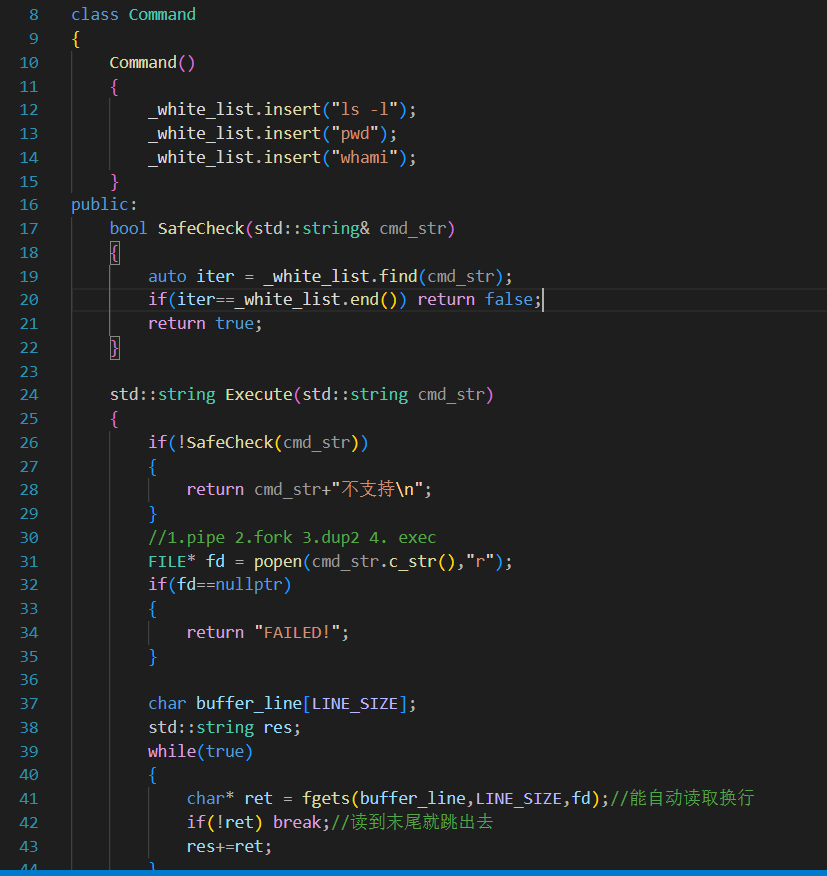
如果不想执行某几个命令,可以用一个容器去记录去过滤(黑名单做法)本次采用白名单做法,也就是只有哪几个命令可以用(因为现在的程序还不支持rm -rf等命令):
使用一个set来记录。
这下就可以实现一个远程控制服务器执行部分指定命令的程序了。