🎯 核心要点 (TL;DR)
- 突破性推理能力:Qwen3-30B-A3B-Thinking-2507 在数学、编程和逻辑推理方面显著提升,AIME25 得分达到 85.0
- 本地部署友好:仅需 32GB RAM 即可运行量化版本,在 M4 Max 上可达 100+ tokens/s
- 专注推理模式:与非推理版本分离,专门优化复杂推理任务,推理长度显著增加
- 256K 长上下文:原生支持 262,144 tokens 上下文长度,适合复杂文档处理
- 社区积极反馈:开源社区快速提供 GGUF 量化版本,工具兼容性持续改进
目录
- [什么是 Qwen3-30B-A3B-Thinking-2507](#什么是 Qwen3-30B-A3B-Thinking-2507)
- 核心技术特性
- 性能基准测试
- 部署与使用指南
- 实际测试对比
- 社区反馈与讨论
- 常见问题解答
模型概述
Qwen3-30B-A3B-Thinking-2507 是阿里巴巴通义千问团队在 2025年7月30日 发布的最新推理模型。这是继非推理版本 Qwen3-30B-A3B-Instruct-2507 之后的配套推理模型,标志着 Qwen 团队正式分离推理和非推理模型路线。
💡 重要变化
与之前的混合推理模式不同,新版本采用纯推理模式,不再需要手动启用
enable_thinking=True参数。
技术特性
模型架构详情
| 特性 | 规格 |
|---|---|
| 总参数量 | 30.5B(激活 3.3B) |
| 非嵌入参数 | 29.9B |
| 层数 | 48 |
| 注意力头数 | Q: 32, KV: 4 (GQA) |
| 专家数量 | 128(激活 8 个) |
| 上下文长度 | 262,144 tokens(原生支持) |
| 架构类型 | 混合专家模型(MoE) |
推理机制优化
推理流程:
用户输入 → <think> 标签自动添加 → 内部推理过程 → </think> 标签 → 最终回答⚠️ 注意事项
模型输出通常只包含
</think>标签,开始的<think>标签由聊天模板自动添加。这是正常现象,不是错误。
性能评测
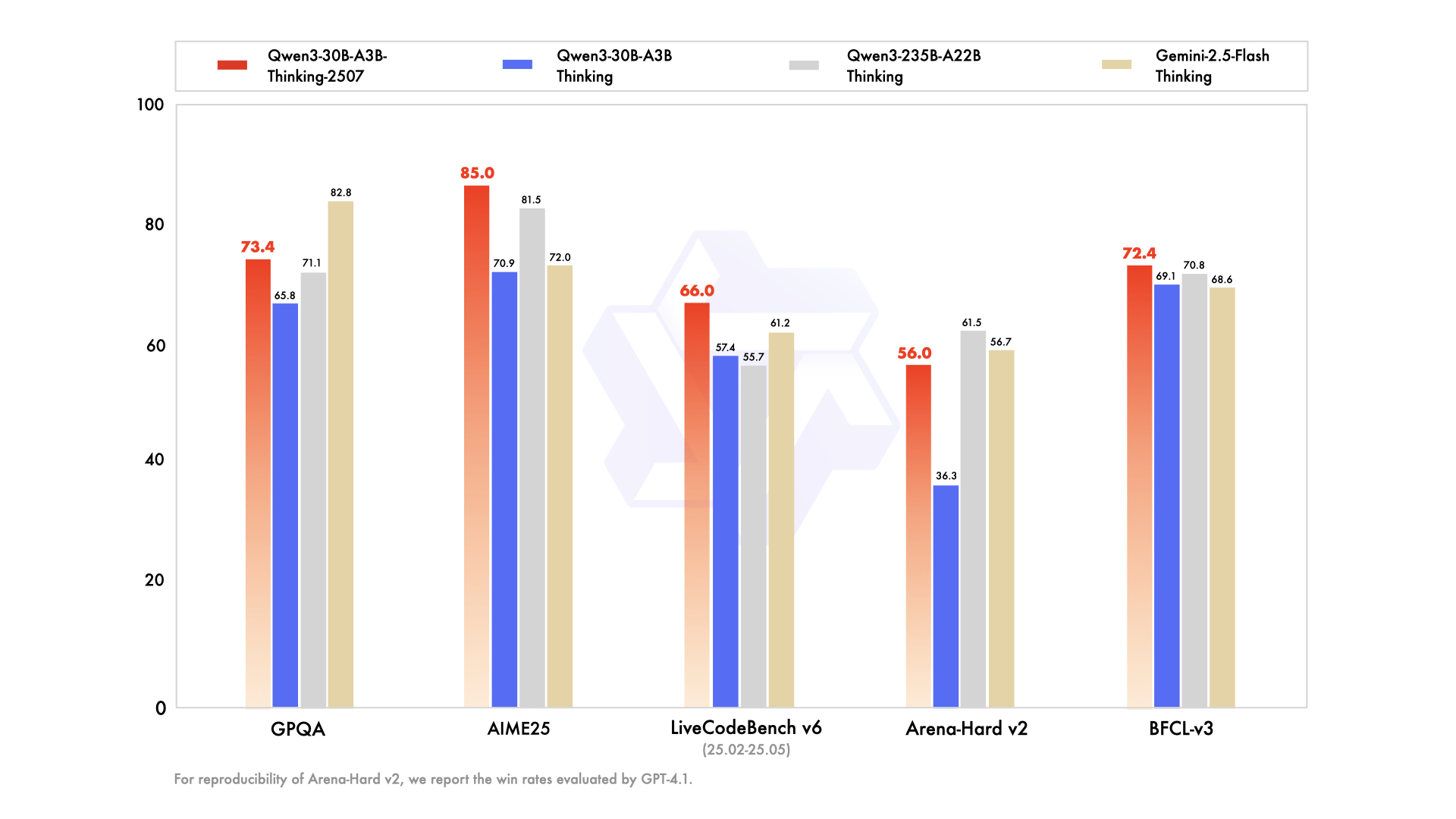
核心基准测试对比
| 测试项目 | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|---|---|
| 知识理解 | ||||
| MMLU-Pro | 81.9 | 82.8 | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | 92.7 | 89.5 | 91.4 |
| GPQA | 82.8 | 71.1 | 65.8 | 73.4 |
| 推理能力 | ||||
| AIME25 | 72.0 | 81.5 | 70.9 | 85.0 |
| HMMT25 | 64.2 | 62.5 | 49.8 | 71.4 |
| LiveBench | 74.3 | 77.1 | 74.3 | 76.8 |
| 编程能力 | ||||
| LiveCodeBench v6 | 61.2 | 55.7 | 57.4 | 66.0 |
| CFEval | 1995 | 2056 | 1940 | 2044 |
| OJBench | 23.5 | 25.6 | 20.7 | 25.1 |
✅ 性能亮点
- 数学推理:AIME25 测试中达到 85.0 分,超越 Gemini2.5-Flash-Thinking
- 编程能力:LiveCodeBench v6 得分 66.0,显著提升
- 工具调用:在多个 Agent 基准测试中表现优异
部署指南
环境要求
bash
# 基础要求
transformers >= 4.51.0
torch >= 2.0
# 推荐配置
- GPU: 24GB+ VRAM(完整精度)
- RAM: 32GB+(量化版本)
- 存储: 60GB+快速开始代码
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备输入
prompt = "解释大语言模型的工作原理"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 生成回答
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# 解析推理内容
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668) # </think> token
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True)
final_answer = tokenizer.decode(output_ids[index:], skip_special_tokens=True)
print("推理过程:", thinking_content)
print("最终答案:", final_answer)部署选项对比
| 部署方式 | 优势 | 适用场景 | 命令示例 |
|---|---|---|---|
| SGLang | 高性能推理 | 生产环境 | python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507 --reasoning-parser deepseek-r1 |
| vLLM | 批量处理 | API 服务 | vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --enable-reasoning --reasoning-parser deepseek_r1 |
| Ollama | 本地使用 | 个人开发 | ollama run qwen3:30b-a3b-thinking-2507 |
| LM Studio | 图形界面 | 桌面应用 | GUI 操作 |
实测对比
SVG 生成测试
测试提示:"生成一个骑自行车的鹈鹕 SVG"
推理版本结果:
- 推理过程详细考虑了各个组件的位置和比例
- 最终输出的 SVG 质量较低,元素排列不合理
- 看起来像"灰色雪人"而非鹈鹕
非推理版本结果:
- 直接生成,质量更好
- 包含可爱的细节,如鹈鹕的微笑
- 整体布局更加合理
🤔 有趣发现
在创意任务中,推理模式并不总是产生更好的结果。过度的推理可能反而影响创造性输出。
编程任务测试
测试提示:"用 HTML 和 JavaScript 实现太空入侵者游戏"
推理版本表现:
- ✅ 游戏可以正常运行
- ✅ 包含更详细的敌人设计(眼睛、触角等)
- ❌ 游戏平衡性有待改进(敌人射击频率低)
非推理版本表现:
- ❌ 游戏运行有问题(移动速度过快)
- ❌ 基本功能不完整
✅ 推理优势明显
在复杂编程任务中,推理模式显著提升了代码的完整性和可用性。
社区观点
Reddit LocalLLaMA 社区反馈
积极评价:
"这基本上是一个 GPT-4 级别的模型,可以在 32GB RAM 的笔记本上运行(量化版本)。虽然在训练材料的事实回忆方面不如大模型,但配合工具使用(如维基百科查找)这不是问题,甚至比更大的模型更可取。"
"你们的速度、可靠性和工作质量令人惊叹。免费提供这样的服务感觉几乎是犯罪。"
技术讨论:
社区用户报告了聊天模板的兼容性问题:
- 原始模板在某些工具中无法正确解析
<think>标签 - Unsloth 团队快速响应,重新上传了修复版本的 GGUF 文件
- 解决方案:移除聊天模板中的
<think>标签,因为模型几乎 100% 会自动生成
Hacker News 技术讨论
性能数据:
- M4 Max 128GB 上运行 MLX 4bit 量化版本
- 小上下文:100+ tokens/s
- 大上下文:20+ tokens/s
应用场景:
"这个模型在本地文档处理方面表现卓越。它超快、非常智能、幻觉率低,长上下文性能出色(最多 256k tokens)。速度使其成为那些囤积数据的封闭专有 API 的合法替代品。"
与其他模型对比:
- 在垃圾邮件过滤基准测试中,仅次于 Gemma3:27b-it-qat
- 但 Qwen3 速度更快,更适合实时应用
Simon Willison 的深度测试
测试结论:
- 创意任务:推理版本在 SVG 生成等创意任务中表现不如非推理版本
- 编程任务:推理版本在复杂编程任务中明显优于非推理版本
- 模型定位:推理和非推理版本各有优势,应根据任务类型选择
最佳实践建议
推荐参数设置
python
# 采样参数
generation_config = {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"min_p": 0.0,
"presence_penalty": 1.0, # 减少重复
"max_new_tokens": 32768, # 一般任务
# "max_new_tokens": 81920, # 复杂推理任务
}任务特定优化
| 任务类型 | 推荐设置 | 提示词建议 |
|---|---|---|
| 数学问题 | max_tokens=81920 | "请逐步推理,并将最终答案放在 \boxed{} 中" |
| 多选题 | max_tokens=32768 | "请在 answer 字段中显示选择,如 \"answer\": \"C\"" |
| 编程任务 | max_tokens=81920 | "请提供完整的可运行代码,包含错误处理" |
| 文档分析 | max_tokens=32768 | "请基于提供的文档内容进行分析" |
多轮对话注意事项
⚠️ 重要提醒
在多轮对话中,历史记录应只包含最终输出部分,不需要包含推理内容。这有助于:
- 减少 token 消耗
- 提高对话连贯性
- 避免推理过程干扰
🤔 常见问题解答
Q: 为什么模型输出只有 </think> 而没有 <think>?
A: 这是正常现象。聊天模板会自动添加开始的 <think> 标签,模型只需要输出结束标签。如果在某些工具中遇到解析问题,可以修改聊天模板移除 <think> 标签。
Q: 推理版本和非推理版本应该如何选择?
A:
- 选择推理版本:复杂数学、编程、逻辑推理、多步骤问题
- 选择非推理版本:创意写作、快速问答、简单任务、对话聊天
- 性能考虑:推理版本需要更多计算资源和时间
Q: 量化版本的性能损失大吗?
A: 根据社区测试,Q4_K_M 量化版本在大多数任务上保持了良好性能,但建议:
- 关键应用使用 Q8_0 或更高精度
- 资源受限环境可使用 Q4_K_M
- 避免过度量化(Q3 以下)
Q: 如何处理 OOM(内存不足)问题?
A:
- 减少上下文长度:从 262144 降至 131072 或更低
- 使用量化版本:选择合适的量化级别
- 分层加载 :使用
device_map="auto"自动分配 - 批处理优化:减少 batch_size
Q: 模型在哪些语言上表现最好?
A: 根据基准测试,模型在多语言任务上表现优异:
- 中文:原生支持,表现最佳
- 英文:接近原生水平
- 其他语言:通过 MMLU-ProX 和 INCLUDE 测试验证,支持多种语言
总结与建议
Qwen3-30B-A3B-Thinking-2507 代表了开源推理模型的重要进步。其主要优势包括:
✅ 技术突破 :在数学和编程推理方面达到新高度
✅ 部署友好 :适合本地部署,资源需求合理
✅ 社区支持 :活跃的开源社区,工具生态完善
✅ 专业定位:专注推理任务,避免混合模式的复杂性
立即行动建议
- 评估需求:根据应用场景选择推理或非推理版本
- 测试部署:从量化版本开始,验证性能表现
- 优化配置:根据任务类型调整参数设置
- 关注更新:跟踪社区反馈和模型更新
相关资源
本文基于 2025年7月31日 的信息整理,模型和工具可能持续更新。建议关注官方渠道获取最新信息。