本章你将看到这些实用干货:
- ✅ 如何用 检索增强生成(RAG) 来减少胡说八道
- ✅ 如何让大模型"反向监管"人类,来减少自动化偏见
- ✅ 如何用大模型的 embedding 赋能传统机器学习算法
- ✅ 如何设计 LLM 的产品体验,让用户和公司都不"掉坑"
前情回顾:你已经掌握了大模型的基本功
到现在为止,你应该已经对 LLM 有了比较"像回事儿"的理解了:
- 它能模仿人类写作;
- 背后吃下了亿万文本;
- 能力强大,但也不是完美体,偶尔也会一本正经地胡说八道。
我们之前也说了,减少模型出错的一种方式是:
加入专业领域知识、或者配合使用一些工具(比如代码解析器、规则校验器等)。
现在,是时候动手搞个"能上线"的方案了!
本章我们就要讲一件实战事:
如何基于大语言模型,设计一个真正能投入使用的"解决方案"?
我们不会空谈理论,而是用一个你我都熟悉的场景来举例:
👉 "联系技术客服" ------ 也就是你电脑坏了、App 出 bug、Wi-Fi 崩了,找人求救那种情况。
第一步,先做一个 Chatbot?
没错,聊天机器人基本上是大家接触 LLM 的第一扇门。
它能跟你一来一回聊天,生成的语句还挺"人模人样"。
所以我们会先探讨一个常见做法:
👉 在客户服务场景中部署一个 LLM 驱动的 Chatbot。
当然,听起来不错,但风险也是真的多 。
本章就会评估这些风险值不值得。
不过如果风险不大,简单的 Chatbot 反而可能就是"够用了"的解决方案。
接下来,我们得想办法"控风险"
如果你担心大模型"飘了",可以通过改进应用设计来管住它。
但注意:
如果你指望"让人来审查大模型每一句输出",这条路问题很多,
因为人类自己也容易"被 AI 带偏",这就是所谓的 自动化偏见(automation bias) 。
很神奇的是,我们可以换个思路:
👉 让 LLM 来监督人类,而不是反过来!
我们还会聊到:
- 怎么用 embedding(向量化表示) 把文本转成"模型能理解的数字";
- 怎么把这些向量喂给传统机器学习模型来帮大模型打辅助,
👉 解决一些 LLM 本身搞不定的任务。
最后,来聊聊"怎么把技术包装得让用户更信任"
技术再牛,如果用户一脸"这啥玩意?"那也白搭。
我们会讨论"可解释 AI(explainable AI)"这个热门方向------
它试图解释模型是怎么想的、为什么给出这个答案。
不过,研究发现:
解释性≠有用性,给用户解释 LLM 背后的机制,并不能解决用户真正的焦虑。
所以更有效的做法其实是:
- 强调透明性:模型输出的来龙去脉要清楚;
- 用户和产品目标一致:你别把 AI 当挡箭牌;
- 构建正向反馈循环:用户用了之后能反馈 → 模型能优化 → 下次更准。
这样,才是真正能让公司和用户双赢的解决方案设计。
8.1 干脆做个聊天机器人?听起来真香!
一点也不意外,很多人在接触到 LLM(大语言模型)之后,第一反应就是:
"我们做个 Chatbot 吧!"
确实,这是个又显眼又顺手的起步方式。
尤其是现在的 ChatGPT,简直就是聊天机器人天花板:
- 能和你一来一回对话;
- 能听懂上下文;
- 能查资料还能组织成句子,
简直是"客服的梦想同事"。
你要真拿以前的老路子搞客服,可能才是真的"不懂事"
过去我们搞客服怎么搞?
- 搭个专家系统,就是用树状菜单给你套话选项;
- 让它走一棵"决策树":
"你是不是打不开App?"
"你是不是忘记密码?"
"你是不是点了'注销账户'?"
客户听得头大,客服也不想搭理,最后只能靠 FAQ + 工单系统硬撑。
现在呢?
有了大模型,用户只要打开一个对话框,就能直接对 AI 说:
"我买的那个智能猫砂盆又联网失败了,快救我!"
不需要翻 FAQ、不需要发邮件、不需要等 IVR(语音菜单)转人工,
AI 直接接招,甚至还能陪你吐槽几句。
听起来是不是像极了未来?
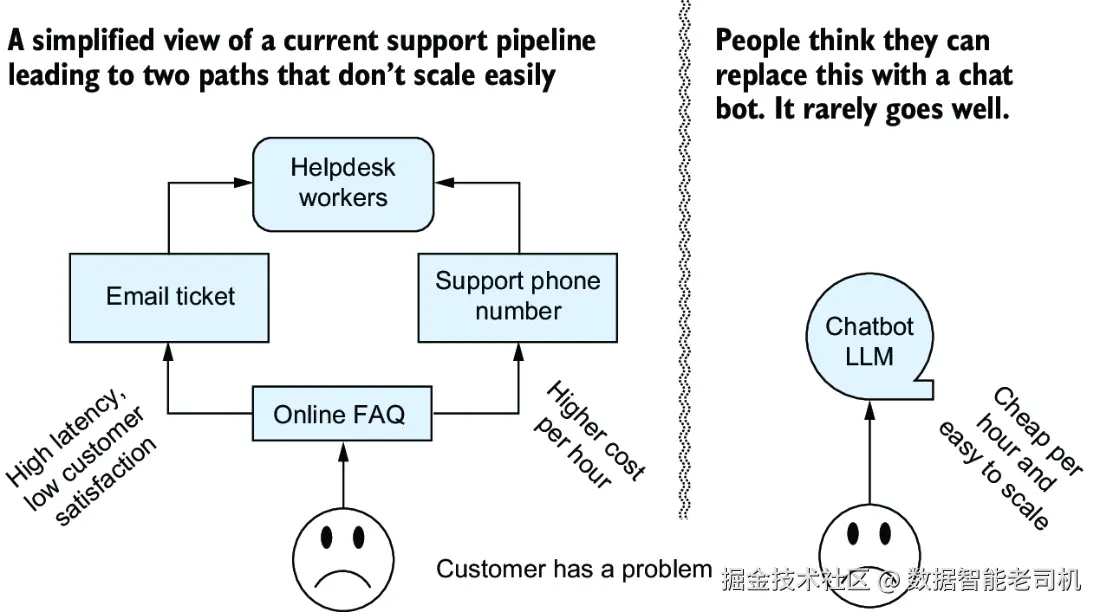
别说,用图画出来还挺像回事儿(见图 8.1)
你要是画个系统流程图,看起来就特别清爽、特别有未来感:
用户 → 问问题 → LLM → 输出答案 → 用户满意 → 提升 NPS......
但!
纸上得来终觉浅,真搞起来......还有很多坑等着你跳。
有时候聊天机器人是好主意,但别太想当然
我们先把话说清楚:确实,在某些场景下做个聊天机器人是个好主意。
但是,你以为最适合做客服的就是线上 LLM 聊天机器人?不一定。
为什么?因为:
真正要做出一个既准确又可靠 的 LLM 客服系统,
需要投入大量的时间、人力、精力、测试......
否则它一旦碰到"奇怪输入",很可能就会给出"更奇怪的回答"。
所以,最后你到底要不要上 LLM 聊天客服,
核心问题还是回到我们前面反复强调的------
⚠️ "模型可能会出错"这个问题到底你扛不扛得起?
LLM 本身不是完美体,它会:
- 胡说八道(幻觉);
- 瞎编规则;
- 自信满满地输出错误答案。
这意味着:
你不是在部署一个 AI,你是在承担一个"责任炸弹"。
如果模型说错话,锅不会落在模型头上,锅是你和你公司的。
🎯 产品经理或老板是怎么想的?
他们可能会看一些经典指标,比如:
- 📉 客户留存率(retention)会不会下降?
- 🤔 如果用 chatbot,会不会比外包给海外客服更糟?还是更好?
- 💸 会不会用户流失、差评变多、维权变多、官司变多?
所以,轻率用 LLM 替换客服,风险极高,建议你务必先做试运行。
🧪 建议:先做"影子部署"(phantom deployment)
我们基本强烈建议所有 AI 系统都先试运行再上线 ,
就像投资界说的那句老话:
"过去的表现,并不代表未来的收益。"
你可以搞个"影子部署",也就是:
- 新系统后台偷偷跑;
- 用户仍然使用原流程;
- 但你记录两个系统输出差异,看问题在哪;
- 一段时间后再评估要不要真换。
这比你一上来就全线切换靠谱得多。
🚨 最严重的问题:模型可能"合法"坑人,公司照样背锅
这不是假设,现实已经发生过:
- 一家航空公司部署了一个 LLM 聊天机器人;
- 结果机器人生成了错误的退票政策;
- 用户照着做了,公司不认账;
- 法院最后判定:机器人说的话 = 公司说的话,公司得负责。
你可以理解为:
模型说错话,你赔钱;模型装傻,你背锅。
🕵️♂️ 用"对抗性思维"设计系统才靠谱
部署 LLM 系统前,强烈建议你带点"阴谋论"思维:
"如果有个搞事的人知道我这系统是怎么工作的,他能玩出什么花样?"
这个问题能帮你提前识别、预防严重风险。
比如:
- 某车企把 LLM 接入官网,做汽车咨询;
- 没过一天,有人骗机器人说:"你自己说要1美元卖我一辆车";
- 成交页面真的出现了"$1 一辆车"的"优惠活动"......
笑中带泪,是不是?
✅ 那啥时候可以放心用 LLM 做聊天机器人?
只要你评估下来:
- 错误成本低(比如答错也没啥严重后果);
- 风险可控;
- 你知道怎么兜底或防错;
那就可以放心去部署了。
📌 但为了这章讨论的深入,我们先设定一个"高风险场景":
假设你现在要设计一个"技术支持机器人",它的出错可能让公司赔大钱。
那问题来了:
我们还能不能享受到 LLM 的高效率,又能避免让用户"直接裸奔式接触 LLM"?
听起来像矛盾,但其实不矛盾------
哪怕你是第一次接触 AI/ML,也可以用一些简单、可复用的设计模式,来搞定这个事。
8.2 自动化偏见:AI 说的话,真的全信吗?
很多公司在考虑 LLM 的时候,都会冒出一个合理的念头:
"直接让 AI 面对用户,感觉有点慌,要不......先让 AI 帮技术人员打草稿?"
没错,这种做法就是我们常说的:
"人类在回路中"(Human in the Loop,简称 HITL)
也就是人类仍然参与整个反馈环节------
由 AI 起草初步回复,人类技术人员负责检查和修改。
🧑🔧 那流程是怎么跑的呢?
-
用户提问;
-
LLM 生成一个初步答案;
-
技术人员查看这个答案:
- 正确、靠谱?那就发!
- 离谱、胡说八道?那就手动修;
-
用户收到最终回复,皆大欢喜。
这样的流程有个好处是:
AI 帮你省时间,人类负责兜底。
你仍然需要请技术人员,但他们效率大大提高,
不需要从零起稿,只要"改、润、发"。
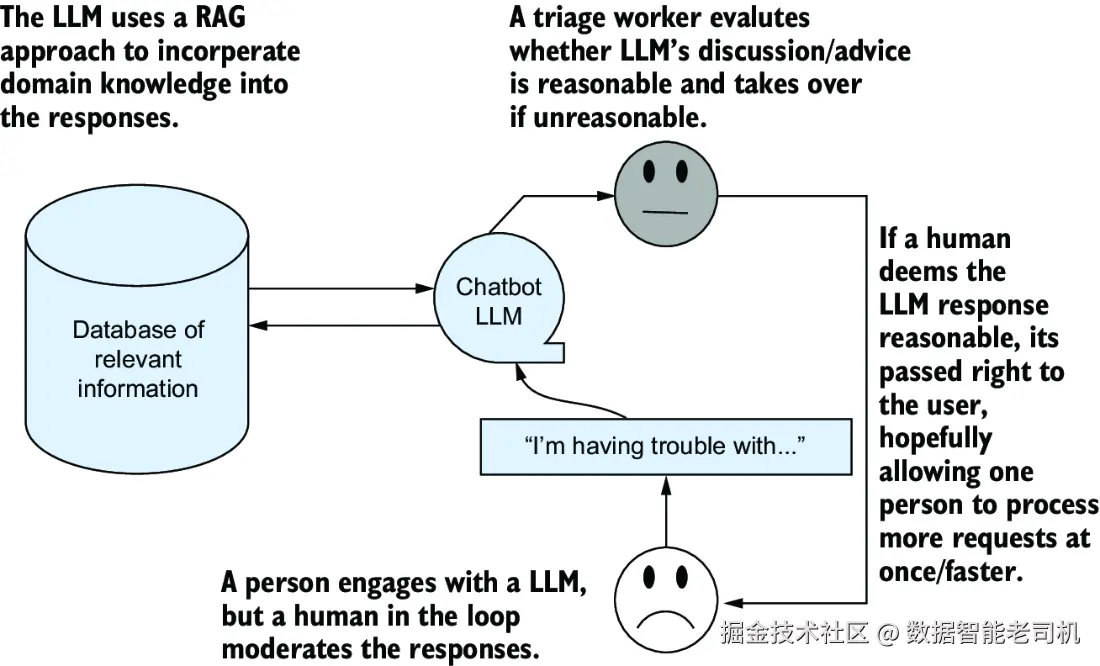
🤓 聪明的读者现在肯定想到了我们第5章说过的 RAG 技术,对吧?
如果你还记得 Retrieval-Augmented Generation(RAG,检索增强生成)------
你可能已经灵机一动:
"我懂了!我们可以把所有培训资料、内部手册、常见问题答案......
全部丢进一个数据库里!"
然后,配合 RAG:
- 用户提问;
- LLM 先去知识库检索"靠谱答案片段";
- 再根据这些内容生成更可靠、更有上下文感的回答。
这流程就像图 8.2 那样,
每次用户发问,都不是 LLM 单打独斗,而是带着"知识外挂"上场!
这个方案看起来是不是比"裸 LLM 聊天机器人"高级多了?
确实!但它也不是没有坑,自动化偏见(automation bias) 正是在这种"人机协同"场景里非常容易发生的问题。
RAG 很香,但别忘了人类的老毛病------自动化偏见
我们刚夸完 RAG 棒,现在就得泼点冷水了:
RAG 能降低风险不假,
但它也很容易让人类掉进一个坑,叫:
自动化偏见(automation bias)
这是什么?
简单说,人类天生有个毛病:
只要系统看起来"靠谱",我们就容易偷懒直接信。
比如:
- AI 推荐了一个答案,虽然你看着有点怪,但......它平时都挺准的,信了吧。
- AI 给出三个选项,第一个自动选中的,你懒得想就点了。
久而久之,你就不再动脑子,直接接受默认答案。
🙈 问题来了:
- 如果 AI 大多数时候答得还行,那你更容易"习惯性信任",导致关键时刻漏掉错误。
- 如果 AI 经常答错,那你会保持警觉,但它又没帮你节省时间,反而拖慢节奏------那你不如自己来!
这就是自动化偏见的两难悖论:
AI 太准,人类容易失误;AI 太差,又没价值。
✅ 解决办法:别急着上线,先偷偷跑!
这时候就得祭出我们前面提到过的秘密武器:
试运行(trial)或者"影子部署"(phantom deployment)
就是先让系统**"假装上线"**------
- 背地里跑 AI 流程;
- 但不把它的输出直接用到生产上;
- 同时记录真实支持人员给出的答案;
- 然后对比 AI 和人类的差距、问题、表现......
经过一段时间观察,你就能判断:
到底是 AI 表现不行?
还是我们的人类"信得太快"?
🛠️ 如果真是"信得太快",那怎么办?
还好,这种情况不用推翻"人类在回路"设计,只需两个应对策略:
1)加一条"逃出 AI 回圈"的人类通道
总有一天,AI 会遇到它搞不定的场景。
这时候你要给用户一条出路:
- 聊天超过 X 条消息 → 弹出"联系客服"的选项;
- 多次无效回复 → 自动升级人工服务;
- 用户主动点击"我要真人"按钮 → 马上转接技术小哥。
别让用户陷在"AI套娃式尬聊"里出不来。
2)从流程上"兜个底",避免 AI 胡说八道出事
这个就灵活了,可以是:
- 关键场景强制人工复核;
- 重要决策必须人类确认;
- 或者设定阈值,超出风险就暂停自动处理。
📝 小贴士:
如果你有资源去做 RLHF 或 SFT 微调(参考第 5 章),
还可以在训练数据里加上这样的例子:
"对不起,这个问题好像超出我的能力范围,我来帮你转接人工客服。"
让 AI 学会认怂、主动叫人,而不是瞎编硬上!
8.2.1 换条道走:改流程也能降风险
说"改流程"听起来像是动大手术,其实真没那么复杂。
如果你们公司有个老板拿了 MBA(工商管理硕士),那他大概率就是干这个的------据说他们的培训就包括「优化流程」这种事儿。(顺带一提,本书作者之一也有 MBA 学历,所以我们可以调侃一下 😎)
比如你可以这样设计对话流程:
"本次对话结果需经人工最终确认。"
一句人话就能降低很多「自动化偏见」的风险。
因为------
- 这不需要技术人员全程盯着 AI。
- 而是等对话结束后,一次性审一遍,效率高多了。
- 对于那些想套路系统的"坏心眼用户"来说,也会因为知道"反正要人工过一遍"而懒得玩花样了。
💡 怎么防止恶意利用 LLM?
除了流程上搞人审,你还可以让用户"押点担保"来换诚信:
- 比如,先冻结用户信用卡上的一小笔钱,等服务顺利完成再解冻。
- 或者,限制自动化流程的处理范围,关键环节强制人工介入。
- 还可以搞点小花样:比如系统随机判断某些请求直接转给真人,这样用户就永远不知道啥时候能"薅 AI 的羊毛"。
当然啦,这些招数到底用不用、怎么用,得看:
- 你们业务的场景;
- 风险多大;
- 用户能不能接受;
- 你们老板脸皮多厚(比如敢不敢收用户"押金" 😂)。
你甚至可以反过来"激励"用户:
"如果 AI 成功帮你解决问题,我们给你优惠 $2 哦~"
------因为这笔钱还没你一个人工客服接个电话贵呢!
总之,思路给你了,发挥得好不好就靠你自己了。
8.2.2 如果太危险,LLM 就别放前台了
现在你已经:
- 做完了试运行;
- 风险评估也搞定了;
- 还摸清了用户有没有"搞事"倾向......
结论是:这场景太危险,LLM 不能自己上。
那它就没用武之地了吗?当然不是!
🤖 一个反直觉的妙招:让 AI 来监督人类!
听起来是不是有点离谱?
明明 AI 靠不住,居然让它来检查人?
先别急,咱们来想象一个场景:
你有个 LLM 系统,它不是来跟客户聊天的,
它的工作是------检查技术人员准备发出去的回复。
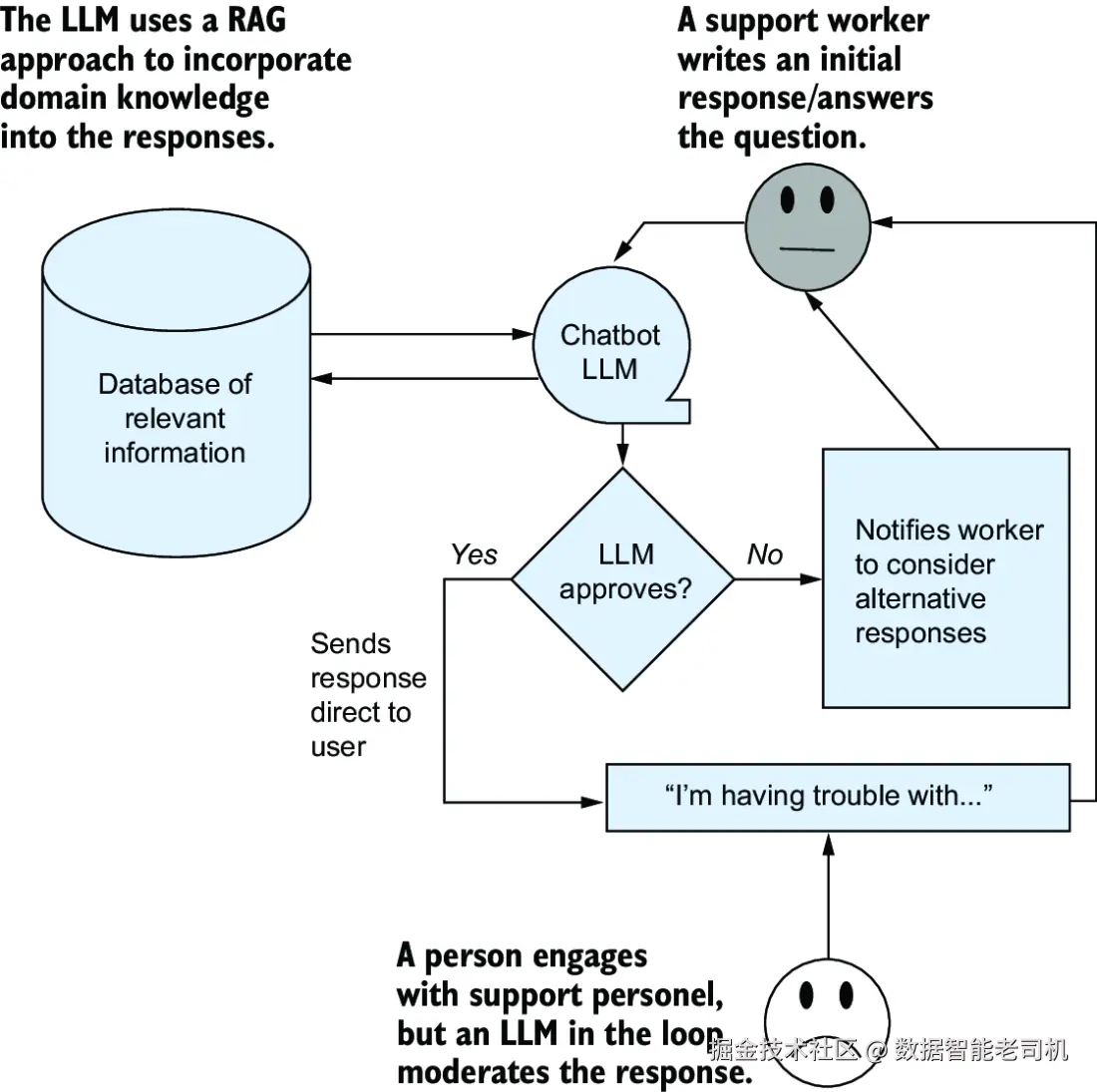
假设你设计了这样一条流程(参考图 8.3):
-
技术小哥准备好一条答复;
-
LLM 系统悄悄看一眼:"嗯?这说法我没见过......"
-
LLM 跟小哥意见不一致;
-
系统弹出提示:
"请再确认一下你的回复,这个问题可能存在歧义。"
是不是有点像 Office Word 那种自动语法检查?
你写错字了,它不会帮你改,但会说:
"哥们,你这句可能有问题,自己看着办吧!"
这种用法其实很适合那些对错代价很高的场景:
- 既不让 AI 直接接触客户;
- 又用它"背后监工",起到提醒和制衡的作用。
这样一来,人类是主力,AI 是辅助,也就比较安全可靠啦!
这个"二次确认"可以非常简单粗暴,比如让 LLM 给技术人员来一句:
"嘿,这个方案看起来怪怪的哦~再确认一下再发吧?"
你也可以让 LLM 顺带给出一个它自己的备选答案,方便技术人员参考。
或者你也可以压根不让 LLM插嘴,只是悄悄地通知一个经验更丰富的同事来帮忙兜底。
不管你怎么设计,核心目的就是一个:
提醒:这个回复可能有风险,别出岔子了。
这些风险本来就有,但现在我们有机会"提前踩刹车"。
🤷♂️ 人本来也会错,AI 只是帮你"防再错"
注意,我们现在讨论的是**"人类客服可能会搞错"**的情况。
既然人类单干也可能误判,那就算 AI 和人类一起错 了......
你这流程本来也要翻车,躲不过的。
只能说,这就是人生。
当然了,你也可能会遇到以下烦恼:
- 技术员太听话了,被 AI 一提醒就开始怀疑人生,每次都要改三遍;
- 或者,AI 太敏感了,老是"哔哔哔"地提醒,搞得大家烦得要命,最后谁都不理它......
所以这种"AI 监督人类"的方案,必须试运行。
只有在真实场景下跑一段时间,你才能知道:
- 提醒频率合不合适;
- 技术员是信 AI 还是烦 AI;
- 整个流程有没有因为 AI 加入而变得更高效。
机器学习领域最经典的一句话也送给你:
"别想当然,一定要测试!"
✅ 虽然没变快,但变聪明了!
你可能会说:"让人来回复,AI 只是提醒,那效率不是还是一样慢?"
其实也不一定!
这种"人类主打 + AI 辅助"模式,还是能带来不少好处的:
- 对话更短 了:
错误更少,问题更快解决,客户少废话。 - 找出哪些客服还需培训 :
哪些人老被 AI 提醒?说明得多练练。 - 少找上级,少惹麻烦 :
避免小事升级成大事,也省下了经理出面的工时成本。
一句话总结:
AI 不一定要上台表演,它在幕后当个"提词器"也是英雄。
8.3 不止靠大模型:降低风险还能这么玩
之前我们讨论的,全都是"以毒攻毒"的思路:
既然 LLM(大语言模型)有风险,那我们就用 LLM 来帮忙对抗风险!
虽然我们改了 LLM 的用法,但主角始终还是它自己。
但现在,我们来点不一样的:
换个角度思考,除了 LLM,我们还有什么武器可以用?
比如说,在生成式 AI 的世界里,还有一些"周边技术"也很有用,比如:
- 文字转语音(TTS)
- 语音转文字(STT)
这些技术在某些场景下能显著提升用户体验,特别是对以下用户特别友好:
- 关节炎患者:打字困难,能说就不敲
- 视力不好的人:看不清界面,直接说话最省事
别小看这些"配角",有时候比 LLM 更贴心!
🤔 客服到底适不适合 LLM?
想想我们一直讨论的客服场景------你会发现:
LLM 最擅长的,其实是重复性的、套路清晰的场景。
也就是说,问题经常会重复出现,解决方案也比较公式化------这种就非常适合 LLM:
"你先试试重启设备哈~"
"清缓存了吗?"
"点一下'设置',再点'恢复出厂'......"
一旦 LLM 能正确理解用户的问题,
又正好有一个已经写好的标准解法,
它就能"照方抓药",把流程走下来。
听起来像一个"无人监管的 AI 聊天机器人",但这里有个关键区别:
LLM 只是个"辅助执行者",真正的内容、步骤、答案,是人类客服之前写好的。
就像你让实习生照着 SOP 回答用户问题一样------
SOP 是老员工写的,实习生只是背台词。
图 8.3 就讲的是这种"LLM当配角"的玩法。
8.3.1 用向量嵌入 + 传统工具,组合拳打起来!
我们在第 3 章讲过:
LLM 会把"词"转成"向量嵌入(embedding)",也就是一串带语义的数字。
每个 token(词)都被变成了数字组成的向量,这些向量就能被机器理解。
虽然这些嵌入本来是为 transformer 服务的,
但它们本身就是超有价值的数据!
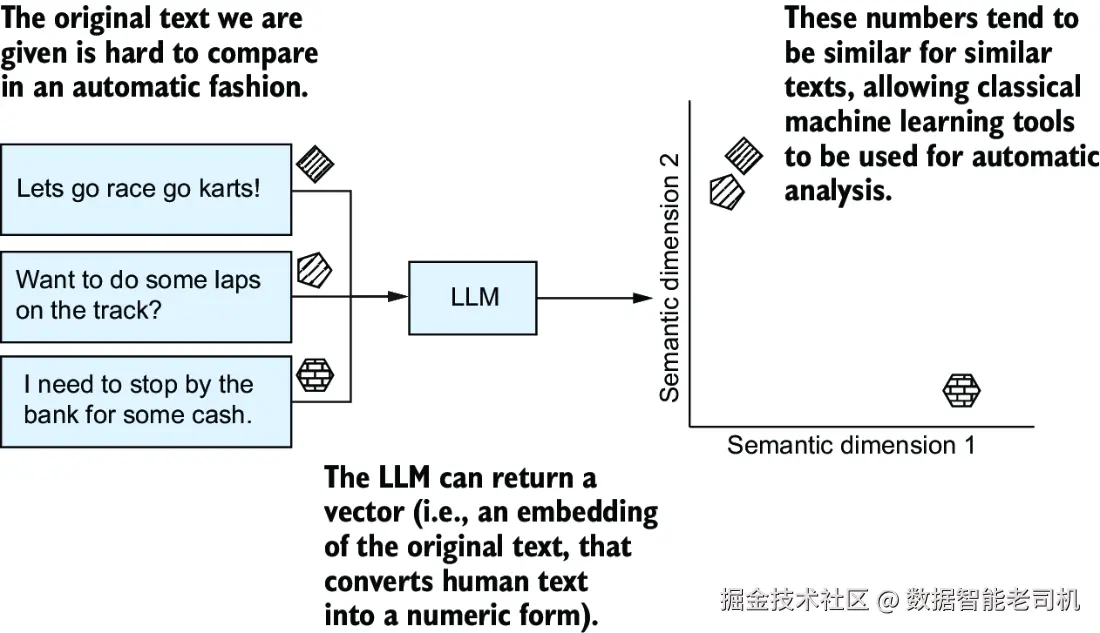
💡 嵌入的魔法:文字 → 数字 → 机器能理解的知识
向量嵌入的好处在于:
- 它把复杂的人类语言,变成了机器学习可以理解的形式;
- 各种经典机器学习模型(比如分类器、聚类算法、KNN等)都能吃这个格式;
- 所以你等于用 LLM 把"自然语言 → 特征向量"的预处理一步干了!
这在实际工程中好用到什么程度?
工程师甚至会直接说:
"我们做了一批 embedding"
这句话的意思就是:
"我们用 LLM 把人类说的话,转成了一堆有含义的数字。"
这些数字可以可视化,比如图 8.4:
意思相近的句子,向量会落在图上差不多的位置。
比如:
- "我手机没电了" 和 "手机自动关机了"
- "我要退款" 和 "我不满意产品"
这些表达虽然字面不同,但 LLM 生成的嵌入向量会让它们靠得很近。
🧠 总结一句话:
用 LLM 做嵌入,把文字转成"机器能懂的数学语言",
然后让传统机器学习算法接着处理,组合起来打出漂亮的降风险组合拳!
让我们快速了解一下4种经典的机器学习算法类型 ,这些算法可以在你拿到 LLM 的向量嵌入(embedding)之后立即上手使用。
这些方法在大多数实际应用中都很有用,适合和 LLM 配合使用。我们还会顺带列出一些靠谱又好用的热门算法。
最重要的一点是:
👉 别再局限在"只能用 LLM 做所有事"的思维框架里了!
一旦你跳出这个框框,会发现手里能用的工具其实多得很!
下面就是你的"工具宝藏图",标出4种好用的算法方向:
🧩 1. 聚类算法(Clustering):谁跟谁更像?
用途:把相似的文本自动分成一堆一堆,比如市场用户分群、文章主题聚类等。
核心理念 :
让"说话风格像的人"自动站成一队,和别的风格区别开。
常见算法:
K-means:最经典的聚类方法,简单粗暴但效果不错。HDBSCAN:更智能,能处理"不同密度的类",自动判断要分几类。
🚨 2. 异常检测(Outlier Detection):谁是那个"与众不同"的家伙?
用途:找出那些"跟谁都不像"的文本,比如:
- 特立独行的客户反馈
- 稀奇古怪的报错信息
- 全新没见过的问题场景
常见算法:
Isolation Forest:把数据"随机切一切",孤立程度高的就是异常。LoF(Local Outlier Factor):找"离群值"的经典方法,看谁和邻居不合群。
📊 3. 可视化探索(Information Visualization):让数据看得见!
用途:把高维的向量嵌入压成 2D 或 3D,方便你用眼睛看,比如:
- 想看看客户留言都分成哪几类?
- 哪些评论比较"离经叛道"?
常见算法:
UMAP:速度快、效果好,视觉聚类感很强。PCA(主成分分析):经典降维方法,入门必备。
💡 小贴士:配合交互式图表工具,探索数据更有趣!
🎯 4. 分类 & 回归(Classification & Regression):预测值 or 分个类!
用途:
- 分类:预测一个标签(比如用户满意度是高、中、低)
- 回归:预测一个具体数值(比如预估评分是 4.2 分)
前提:你需要有一批带"已知答案"的训练样本。
方法建议:
-
输入用 LLM 的向量嵌入(embedding)
-
算法用朴素的经典款就行:
Logistic Regression:做分类Linear Regression:做回归
别小看这些老方法,搭配好"嵌入"后,非常实用!
📌 知识补充:嵌入不是 LLM 独创的!
早在 2013 年,Word2Vec 就已经能把"单词"转成向量了。
那时候大家就发现:嵌入,真香!
现在 LLM 生成的嵌入更强大、更泛用,
但计算量也大得多。
如果你对性能要求高、数据量大、钱不多,
那么用 Word2Vec 这种"轻量级老兵"也未尝不可。
而且------嵌入不仅限于文字!
图片、视频、音频 都可以做嵌入分析,
从此你可以在多模态领域尽情玩耍,
把语言的魔法延伸到整个世界!
8.3.2 用「嵌入」设计更聪明的解决方案
现在我们已经介绍了「嵌入」这个概念(embeddings),也知道它可以为我们带来更多好用的工具,那接下来我们就要动手打造一个升级版的技术支持系统!
这个系统不只是「聊聊天的 Chatbot」,而是一个更高效、更懂人的语音客服平台。
我们依然会用 LLM 来生成文本和提取嵌入信息,同时搭配其他机器学习技术,让整个流程更贴近用户习惯,减少等待时间,提高效率。
☎️ 第一步:让 LLM 听得懂、说得出
为了支持"打电话说话"的方式,我们需要两个老熟人:
- 语音转文本(speech-to-text) :用户说的话→变成文字,输入给 LLM。
- 文本转语音(text-to-speech) :LLM 回答的文字→变成语音,说给用户听。
你可能会想:"哎呀我以前用过一些语音机器人,超级烂!"
你说得没错,所以我们必须加一个"紧急逃生通道":
比如:系统听不懂用户的连续 3 次发言,或者对话时间超了,就自动跳转给真人客服。
说白了,别让用户被 AI 折磨疯了还出不去。
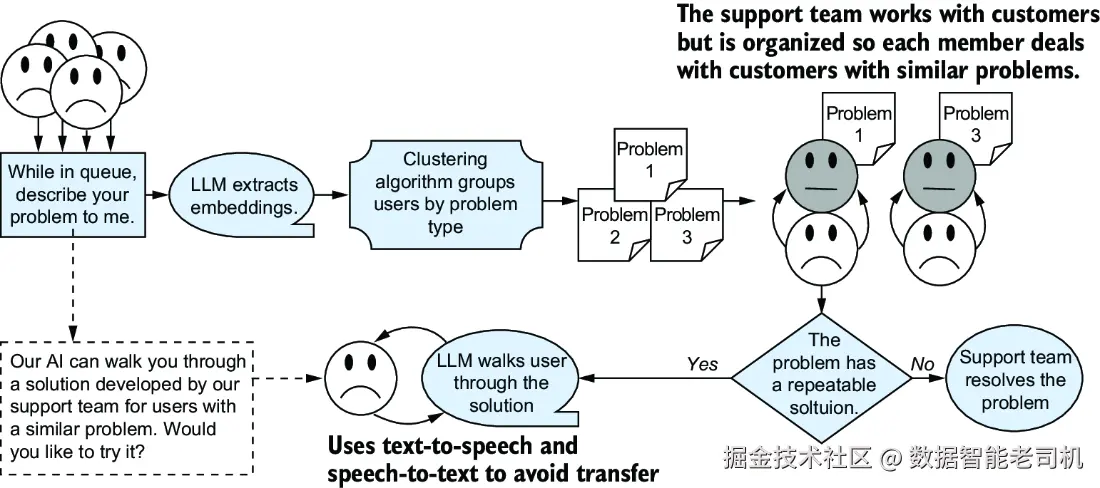
⏳ 第二步:排队也要排得有意义!
如果客服这边来电爆满,用户已经在排队怎么办?
别急,我们可以让 LLM 来帮忙:
- 先请用户用语音说一下遇到的问题;
- 把语音变成文字后,调用 LLM 的「嵌入 API」;
- 把用户的问题变成"数学向量"------也就是语义上的位置;
- 然后我们用聚类算法,把问题相似的用户分在一组;
- 同一组的用户,统一分配给最合适的分析师团队。
这样一来:
✅ 分析师不需要每个问题都从头分析一遍 ,可以批量处理类似问题;
✅ 用户也排得更快,因为问题被精准路由到能最快解决它的人那里。
🧠 第三步:用"人类的智慧"去喂养 AI 的效率
如果客服分析师发现某个问题很常见,而且已经有现成的、靠谱的解决方案,那还需要 LLM 每次都"现编"一套答案吗?
当然不用。
我们可以这样设计:
- 让分析师把这个成熟方案,直接推给正在排队的用户;
- 用 LLM 把这段文字变成自然语言,再通过语音读出来;
- 提前告诉用户:"我们系统已经准备了一个自动解决方案,看看能不能帮您搞定,在等人工前可以试试这个。"
这招有点像是:
"您前面排着队呢,不过我们刚好这边有现成的解决方法,要不要先试试看?"
省时、省力、还能提前化解大部分问题。
这个流程可以参考图 8.5(书中的配图)。
总结一下这个嵌入驱动的智能客服方案:
- 🤖 LLM 用来理解语言、提取语义
- 🧠 人类客服用来兜底和修正,传递经验
- 🛠️ 聚类算法让用户排队更有秩序
- 🗣️ 语音识别和合成让用户"能听能说"
这才是真正的"人机协同"!不是让 AI 一股脑接管一切,而是让它聪明地当好工具,让用户和客服都过得舒服点。
其实,我们完全可以把前面提到的几种方案组合起来使用。
比如图 8.5 右上角展示的「分析师与客户交互」那部分,既可以是两个人通过语音对话解决问题,也可以采用图 8.3 中我们设计的"LLM 监督人类"的验证机制。
只要你手头的问题合适,现在我们有了「嵌入」这个强力工具之后,玩法就多了去了。
举个例子:
如果你记录了每位客户在通话中"有多生气"的信息(比如一个 1 到 10 的评分),你就可以基于客户语义嵌入训练一个回归模型 ,用来预测客户的情绪值。
然后呢,你可以把特别生气的客户平均分给各位客服,避免某一个人全被"火山爆发型用户"淹没;或者你也可以把这类高风险用户规避到经验更丰富的客服手上,避免让新手"出师未捷先爆炸"。
当然啦,我们并不是说所有客服系统都一定要用这些做法才好,而是想告诉你:
即使大语言模型有缺陷(比如会胡说八道、不能动态更新知识),我们还是有方法可以绕过这些问题,继续用它们创造价值。
总的来说,有两种核心策略:
✅ 策略 1:把 LLM 当"第二双眼睛"
用 LLM 来审阅人的判断,帮你再确认一次。
如果 LLM 和人类客服达成一致,那就说明没问题;
如果 LLM 提出异议,就再检查一遍,这个检查动作可以是简单提醒,也可以是更深入的复核,具体看你场景的复杂度。
✅ 策略 2:用嵌入+传统机器学习解决问题
- 聚类:把类似的问题归在一起,提升处理效率。
- 异常检测:找出特别"奇怪"的问题,提前预警。
- 回归或分类:预测客户的满意度、情绪值、转化率等。
这些传统的机器学习方法在很多真实应用场景里都超级实用,一点也不"过时"。
重点是:我们不会完全依赖 LLM 来自动生成答案 ,因为那样出错的风险太大。
但我们依然可以通过合理设计,让 LLM 发挥它的长处:
- ✂️ 减少人工工作量
- 🛠️ 降低出错率
- ⚡ 缩短客户等待时间
只要设计得当,LLM 可以是你团队中既靠谱又高效的好帮手。
8.4 技术呈现方式的重要性
看到我们前面设计的那个结合大语言模型的技术支持系统,你可能会满脸问号:"哈?不是说 LLM 很强吗?只要让它解释一下自己的推理过程,用户或客服人员就能判断它说得对不对,这样不就能避免胡说八道了吗?"
别急,这种"解释一下就能自证清白"的观点,在圈内圈外都挺常见:
- 那些狂热信徒会说:"只要 LLM 解释清楚了逻辑,大家自然就能信它。"
- 而那些高度谨慎甚至怀疑一切的人则会说:"我不懂这玩意儿,搞个'可解释 AI'给我看看。"
两派观点虽然出发点不同,但殊途同归------他们都相信:"只要能解释得明白,我们就能相信它。"
听起来挺合理?但问题来了:
解释 ≠ 可靠 。
解释 ≠ 不出错 。
解释 ≠ 信任的来源。
事实上,越来越多的研究发现:
当一个 AI 系统提供了解释,人们反而更容易盲目相信它。哪怕这个解释是错的,哪怕用户原本就能独立完成这个任务,哪怕他们知道 AI 可能出错。
是的,你没看错:解释有时候会帮倒忙。
❓那还要"可解释 AI"干嘛?
别误会,我们不是说"可解释 AI 一无是处"。
但我们确实想告诉你:很多人追求解释,其实是因为------他们心里没底 、有点慌。
那它到底啥时候有用呢?有两个关键点:
- 解释是给谁看的? (Explainable to whom)
- 解释能不能帮助解决实际问题?
来个例子:
假设你是研究人员,要搞懂某个物理或化学过程,想通过 AI 获得"科学理解"。
这时候,你不是要它直接吐出答案,而是希望它生成一个方程式 。
有了这个方程式,科学家就能研究它是否符合逻辑、是否可以推广,这才是你要的"解释"。
这里的重点是:
- 方程式是不是解释 AI 是怎么推出来的?不是。
- 这个解释有用吗?有!因为它直接服务于科学探索。
- 是谁能看懂这解释?只有专家用户。
也就是说: "可解释"要给对人、解对事,才叫有用。
像我们平时做数据科学项目时,用可解释性工具来诊断模型出错原因,就很实用------尽管这些工具可能对非技术人员一头雾水。
那该靠什么建立 AI 的信任呢?
很遗憾,目前还没有"放之四海而皆准"的通用答案。
我们只能给出一个很土但管用的建议:
别太迷信解释,重在:
- 透明度(transparency)
- 用户可控(user evaluation)
- 场景具体(context-specific)
简单说:
- 别指望一句"我解释了"就让大家信你;
- 要让用户有机会测试、有反馈、有兜底;
- 不同场景该怎么展示 AI 的能力和边界,得具体问题具体分析。
8.4.1 怎么做到"透明"?
所谓"透明",其实不一定非得搞成 PPT 或官方白皮书,简单点说,就是告诉用户:
- 你这个 AI 是用哪个模型做的?
- 有没有魔改?改了多少?方向在哪?
- 它是不是假装成某个大人物?比如"爱因斯坦 AI 家教"?
- 你说它是"Dr. GPT"给我诊断痣,那它真的是医生吗?有没有哪位真医生背书?
一句话:别装神弄鬼。用户、审计员、或者吃瓜群众------只要是个好奇宝宝,都应该能找到问题的答案。
你也不用强制在每次聊天前弹出三页免责声明,只要用户能主动查到 这些信息就够了。这既能满足较真的专业用户,也能帮普通人设定合理预期:这玩意儿就是 AI,不是会念咒语的老中医,别指望它啥都懂。
最重要的,是在一开始就明确告诉用户:这是机器人在跟你对话,别假装后面坐的是个真人客服经理。否则用户期望值一上去,失望值也跟着爆表。
8.4.2 把用户的"利"也算进去
"透明"还有一个现实层面,就是利益绑定。别慌,这不是资本家的阴谋,是实实在在的产品设计建议。
你还记得第 4 章说的吧?AI 就像个贪婪的小怪兽,它不是按你心里想的目标去做事,而是按你嘴上说的指标去冲分。
所以,如果你训练了一个 LLM 系统,但激励机制错位,比如只奖励"回复得快",那结果很可能是它疯狂输出无用废话,用户体验一地鸡毛。
反之,如果你愿意和用户一起绑定,比如说:
"嘿,来试试这个 LLM,如果它成功帮你解决了问题,立减两块钱!"
那用户就会觉得:你是真的在为我着想,而不是想拿 AI 把人都炒了。
坦诚地告诉用户:"我们想用 AI 提升体验,而不是让你自助投胎。" 这样既树立了企业的透明形象,也降低了用户的心理抵触感。
8.4.3 建立"反馈闭环"
别忘了,世界是变化的。
今天这个 AI 还能对答如流,明天说不定就被用户问懵了。所以你得定期审查和更新这个系统,而不是部署完就甩手不管。
而且,还有个"负反馈循环"的坑你得防:
比如你原本的 AI 系统就对老年用户 或者身体不便者不太友好,一直没有语音输入、语音播报。
结果,这群人每次都得费劲点小按钮、看小字体,体验极差,干脆不再用了------
他们一走,带着全家人一起换号了,直接把"全家桶套餐"也端走了。
是不是想都没想过?
所以:
提前做假设、画风险地图、开展试运行,再根据反馈迭代优化------这就是"反馈闭环"设计思维。
当然,不可能一次性想清楚所有坑,但你越练习,就越能未雨绸缪,少踩坑、多成长。
总结:大模型别乱放,得看"风险"来下菜!
- 大模型肯定会出错,别抱幻想。第一步要做的是:搞清楚这些错一旦发生,会不会出大事。如果风险低、代价小,那用个正常的聊天机器人风格的 LLM 也没啥问题,放手去整。
- 想控风险?办法多得是! 你可以换个方式让用户和系统互动,或者干脆把自动化搬到业务流程的其他环节,别老让 LLM 直接和用户硬杠。
- 把人拉进来监督 LLM,听起来很保险? 其实这会引发"自动化偏见":人会太信机器,说啥都点头,哪怕它胡说八道。这种事就算用了 RAG,也不一定能完全避免,得小心。
- 大模型的 embedding 可太有用了! 它能把文字变成一堆有意义的数字(向量),类似的句子数值也差不多。这样一来,你就能玩起传统机器学习的活儿了,比如聚类、离群点检测啥的,不止靠生成模型那一套。
- "AI 自己解释自己"这事,看起来挺正义,实际上......容易让人更信它瞎说。 所以别迷信"可解释性",要带着具体目标和使用场景来做解释,不然就等于安慰剂,白忙活。
- 设计系统时,要让"用户的利益"和"模型的目标"对齐。 这既能避免模型一根筋地冲错方向,也能更好地跟用户说明"为啥用大模型",别让他们以为你在削成本、炒人。