本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
最近后台收到很多工程行业粉丝的提问:"明明上传了全套施工规范和项目资料,AI却连'A2标段混凝土强度标准'这种基础问题都答不准""查个工程量清单,翻遍知识库都找不到对应数据"。其实问题根本不在AI本身,而在"喂"给模型的姿势------
默认参数撑不起工程文档的复杂需求,精细化参数配置才是关键。
今天这篇教程,就针对我们工程人常用的场景,把RAGFlow(一款开源RAG引擎)的核心参数拆解得明明白白。从分块、知识图谱到召回增强,每个环节都附"直接抄作业"的配置表和实操截图,帮你把AI助理打造成真正的"工程知识库管家"。
一、先搞懂原理:RAGFlow是怎么"读懂"工程文档的?
在调参前,得先明白RAGFlow的工作逻辑------它就像一个"智能资料员",处理文档分三步,每一步的参数都直接影响最终效果。结合工程场景简化如下:
1文档解析(Parsing):把PDF规范、Excel清单、Word报告等不同格式的文件"翻译"成AI能识别的文本,重点解决表格、扫描件的识别问题;
2文本分块(Chunking):把长文档切成合适的"知识卡片",比如将500页的《混凝土结构规范》切成几百个小片段,既保留条款完整性又方便检索;
3索引与召回(Indexing & Retrieval):给"知识卡片"建索引,当你提问时快速找出相关内容,知识图谱和RAPTOR就是提升召回质量的"黑科技"。
| 核心认知:参数调整的本质,就是让每个环节适配工程文档的特点------比如规范的章节结构、清单的表格关联、报告的项目关系。 |
二、文档预处理与格式适配:决定质量的核心前置步骤
文档质量是知识库效果的"命脉",却往往被多数人忽视------若原始文档格式混乱、命名无效,后续再精细的参数调整也难以挽回效果。分块前,这两步预处理必须扎实落地:
1格式统一:DOC/DOCX转PDF必做:实操中发现,直接上传DOC/DOCX文档易出现预览失败、格式错乱问题,而PDF格式能100%保障预览正常,且原文引用时可精准定位内容。转换方式:用WPS或Office"另存为"选择PDF格式,务必勾选"保留排版"选项,避免表格、公式变形。
2AI辅助预处理:重命名+补源数据:借助Claude Code或AI工程文档归档工具完成两项关键操作:①重命名:按"项目名称-文档类型-关键信息"规范命名(如"A2标段-检测报告-C30混凝土202510"),摒弃"新建文档1.docx"等无效命名;②补源数据:补充文档摘要、项目编号、创建时间等信息,从源头提升检索匹配精度。
3Excel专项清理:去冗规整防解析失败:工程类Excel常含冗余信息,直接上传易因数据量过载导致解析崩溃(即"删爆"),需提前清理:①删无用信息:删除空白列、测试数据列、重复备份行等无效内容;②清冗余标题:保留唯一表头行,删除表头上方的说明性文字行、拆分的子标题行;③格式规整:选中数据区域执行"单元格格式对齐"(建议左对齐文本、右对齐数值),通过"查找和替换"批量删除多余空格,避免解析时出现乱码或错位。
三、核心参数:智能分块(Chunking)------决定检索精度的基石
分块是RAG的"地基":块太大,AI找不到具体条款;块太小,会割裂"施工步骤+质量标准"的关联关系。工程文档类型多,必须"量体裁衣"。
- 分块模板:工程人必用的6种模板适配指南
RAGFlow预设了多种模板,不用自己写规则,选对模板就成功了一半。结合动态操作图(图2),我们逐个说清工程场景的用法:

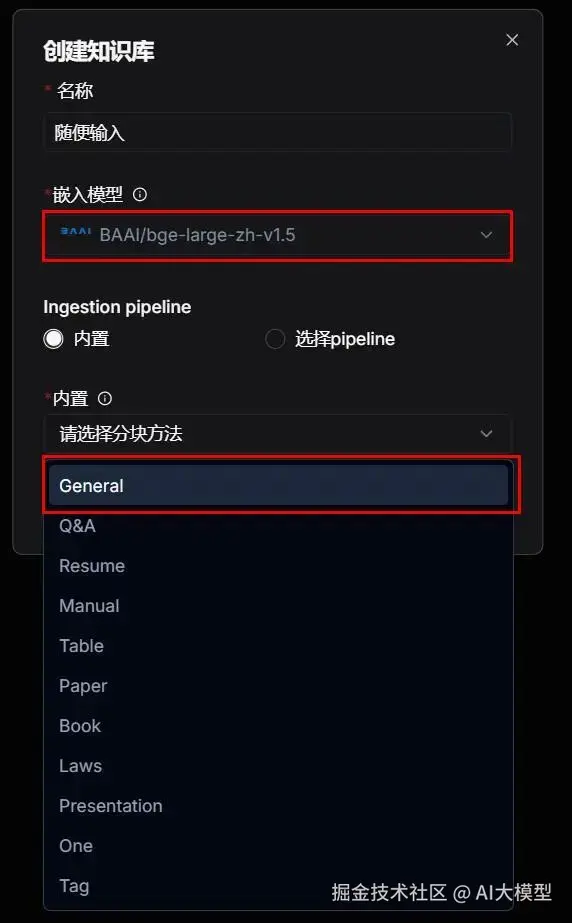
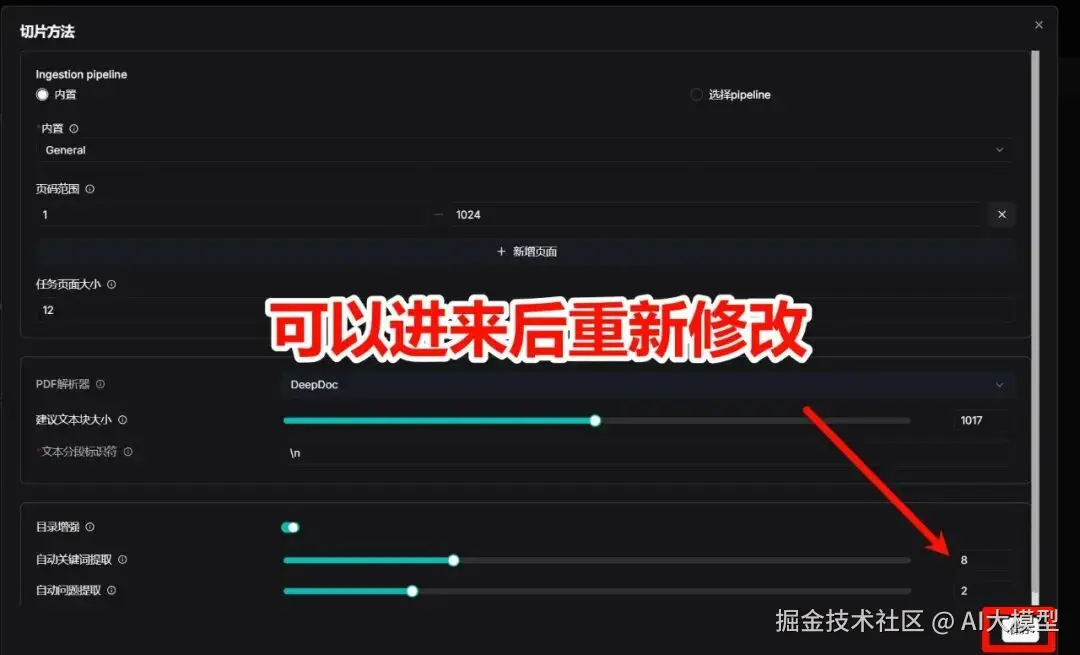
| 这里的Ingestion pipeline 是指如何给你的文档分块,选择:"内置",一般都选择General,(后续可以修改) 而"选择pipeline",就需要你自己提前搭设好智能体,根据自己的智能体给文档分块,这里属于高阶玩法,后续我探索了再告诉大家。 |
| 模板类型 | 核心优势 | 工程适配场景 | 避坑要点 |
| General(通用) | 适配多格式,解析速度快 | 施工日志、会议纪要、变更通知单等无固定结构文档(建议一开始都选这个,后期再根据文档切块效果再调整) | 纯表格文件不适用,会拆分表格结构 |
| Book(书籍) | 保留章节层级,上下文连贯 | 《建筑施工规范》《技术手册》等长文档 | 需确保文档有清晰的"章-节-条"标题格式 |
| Laws(法律) | 按条款编号拆分,定位精准 | 国家/行业法规、地方建设标准(如GB 50010-2010) | 条款编号不规范时,改用Book模板 |
| Table(表格) | 保留行列关联,数据提取完整 | 工程量清单、检测报表、材料台账等Excel/CSV文件 | 上传前建议将Excel转为CSV格式,避免公式丢失 |
| Q&A(问答) | 自动识别问答对,响应快速 | 投标答疑、安全交底FAQ、质量问题问答集 | 需按"问题+答案"格式排版,否则识别错乱 |
| Presentation(PPT) | 按幻灯片分页,保留图文关联 | 项目汇报PPT、技术交底幻灯片 | 图片较多时需开启OCR,否则仅识别文字 |
- 关键参数:工程场景量化配置表
选好模板后,需调整两个核心参数。结合51CTO实测数据和工程文档特点,直接给出行之有效的配置:
| 参数名称 | 作用解释 | 工程场景推荐值 | 调整原则 |
| chunk_size(块大小) | 每个"知识卡片"的token数量(1汉字≈2token) | General/Table:500-1000token;Book/Laws:1500-2000token | 长文档(规范)取大值保连贯,短文档(日志)取小值提精度 |
| chunk_overlap(重叠率) | 相邻块的重复内容比例,避免割裂关键信息 | Book/Laws:20%-25%;其他模板:10%-15% | 条款类文档重叠率高些(防条款拆分),表格类低些(防数据重复) |
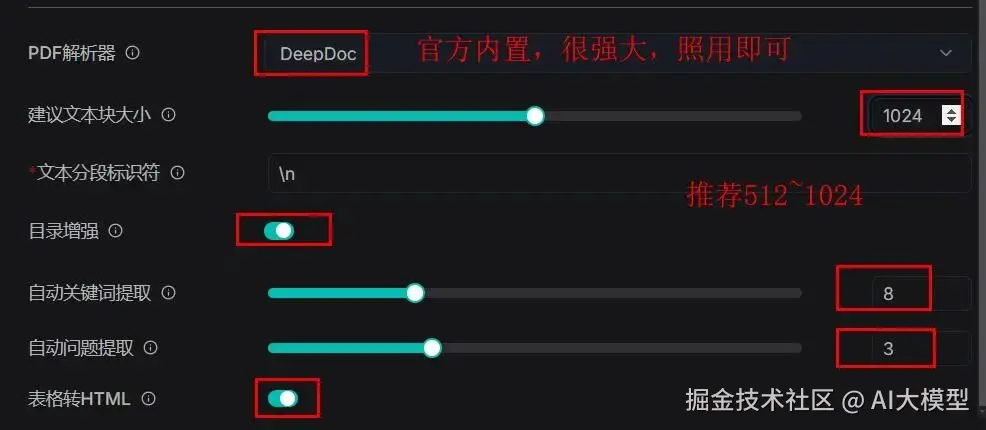
如果你的块设置太小了,文本的意思会被打断,不利于后续的检索。但如果你的块设置太大了,会增加检索时间以及存在噪声。
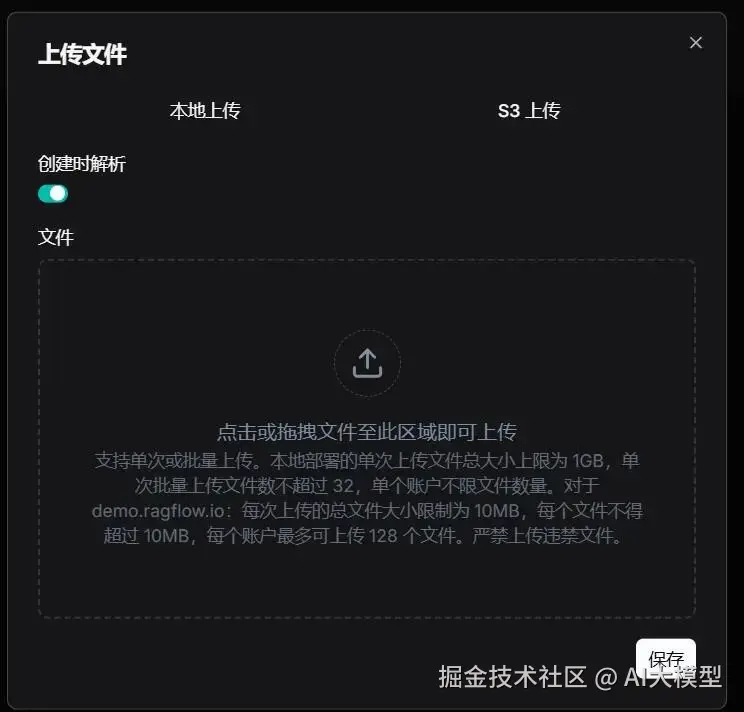
我喜欢把"创建时解析"打开,上传完文档就自动解析分块、弄关键词、给块提问题等。
等完成后我再看合不合适,再作调整。
| 参数联动提醒:Qwen3-embedding(推荐嵌入模型)支持1500token以上大块长,若用该模型,Book模板可将chunk_size调至2000token,上下文连贯率提升15%。 |
- 人工干预:工程文档分块的"最后防线"
自动分块难免有误差,尤其是复杂的工程文档,手动调整能大幅提升效果。操作步骤如下(对应图2红框标注):
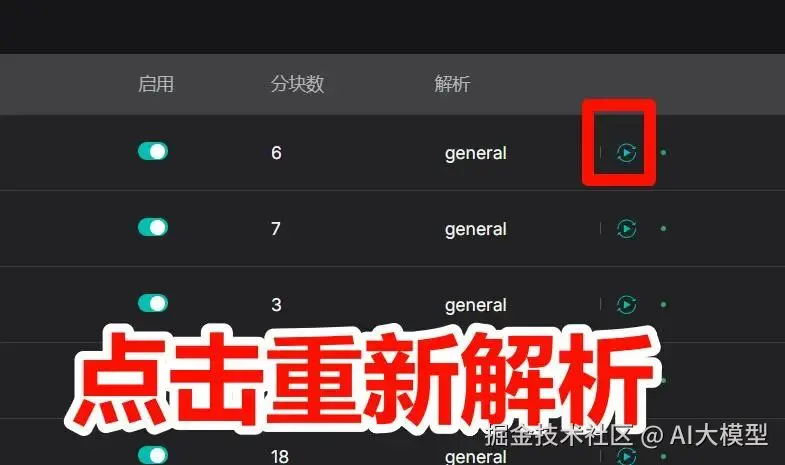
1上传文档后,点击"分块预览",查看自动拆分的结果;
2遇到问题:智能重新再次分块或选择不同的分块方式。
3特殊处理:表格分块后若行列错乱,删除后重新选择Table模板上传;
4保存生效:调整完成后点击"确认分块",生成最终"知识卡片"。
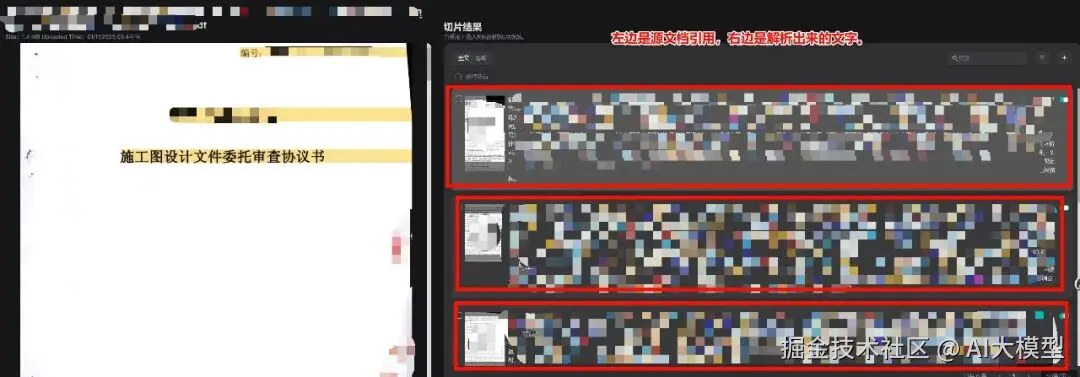
自己查看分块结果如何,也可以自己点击进去进行修改
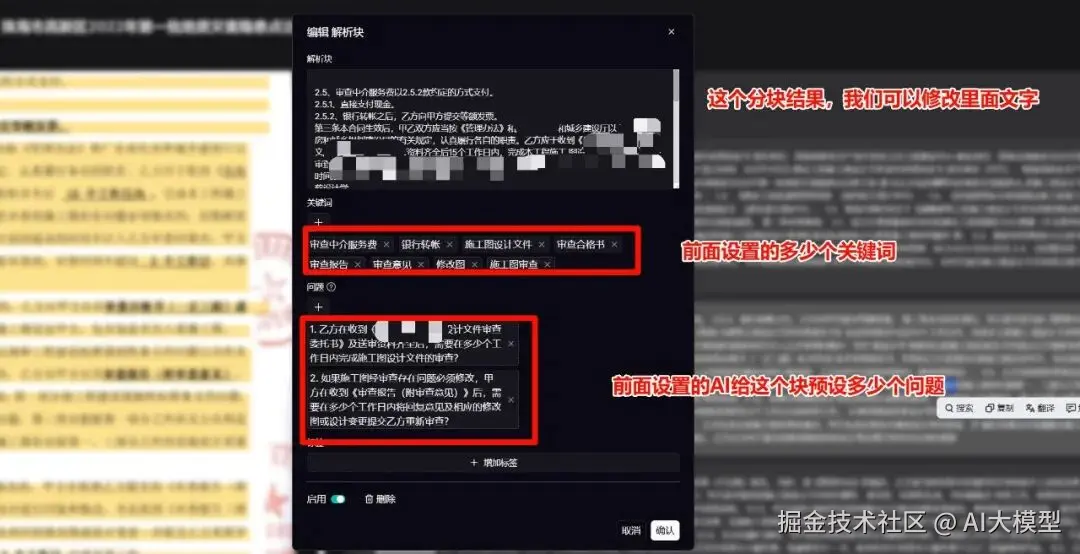
如果你觉得这个分块效果不佳,可以重新选择分块方式,如下:
四、进阶功能:知识图谱------处理工程复杂关系的神器【消耗时间和TOKEN很多】
工程文档里全是"关系网":施工单位-项目经理-标段-检测数据,普通分块只能找到零散信息,知识图谱却能把这些关系串联起来,实现"多跳推理"。
- 核心区别:分块vs知识图谱(工程场景举例)
比如提问"负责A2标段的施工单位,其总工程师是谁?":
1普通分块:返回包含"A2标段""施工单位""总工程师"的多个文本块,需要你手动筛选整合;
1知识图谱:直接输出"XX建设集团(施工单位)→ 王五(总工程师),负责A2标段",自动完成关系关联。
- 工程人必开场景:这3类文档一定要用
| 适用场景 | 文档类型 | 核心价值 |
| 项目管理 | 项目立项报告、参建单位名单、负责人任命书 | 快速定位"单位-人员-标段"关联关系 |
| 质量追溯 | 检测报告、不合格项整改单、材料验收记录 | 关联"材料批次-检测结果-整改责任人" |
| 招投标管理 | 投标文件、资质证明、中标通知书 | 提取"投标单位-资质等级-项目经理资质"关系 |

- 实操配置:3步开启+工程专属实体模板
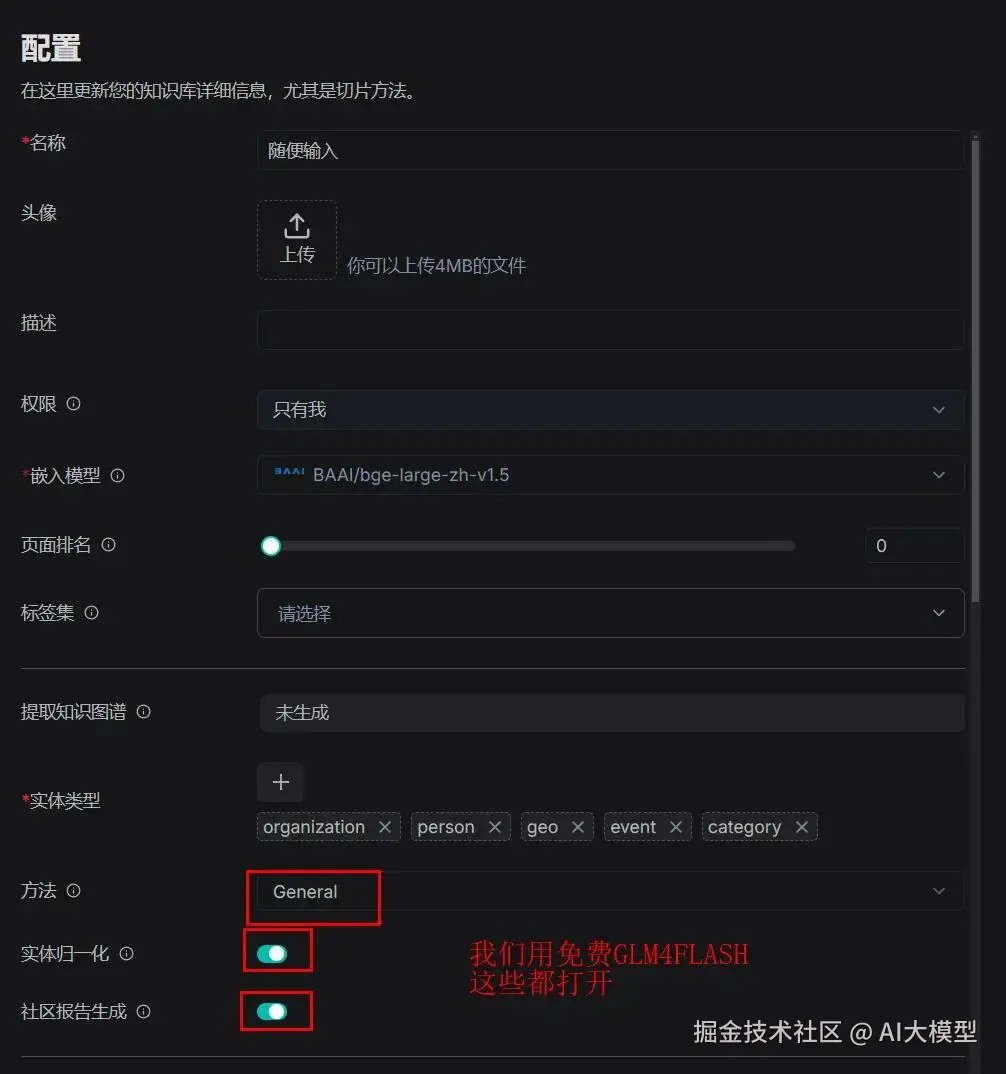
知识图谱看似复杂,实则按步骤操作即可,关键是定义好工程专属"实体"(即需要提取的关键信息类型)。
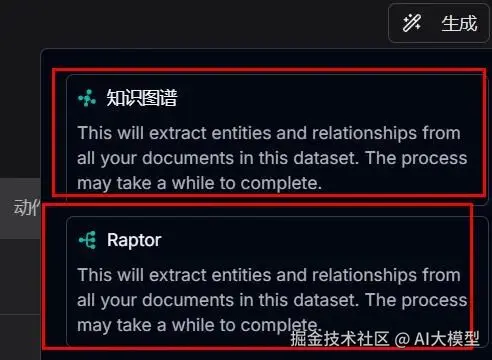
1开启功能:进入数据集配置页→"高级设置"→找到"知识图谱构建"开关并打开(图4红框位置);
1定义实体:点击"实体模板"→选择"自定义",导入工程专属实体模板(直接复制下表内容);
1选择模式:根据需求选择General(精准)或Light(快速)模式,点击"保存配置"。
图片下载失败
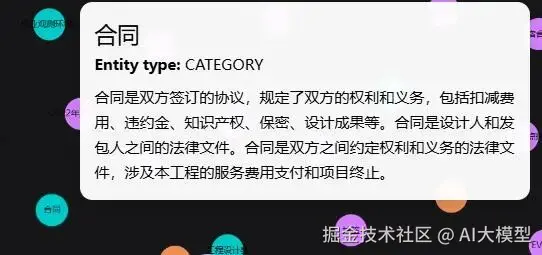
工程行业实体定义模板(直接复用):
| 实体类型 | 提取关键词示例 | 优先级 |
| 施工单位 | 建设集团、建筑工程局、施工总包、承建方 | 高 |
| 标段 | 标段、工区、分区、施工段(如A1标段) | 高 |
| 责任人 | 项目经理、总工程师、监理、检测员 | 高 |
| 检测指标 | 强度、含水率、垂直度、合格率、C30 | 中 |
| 材料信息 | 钢筋型号、水泥标号、混凝土强度、批次号 | 中 |
- 模式选择:General vs Light(实测数据参考)
针对100页工程文档的实测对比,帮你快速决策:
| 模式类型 | 实体提取数量 | 解析耗时 | Token消耗 | 适用场景 |
| General(通用) | 128组(完整) | 12分钟 | 8.2万 | 正式项目库,需精准关系提取 |
| Light(轻量) | 91组(核心) | 5分钟 | 4.1万 | 测试场景,快速验证效果 |
五、性能飞跃:召回增强(RAPTOR)------超长文档的救星
处理几百页的标书、全套规范时,普通召回会"只见树木不见森林",RAPTOR通过构建"知识树",让AI既能找到具体条款,又能把握整体结构。
- 通俗理解:RAPTOR就是"自动生成思维导图"
以《混凝土结构施工规范》为例,RAPTOR会:
1底层(叶子节点):拆分后的具体条款(如"5.2.3条 钢筋绑扎要求");
2中层(枝干节点):按章节聚类总结(如"第五章 钢筋工程核心要求");
3顶层(树根节点):全文核心思想(如"混凝土结构施工的强度控制与质量验收标准")。
提问时,AI会同时检索"叶子"和"枝干",既精准又全面。
- 必开场景:这3类文档效果翻倍
1超长技术文档:如500页以上的行业规范、全套标书、项目可行性研究报告;
2宏观总结需求:如"总结这份标书的核心竞争力""概括规范中关于安全施工的要求";
3跨章节推理:如"结合第三章和第五章,分析A2标段的施工流程优化方案"。
- 实操配置:1步开启+资源消耗提醒
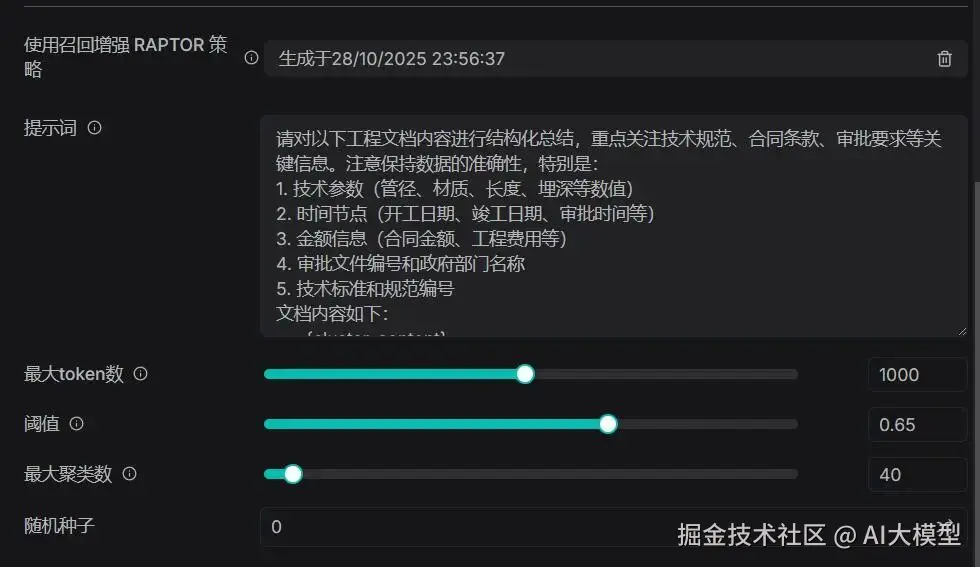
1开启步骤:进入数据集配置页→"召回增强"模块→选择参数→退回知识库界面--右上角点击开启;
1参数默认即可:RAPTOR的聚类层级、总结长度等参数无需手动调整,系统会根据文档长度自动适配;可以让AI给你合适的参数,我这个也是在测试的。
1资源预警:开启后内存占用增加约60%,100页文档解析时间增加8-10分钟,低配服务器慎开。
- 每个参数的意义?
RAPTOR的核心参数直接决定"知识树"的结构与质量,结合工程文档(规范、标书、检测报告等)的层级性、技术性特点,逐一拆解含义及适配方案:
1提示词(Prompt) 参数含义:指导AI生成"知识树"各层级总结(如中层章节概括、顶层全文核心)的指令模板,决定总结内容的侧重点(技术精准性/结构完整性)。 工程场景选择建议:需突出工程文档"层级清晰、术语严谨"的特点,推荐直接复用模板:"请基于工程文档的章节标题、条款编号(如GB 50010-2010的5.2.3条),总结核心内容:1. 明确技术要求/指标数值;2. 保留'章-节-条'层级关系;3. 不遗漏关键施工/验收标准。" 避免用泛用性提示词(如"总结主要内容"),易丢失工程术语精度。
2最大TOKEN数(Max Token) 参数含义:限制单层级总结内容的长度(1汉字≈2Token),决定总结的详略程度------Token数越大,总结越细致但冗余度可能升高。 工程场景选择建议:按文档类型分级设置:① 超长规范/标书(500页+):顶层1000Token、中层800Token、底层500Token(保顶层宏观框架+底层条款细节);② 普通项目报告/检测报表(50页内):统一设500-600Token(避免过度总结丢失关键数据,如混凝土强度值、标段编号);③ 短FAQ/交底记录:设300-400Token(聚焦核心问答/要求)。
3阈值(Threshold) 参数含义:控制聚类的"相似度标准"------数值越接近1,仅允许高度相似的分块聚为一类;数值越低,聚类范围越广(易合并关联内容)。 工程场景选择建议:工程文档需兼顾"关联性"与"独立性",推荐分场景设值:① 规范/技术手册(章节关联紧密):设0.3-0.4(如将"钢筋绑扎""钢筋验收""钢筋检测"聚为"钢筋工程"大类);② 多标段项目资料(各标段独立):设0.6-0.7(避免不同标段的同类资料混乱聚类,如A1与A2标段的混凝土报告分开);③ 混合格式资料(含规范+报表+FAQ):设0.5(平衡关联与独立)。
4最大聚类数(Max Clusters) 参数含义:限制"知识树"的中层(枝干)最大数量,决定层级结构的简洁度------数量过多易拆分过细,过少易合并核心分类。 工程场景选择建议:匹配工程文档的天然层级:① 行业规范(如《混凝土结构施工规范》):设8-12个(对应规范的核心章节数,如"材料要求""施工工艺""质量验收"等);② 项目全周期资料(含立项-施工-验收):设6-8个(对应"项目管理""技术方案""质量控制""安全交底"等核心模块);③ 单一类型资料(如仅检测报表):设3-5个(按"材料检测""结构检测""工序检测"分类)。避免设值>15(易导致层级混乱,检索时难定位)。
5随机种子(Random Seed) 参数含义:控制聚类结果的"稳定性"------固定种子值(如100、200),相同文档重复解析时聚类结果一致;不固定则每次解析可能生成不同聚类(用于测试最优结构)。 工程场景选择建议:① 正式项目知识库:固定种子值(如100)------确保团队成员检索时"知识树"结构一致,避免因聚类变化导致检索结果差异;② 测试/优化阶段:不固定(或多次调整种子值,如100、200、300)------对比不同聚类结构,选择最贴合工程逻辑的方案(如优先按"标段"还是"工序"聚类)。
六、工程人专属:3大场景配置"直接抄作业"
结合前面的知识点,针对工程行业最高频的3类场景,整理了可直接复用的配置方案,附效果验证案例。
场景一:技术规范/法律法规查询库
| 配置项 | 推荐设置 | 核心原因 |
| 分块模板 | Laws模板(优先)/ Book模板 | 保留条款/章节结构,定位精准 |
| chunk_size/chunk_overlap | 2000token / 25% | 长文档保连贯,防条款割裂 |
| 知识图谱 | 关闭 | 规范以条款为主,关系简单,性价比低 |
| RAPTOR | 开启 | 超长文档需宏观+微观结合理解 |
| 嵌入模型 | Qwen3-embedding | 支持大块长,中文适配性好 |
效果验证:提问"GB 50010-2010中关于C30混凝土的强度检测要求是什么?",10秒内定位到具体条款,同时给出章节总结。
场景二:项目管理资料查询库
| 配置项 | 推荐设置 | 核心原因 |
| 分块模板 | General+Table组合(Word用General,Excel用Table) | 适配多格式,保留表格数据关联 |
| chunk_size/chunk_overlap | 800token / 15% | 短文档提精度,兼顾关系连贯 |
| 知识图谱 | 开启(General模式) | 需关联"单位-人员-项目"复杂关系 |
| RAPTOR | 长报告开启,短资料关闭 | 平衡效果与资源消耗 |
| 嵌入模型 | Qwen3-embedding | 中文人名、单位名识别准确率高 |
效果验证:提问"A2标段的施工单位是哪家?其项目经理的监理是谁?",直接返回关联结果,无需手动筛选。
场景三:投标答疑/FAQ知识库
| 配置项 | 推荐设置 | 核心原因 |
| 分块模板 | Q&A模板 | 专门适配问答结构,响应速度快 |
| chunk_size/chunk_overlap | 500token / 10% | 单问答对简短,小色块提效率 |
| 知识图谱 | 关闭 | 问答直接对应,无需关系推理 |
| RAPTOR | 关闭 | 文档简单,无需层级总结 |
| 嵌入模型 | BAAI/bge-large-zh-v1.5 | 问答匹配精度高,速度快 |
效果验证:提问"本项目的投标保证金缴纳期限是多久?",5秒内返回标准答案,准确率100%。
七、避坑指南:工程人常见问题排错表
调参过程中难免遇到问题,整理了4类高频问题及解决方案,附操作路径:
| 常见问题 | 可能原因 | 排查步骤(附操作路径) | 解决方案 |
| 检索不到检测报表数据 | Excel文件用了General模板,表格结构被拆分 | 1. 查看分块记录(文件→Chunk页面);2. 确认模板类型(配置→分块设置) | 1. 删除原分块(批量操作→删除分块);2. 重新上传并选择Table模板 |
| 知识图谱提取不到标段信息 | 未定义"标段"实体类型 | 1. 进入图谱设置→实体模板;2. 检查是否有"标段"类型 | 1. 新增"标段"实体,导入关键词;2. 重新解析文档(文件→重新解析) |
| 开启RAPTOR后服务器卡顿 | 文档过大(超500页)或内存不足 | 1. 查看文档页数(文件→详情);2. 监控内存(服务管理→资源监控) | 1. 拆分文档为单章(每章≤100页)上传;2. 关闭RAPTOR,改用高召回配置(top_n=15,阈值=0.15) |
| 扫描版规范无法识别文字 | 未开启OCR识别功能 | 看一下是否安装了完整版,SLIM需要自己下载OCR的。 | 1. 开启OCR(选择中文识别);2. 重新上传文档,等待识别完成 |
八、如何问答?

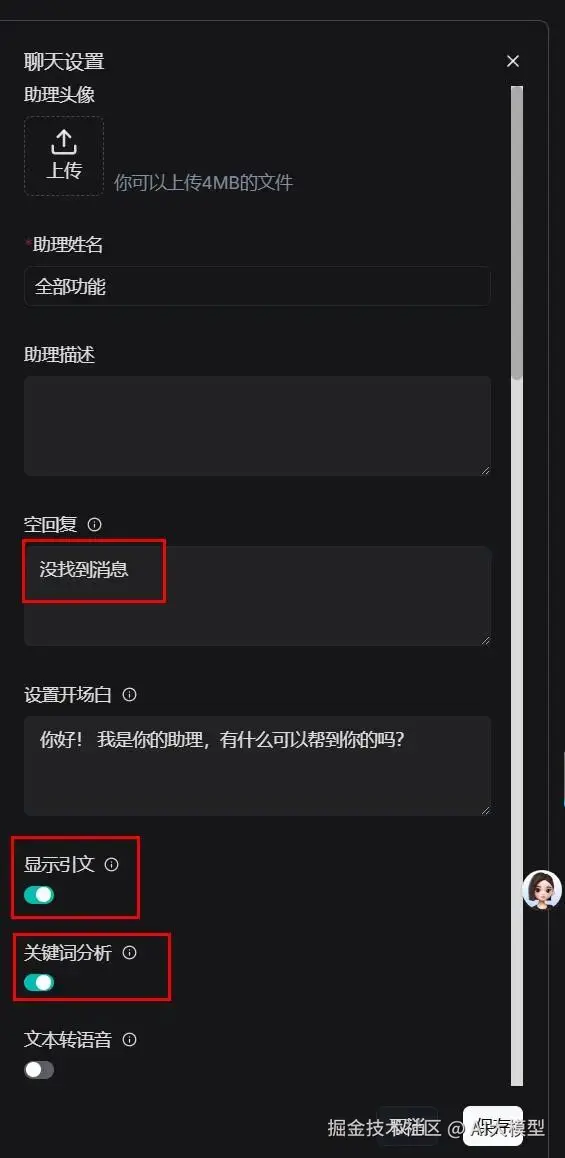
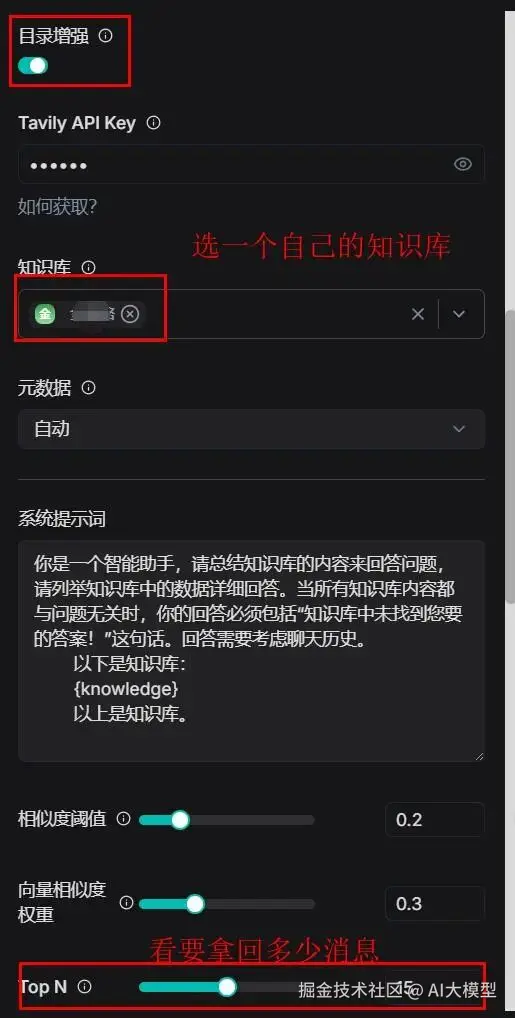
【如果你的知识库没选目录增强,就不要选使用目录增强。】
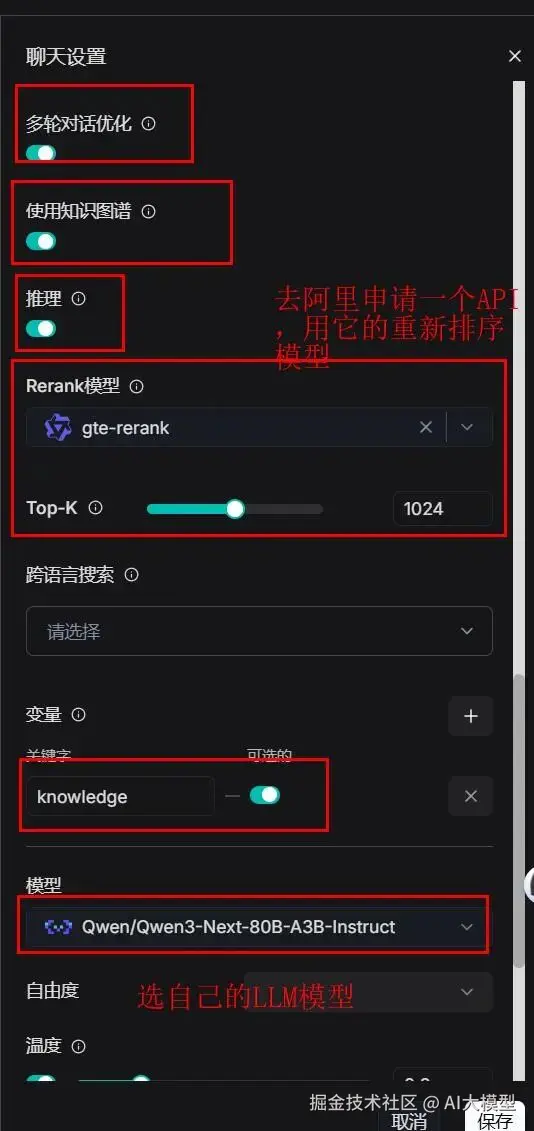
【如果你的知识库没做知识图谱,就不要选使用知识图谱。】
九、总结:调参的核心原则
- 模板优先:先选对模板再调参数,80%的效果由模板决定;
- 场景适配:规范用Laws+RAPTOR,项目资料用General+知识图谱,不盲目开启高级功能;
- 小步测试:新场景先上传10页样例文档测试,效果达标再全量上传;
- 人工兜底:关键文档务必做分块预览,手动调整误差。
最后提醒:没有"万能配置",只有"最适配的配置"。建议收藏本文,根据实际场景对照调整,多测试几次就能找到最优解。
| 到此,我们工程人的大脑可以说是完成了一大半了! |
我正在研究如何使用CLAUDE CODE调用API来查询RAGFLOW,这样的话就可以让CLAUDE CODE把RAGFLOW当做大脑,从而帮我填表和做其他事!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。