在前面的文章中我们了解了 提示词和工具的调用。今天我们来了解一下 rag。rag 全称Retrieval Augmented Generation 即检索增强生成,通过本地知识与问题的结合让大模型生成更好的答案。整个rag包含的知识如下
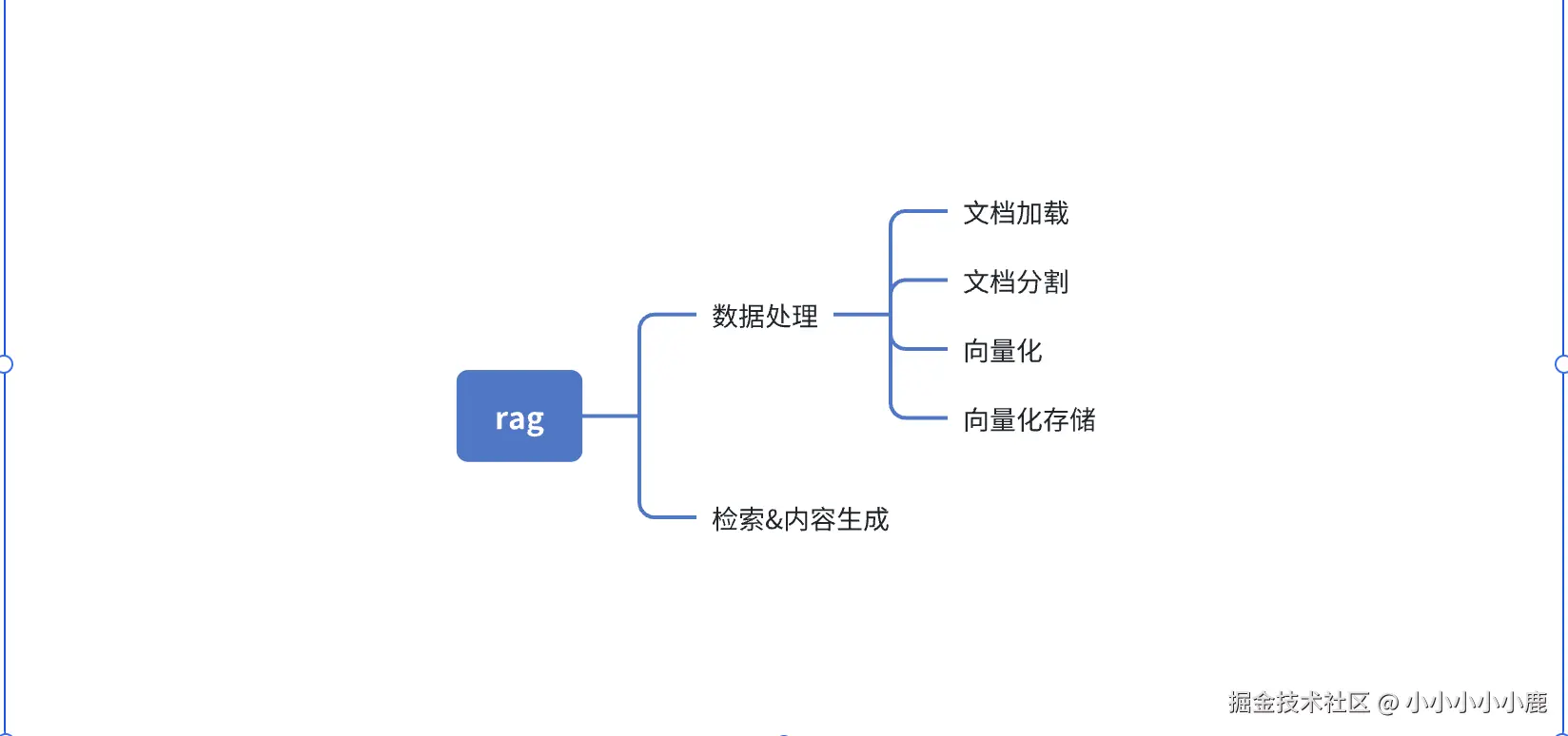
数据处理
数据的处理过程分成4步
- 加载数据
- 切割数据
- 数据向量化
- 向量化数据存储
借用一张langchain官方的图片
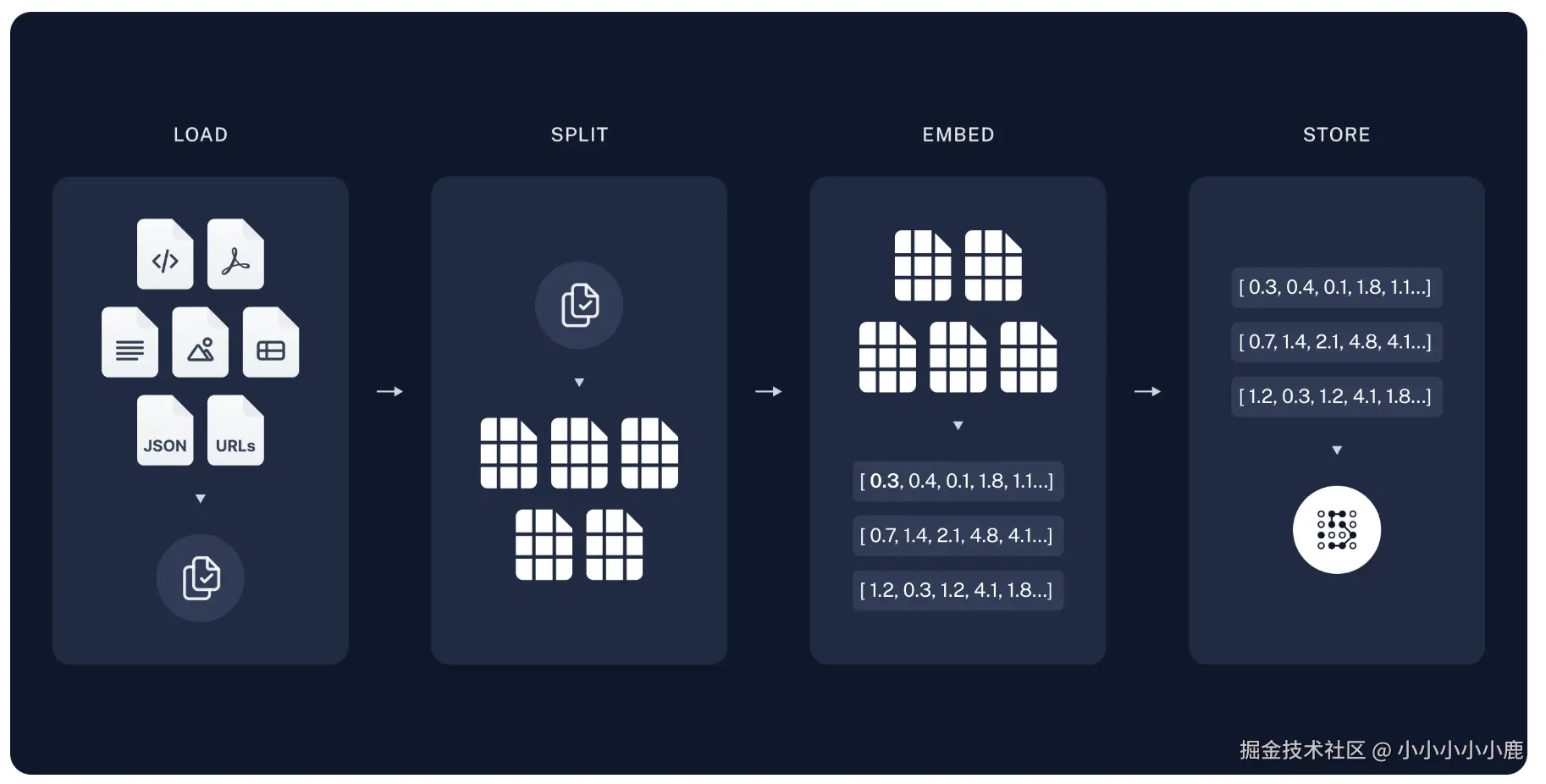
数据加载
在开始的时候我们让Ai帮忙生成了一个一个大模型学习计划 plan.md并且将我们的学习内入输出到 README.md ,这里我们主要做的就是让大模型结合我们的学习计划以及结果来评估我们的学习情况给出更好的建议。
我们这里使用 UnstructuredMarkdownLoader 加载文档, 不同的文档有不同的加载方式 具体可以参考 文档加载列表
python
def load_document(self) -> List:
"""加载 Markdown 文档"""
if not self.markdown_path.exists():
raise FileNotFoundError(f"文档不存在: {self.markdown_path}")
loader = UnstructuredMarkdownLoader(str(self.markdown_path))
self.documents = loader.load()
return self.documents通过加载打印文档的内容查看
python
plan_documents = PlanDocumentProcessor("../plan.md").load_document()
print(f"Total characters: {len(plan_documents[0].page_content)} ${plan_documents[-1].page_content}")
数据切割
大模型对 Token 数量有限制,如果直接将整个原始文档输入上下文,不仅容易超出模型的承载范围,还会增加关键信息被噪声淹没的风险。因此,我们需要对原始文档进行分块处理,确保每段文本长度适中,既能满足模型的输入限制,又能提升关键信息的提取效率。
在实现上,我们使用 MarkdownHeaderTextSplitter 结合 RecursiveCharacterTextSplitter 进行文本分块。MarkdownHeaderTextSplitter将文档按照标头拆分,RecursiveCharacterTextSplitter实现对文本内容的分割
python
from pathlib import Path
from typing import List
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter
def markdown_file_load_and_document_spilt(
markdown_path: str) -> list[Document]:
"""
加载文档,并进行文档分割
:param markdown_path: 文件路径
:return:
"""
# 1. 加载 Markdown 文档
documents = __load_document_from_markdown_path(markdown_path)
# 2. 分割配置(修正:补充参数说明)
all_splits = __splitter_markdown(documents)
return __documents_splitter(all_splits)
def __load_document_from_markdown_path(markdown_path: str) -> List[Document]:
"""加载 Markdown 文档"""
file = Path(markdown_path)
if not file.exists():
raise FileNotFoundError(f"文档不存在: {markdown_path}")
loader = UnstructuredMarkdownLoader(str(markdown_path))
documents = loader.load()
return documents
def __splitter_markdown(documents):
headers_to_split_on = [
("#", "Header 1"), # 一级标题 → 存入 metadata["Header 1"]
("##", "Header 2"),
("###", "Header 3")
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=True # False=保留标题文本在内容中,True=仅存到metadata
)
# 3. 分割处理(修正:优化元数据合并逻辑)
all_splits: List[Document] = []
for doc in documents:
# 提取原始文本并分割
header_splits: List[Document] = markdown_splitter.split_text(doc.page_content)
# 仅合并必要的源元数据(如文件路径)
for split in header_splits:
split.metadata.update({
"source": doc.metadata.get("source", "unknown"), # 保留原始来源
"original_format": "markdown" # 添加自定义标记
})
all_splits.extend(header_splits)
return all_splits
def __documents_splitter(documents: List[Document])->list[Document]:
# 4. 二次分割(保持不变)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", "。", "!", "?"]
)
final_splits = text_splitter.split_documents(documents)
return final_splits向量化与存储
数据向量化是将文本块转换为数值向量(Embedding)的过程。通过嵌入模型(如 OpenAI Embeddings、BERT 等)将文本转换为高维向量,捕捉文本的语义特征,使计算机能够计算文本间的相似度。
向量化数据存储是将生成的文本向量保存到向量数据库(如 Chroma、FAISS、Pinecone 等)的过程。向量数据库支持高效的相似度搜索,能快速找到与查询向量最相似的文本向量,为后续检索提供支持
ini
def load_document():
plan_documents = markdown_file_load_and_document_spilt("../plan.md")
print(f"Total characters: {len(plan_documents[0].page_content)} ${plan_documents[-1].page_content}")
learn_documents = markdown_file_load_and_document_spilt("../README.md")
# 两个文档的数据进行结合
plan_documents.extend(learn_documents),
# 嵌入
embeddings = DashScopeEmbeddings(model="text-embedding-v1",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"))
db = Chroma.from_documents(documents=plan_documents, embedding=embeddings, persist_directory="./chroma_db")检索与内容生成
还是借用一张 官方案例的图片
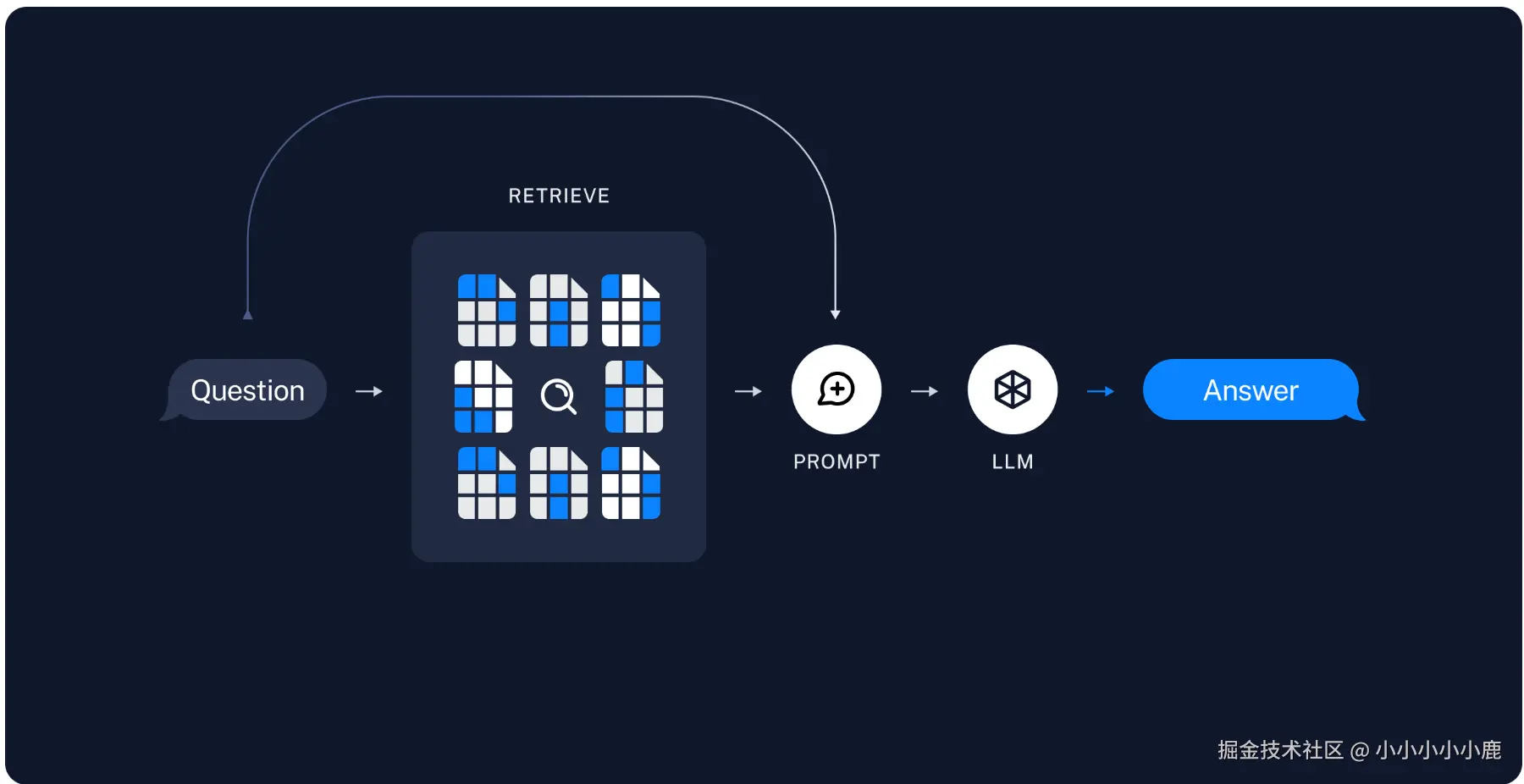
- 初始化llm
- 构建提示词模版
- 通过向量数据库检索相关内容
- 将检索内容和用户问题一起给到大模型
- 得到最终答案
python
import getpass
import os
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tracers.context import tracing_v2_enabled
from learn03.content_loader import search, load_document
try:
# load environment variables from .env file (requires `python-dotenv`)
from dotenv import load_dotenv
load_dotenv()
except ImportError:
pass
os.environ["LANGSMITH_TRACING"] = os.getenv("LANGSMITH_TRACING")
os.environ["LANGSMITH_API_KEY"] = os.getenv("LANGSMITH_API_KEY")
os.environ["LANGSMITH_PROJECT"] = os.getenv("LANGSMITH_PROJECT")
# 1.初始化 llm
model = ChatTongyi(
model="qwen-plus",
api_key=os.getenv("TONG_YI_API_KEY"))
# 2.初始化 提示词模版
complex_template = ChatPromptTemplate.from_messages([
("system", """
你是一名高级ai开发教练,你严谨,认证细致,幽默。你的主要职责是
1. 帮助制定学习计划
2. 检验每日的学习成果,并针对学习效果进行评估。
3. 当学习效果较好时,给予鼓励,当学习效果 较差时 针对不足的内容提出针对性的学习方案,并在此检验直到完成
4. 能够根据实际情况动态调整学习计划与目标。
5. 每次会带 以markdown 格式输出
6. 我的学习计划是{plan}
7. 我当前的学习内容有{learn}
8. 你可以基于当前包含的内容回答问题,当你不知道的时候可以回答不知道
"""),
("user", "{query}"),
])
# 3.通过向量数据库检索出相关数据 ,并结合用户问题,生成最终的回答
with tracing_v2_enabled(project_name=os.environ["LANGSMITH_PROJECT"]):
response = model.invoke(complex_template.invoke({"plan": search("学习计划"), "learn": search("学习内容"),"query":"7.20 学习情况"}))
print(response.content)结果输出:
总结:
RAG 技术通过 "检索 + 生成" 的两阶段架构,有效解决了大模型知识滞后、幻觉和领域适应问题。核心流程包括数据加载、文本分块、向量化和向量存储四个离线步骤,以及检索增强生成的在线步骤。通过 LangChain 框架可以快速实现 RAG 系统,结合学习计划和成果评估等场景,为个性化学习提供有力支持。 代码地址:github.com/xiaolutang/...