**💡**内容来自图灵学术AI科研
从未微调目标数据集,一个预训练模型竟能自己筛选出「黄金训练样本」?
上海交通大学等团队提出 Data Whisperer ------ 首个免训练的注意力驱动数据选择框架。它直接利用预训练模型的上下文学习(ICL)能力,无需额外微调打分模型,仅用 10% 数据就能让微调效果逼近全量数据!
就像一位精通教学的导师,看一眼题库就知道该让学生重点练什么题。
-
论文标题:Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
-
GitHub 地址:gszfwsb/Data-Whisperer
-
关键词:数据选择、上下文学习、小样本泛化、结构对齐
精调大模型,数据挑对才关键
模型说:「别给我扔几百万条数据了,你先告诉我哪些题值得看!」
传统的数据选择方法:
-
要先训练个打分模型;
-
要调一堆启发式参数;
-
要花一堆时间还不一定好用;
而 Data Whisperer 就像摸鱼同学中的学霸 ------ 不看全书也能稳拿高分。
关注计算机科研圈获取ccf/sci发文资讯~
方法核心:ICL与注意力权重的结合
Data Whisperer的核心机制依赖于预训练模型的固有能力,而非外部训练。它通过两个步骤实现数据选择:
-
少样本ICL构建:随机采样少量示范样本(demonstration samples)和查询样本(query samples),构建提示(prompt)让模型尝试回答查询任务。输出质量用于初步评估样本价值。
-
注意力感知权重:不只依赖输出结果,Data Whisperer利用Transformer模型的注意力权重,量化每个示范样本对推理过程的"影响力"。最终打分结合输出质量和注意力贡献,确保稳定性和合理性。
这种方法完全无需人工标注或额外训练,仅利用模型自身结构。
理论支撑:ICL等价于隐式参数更新
Data Whisperer的理论基础在于ICL与精调的等价性。传统精调通过梯度下降更新参数矩阵(如Key矩阵 WK和 Value矩阵 WV):
ΔW=−η∇L
而在ICL中,固定参数模型通过注意力机制加权上下文样本,行为上模拟了权重调整:
y^≈f(x;θ+Δθimplicit)
其中 Δθimplicit并非真实更新,而是注意力机制生成的隐式调整。这解释了Data Whisperer的效能:ICL在行为上"预训"了模型,无需实际参数优化。
关注计算机科研圈获取ccf/sci发文资讯~
实验结果:高效性能与广泛优势
Data Whisperer在多个基准测试中验证了其效果:
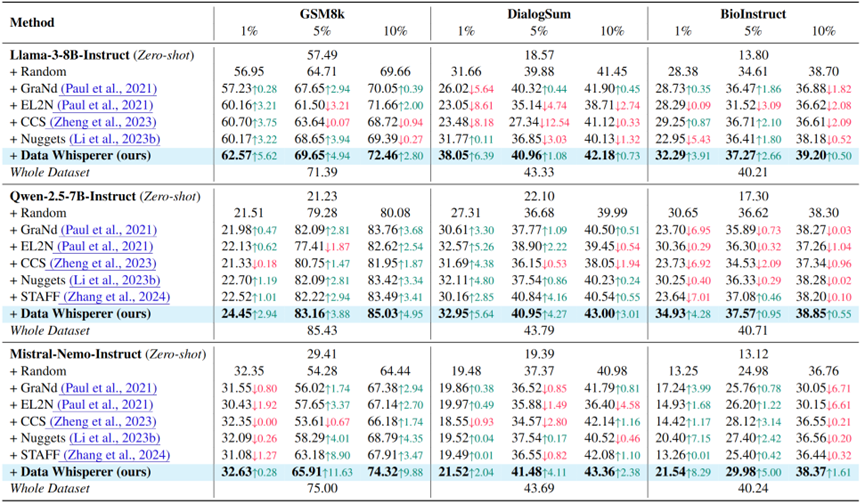
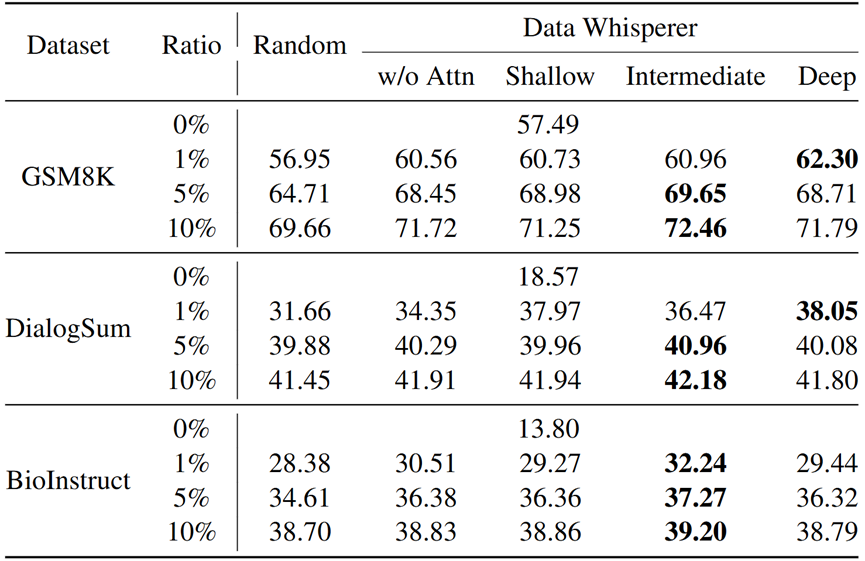
- 任务性能:在数学推理(GSM8K)、对话总结(DialogSum)和生物指令(BioInstruct)任务上,仅用5-10%数据就达到或超越全量数据精调的结果。例如,DialogSum任务中,使用Qwen模型达到43%的准确率,比现有最佳方法高2.5个百分点。
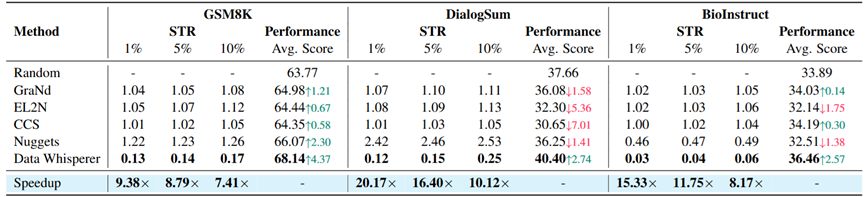
- 效率指标:引入Selection-to-Tuning Ratio(STR)指标(选择耗时与全量精调耗时的比率)。Data Whisperer的STR低至0.03-0.2,远优于传统方法(如Nuggets的STR>1),证明其在时间成本上的显著优势。
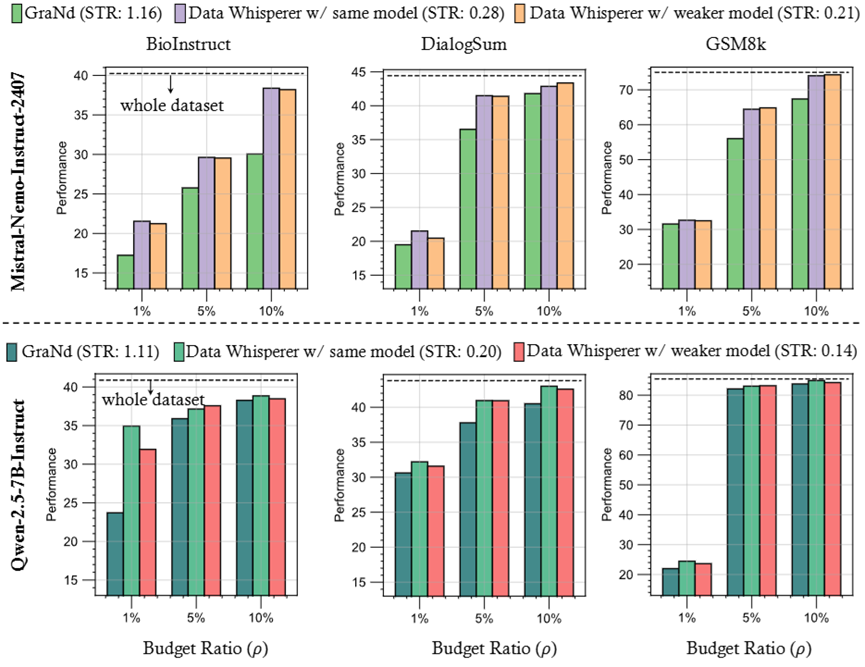
- 弱选强训机制:支持小模型选题、大模型精调的范式(weak-to-strong)。例如,用Qwen-2.5-3B-Instruct选题后精调Qwen-2.5-7B-Instruct,性能接近全量训练,计算负担更低
参数分析与优化
研究团队深入探讨了关键配置的影响:
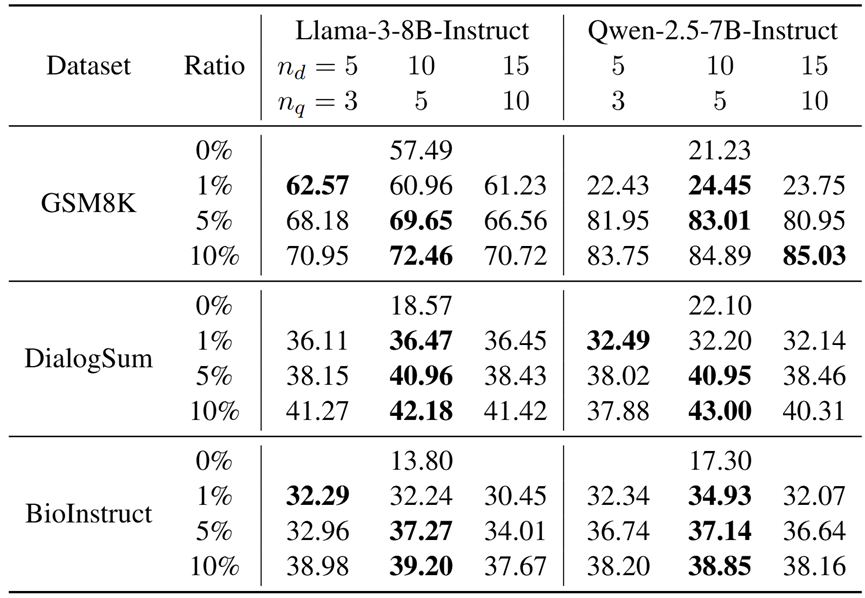
- 样本数量配置:示范样本数(n_d)和查询样本数(n_q)的平衡至关重要。实验显示n_d=10、n_q=5为最优,增加样本效果饱和,凸显框架的高鲁棒性。
- 注意力层选择:不同Transformer层对打分的贡献各异。中层(如Layer13)注意力提供更稳定的语义信息,优化数据选择效果。
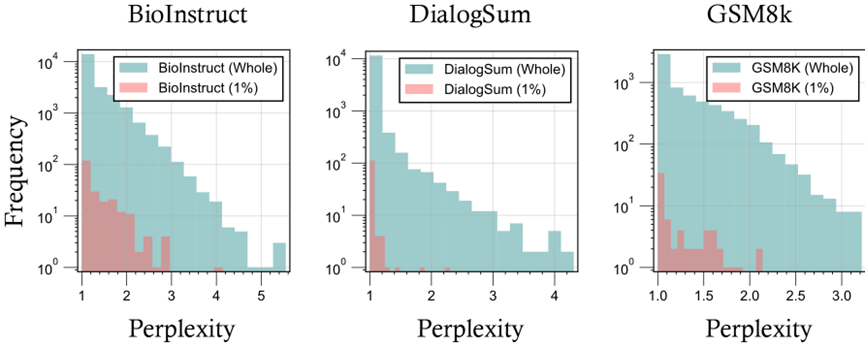
- 样本偏好分析:使用GPT-4o-mini评估显示,Data Whisperer倾向选择困惑度(perplexity)较低的样本,符合"易例优先"理论,优先简单易懂的数据。
关注计算机科研圈获取ccf/sci发文资讯~