AlexNet:
首先回顾一下LeNet-5,该网络结构为CONV-POOL-CONV-POOL-FC-FC,卷积层使用的
的卷积核,步长为1,;池化层使用
的size,步长为2
AlexNet的结构:
CONV1-MAX POOL1-NORM1-CONV2-MAX POOL2-NORM2-CONV3-CONV4-CONV5-MAX POOL3-FC5-FC7-FC8
结构如图:
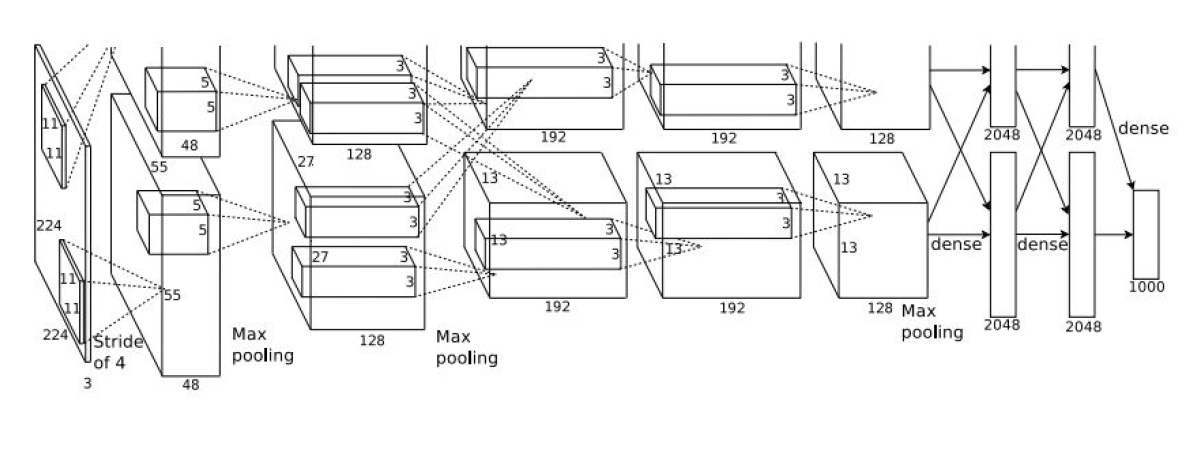
在图中分成上下两个部分,是因为当时的GPU容量太小,需要分成两个GPU来完成
VGG:
相对于AlexNet时候用更小的卷积核,层数也更深,有16层和19层两种。卷积核只使用,padding=1,POOLING为
,stride=2
使用小卷积核的原因:
第一次卷积核感受原图的size是,第二次卷积就是
(因为边界会多感受一格),堆叠三层就变成了
的感受野
多个小卷积层比一个大卷积层有更多层的非线性函数,使得判决函数更加具有判决性
3个的卷积层参数比一个
的大卷积层具有更少的参数,比如假设每个卷积层的输入和输出的size都是
,则3个
的卷积层的参数个数就是
,而
的卷积层的参数个数是
,要更多
GoogLeNet:
网络有22层,比VGG更深
为了高效的计算,使用inception模块
不使用全连接层
Inception Module:
是一种设计得比较好的局域网络拓补结构,如图所示
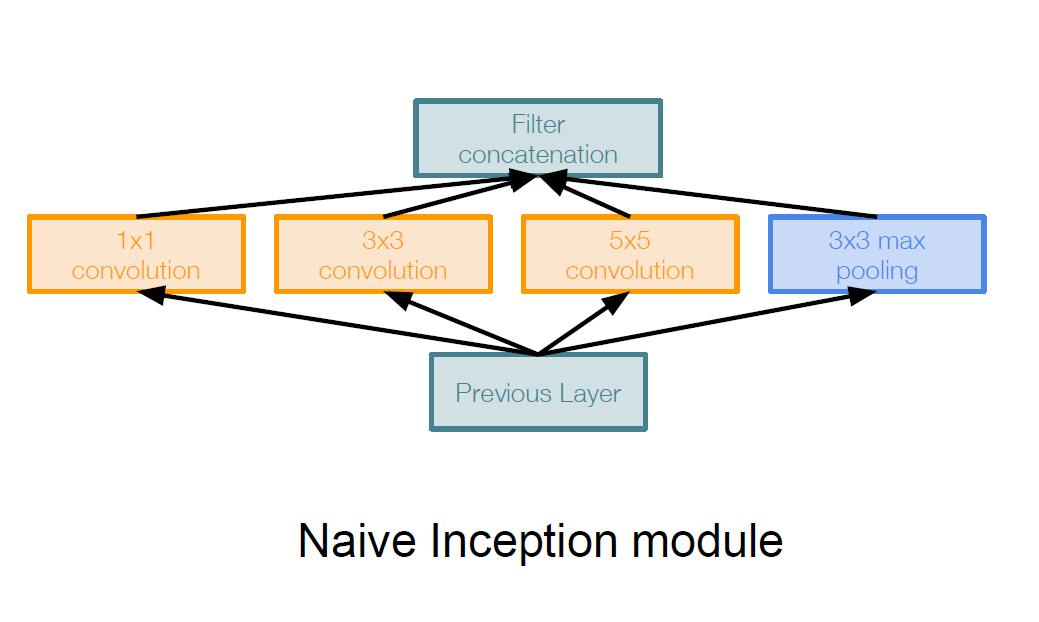
这种结构对上一层的输入分别进行不同size卷积核的卷积以及pooling,通过分别设定不同的padding和步长,保证这几个卷积以及pooling的输出size一致,然后把所有的这些输出在深度上串叠在一起
这种结构的一个问题就是计算量会大大增加,且由于pooling会保持原输入的深度,导致模块的最终输出的深度一定会增加
因此,解决办法是在进行卷积核pooling操作前加入一个bottleneck层,该层使用的卷积,在保留原输入的size的同时,减小其深度(只要kernel的个数小于原输入的深度即可),修正后的模块结构如图所示
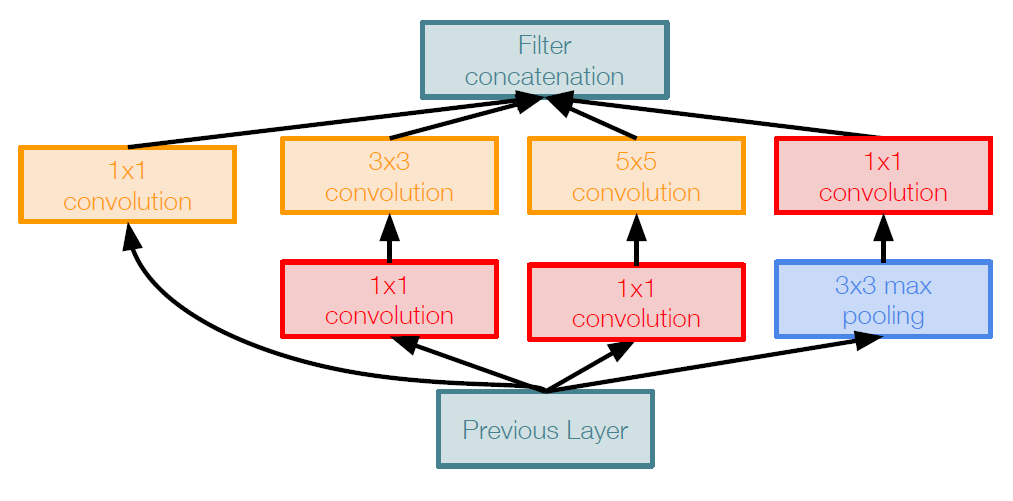
这样一来,我们既减小了输出的深度,又减少了计算量
完整结构:
分为三部分,分别是主干网,inception模块堆叠,分类输出层
如图所示:
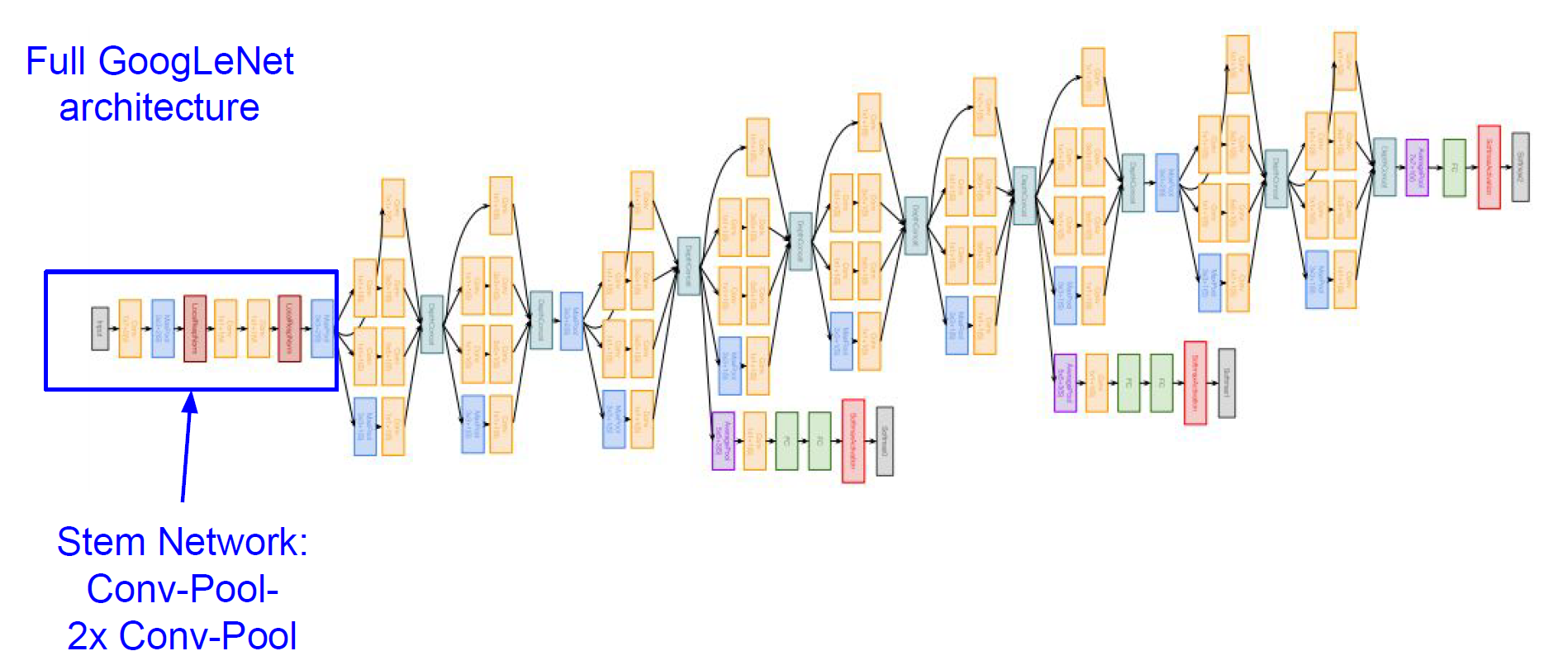
下面还有两个小辅助网络,其在网络较浅的部分作出分类预测,在训练期间,它们的损失会加权(0.3)到网络总损失中,在预测的时候,辅助网络不再使用。这样的目的是,网络中间层产生的特征应该是区别性较强的,通过添加连接到这些中间层的辅助分类器,我们期望在分类器的较低阶段中鼓励区分,增加回传的梯度信号,并提供额外的正则化
ResNet:
有152层
核心思想:
通过使用多个有参层来学习输入与输入输出之间的残差映射(residual mapping),从而保证在深层网络的时候,其所接受到的输入不会比浅层网络的更差,保证了即使在训练不足的情况下,深层网络至少能够有浅层网络的性能
残差学习(Residual Learning):
若将输入设为X,将某一网络层对其的映射设为H,那么该层的输出应是H(X),通常的CNN会直接通过训练学习得出H的表达式,而直接得到X到H(X)的映射
而残差学习是想要使用多个有参网络层来学习输入到输入、输出间的残差H(X)-X的映射,然后再在结果加上X,从而得到直接映射
自身映射(Identity Mapping):
自身映射就是X映射到X不变,由于残差映射最后的结果会直接加上X的自身映射,从而保证其输出最坏也就是完全不做映射,因此有参网络层就能够更好地去学习残差映射
如果残差映射出来的通道数和X的通道数不同时,我们需要特别去设计X的自身映射,使其通道数匹配,通常有两种方法:
1.简单地将X相对于Y缺失的通道直接补0
2.通过使用的卷积作用于X而修改其通道数
完整结构:
如图所示
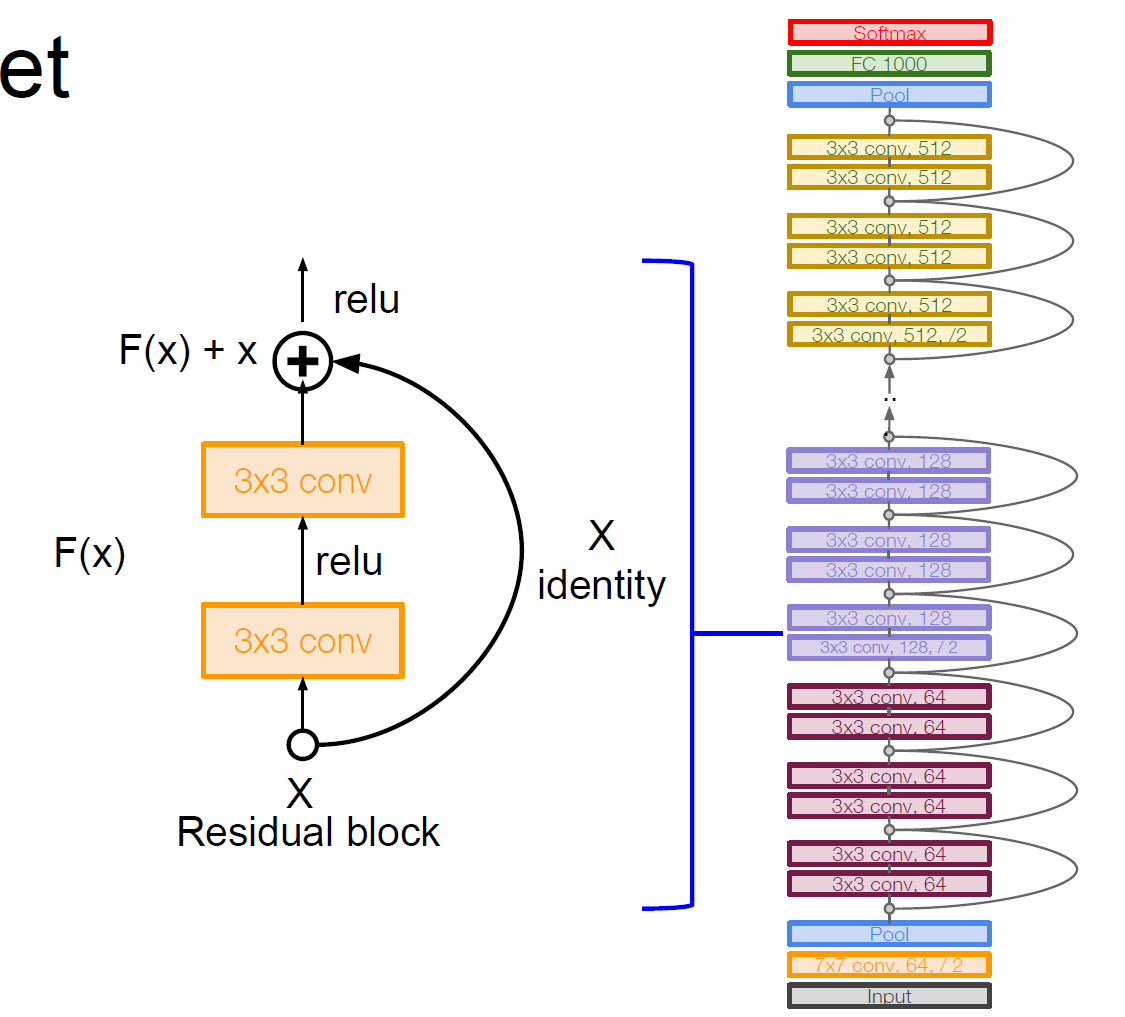
ResNet也会使用类似于GoogLeNet的bottleneck层来提高计算效率