点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月04日更新到: Java-89 深入浅出 MySQL 搞懂 MySQL Undo/Redo Log,彻底掌握事务回滚与持久化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Kafka 序列化器
- Kafka 自定义序列化器
- Kafka 分区器
- Kafka 自定义分区器

拦截器
Kafka 拦截器详解
拦截器概述
Producer拦截器(Interceptor)和 Consumer拦截器是 Kafka 0.10 版本中引入的重要功能,主要用于实现客户端(Client端)的定制化控制逻辑。这些拦截器提供了一种非侵入式的方式来监控和修改消息流,而不需要修改核心的业务逻辑代码。
Producer拦截器功能
对于Producer而言,Interceptor 提供了两个关键时机的拦截点:
- 在消息
发送前:可以对消息内容进行修改或增强 - 在Producer
回调逻辑前:可以处理发送结果或执行清理操作
常见的应用场景包括:
- 消息内容修改(如添加时间戳、消息ID等)
- 消息格式转换
- 发送监控和统计
- 消息日志记录
- 消息加密/解密
拦截链机制
Producer允许指定多个Interceptor,它们会按顺序作用在同一条消息上,形成一个拦截链(Interceptor chain)。这种设计类似于Servlet中的Filter链或Spring中的AOP拦截器链。
核心方法详解
1. onSend(ProducerRecord)
- 执行时机:该方法封装在KafkaProducer.send方法中,运行在主线程中
- 调用顺序:Producer确保在消息序列化及分区计算前调用该方法
- 使用建议:
-
可以对消息内容进行任意修改(如添加header、修改value等)
-
避免修改消息的topic和分区信息,这会影响分区的计算逻辑
-
典型的应用包括:
java// 示例:添加时间戳 public ProducerRecord onSend(ProducerRecord record) { Headers headers = record.headers().add("send_timestamp", System.currentTimeMillis()); return new ProducerRecord(record.topic(), record.partition(), record.key(), record.value(), headers); }
-
2. onAcknowledgement(RecordMetadata, Exception)
- 执行时机:
- 在消息被服务端应答之前调用
- 或在消息发送失败时调用
- 总是在Producer回调逻辑触发之前执行
- 线程特性:运行在Producer的IO线程中
- 使用建议:
-
避免执行耗时或复杂的逻辑,以免阻塞IO线程
-
适合用于:
- 发送结果统计(成功/失败计数)
- 资源清理
- 发送监控
- 错误日志记录
-
示例:
javapublic void onAcknowledgement(RecordMetadata metadata, Exception exception) { if (exception != null) { errorCounter.increment(); } else { successCounter.increment(); } }
-
3. close()
-
功能:关闭Interceptor时调用
-
主要用途:
- 释放Interceptor占用的资源
- 执行最后的统计或日志输出
- 关闭网络连接等
-
示例:
javapublic void close() { // 输出最终统计结果 System.out.println("Success: " + successCounter.get()); System.out.println("Failed: " + errorCounter.get()); }
多线程注意事项
由于Interceptor 可能被运行在多个线程中(主线程和IO线程),在具体实现时需要特别注意:
-
确保所有共享变量的线程安全
-
避免使用非线程安全的集合类
-
考虑使用原子变量或同步机制
-
示例:
java// 线程安全的计数器实现 private final AtomicLong counter = new AtomicLong(0); public void onSend(ProducerRecord record) { counter.incrementAndGet(); return record; }
错误处理机制
当指定了多个Interceptor时:
- Producer会按照配置顺序依次调用每个Interceptor
- 如果在某个Interceptor中抛出异常:
- 异常会被捕获并记录到日志中
- 异常不会向上传递,不会中断后续Interceptor的执行
- 业务逻辑(消息发送)会继续正常执行
- 这种设计保证了单个Interceptor的故障不会影响整体消息发送流程
最佳实践建议
- 保持Interceptor逻辑简单高效
- 避免在Interceptor中执行耗时操作(如网络IO)
- 为Interceptor添加清晰的日志记录
- 考虑使用拦截器实现:
- 消息追踪(TraceID传递)
- 消息加密/解密
- 发送监控和统计
- A/B测试的消息路由
通过合理使用拦截器,可以在不修改核心业务代码的情况下,实现各种横切关注点的功能,这是Kafka提供的一个非常强大的扩展机制。
自定义拦截器
根据对拦截器的观察学习,我们知道了,要实现自定义的拦截器,我们需要:
实现ProducerInterceptor接口- 在
KafkaProducer的设置中定义自定义的拦截器
自定义类
(上一节 大数据 Kafka 58 点击跳转) 借用我们刚才实现的 User 类,这里就不再写了。
自定义拦截器
自定义拦截器01
java
public class Interceptor01<K, V> implements ProducerInterceptor<K, V> {
@Override
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
System.out.println("=== 拦截器01 onSend ===");
// 做一些操作
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("=== 拦截器01 onAcknowledgement ===");
if (null != exception) {
// 此处应该记录日志等操作
exception.printStackTrace();
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}自定义拦截器02
java
public class Interceptor02<K, V> implements ProducerInterceptor<K, V> {
@Override
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
System.out.println("=== 拦截器02 onSend ===");
// 做一些操作
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("=== 拦截器02 onAcknowledgement ===");
if (null != exception) {
// 此处应该记录日志等操作
exception.printStackTrace();
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}使用拦截器
java
configs.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"icu.wzk.model.Interceptor01,icu.wzk.model.Interceptor02"
);原理剖析
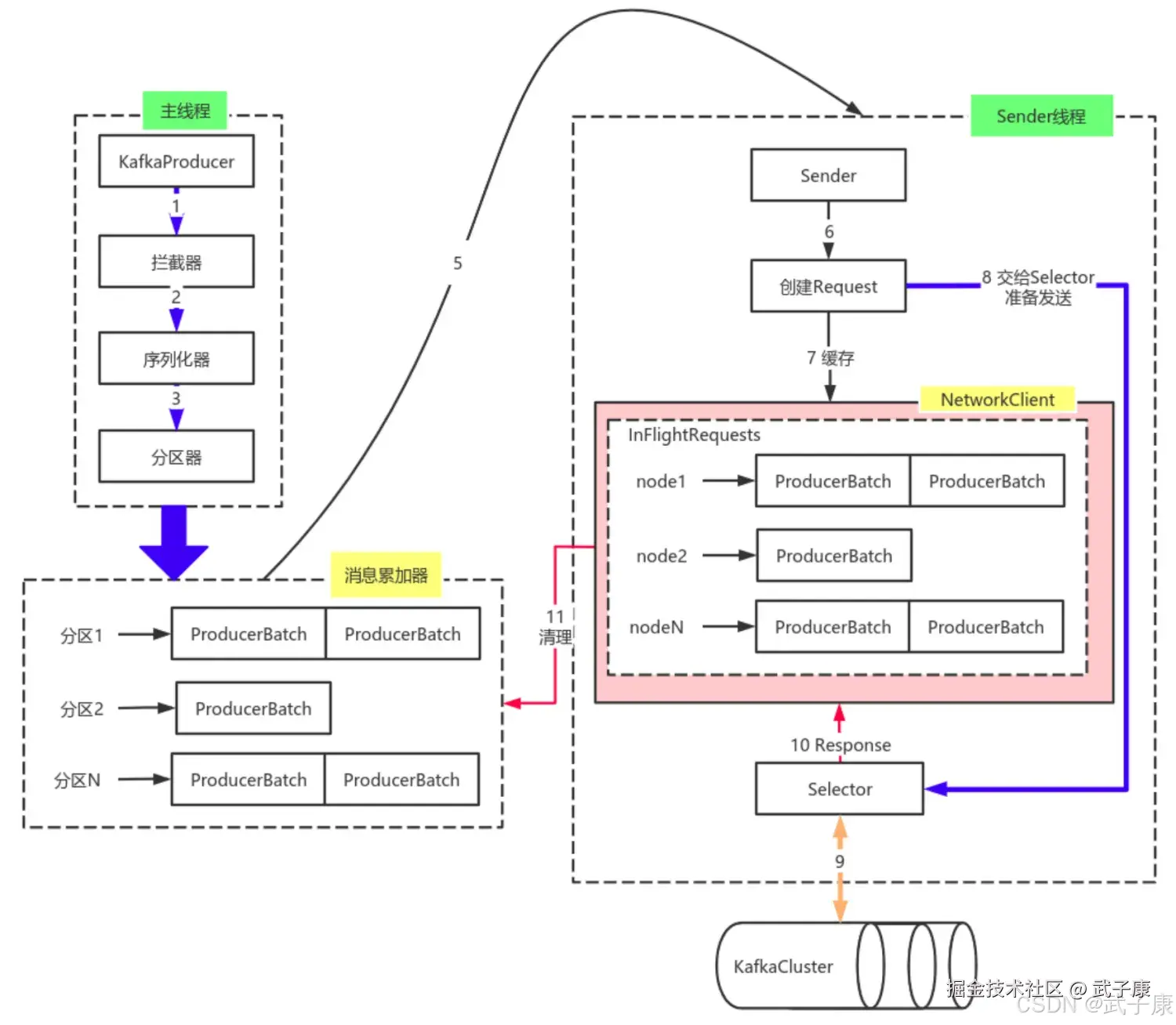
整体原理图
主线程工作流程详解
主线程是Kafka生产者客户端的核心控制线程,主要完成以下关键操作:
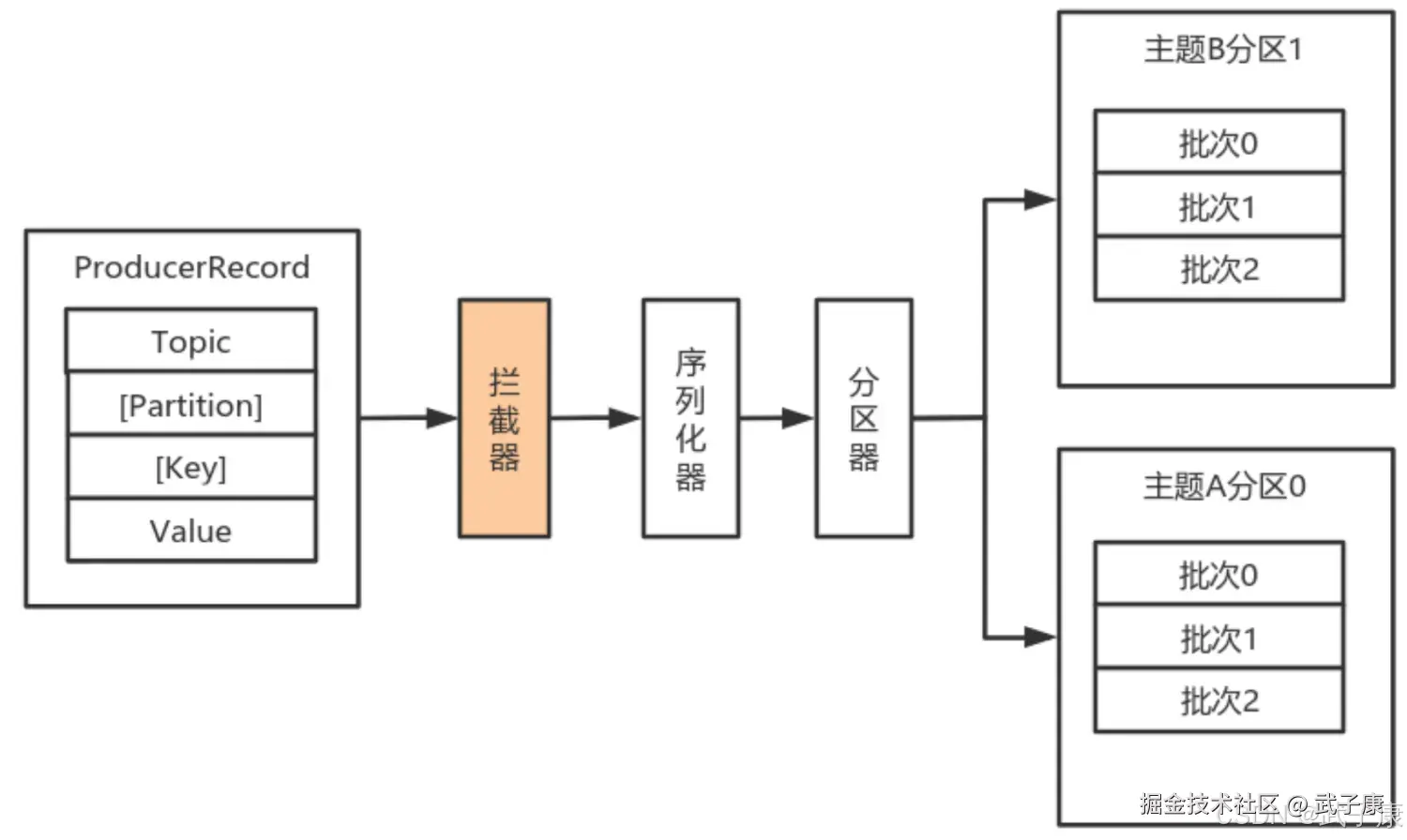
消息处理阶段
- 消息创建:接收应用程序发送的ProducerRecord对象,包含主题、分区、键值对等信息
- 拦截器处理 :依次通过配置的ProducerInterceptor链进行处理,可进行消息修改、统计等操作
- 示例:添加时间戳、消息ID等元数据
- 序列化 :使用配置的Serializer将键值对象序列化为字节数组
- 常见序列化方式:StringSerializer、ByteArraySerializer等
- 分区选择 :通过Partitioner确定消息的目标分区
- 默认策略:key哈希或轮询(无key时)
RecordAccumulator工作机制
消息收集器RecorderAccumulator采用高效的双层存储结构:
-
分区队列:
- 每个分区对应一个Deque双端队列
- 采用双端队列便于头尾操作,提高并发性能
-
批次管理:
- ProducerBatch是内存中的消息批次容器
- 默认大小由batch.size参数控制(默认16KB)
- 采用ByteBuffer存储,支持批量压缩
- 新建批次条件:
- 当前无可用批次
- 现有批次剩余空间不足
- 批次已满(达到batch.size或linger.ms)
- ProducerBatch是内存中的消息批次容器
-
内存管理优化:
-
BufferPool内存池设计:
- 维护固定大小(默认为32MB)的ByteBuffer池
- 只缓存特定大小(由batch.size决定)的ByteBuffer
- 大消息直接分配非池化内存
-
内存分配策略:
javaif (size == poolableSize && !this.free.isEmpty()) return this.free.pollFirst(); // 从池中获取 else return ByteBuffer.allocate(size); // 直接分配
-
发送准备阶段
-
批次转换:
- 将Deque按Broker节点分组
- 生成<Node, List>结构
- 通过元数据获取分区Leader所在的Broker节点
-
请求构建:
- 将批次列表转换为网络请求Request
- 考虑压缩配置(gzip/snappy/lz4等)
- 添加必要的请求头信息
-
飞行请求管理:
-
InFlightRequests缓存设计:
- 采用Map<NodeId, Deque>结构
- 限制每个节点的未确认请求数(max.in.flight.requests.per.connection)
-
负载均衡策略:
javaNode node = this.accumulator.ready(cluster).stream() .min(Comparator.comparingInt(n -> this.inFlightRequests.count(n.id()))) .orElse(null); -
优先选择负载最低的节点发送
-
该设计通过批量处理、内存复用和智能路由等机制,显著提升了Kafka生产者的吞吐量和可靠性。