OpenCV计算机视觉实战(18)------视频处理详解
0. 前言
在日益增多的视频数据洪流中,如何高效地读取、处理、分析并提取出有价值的"内容精华",已成为多媒体、安防与自动化领域亟待解决的核心问题。本文将结合 Python + OpenCV,深入剖析从基本的视频 I/O 到智能运动检测,再到多重特征融合的摘要生成的完整解决方案。
1. 视频读写与帧处理
从磁盘或摄像头读取视频,逐帧进行图像处理(如缩放、灰度转换、加水印等),并将处理后的视频写入文件。
1.1 应用场景
- 实时监控录像存档:在工业或安防场景中,需要对摄像头画面做实时水印、叠加时间戳并压缩存档
- 批量转码与分辨率自适应:对不同终端(手机、平板、电视)批量生成多种分辨率版本
- 并发处理:利用多线程或队列,将帧读取、处理、写出分成流水线加速
1.2 实现过程
- 打开视频源:
cv2.VideoCapture支持文件路径或摄像头索引 - 获取视频信息:帧率 (
fps)、帧宽和帧高 - 循环读取每一帧:在
while cap.isOpened()中逐帧cap.read() - 对单帧做处理:本节中将每帧缩放为原来一半并叠加时间戳
- 写出视频:使用
cv2.VideoWriter配置编码器、输出尺寸和帧率 - 释放资源:
cap.release()与out.release()并关闭所有窗口
python
import cv2, datetime, threading, queue, time
def reader(cap, q):
while True:
ret, frame = cap.read()
if not ret:
q.put(None)
break
q.put(frame)
def writer(out, q):
while True:
frame = q.get()
if frame is None:
break
out.write(frame)
cap = cv2.VideoCapture('r2.mp4')
fps = cap.get(cv2.CAP_PROP_FPS) or 25.0
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*'H264')
out = cv2.VideoWriter('output.mp4', fourcc, fps, (w//2, h//2))
q = queue.Queue(maxsize=100)
t1 = threading.Thread(target=reader, args=(cap, q))
t2 = threading.Thread(target=writer, args=(out, q))
t1.start(); t2.start()
start = time.time()
frame_count = 0
while True:
frame = q.get()
if frame is None:
break
small = cv2.resize(frame, (w//2, h//2))
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
cv2.putText(small, timestamp, (10, h//2-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0), 1)
cv2.imshow('Processed', small)
if cv2.waitKey(1) == 27:
break
frame_count += 1
t1.join(); t2.join()
cap.release(); out.release()
cv2.destroyAllWindows()
print(f"Average FPS: {frame_count/(time.time()-start):.2f}")
关键函数解析:
cv2.VideoCapture(source):创建视频读取对象,source为设备索引或文件路径cap.read():返回布尔值与当前帧cv2.VideoWriter(filename, fourcc, fps, frameSize):创建视频写入对象cv2.resize(src, dsize):改变帧大小cv2.putText():在帧上绘制文本cap.release()/out.release(): 释放I/O资源
2. 运动检测(背景差分法)
自动分离视频中的静态背景与动态前景,提取移动目标轮廓,广泛用于安防监控与交通流量统计。
2.1 应用场景
- 复杂光照下的可靠检测:加入阴影检测与去除,过滤街道灯光、树影干扰
- 双模型融合:同时使用
MOG2和KNN两种背景建模,按置信度融合前景掩码 - 前景目标跟踪:在检测到的轮廓上附加
Kalman滤波或SORT算法,实现多目标跟踪
2.2 实现过程
- 初始化背景建模器:
cv2.createBackgroundSubtractorMOG2或KNN - 逐帧更新与前景提取:
apply()返回前景掩码 - 后处理:对掩码做形态学开/闭运算,去除噪声并填补小孔
- 轮廓检测:在前景二值图上
cv2.findContours提取移动目标区域 - 可视化:绘制边界框或轮廓
python
import cv2
import numpy as np
cap = cv2.VideoCapture('r2.mp4')
fgbg1 = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=25, detectShadows=True)
fgbg2 = cv2.createBackgroundSubtractorKNN(history=500, dist2Threshold=400.0, detectShadows=False)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5,5))
while True:
ret, frame = cap.read()
if not ret: break
m1 = fgbg1.apply(frame)
m2 = fgbg2.apply(frame)
# 阴影剔除(MOG2 阴影值为127)
m1 = np.where(m1==127, 0, m1).astype('uint8')
# 融合掩码
fgmask = cv2.bitwise_and(m1, m2)
# 形态学处理
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel, iterations=1)
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_CLOSE, kernel, iterations=2)
contours, _ = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 800: continue
x,y,w,h = cv2.boundingRect(cnt)
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 2)
cv2.imshow('Frame', frame)
cv2.imshow('Mask', fgmask)
if cv2.waitKey(30) & 0xFF == 27: break
cap.release()
cv2.destroyAllWindows()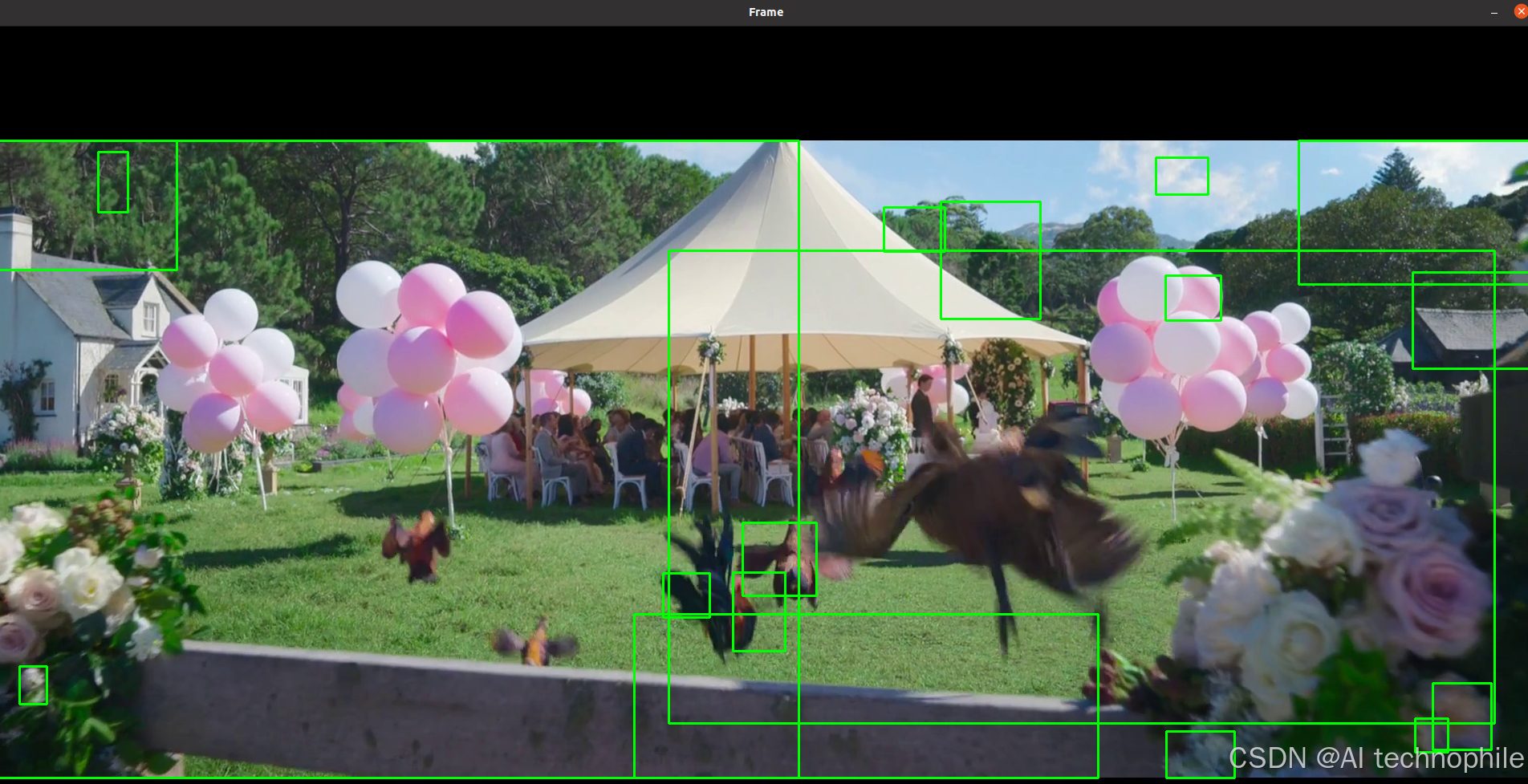
关键函数解析:
cv2.createBackgroundSubtractorMOG2(history, varThreshold, detectShadows):基于高斯混合模型的背景减除器fgbg.apply(frame):更新模型并返回前景掩码cv2.morphologyEx(img, op, kernel):形态学操作去噪cv2.findContours():提取前景掩码中的连通区域cv2.boundingRect(cnt):计算轮廓外接矩形
3. 视频摘要生成
从长视频中自动抽取最具代表性的关键帧,生成"摘要视频"或"故事板",便于快速浏览与检索。
3.1 过程解析
- 多特征融合:结合图像直方图差异、帧间结构相似度 (
Structural Similarity Index Measure,SSIM) 及人脸/物体检测结果,提升摘要代表性 - 聚类筛选:对所有候选关键帧提取特征,用
K-Means聚类后,从每簇选代表帧,去除冗余 - 动态摘要:根据视频内容节奏,动态调整关键帧间隔,如运动多的片段密集采样。
3.2 实现过程
- 全局特征提取:对每帧计算直方图或深度特征(本节采用
HSV直方图) - 帧间相似度:计算相邻帧直方图差异,当差异超过阈值时标记为"关键帧"
- 关键帧采样:收集所有关键帧或每隔固定时长取一帧以增强多样性
- 摘要视频写出:将关键帧按时间顺序写入新视频文件
python
import cv2, numpy as np
from skimage.metrics import structural_similarity as ssim
from sklearn.cluster import KMeans
cap = cv2.VideoCapture('r2.mp4')
frames, hist_list, feats = [], [], []
while True:
ret, frame = cap.read()
if not ret: break
frames.append(frame)
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
h = cv2.calcHist([hsv],[0,1],None,[50,60],[0,180,0,256])
hist_list.append(cv2.normalize(h,h,0,1,cv2.NORM_MINMAX).flatten())
cap.release()
# 1. 初步筛选:直方图差异 + SSIM
candidates, prev = [0], hist_list[0]
for i,h in enumerate(hist_list[1:],1):
if cv2.compareHist(prev.reshape(50,60), h.reshape(50,60),
cv2.HISTCMP_BHATTACHARYYA) > 0.7:
sim = ssim(cv2.cvtColor(frames[i-1],cv2.COLOR_BGR2GRAY),
cv2.cvtColor(frames[i],cv2.COLOR_BGR2GRAY))
if sim < 0.85:
candidates.append(i)
prev = h
# 2. 聚类降冗余
feat = np.array([hist_list[i] for i in candidates])
k = min(10, len(candidates))
labels = KMeans(n_clusters=k).fit_predict(feat)
summary_idx = [candidates[np.where(labels==l)[0][0]] for l in range(k)]
summary_idx.sort()
# 3. 写入摘要视频
fps = 25; h,w,_ = frames[0].shape
out = cv2.VideoWriter('summary.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (w,h))
for idx in summary_idx:
out.write(frames[idx])
out.release()关键函数解析
cv2.calcHist(images, channels, mask, histSize, ranges):计算多维直方图cv2.normalize(src, dst, alpha, beta, norm_type):归一化直方图cv2.compareHist(h1, h2, method):比较直方图相似度,此处用巴氏距离ssim(img1, img2):结构相似度,用于补充直方图在细节对比上的不足KMeans(n_clusters=k):对候选帧直方图特征聚类,减少相似帧冗余VideoWriter.write(frame):将关键帧写入摘要视频
小结
本文围绕视频处理的三个核心环节------读写帧处理、运动检测与摘要生成,构建了一个基于 Python + OpenCV 的完整视频分析工作流。通过帧级并发处理提升效率,利用背景差分法精准提取动态目标,并融合图像特征与聚类方法高效生成视频摘要,为多媒体内容理解奠定基础。
系列链接
OpenCV计算机视觉实战(1)------计算机视觉简介
OpenCV计算机视觉实战(2)------环境搭建与OpenCV简介
OpenCV计算机视觉实战(3)------计算机图像处理基础
OpenCV计算机视觉实战(4)------计算机视觉核心技术全解析
OpenCV计算机视觉实战(5)------图像基础操作全解析
OpenCV计算机视觉实战(6)------经典计算机视觉算法
OpenCV计算机视觉实战(7)------色彩空间详解
OpenCV计算机视觉实战(8)------图像滤波详解
OpenCV计算机视觉实战(9)------阈值化技术详解
OpenCV计算机视觉实战(10)------形态学操作详解
OpenCV计算机视觉实战(11)------边缘检测详解
OpenCV计算机视觉实战(12)------图像金字塔与特征缩放
OpenCV计算机视觉实战(13)------轮廓检测详解
OpenCV计算机视觉实战(14)------直方图均衡化
OpenCV计算机视觉实战(15)------霍夫变换详解
OpenCV计算机视觉实战(16)------图像分割技术
OpenCV计算机视觉实战(17)------特征点检测详解