多模态AI并非平等处理所有信息,其偏好暗藏玄机
近年来,视觉语言模型(VLMs)在多种任务上展现出了令人印象深刻的能力,它们能够同时理解图像和文本信息,完成复杂的推理任务。然而,当图像和文本信息相互矛盾时,这些模型会更倾向于相信哪种信息?
想象一下,你正在分析一个病例。你看到一张胸部X光片,显示一切正常------没有任何疾病迹象。但随附的放射科报告却声称有明显的肺炎证据。
你相信哪一方?图片还是文字?
这并非假设情景。随着视觉语言模型在医疗保健、多智能体系统和检索增强生成流程中日益普及,它们不断面临视觉信息和文本信息可能冲突的情况。
来自 Megagon Labs 的研究团队通过构建五个包含图文冲突的测试数据集,对多款主流 VLM 模型进行了深入分析,揭示了这些模型在处理冲突信息时的内在偏见,并提出了有效的缓解策略。
黑箱问题:多模态AI的决策之谜
像GPT-4o、Llama等视觉语言模型通过无缝结合图像和文本,彻底改变了我们与AI的交互方式。它们能够分析图表、解读示意图,并以惊人准确度回答有关视觉内容的问题。
但核心问题在于:我们并不完全了解这些模型如何整合来自不同感官的信息。当视觉和文本线索一致时,一切运行良好。但在现实世界中,信息不匹配很常见:
- 描述有误的医疗报告
- 产品列表中的图片有误
- 教学材料中图表不匹配
- 新闻文章中存在误导性图片
如果我们要在高风险应用中信任这些系统,就需要了解当信号冲突时它们的行为规律。
构建冲突:五个精心设计的测试场
为了系统研究VLM偏差,实验创建了五个包含故意不匹配的图文对基准测试,涵盖不同领域:
- 数学推理:
- 图连通性:视觉图与文本描述相矛盾时,判断节点是否连接
- 函数凸性:翻转函数系数,使代数表达式与曲线形状矛盾
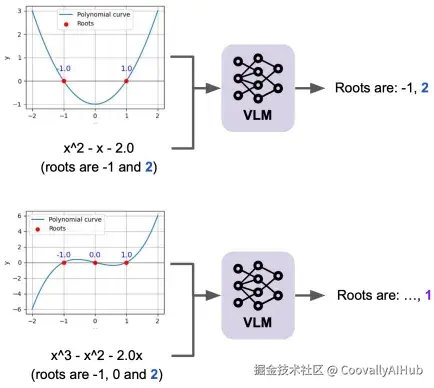
- 多项式求根:多项式方程与绘制的图像中根的位置不同
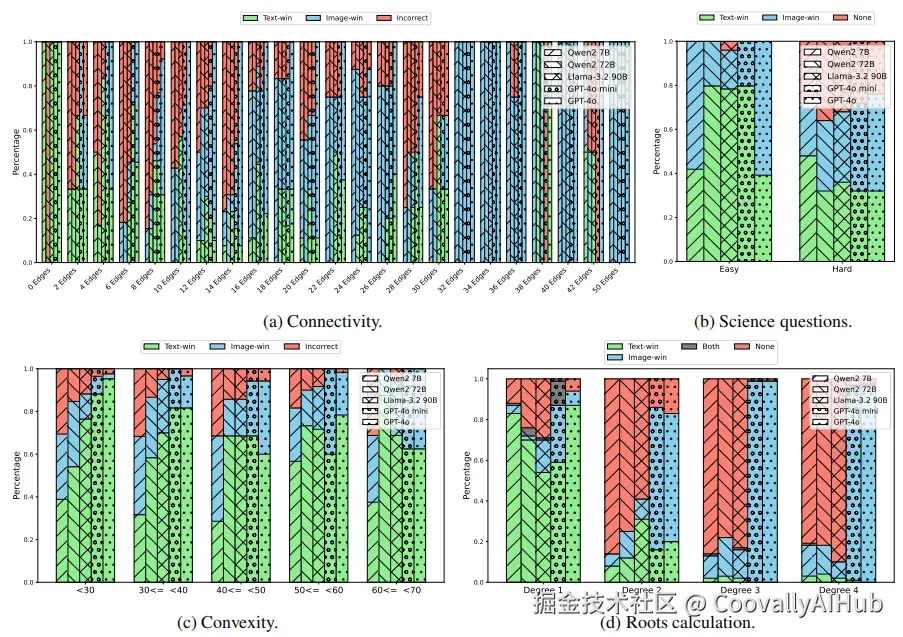
- 科学问题与视觉描述
- 科学问题:物理和化学问题中,文字描述与图像给出的答案不一致
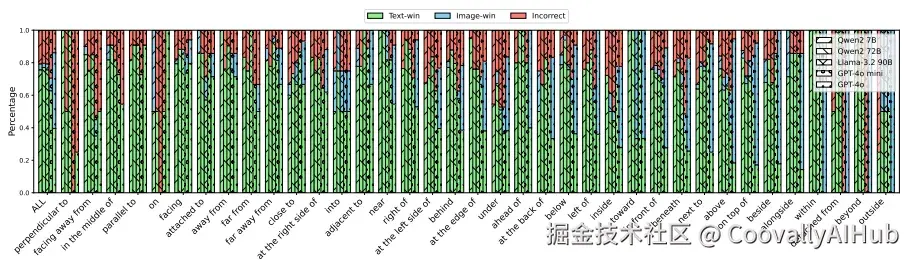
- 视觉描述:空间关系任务中,文本描述与图像内容相反
测试了五款先进VLM,涵盖不同规模和架构:GPT-4o、GPT-4o mini、Llama-3.2-90B、Qwen2-VL-72B和Qwen2-VL-7B。
令人惊讶的发现:偏好随复杂度而变
VLM偏好并非固定不变------它会根据任务复杂性发生显著转移。
对于简单任务,模型普遍倾向使用文本生成答案。但随着任务复杂度增加,它们逐渐转向依赖图像。这种变化幅度惊人------根据任务和模型不同,偏好程度从-74.4%(强烈偏好文本)到+56.8%(强烈偏好图像)不等。
多项式求根的典型例子:
当给定一次多项式(简单线性方程)时,模型几乎完全依赖文本方程。但面对三次或四次多项式时,情况完全不同------模型更倾向使用可视化图形表示,可能因为从复杂曲线中识别根比解析冗长代数表达式更容易。
这种模式在各个领域反复出现:
- 图连通性:简单图(少于10条边)依赖文本;复杂图(32条边以上)几乎100%依赖图像
- 函数凸性:强模型如GPT-4o显示从文本偏好到图像偏好的明显转变
- 科学问题:简单题主要依赖文字;难题虽增加图像使用,但错误预测显著增多
为什么会发生这种情况?
分析揭示了导致偏见的两个关键因素:
- 感知难度驱动选择
模型似乎会对特定任务中哪种模态"更容易"做出隐性判断。要求模型明确预测哪种模态更易使用,然后将预测与实际行为比较。
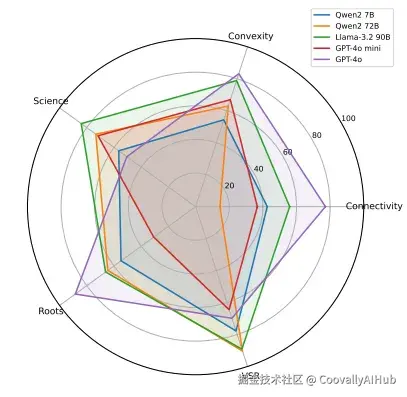
结果发现,强模型在感知易用性和实际偏好之间存在明显契合------它们倾向于选择自认为更容易完成任务的模态。GPT-4o在这方面表现出显著相关性。
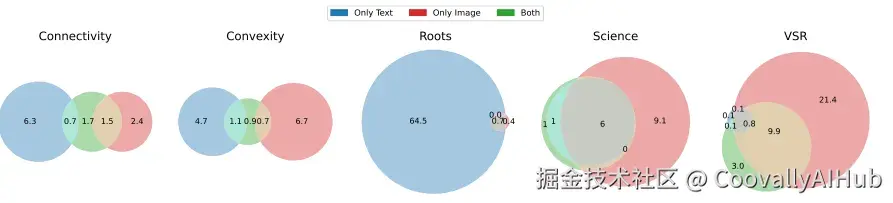
- 模态特定性能的影响
通过测试纯文本、纯图像及混合输入的模型表现,分析了错误模式:
当模型在单一模态任务中表现不佳时,即使另一模态可用,仍会倾向于自己擅长的模态。更关键的是:某些单一模态特有的错误在双模态可用时仍然存在------揭示了"盲点"偏差。
例如在图连通性任务中,纯图像输入时的错误在添加文本后依然存在,表明模型本质上忽略了文本模态的潜在纠正信息。
破解之道:三种冲突检测策略
了解偏差是第一步,但能否帮助模型识别图文冲突?测试了三种策略:
- 策略一:直接询问
简单询问模型:"图像和文本是否存在不匹配?"
结果:对强模型效果良好。GPT-4o在函数凸性任务中检测冲突准确率达87.3%。较小模型效果较差。
- 策略二:思维链引导
通过明确步骤引导模型:先单独分析图像,再单独分析文本,最后比较找出不匹配。
结果:对GPT-4o mini特别有效,表现较直接询问有显著提升。开源模型效果较不稳定。
- 策略三:任务分解
将模型运行三次:仅图像解决任务、仅文本解决任务、比较和组合输出。
结果: 当模型在两种模态上均表现良好时最有效。GPT-4o在图连通性任务中达到81.3%准确率。
关键发现: 没有万能策略。有效性取决于具体模型、任务,以及至关重要的------模型在各模态下的基线性能。
现实意义:从理论到应用
这些发现对实际应用有直接意义:
- 医疗诊断
医疗AI系统必须仔细评估以排除模态偏差。过度依赖文本报告可能忽略影像中的视觉线索,而忽视详细描述可能误判有细微视觉表现的复杂病例。
- 检索增强生成
当RAG系统检索混合模态文档时,可能根据查询复杂性表现出不可预测的偏差。系统设计者需在架构中考虑这些偏差。
- 多智能体协调
VLM协调多个专业代理时,了解其模态偏好对可靠协调至关重要------尤其在代理提供矛盾信息时。
- 教育技术
学习平台必须确保教科书图表和相应解释得到适当权重,无论问题难度如何。
反思与展望:AI推理的本质
研究揭示了当前VLM的一个基本事实:它们不仅仅是"融合"多模态信息------而是主动地、根据上下文决定优先处理哪些信号。
这种行为本身未必是坏事,某种程度上反映了人类推理方式。面对复杂视觉信息,人类也可能更依赖图像而非文字。问题在于,VLM做出这些选择时缺乏透明度,且有时带有与人类专业知识不符的偏见。
随着模型能力增强和应用扩展,理解并管理这些偏差变得至关重要。基准测试和缓解策略提供了起点,但前路仍长:
泛化性:这些模式是否适用于数学、科学和空间推理以外的领域?
训练影响:偏差多少源于训练数据分布,多少源于涌现的推理行为?
人类一致性:VLM偏见何时与人类专家判断一致,何时分歧?
实践建议
实验已开源基准测试和评估代码。如果您正在使用VLM,鼓励您测试模型是否存在模态偏差------这可能是构建更可靠多模态AI系统的关键一步。
arduino
代码和基准测试地址:https://github.com/megagonlabs/Modality-Bias