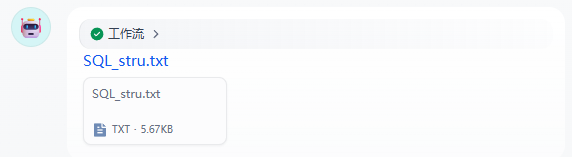
我在使用http节点下载文件时,文件名默认为UUID,于是我设置了请求头
Content-Disposition: attachment; filename*=UTF-8''{file_name}但是发现还是没有变化
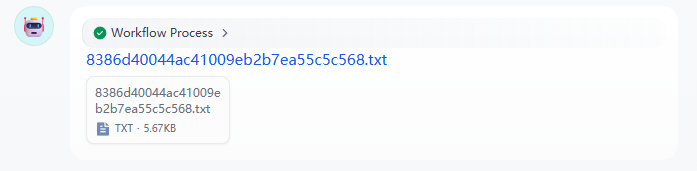
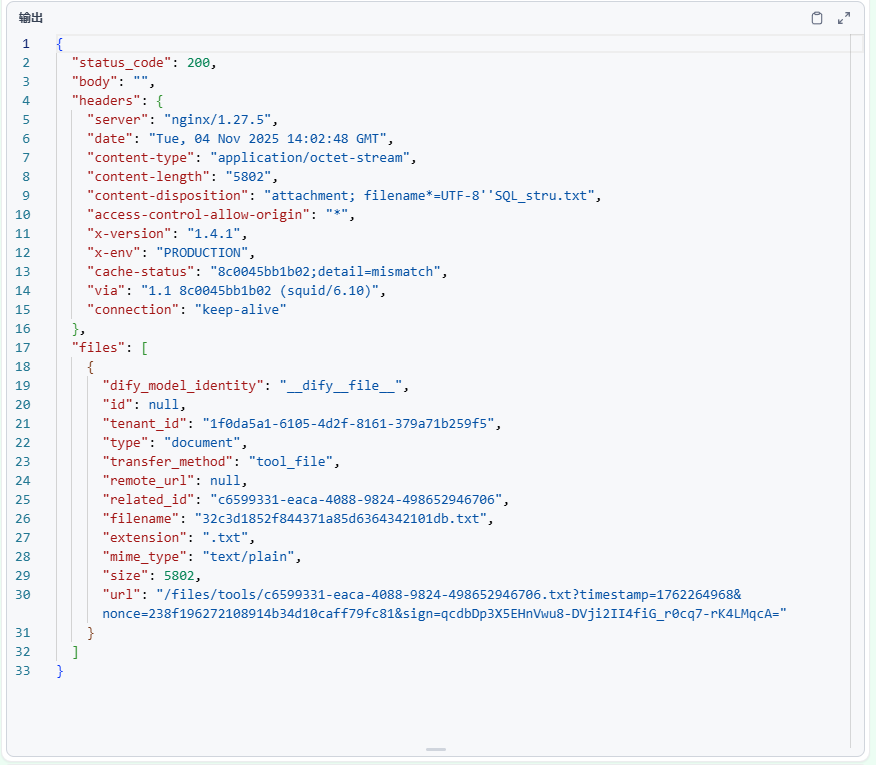
而且我发现设置的Content-Disposition完全没有起作用,并且返回的结果本身就是原始文件名,但是并没有启用,最后files中的filename返回的还是uuid。
我在github上发现有人有相同的问题,并且已经解决
简单来说就是需要去修改后端代码,如果是docker部署就需要去docker中修改,
修改的文件为 api/core/workflow/nodes/http_request/node.py,190行左右,修改为
python
content_disposition_filename = None
if parsed_content_disposition:
content_disposition_filename = parsed_content_disposition.get_filename()
filename = content_disposition_filename or url.split("?")[0].split("/")[-1] or ""
# ... rest of your logic
tool_file = tool_file_manager.create_file_by_raw(
user_id=self.user_id,
tenant_id=self.tenant_id,
conversation_id=None,
file_binary=content,
mimetype=mime_type,
filename=filename, # <-- pass the filename here
)随后就可以输出原始文件名的文件了