1. Transformer的背景
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
论文地址: https://arxiv.org/pdf/1810.04805.pdf
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer。
直到现在,Transformer在市场中占用率依旧居高不下,大多数大模型或多或少都使用了transformer的encoder或者decoder架构
2. transformer架构图
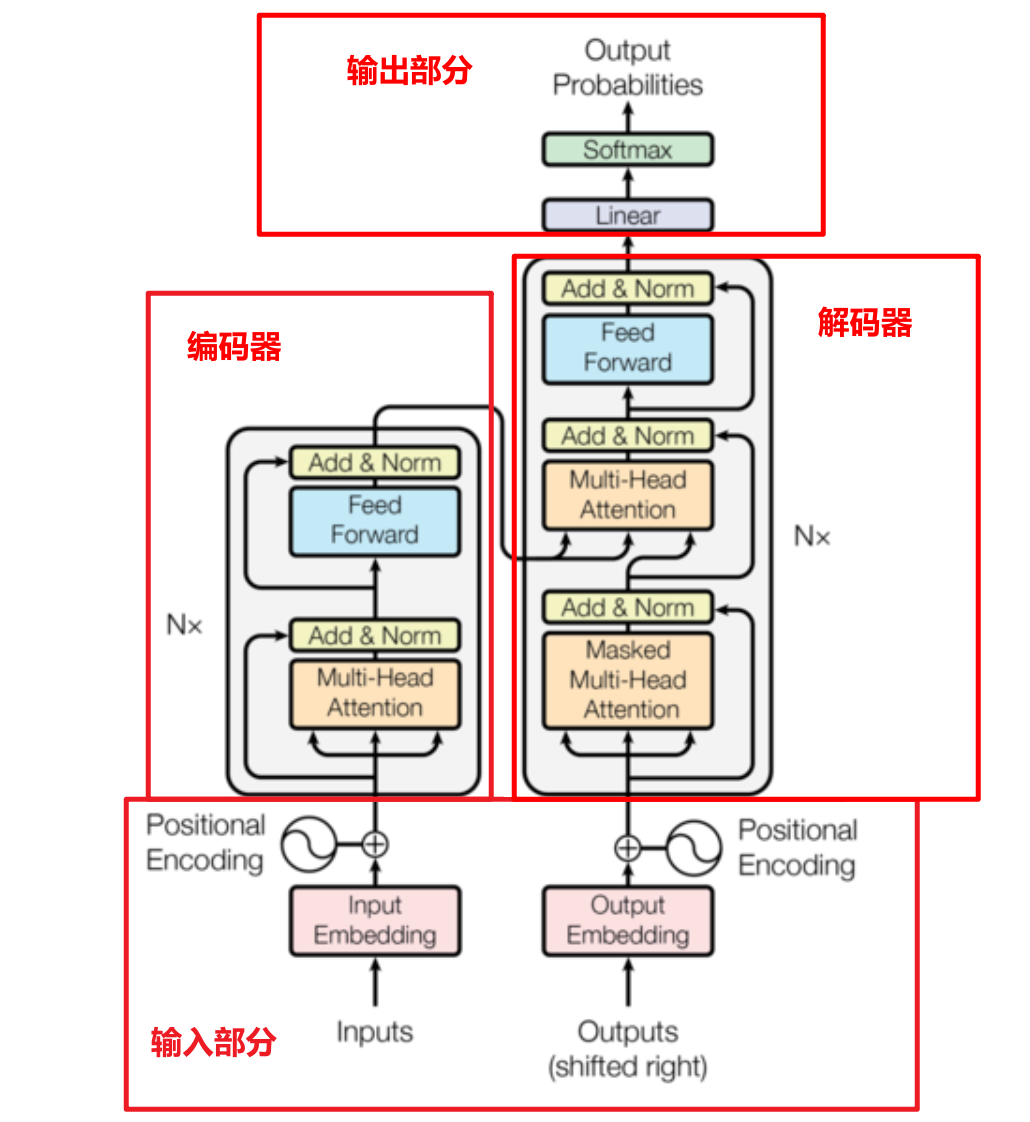
2.1 输入部分
输入部分包含:
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
2.1.1 文本嵌入层的作用
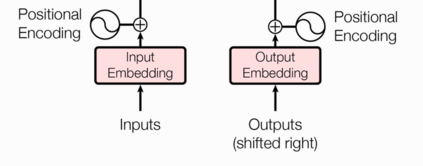
- 无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示, 希望在这样的高维空间捕捉词汇间的关系.
注意:为什么embedding之后要乘以根号下d_model
-
原因1:为了防止position encoding的信息覆盖我们的word embedding,所以进行一个数值增大
-
原因2:符合标准正态分布
2.1.2 位置编码器
因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
位置编码器实现方式:三角函数来实现的,sin\cos函数
为什么使用三角函数来进行位置编码:
1、保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化
2、正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算
3、三角函数能够很好的表达相对位置信息
2.2 编码器部分
编码器由N个编码器层组成
1、每个编码器层由两个子层连接结构
2、第一个子层连接结构:多头自注意力机制层+残差连接层+规范化层
3、第二个子层连接结构:前馈全连接层+残差连接层+规范层
2.2.1 掩码张量
掩码:掩就是遮掩、码就是张量。掩码本身需要一个掩码张量,掩码张量的作用是对另一个张量进行数据信息的掩盖。一般掩码张量是由0和1两种数字组成,至于是0对应位置或是1对应位置进行掩码,可以自己设定
掩码分类:
PADDING MASK: 句子补齐的PAD,去除影响
位置:编码器的自注意力层(Self-Attention),编码器-解码器注意力层
SETENCES MASK:解码器端,防止未来信息被提前利用
位置:解码器的自注意力层
2.2.2 注意力机制
自注意力机制,规则:Q乘以K的转置,然后除以根号下D_K,然后再进行Softmax,最后和V进行张量矩阵相乘
多头自注意力机制介绍
将模型分为多个头, 可以形成多个子空间, 让模型去关注不同方面的信息, 最后再将各个方面的信息综合起来得到更好的效果.
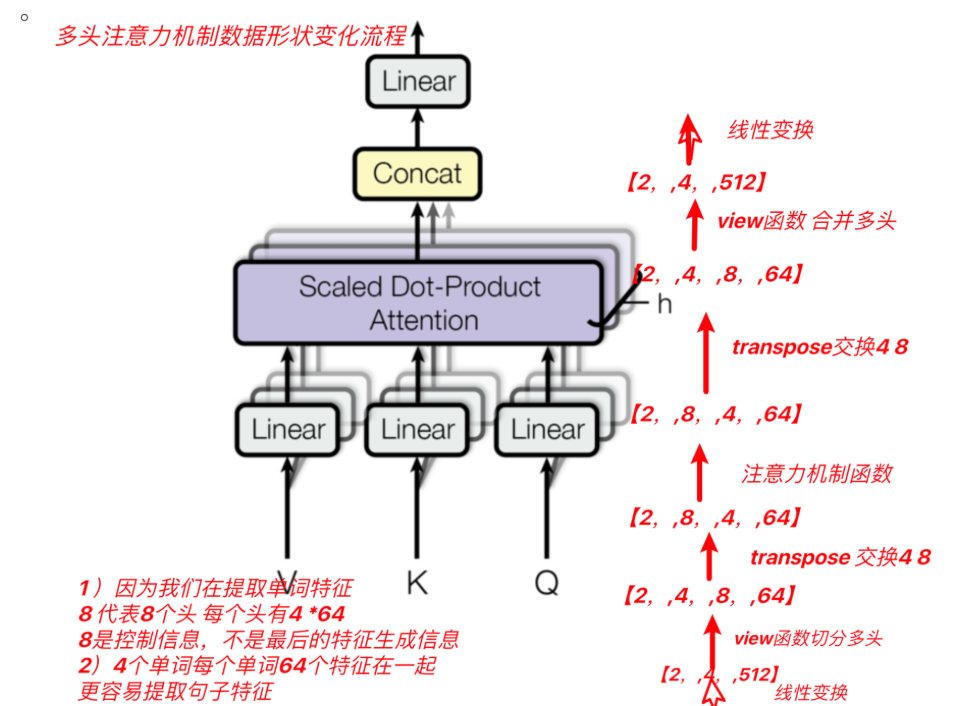
在这里QKV是先经过三个不同的linear层,再分多头,然后每个头的QKV进行注意力计算再拼接,最后经过一个linear层
2.2.3 前馈全连接层
前馈前连接层其实就是俩线性层,俩linear,作用是增强模型的拟合能力
2.2.4规范化层
作用:随着网络深度的增加,模型参数会出现过大或过小的情况,进而可能影响模型的收敛,因此进行规范化,将参数规范致某个特征范围内,辅助模型快速收敛。作用原理就是一些列的数学计算,使得向量规范.
2.2.5 子层连接结构
- 如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.
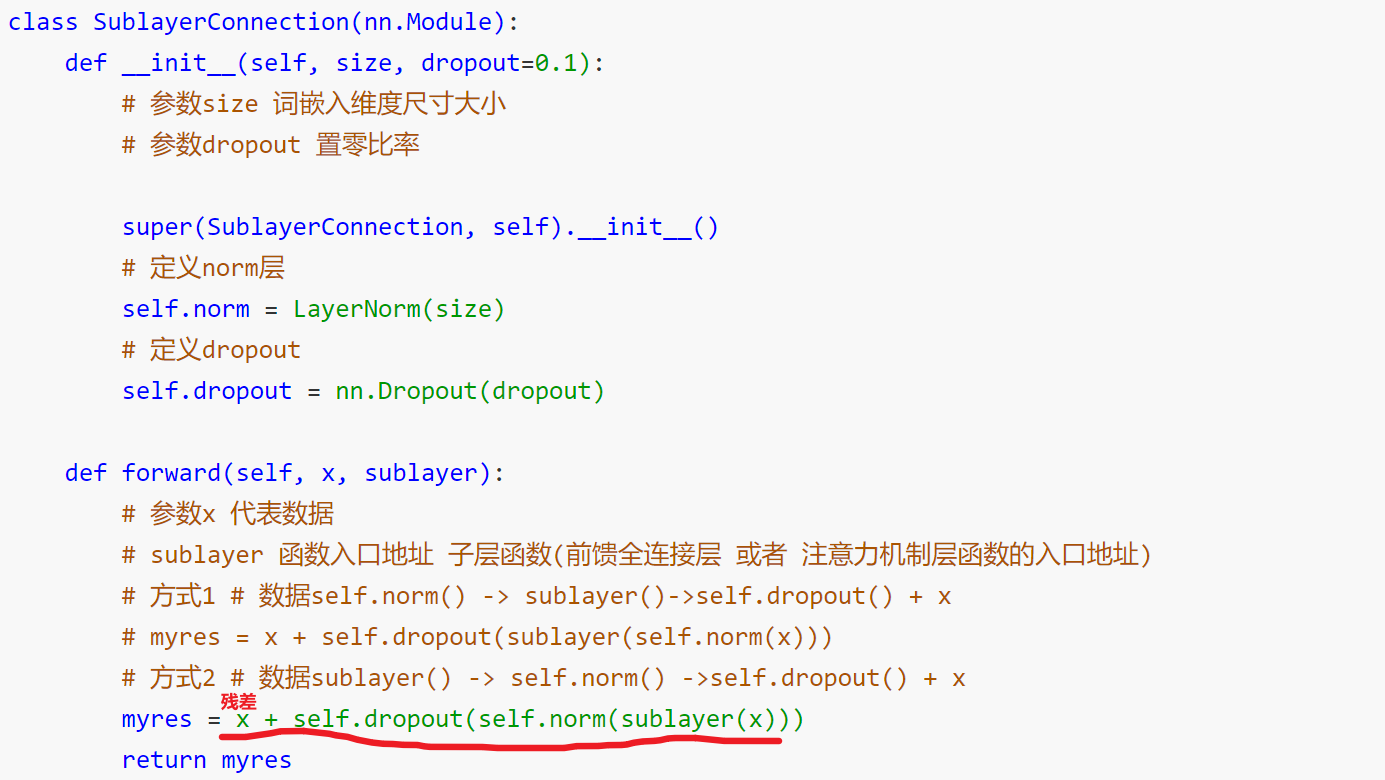
在这里残差链接的作用就是引入加法防止梯度消失
2.3 解码器部分
解码器构成:
- N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构:多头自注意力(masked)层+ 规范化层+残差连接
- 第二个子层连接结构:多头注意力层+ 规范化层+残差连接
- 第三个子层连接结构:前馈全连接层+ 规范化层+残差连接
与编码器的区别就在于多了第一个子层连接,他引入了SETENCES MASK用于防止未来信息被提前利用
2.4 输出部分
一个线性层linear,一个softmax层:作用:通过线性变化得到指定维度的输出,也就是预测的下一个词
注:这时候解码器的输入可以是上一步的输出预测的词,也可以是真实的词
3.可能的面试题
3.1 attention为什么使用多头?
- 表达能⼒增强:通过引⼊多个注意⼒头,每个头都可以关注不同的语义信息,从⽽能够捕捉更丰富的特征表示。不同的注意⼒头可以学习到不同的关注权重分布,帮助模型更好地理解输⼊序列 的不同部分。
- 模型泛化性能提升:通过多头机制,模型可以同时考虑多个关注粒度的信息。每个头可以关注序 列中的不同位置或不同的关系,使得模型能够处理不同尺度和不同层次的语义关系。这有助于提 ⾼模型在不同任务和不同数据集上的泛化性能。
- 抗噪能⼒增强:多头机制能够减少注意⼒机制中的随机性,因为每个头都可以专注于不同的注意 ⼒权重。这样可以降低模型对于噪声的敏感性,提⾼模型的鲁棒性和稳定性。
- 并⾏计算加速:注意⼒机制的计算通常是⾼度并⾏的,⽽多头注意⼒进⼀步增加了并⾏计算的程 度。多个注意⼒头可以同时计算,加快了模型的训练和推理速度。
3.2 transformer为什么⽤layer norm不⽤batch norm,解释下,什
么情况可以⽤batch norm?
-
序列⻓度变化:在Transformer中,输⼊序列的⻓度通常是可变的,因为它们可能具有不同数量的词语或位 置编码。Batch Normalization依赖于在每个批次中计算样本的均值和⽅差,⽽样本数⽬在不同的批次中是 不同的。这导致在每个批次上计算的均值和⽅差存在差异,这可能会影响模型的稳定性。相⽐之下,Layer Normalization是对每个样本的特征维度进⾏归⼀化,不依赖于批次,因此对序列⻓度的变化更加鲁棒。
-
训练和推断的⼀致性:在训练和推断过程中,Batch Normalization的⾏为是不同的。在训练时,Batch Normalization使⽤每个批次的均值和⽅差进⾏归⼀化,但在推断时,需要使⽤累计的整体均值和⽅差。这 意味着在推断过程中,需要记录每个批次的均值和⽅差,增加了推断的复杂性。相⽐之下,Layer Normalization的计算过程在训练和推断中是⼀致的,更加简单和可靠。
-
并⾏计算:Batch Normalization的计算涉及对每个特征维度的均值和⽅差进⾏计算,因此在处理序列时⽆ 法进⾏有效的并⾏计算。⽽Layer Normalization的计算是在特征维度上进⾏的,可以更好地⽀持并⾏计算, 因此在处理⻓序列时更加高效。
3.3 Add&norm层的作用?
- 归⼀化:通过对输⼊进⾏归⼀化操作,使得输⼊的均值和⽅差保持稳定,有助于加速模型的收敛和提⾼训 练效果。归⼀化可以缓解梯度消失和梯度爆炸等问题,提⾼模型的数值稳定性。
- 残差连接:Add Norm层通常与残差连接⼀起使⽤,⽤于将前⼀层的输出与当前层的输出相加。残差连接允 许信息在⽹络中直接传递,有助于缓解梯度消失、加速训练过程和提⾼模型的表达能⼒