文章目录
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
随着我国城市化进程不断推进,房地产市场已成为国家宏观调控和民众生活质量改善的重要领域之一。尤其在成都市这样的新一线城市,二手房交易市场活跃,数据体量庞大,房价波动频繁,对市场供需分析、购房者决策及政府调控均提出了更高的技术要求。本项目正是在这样的大背景下,围绕"如何有效地采集、分析、预测和可视化二手房房价数据"这一核心问题,构建了一套基于Hadoop平台的大数据分析与机器学习预测系统,兼顾实用性与智能化。
一、项目背景与研究意义
成都是我国西部地区重要的经济、交通、教育中心,近年来二手房交易量持续上涨,呈现出区域分布广、户型结构复杂、价格变动快等特点。链家等主流房产平台虽然提供了丰富的房源数据,但信息质量参差不齐、结构不统一、更新频率高等问题使得数据分析难度增加。同时,房地产数据的高维度与大体量也对传统数据处理和建模手段提出挑战。因此,开发一套具备高并发采集、高效处理、智能分析能力的系统已成为行业刚需。
本项目的实施,不仅可以帮助购房者更准确地评估心仪房源的市场价值,辅助业主合理定价,降低交易摩擦,还可为政府部门提供区域房价的多维动态数据支持,为政策调控、城市规划提供参考依据,具有现实意义和推广价值。
二、技术架构与系统设计
项目系统采用B/S架构,整体分为数据采集层、数据存储层、数据分析层、模型预测层和Web应用层五个部分:
- 数据采集层:使用Python开发高鲁棒性网络爬虫,模拟用户行为从链家官网持续爬取成都市11个主城区的二手房信息,最终获取逾3万条房源数据。针对反爬机制,设计了动态请求头、延时策略、异常捕获和邮件提醒等机制,有效解决了跨区数据抓取难题。
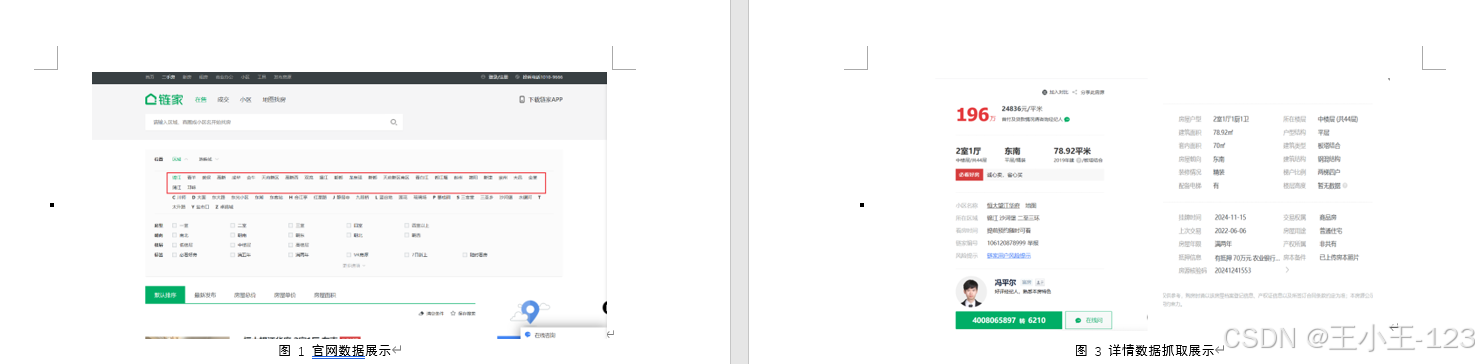
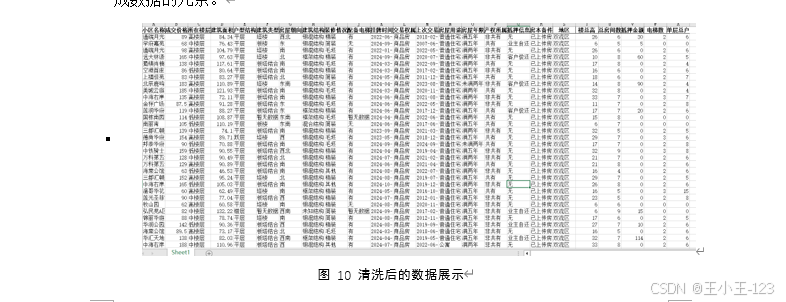
- 数据预处理层:利用Pandas、正则表达式等工具对原始数据进行去重、字段清洗、格式统一、数值提取、异常处理及标准化。例如对"建筑面积"、"梯户比例"、"抵押信息"等字段进行精细清洗,提升了数据质量与后续分析的稳定性。
- 数据存储与分析层:搭建完整的Hadoop生态系统(包括HDFS、Hive、Sqoop、Flume等),通过Flume监听爬虫数据并实时导入HDFS,再通过Hive构建数据表进行分析查询。同时,借助Sqoop将分析结果导出至MySQL数据库,便于可视化与系统接口调用。

-
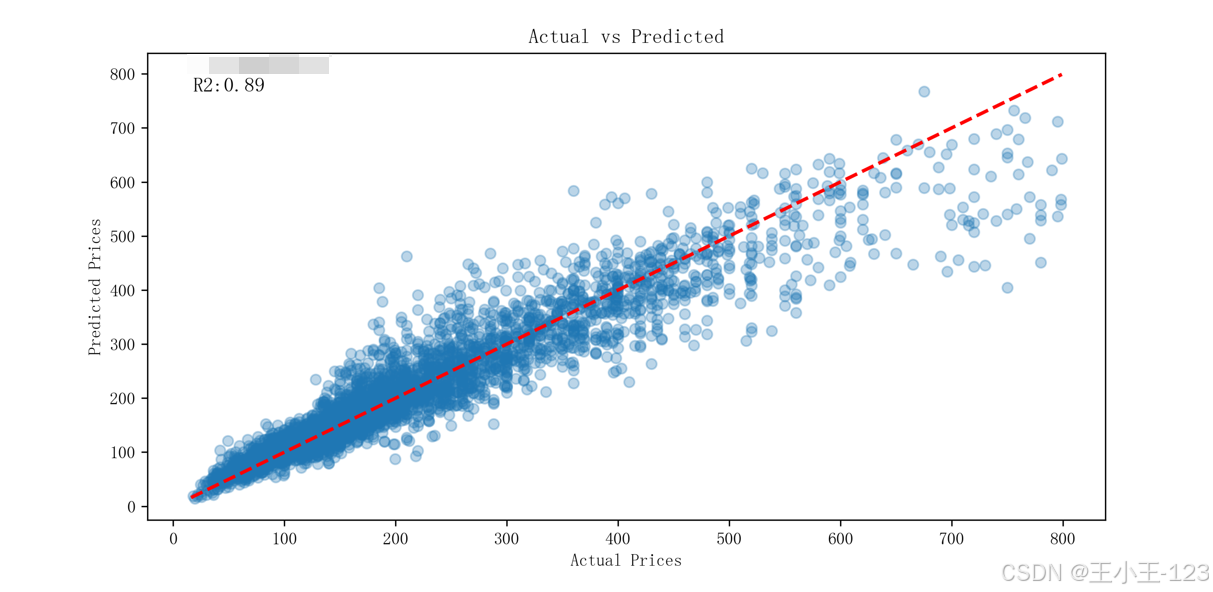
机器学习预测层 :选用CatBoost回归模型,针对清洗后的高质量数据进行训练与评估。该模型原生支持类别特征,无需编码,适用于房地产数据这种结构复杂的场景。在测试集中取得R²达0.89的优秀预测表现,并通过Joblib保存模型用于系统调用。

-
Web可视化应用层 :采用Python Flask框架搭建系统后端,前端使用Layui和ECharts等技术构建图表展示和用户交互界面。支持普通用户与管理员的角色区分,前者可查看数据分析结果、进行房价预测,后者可管理房源数据和用户信息,实现完整的权限管理体系。
三、核心功能与应用价值
本系统围绕成都市二手房市场需求,设计了如下核心功能模块:
-
房价多维可视化分析
系统支持对房价在建筑类型、户型结构、楼层、用途、装修情况、抵押状态、小区分布等多个维度的可视化统计分析。通过图表直观展现市场价格规律,辅助用户了解整体市场走向与个别小区差异。
-
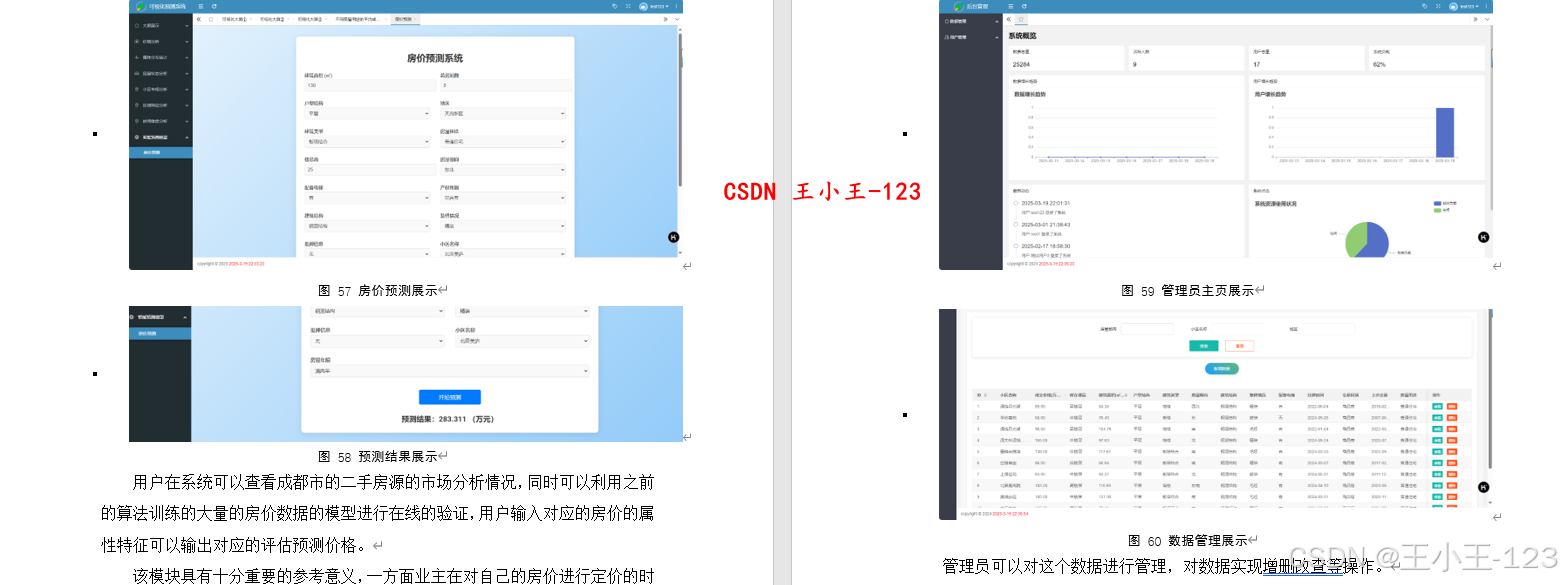
智能预测与价格评估
用户输入房源关键信息(如面积、户型、小区名称等),系统将通过CatBoost模型实时预测其市场参考价格,作为定价或购房依据。模型训练基于近3万条本地化真实数据,预测精度高,落地效果好。
-
数据管理与权限控制
管理员可对房源信息进行增删改查,并具备用户权限审核、升级管理功能,实现系统数据的持续维护与用户体验优化。
-
一体化系统集成
将大数据分析、机器学习模型和Web应用集于一体,构建了完整、实用、智能化的房价分析平台,具有良好的可扩展性与迁移能力,可为其他城市或行业提供模板。
四、实验与测试成果
在系统部署后,进行了全面的功能测试与数据验证,具体成果包括:
- 成功采集11个区域共超3万条二手房数据,结构统一,字段丰富;
- Hive分析实现房价在多个维度下的统计建模,揭示房屋物理属性对价格影响最显著;
- 预测模型表现优异,测试集R²为0.89;
- Web端交互良好,响应迅速,页面支持动态图表与预测结果展示;
- 管理员模块稳定运行,支持数据与权限的动态管理。
结语
本项目通过整合Hadoop大数据平台、CatBoost机器学习算法及Flask Web应用技术,成功搭建了一套面向成都市二手房市场的数据分析与智能预测系统。项目不仅在技术实现上展现出良好的稳定性和实用性,更在数据应用层面提供了切实可行的价值服务。未来,系统仍具备广阔的优化与推广潜力,为智慧城市、房地产信息化发展贡献力量。



每文一语
当一个人的财富拥有到极限,他就会倍加珍惜时间;普通人的时间弹指间,却丝毫没有感觉