前言
本文是个人对大模型、智能体等知识点的汇总,力求尽可能的覆盖知识点,以建立初步认知;
技术演进关系
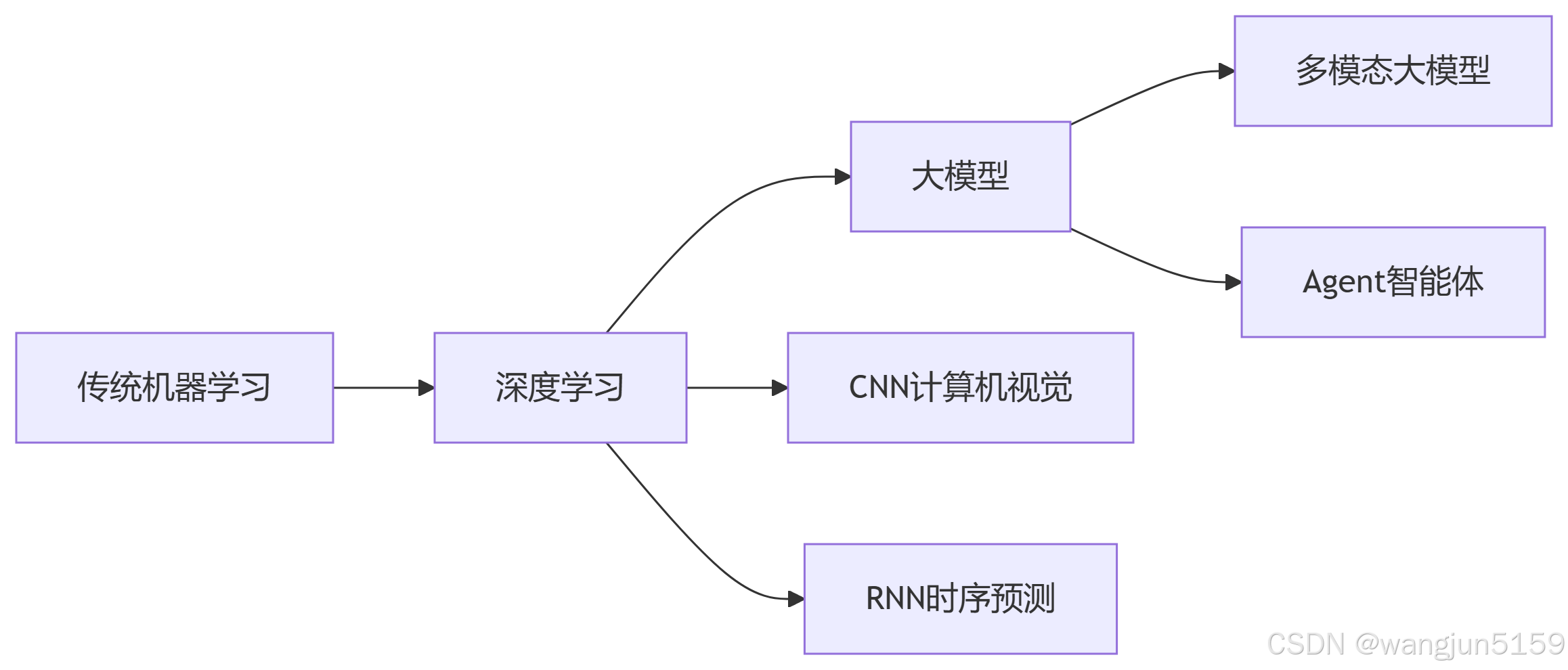
机器学习
机器学习的原理就是通过算法,让计算机能够从大量的数据中发现规律,然后做出预测或者决策。比如,通过分析过去的销售数据,机器学习可以帮助我们预测未来哪个产品会大卖。
深度学习
深度学习是机器学习的一个分支,通常指的是模仿人类大脑皮层,自动提取特征;最常见的深度学习有CNN、RNN、GNN
- 卷积神经网络(CNN=Convolutional Neural Network),CNN在图像识别领域特别厉害,它能够自动从图像中学习到有用的特征,而不需要人工去设计特征。
- 以 卷积操作(Convolution) 为核心,通过卷积核(Filter)在输入数据(一般是图像)上滑动以提取局部特征,层层深入获取高级语义信息。
- 对 图像识别、目标检测、自然语言处理(词向量局部化处理) 等有出色表现。
- 循环神经网络(RNN=Recurrent Neural Network,),RNN则擅长处理序列数据,比如语音或者文本,它能够记住之前的信息,这对于理解上下文特别重要。
- 在序列数据上表现优异,通过 隐藏状态(Hidden State) 实现对历史信息的"记忆",从而捕捉上下文依赖关系。
- 常用于 文本生成、机器翻译、语音识别 等序列任务。RNN 家族中比较著名的改进有 LSTM 和 GRU,长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式 。
- 图神经网络(GNN=Graph Neural Network)
- 针对 图结构数据(如社交网络、推荐系统中的用户关系、分子化学结构、知识图谱等)而设计,通过在图节点或边上进行消息传递、聚合,学习节点或整个图的表征。
- 近年来在 社交分析、推荐系统、药物分子发现、知识图谱 等领域崛起,被广泛研究和应用。
迁移学习、强化学习、监督学习、无监督学习 与 深度学习、机器学习 的关系解析
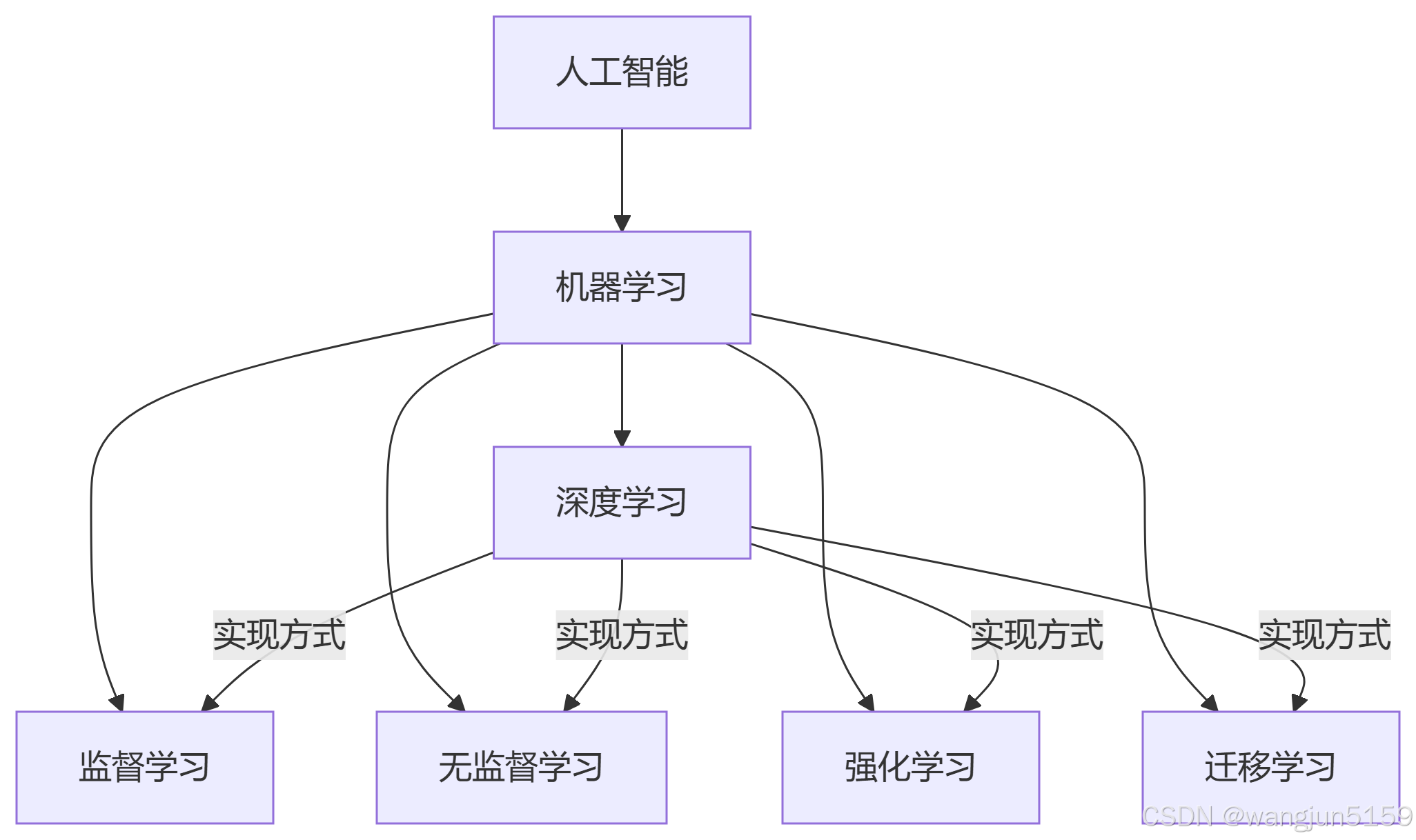
-
深度学习:一种实现机器学习的技术(基于神经网络),可服务于所有学习范式。
-
其他四者:属于机器学习的方法论,既可用传统算法实现,也可用深度学习实现。
监督学习(Supervised Learning)
核心思想:通过标注数据(输入-输出对)学习模型,预测未知数据的输出。
关键点:
-
需要大量带标签的数据。
-
模型学习输入特征与标签之间的映射关系。
典型任务:
-
分类(输出离散类别,如图像识别)。
-
回归(输出连续值,如房价预测)。
常见算法:
- 线性回归、逻辑回归、决策树、支持向量机(SVM)、神经网络等。
无监督学习(Unsupervised Learning)
核心思想:从无标签数据中发现隐藏模式或结构。
关键点:
-
无明确的目标输出,依赖数据内在关系。
-
常用于探索性数据分析。
典型任务:
-
聚类(将相似数据分组,如客户分群)。
-
降维(减少数据维度,如PCA)。
-
异常检测(识别异常点)。
常见算法:
- K-Means、层次聚类、DBSCAN、主成分分析(PCA)、自编码器等。
强化学习(Reinforcement Learning, RL)
核心思想:智能体通过与环境交互学习策略,以最大化累积奖励。
关键点:
-
通过试错(trial-and-error)学习。
-
反馈延迟(奖励可能滞后于动作)。
核心要素:
- 状态(State)、动作(Action)、奖励(Reward)、策略(Policy)。
典型应用:
- 游戏AI(如AlphaGo)、机器人控制、自动驾驶。
常见算法:
- Q-Learning、深度Q网络(DQN)、策略梯度(Policy Gradient)、PPO等。
迁移学习(Transfer Learning)
核心思想:将已训练模型的知识迁移到新任务,解决数据或算力不足问题。迁移学习,是复用已有学习成果,快速学习新领域的本领,语音识别也是迁移学习的热门应用领域。通过在一个大规模的语音数据库上训练好的模型,可以迁移到新的方言或者口音的识别上,大大提高了识别的准确性和效率。总的来说,迁移学习就像是给了机器一个"快速学习"的能力,让它们能够在新任务上迅速上手,减少了从头开始学习的时间和精力。这种能力在数据稀缺或者任务复杂的情况下尤其宝贵。
关键点:
-
源任务(Source Task)与目标任务(Target Task)需有一定关联。
-
通常复用预训练模型的底层特征(如神经网络的前几层)。
典型场景:
-
小样本学习(如医疗图像分析)。
-
跨领域迁移(如将自然语言处理的BERT模型用于金融文本分类)。
常见方法:
- 微调(Fine-tuning)、特征提取、多任务学习等。
LLM(large language model)
大模型是指参数量达到 十亿级(Billion)甚至万亿级(Trillion) 的深度学习模型,基于海量数据预训练,具备通用任务处理能力;具有强大的认知、推理能力,主要的大模型有通义千问、文心一言、deepseek、chatgpt
关键特征:
- 规模定律(Scaling Laws):性能随参数/数据量增加而显著提升
- 涌现能力(Emergent Abilities):在超大规模下突然获得的新能力(如逻辑推理)
- 统一架构:多任务共享同一模型(如Transformer)
LLM vs 传统模型
| 对比维度 | 大模型(如GPT-4) | 传统机器学习(如SVM) |
|---|---|---|
| 定义 | 超大规模参数(十亿+)的预训练通用模型 | 针对特定任务的小规模专用模型 |
| 数据需求 | TB级未标注文本/多模态数据 | GB级标注结构化数据 |
| 计算资源 | 千张GPU集群(千万美元级成本) | 单机CPU/GPU(百美元级成本) |
| 训练方式 | 自监督学习+微调 | 监督学习/特征工程 |
| 能力特点 | 零样本学习、多任务泛化 | 高精度但需任务定制 |
| 典型应用 | 对话生成、跨模态搜索 | 金融风控、工业质检 |
| 优缺点 | ✅通用性强 ❌黑箱性严重 | ✅可解释性强 ❌迁移能力差 |
模态
模态就是大语言模型识别的格式,比如识别文本、图片、音频、视频;如果大模型只能识别一种模式,就叫单模态;如果能识别多种格式,就叫多模态;
生成器
生成式人工智能在各种任务中的出色表现开启了 AIGC(人工智能生成内容)时代。生成模块在 RAG 系统中起着至关重要的作用。不同的生成模型适用于不同的场景,例如用于文本到文本任务的 Transformer 模型、用于图像到文本任务的 VisualGPT、用于文本到图像任务的 Stable Diffusion,以及用于文本到代码任务的 Codex 等 。生成器的基础技术包括 Transformer 模型、长短期记忆网络(LSTM)、扩散模型和生成对抗网络(GAN)。
Transformer
Transformer模型是一种用于处理语言数据的神经网络模型,非常适合用于翻译、文本生成和理解等任务。由自注意力机制、前馈网络、层规范化模块和残差网络组成 。
- 扩散模型是一类深度生成模型,可以创建真实且多样化的数据样本(包括图像、文本、视频等。
生成对抗网络(GAN)是备受期待的深度学习模型,可以模拟和生成逼真的图像、音频和其他数据。
RAG vs 微调
预训练的 LLM 可能存在知识截止、容易产生幻觉(编造事实)以及缺乏特定领域深度知识等问题。为了克服这些局限性,并使 LLM 更适应特定任务和场景,检索增强生成 (RAG) 和微调 (Fine-tuning) 是两种主流且有效的技术。rag是通用的,适用于多种任务;微调就是使用特定数据精调试,取决于数据的质量;
检索器
检索是在给定信息需求的情况下识别和获取相关信息。具体来说,让我们考虑可以概念化为键值存储的信息资源,其中每个键对应一个值(键和值可以相同)。给定一个查询,目标是使用相似度函数从数据库中选取最相似的键,并得到配对的值。根据不同的相似度函数,现有的检索方法可以分为稀疏检索、密集检索和其他方法 。
- 稀疏检索方法通常用于文档检索,其中键/值表示要搜索的文档。这些方法利用术语匹配指标,例如 TF-IDF,查询可能性;
- BM2.5分析文本中的单词统计数据并构建倒排索引以实现高效搜索 。
- 密集检索方法使用密集嵌入向量表示查询和键,并构建近似最近邻 (ANN) 索引以加快搜索速度 。
LangChain
LangChain 是一个用于构建基于大语言模型(LLM)的应用程序的框架,旨在简化将 LLM 与外部数据源、工具和逻辑集成的过程。它的核心作用是增强和扩展大模型的能力,使其更适应实际应用场景。
RAG流程
RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的混合型AI技术,它通过从外部知识库中检索相关信息来增强生成模型的能力。简单来说,就是先将结构化和非结构化的数据,向量化存储到向量数据库,作为一个知识库,再结合原始输入,输入到大模型,提高检索质量。
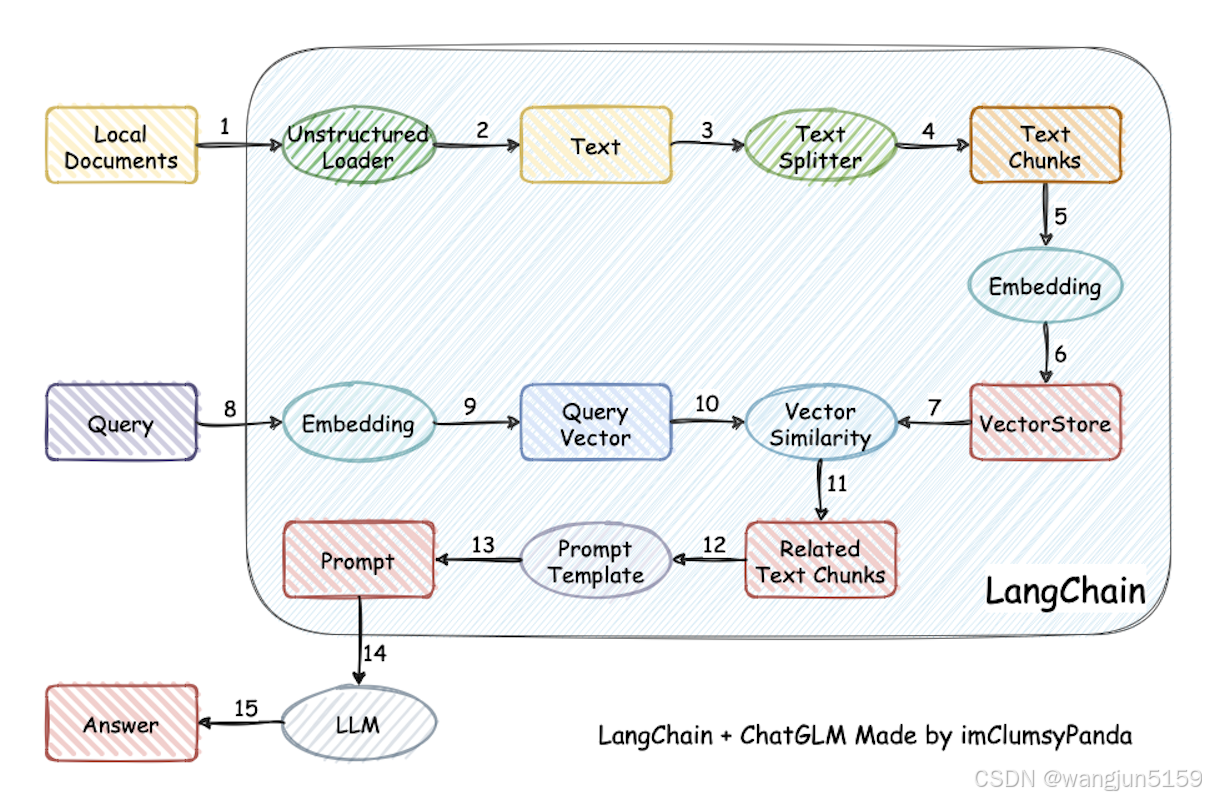
向量化
- 文本加载
- 文本分割
- 文本向量化
- 存储到向量库
- 分词器
- 比如按照空格分词,这种适合英语
- 按照语义分词,这种适合汉语
- 受限于大模型能力,还可以按照token数分词?
- 关键词检索
- 相当于直接匹配,比如搜索苹果两个字,只搜索字面意思,apple搜索不出来,比如elasticsearch、sql查询
- 向量检索
- 按照相似度搜索,比如输入苹果或者apple,能通过上下文判断是水果苹果还是苹果公司,常见的向量库搜索
- 混合检索
- 在实际应用中,关键词搜索和向量搜索,可结合使用;先通过关键词搜索搜索出top k,然后通过向量搜索
- 重排序
- 分步思考?
function call vs mcp
- function call,大模型开放的api,与大模型厂商密切相关,api因厂商、模型不同而不同
- mcp,model context protocol,用来屏蔽大模型的差异,可使用统一接口调用大模型
其它
- tensorflow和pytorch是用来训练大模型的工具,大模型的核心是transformer,支持分布式训练;
- 常见AI编程工具: cursor、windsurf 、trae
- 练手项目llm-universe
- anthropic出品的building-effective-agents
- ragflow 做知识库检索不错的方案
- coze、dify
- Ollama是开源跨平台大模型工具,大模型本地化部署工具