目录
[如何使用手肘法 ?](#如何使用手肘法 ?)
[计算不同 k 的 SSE](#计算不同 k 的 SSE)
[绘制SSE随 k 变化的曲线](#绘制SSE随 k 变化的曲线)
[找曲线拐点对应的 kk 即为最优聚类数](#找曲线拐点对应的 kk 即为最优聚类数)
鸢尾花聚类
提取数据,转化格式
python
# 以下代码是导入这个数据集
# 注意data返回的是一个字典
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
data = load_iris()
data
python
#输入的类型是字典,因此我们需要转换类型
x=data['data']
y=data['target']
iris=pd.DataFrame(x,columns=['sepal_length','sepal_width','petal_length','petal_width'])
iris['target']=y以前两个特征为例分析,对数据进行标准化
python
#提取数据(以前两列为例)
X = iris[['sepal_length','sepal_width']]
#标准化(因为特征之间可能有不同的量纲,但是每个特征都应该平等)
Xstd = (X - X.mean()) / X.std()确定K值
手肘法
python
from sklearn.cluster import KMeans
#使用手肘法确定K值
#存储所有样本的簇内距离平方求和(与簇内中心的欧式距离)
result_list = []
#假设我们的类别是2-11(没有1,因为只有一个簇的话没有意义)
for i in range(2,12):
#新建聚类模型,递增我们的聚类中心个数
model = KMeans(n_clusters = i,random_state = 1)
#训练一模型
model.fit(Xstd)
#取出样本的簇内距离平方求和
result_list.append(model.inertia_)
python
#画手肘图
import matplotlib.pyplot as plt
xs = list(range(2,12))
plt.plot(xs, result_list)
plt.xticks(xs)
plt.show()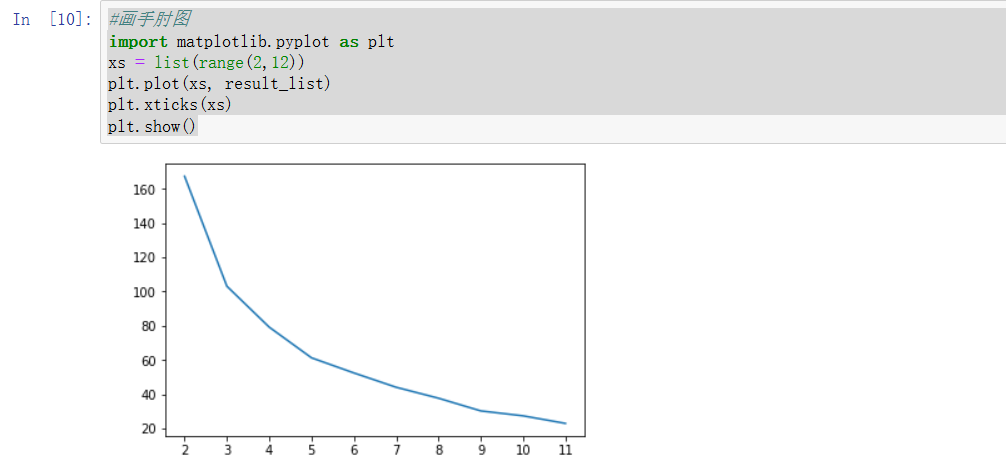
显然在3的时候,斜率变缓了,说明sse是簇内各点到簇内中心的距离明显的斜率变缓,因此K=3
轮廓系数
python
from sklearn import metrics
for i in range(2,12):
#新建聚类模型,改变我们的聚类中心个数
mode2 = KMeans(n_clusters = i,random_state = 1)
#训练一下模型
mode2.fit(Xstd)
#获取kmeans聚类的结果
labels = mode2.labels_
#print(labels)
#得到轮廓系数
res = metrics.silhouette_score(Xstd,labels)
print(i,'的轮廓系数:',res)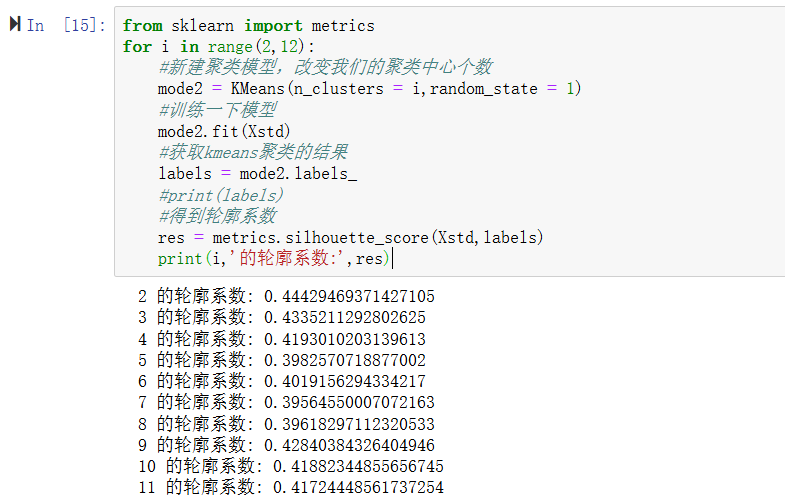
可见2和3的轮廓系数偏大,综合手肘图选择K=3
绘制散点图
python
#新建聚类数为3的聚类模型
model_final = KMeans(n_clusters = 3,random_state = 1)
#训练模型
model_final.fit(Xstd)
#获取kmeans聚类的结果
labels = model_final.labels_
iris['labels'] = labels
iris
python
#聚类的结果散点图
for label in list(set(list(iris['labels']))):
df = iris[iris['labels'] == label]
plt.plot(df['Sepal.Length'],df['Sepal.Width'],'o',label = label)
plt.legend()
plt.show()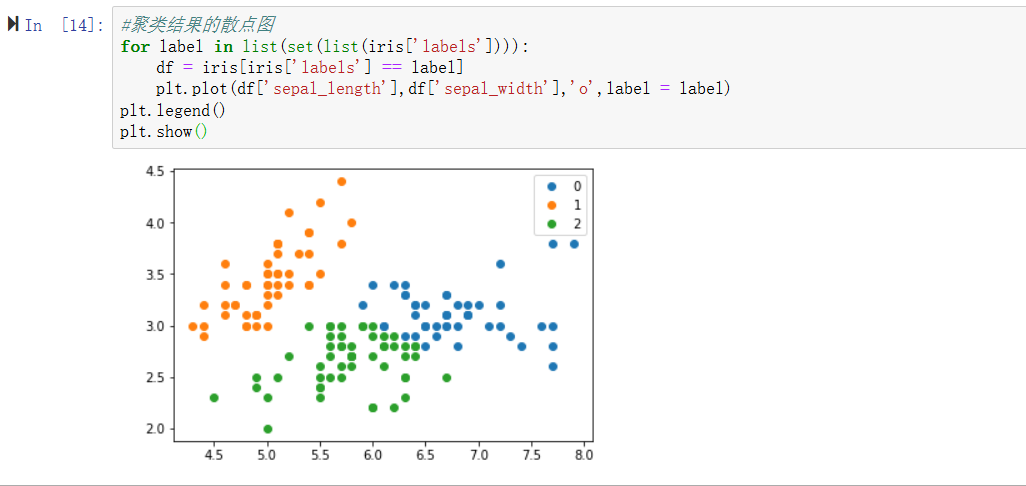
python
#真实数据的结果散点图
for label in list(set(list(iris['target']))):
df = iris[iris['target'] == label]
plt.plot(df['sepal_length'],df['sepal_width'],'o',label = label)
plt.legend()
plt.show()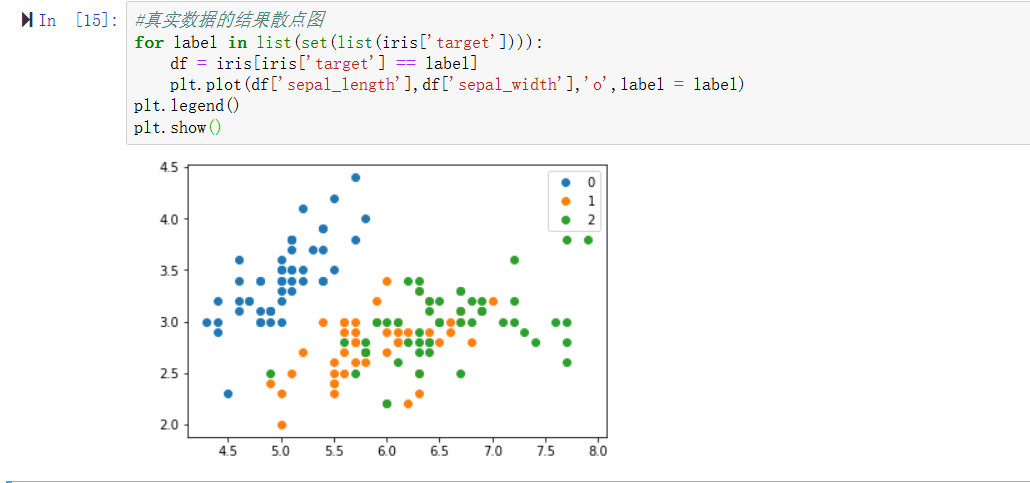
可以看出聚类的结果还是可以的
总结:
类型转化
因为原数据是字典类型,所以我们需要先转化类型为DataFrame
iris=pd.DataFrame(x,columns='sepal_length','sepal_width','petal_length','petal_width')
标准化
标准化是什么?

为什么要标准化?

手肘法
手肘法是什么?

如何使用手肘法 ?
计算不同 k 的 SSE
对 k从1到预设最大值(如10),分别运行K-Means并记录SSE。
绘制SSE随 k 变化的曲线
找曲线拐点对应的 kk 即为最优聚类数
轮廓系数
轮廓系数是什么?
衡量分离性和紧密度


在确定K值得时候,先用手肘法,然后再求轮廓系数,综合选取K