1.一个数量庞大的issue集合,包含了标题和描述等各种属性,有的issue有label标注,但是大部分没有label。现在需要根据拥有label的少量样本数据进行训练,预测没有标注的数据可能的label。
2.第一步:先准备数据。数据可以去这里下载
每一条数据都包含了如下属性:
arduino
"url", "title", "body", "labels", "id", "user","state","created_at"但是,并不是每一条数据的labels都有值。
3.有了数据之后,先查看一下数据的基本格式,并查看数据标注的分布:
python
df_issues = pd.read_json("./data.jsonl", lines=True)
print(df_issues.shape)
cols=["url", "title", "body", "labels", "id", "user","state","created_at"]
df = df_issues.loc[2,cols].to_frame()
print(df)
df_issues["labels"] = (df_issues["labels"].apply(lambda x: [meta["name"] for meta in x]))
print(df_issues["labels"].head())
count = df_issues["labels"].apply(lambda x: len(x)).value_counts().to_frame().T
print(count)
label_counts = df_issues["labels"].explode().value_counts()
print(f"number of labels: {len(label_counts)}")
labels = label_counts.to_frame().head(10).T
print(labels)
label_map = {"Core: Tokenization": "tokenization",
"New model": "new model",
"Core: Modeling": "model training",
"Usage": "usage",
"Core: Pipeline": "pipeline",
"TensorFlow": "tensorflow or tf",
"PyTorch": "pytorch",
"Examples": "examples",
"Documentation": "documentation"}
def filter_labels(x):
return [label_map[label] for label in x if label in label_map]
df_issues["labels"] = df_issues["labels"].apply(filter_labels)
all_labels = list(label_map.values())
print(all_labels)
df_counts = df_issues["labels"].explode().value_counts().to_frame().T
print(df_counts)4.给数据创建一个新列,区分数据是否有标注:
python
df_issues["split"] = "unlabeled"
mask = df_issues["labels"].apply(lambda x: len(x))>0
df_issues.loc[mask, "split"] = "labeled"
new_col = df_issues["split"].value_counts().to_frame()
print(new_col)
for column in ["title","body","labels"]:
print(f"{column} : {df_issues[column].iloc[26][:500]}")
df_issues["text"] = df_issues.apply(lambda x:x["title"] + "\n\n" + x["body"], axis=1)5.去掉数据中重复的条目,并使用可视化工具查看数据中body的分布情况:
python
len_before = len(df_issues)
df_issues = df_issues.drop_duplicates(subset="text")
print(f"Removed {len_before - len(df_issues)} duplicate rows")
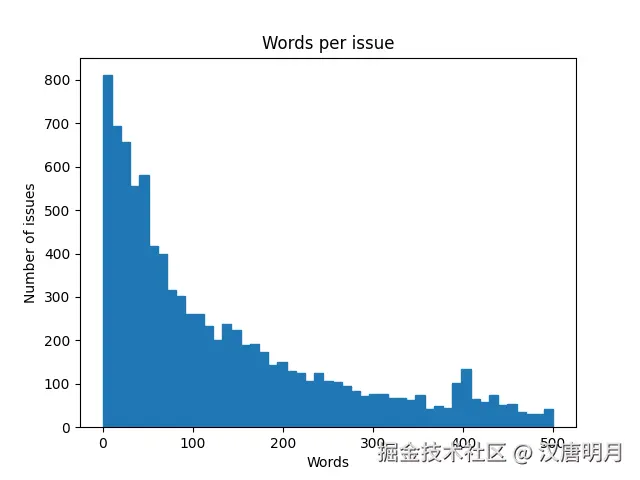
df_issues["text"].str.split().apply(len).hist(bins=np.linspace(0,500,50), grid=False, edgecolor="C0")
plt.title("Words per issue")
plt.xlabel("Words")
plt.ylabel("Number of issues")
plt.show()数据中text列的分布符合长尾特征。
 ### 6.清洗数据,创建训练集和测试集
### 6.清洗数据,创建训练集和测试集
python
mlb = MultiLabelBinarizer()
mlb.fit([all_labels])
one_hot = mlb.transform([["tokenization", "new model"],["pytorch"]])
print(one_hot)
def balanced_split(df, test_size=0.5):
ind = np.expand_dims(np.arange(len(df)), axis=1)
labels = mlb.transform(df["labels"])
ind_train, _, ind_test, _ = iterative_train_test_split(ind, labels, test_size=test_size)
return df.iloc[ind_train[:,0]], df.iloc[ind_test[:,0]]
df_clean = df_issues[["text", "labels", "split"]].reset_index(drop=True).copy()
df_unsup = df_clean.loc[df_clean["split"] == "unlabeled", ["text", "labels"]]
df_sup = df_clean.loc[df_clean["split"] == "labeled", ["text", "labels"]]
np.random.seed(0)
df_train, df_tmp = balanced_split(df_sup, test_size=0.5)
df_valid, df_test = balanced_split(df_tmp, test_size=0.5)7.准备训练切片,并开始训练,可视化不同切片数量下的训练指标:
python
# 1. 准备训练切片(不同样本量)
train_slices = [100, 500, 1000, 2000, len(df_train)] # 定义不同的训练样本量
frac_slices = [0.1, 0.2, 0.32, 0.5, 0.8]
results = []
# 2. 文本向量化(全局拟合,避免数据泄漏)
vectorizer = CountVectorizer(max_features=5000, stop_words="english")
X_all = vectorizer.fit_transform(df_clean["text"])
mlb = MultiLabelBinarizer()
mlb.fit([all_labels])
classifier = BinaryRelevance(classifier=MultinomialNB())
# 3. 遍历不同训练样本量
for i in range(len(frac_slices)):
# 随机选择子集(保持类别平衡)
df_slice = df_train.sample(frac=frac_slices[i])
# 转换为模型输入格式
X_train = vectorizer.transform(df_slice["text"])
y_train = mlb.transform(df_slice["labels"])
# 测试集保持不变
X_test = vectorizer.transform(df_test["text"])
y_test = mlb.transform(df_test["labels"])
# 4. 训练朴素贝叶斯模型
classifier.fit(X_train, y_train)
# 5. 预测并计算F1分数
y_pred = classifier.predict(X_test)
f1 = f1_score(y_test, y_pred, average="micro") # 使用micro平均处理多标签
slice_size = len(df_train)*frac_slices[i]
results.append({
"train_size": slice_size,
"f1_score": f1
})
print(f"Train size: {slice_size}, F1: {f1:.3f}")
print("\nFinal Classification Report (Full Training Set):")
print(classification_report(
y_test,
classifier.predict(X_test),
target_names=mlb.classes_,
zero_division=0
))
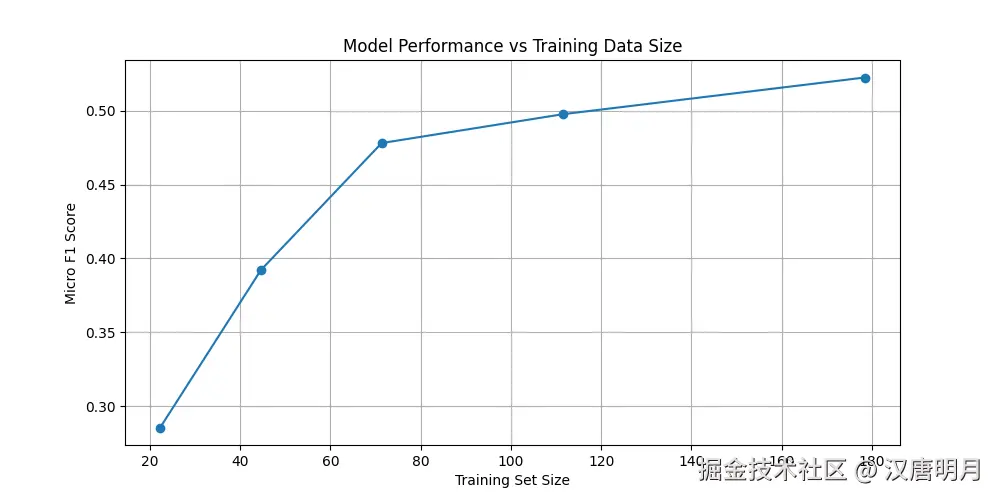
# 6. 可视化结果
results_df = pd.DataFrame(results)
plt.figure(figsize=(10, 5))
plt.plot(results_df["train_size"], results_df["f1_score"], marker="o")
plt.xlabel("Training Set Size")
plt.ylabel("Micro F1 Score")
plt.title("Model Performance vs Training Data Size")
plt.grid(True)
plt.show()f1分数根据不同切片数量的分布如下图:
 ### 8.自定义数据进行预测验证:
### 8.自定义数据进行预测验证:
python
sample_texts = [
"Tokenizer throws error with special characters",
"How to fine-tune BERT with PyTorch?"
]
sample_vec = vectorizer.transform(sample_texts)
sample_pred = mlb.inverse_transform(classifier.predict(sample_vec))
print("\nSample Predictions:")
for text, labels in zip(sample_texts, sample_pred):
print(f"Text: {text[:60]}... -> Labels: {labels}")