一、语法陷阱
1. 参数求值顺序陷阱
c
int i = 5;
printf("%d %d %d", i++, i, ++i);标准解析:
-
未定义行为(UB):函数参数求值顺序未指定
-
可能输出:
5 6 7(GCC) 或7 7 7(Clang) -
违反序列点规则:同一序列点内多次修改同一变量
我的理解:
就像让三个人同时报数但没规定谁先开口,结果会混乱。逗号只是分隔符不是指令,CPU可能从右向左或乱序处理表达式。
2. 结构体大小计算
c
#pragma pack(1) // 关键指令!
struct {
char a; // 1字节
double b; // 8字节
short c; // 2字节
} s;标准解析:
-
有
#pragma pack(1):大小=1+8+2=11字节(这个命令是禁用内存对齐) -
无pack时:24字节(填充7字节对齐double+6字节结构体对齐)
-
内存对齐原理:CPU按块读取内存(如8字节块)
实际编译器行为对比:
| 类型 | C语言 (标准) | C语言 (GCC扩展) | C++语言 |
|---|---|---|---|
| 空结构体 | 非法 | 0字节 | 1字节 |
| 空联合体 | 非法 | 0字节 | 1字节 |
内存对齐总结表
| 特性 | C语言 | C++语言 |
|---|---|---|
| 空结构体/类 | 非法 | 1字节 |
| 空联合体 | 非法 | 1字节 |
| 空基类空间占用 | N/A | 可优化为0字节 |
| 默认对齐方式 | 自然对齐 | 自然对齐 |
#pragma pack 支持 |
是 | 是 |
alignas 关键字 |
C11支持 | C++11支持 |
| 对齐查询 | _Alignof |
alignof |
我的理解:
像书架放书:小书(1cm)后放百科全书(8cm),必须从新格子开始,否则管理员要拆两格取书。pack就是允许塞满不留空。
3. 多次free的安全性
c
int *p = malloc(sizeof(int));
*p = 10;
free(p); // 第一次释放
p = NULL; // 关键置空!
free(p); // 第二次释放标准解析:
-
free(NULL)是安全的空操作(C标准明确允许) -
危险的是:首次free后未置空形成野指针
-
正确做法:free后立即置空
我的理解:
第一次拆房子后把地址牌摘掉(p=NULL),第二次拆"空地址"当然安全。不摘牌就是野指针------导航到已拆房屋会出事。
4. 字符字面量的本质
c
sizeof('a'); // 结果是什么?标准解析:
-
C语言中:字符字面量是
int类型 -
结果:
sizeof(int)(通常4字节) -
与C++区别:C++中
sizeof('a')=1(char类型)
我的理解:
C语言把'a'当作微型整数处理,就像小号行李箱仍占整个储物格(int大小)。C++则用精确尺寸包装。
5. 复杂声明解析
c
void (*fp)(int(*)());标准解析:
-
fp:函数指针 -
指向函数:返回
void,参数为函数指针 -
参数函数:返回
int,无参数 -
中文:fp是指向"参数为(返回int的无参函数指针)、返回void的函数"的指针
我的理解:
洋葱式解读:
(*fp):fp是指针
(int(*)()):指向接收函数指针的函数最内层
int():该函数指针指向返回int的无参函数
6. 指针常量 vs 常量指针
c
int *const ptr = &x; // 指针常量
*ptr = 20; // ✔ 可修改指向的值
ptr = &y; // ✘ 不可修改指针本身标准解析:
-
int *const:指针常量(枪固定靶可换) -
const int*:常量指针(靶固定枪可换) -
const int *const:双常量
我的理解:
指针常量:枪焊死在地上,但能打不同靶子
常量指针:靶子固定,但可用不同枪射击
7. 宏定义陷阱
c
#define SQUARE(x) x*x
SQUARE(a+1) // 展开为 a+1*a+1标准解析:
-
宏是简单文本替换,无运算优先级
-
正确写法:
#define SQUARE(x) ((x)*(x)) -
更佳方案:用内联函数替代
我的理解:
宏像无脑复印机:
SQUARE(手+苹果)→手+苹果*手+苹果= 手 + 苹果手 + 苹果(完全混乱)
8. 联合体的内存把戏
c
union {
int i;
float f;
} u;
u.f = 0.1f;
printf("%x", u.i); // 输出0x3dcccccd标准解析:
-
联合体共享内存空间(同地址不同解释)
-
输出的是0.1的IEEE 754二进制表示
-
非整数转换(是内存位模式转十六进制)
联合体基础知识
什么是联合体?
联合体(union)是C语言中一种特殊的数据类型,它允许在同一内存位置存储不同的数据类型。联合体的所有成员共享同一块内存空间。
联合体的特点:
-
内存共享:所有成员共享同一块内存
-
大小确定:联合体大小等于其最大成员的大小
-
同时只有一个成员有效:只能存储一个成员的值
-
类型转换:通过不同成员访问实现内存数据的类型转换
联合体声明语法:c
union 联合体名称 {
类型1 成员1;
类型2 成员2;
// ...
} 变量名;联合体 vs 结构体:
| 特性 | 联合体 (union) | 结构体 (struct) |
|---|---|---|
| 内存使用 | 所有成员共享同一内存 | 每个成员有自己的内存空间 |
| 大小 | 等于最大成员的大小 | 所有成员大小之和(含对齐) |
| 成员访问 | 同时只有一个成员有效 | 所有成员同时有效 |
| 主要用途 | 类型转换、节省内存 | 组织相关数据 |
关键点
-
类型双关(Type Punning):
-
通过不同成员访问同一内存实现类型转换
-
这是联合体的主要用途之一
-
-
字节序问题:
-
输出结果取决于系统的字节序(endianness)
-
小端系统:
3dcccccd(如x86处理器) -
大端系统:
cdcccc3d(某些网络设备)
-
-
精度问题:
-
0.1在二进制中是无限循环小数
-
实际存储的是近似值,这就是为什么:
c
0.1 + 0.2 != 0.3 // 浮点数精度问题
-
使用联合体的注意事项
-
成员覆盖:
-
给一个成员赋值会覆盖其他成员的值
-
只能同时"有效"一个成员
-
-
字节序问题:
-
不同系统可能有不同的字节序
-
影响多字节数据的解释方式
-
-
对齐要求:
-
联合体可能有内存对齐要求
-
使用
#pragma pack可控制对齐
-
-
类型安全:
-
C语言不检查访问的成员是否"正确"
-
需要程序员自己保证类型使用的正确性
-
我的理解:
同一碗水,物理老师说它是H₂O,化学老师说它是溶剂。联合体就是让不同"专家"解释同一块内存。
9. 数组指针偏移
c
int arr[5] = {1,2,3,4,5};
int *p = &arr[2];
printf("%d", p[2]); // 输出5标准解析:
-
p[2]等价于*(p+2) -
内存计算:
&arr[2] + 2*sizeof(int) = &arr[4] -
指针运算自动考虑类型大小
我的理解:
指针像地址计算器:
p[2]= 当前位置 + 2步(步长=数据类型大小)
10. volatile关键字的真义
标准解析:
-
作用:防止编译器优化(强制每次从内存读写)
-
使用场景:
-
硬件寄存器访问
-
多线程共享变量
-
信号处理程序中的变量
-
-
与const配合:
volatile const表示硬件只读寄存器
volatile 关键字核心知识点
-
核心作用:
-
禁止编译器优化:强制每次访问都从内存读写(不使用寄存器缓存)
-
防止编译器重排:确保声明顺序在编译后不变(但 CPU 仍可能乱序)
-
适用场景:
-
内存映射 I/O(硬件寄存器)
-
信号处理中的全局标志(
volatile sig_atomic_t) -
被异步修改的变量(如中断服务程序)
-
-
-
三大保证:
-
可见性:写入立即同步到主存
-
访问性:不被编译器优化消除
-
顺序性(仅编译器级) :编译器不重排
volatile操作顺序
-
-
不保证的行为:
-
❌ 原子性 :
volatile int a; a++;仍是非原子操作 -
❌ CPU 乱序:硬件仍可能重排指令
-
❌ 内存屏障:不阻止 Store Buffer 延迟写入
-
内存屏障核心知识点
-
为什么需要:
-
现代 CPU 的乱序执行(Out-of-Order Execution)
-
多核缓存一致性(Cache Coherence)问题
-
编译器优化导致指令重排
-
-
屏障类型:
屏障类型 作用 示例指令 编译器屏障 阻止编译器重排指令 asm volatile("" ::: "memory")读屏障 确保屏障前读操作先完成 ARM: dmb ld; x86:lfence写屏障 确保屏障前写操作先完成 ARM: dmb st; x86:sfence全屏障 阻止所有指令跨越屏障 ARM: dmb ish; x86:mfence -
C11 标准实现:
c
// 编译器屏障 atomic_signal_fence(memory_order_seq_cst); // CPU 内存屏障 atomic_thread_fence(memory_order_release); // 写屏障 atomic_thread_fence(memory_order_acquire); // 读屏障
volatile vs 内存屏障对比
| 特性 | volatile |
内存屏障 |
|---|---|---|
| 作用层级 | 编译器级 | 编译器 + CPU 级 |
| 重排控制 | 仅禁止编译器重排 | 禁止编译器 + CPU 重排 |
| 原子性 | 不保证 | 不直接保证(需原子指令配合) |
| 性能影响 | 低(仅内存访问优化失效) | 中高(暂停流水线) |
| 典型应用 | 硬件寄存器访问 | 多线程同步、无锁数据结构 |
关键场景解决方案
场景 1:多核间数据同步
c
// 线程 1 (Writer)
data = 42; // 写数据
atomic_thread_fence(memory_order_release); // 写屏障
ready = 1; // 设置标志
// 线程 2 (Reader)
while (!ready); // 等待标志
atomic_thread_fence(memory_order_acquire); // 读屏障
use_data(data); // 安全读取 场景 2:硬件寄存器操作
c
volatile uint32_t *reg = (volatile uint32_t*)0xFFFF0000;
*reg = ENABLE_MASK; // 写寄存器
asm volatile("dmb st" ::: "memory"); // ARM 写屏障(确保写入顺序) 使用原则总结
-
volatile使用场景:-
硬件寄存器访问
-
被异步修改的全局标志
-
禁止编译器优化特定内存访问
-
-
内存屏障使用场景:
-
多线程共享数据同步
-
无锁编程(Lock-Free Programming)
-
设备驱动中关键操作序列化
-
-
黄金法则:
🔥
volatile解决可见性问题,内存屏障解决顺序问题🔥 多线程同步永远优先用
atomic或互斥锁,而非volatile -
常见误区:
-
错误 :用
volatile实现多线程计数器c
volatile int count = 0; count++; // 仍存在数据竞争! -
正确:
c
atomic_int count = 0; atomic_fetch_add(&count, 1); // 原子操作
-
我的理解:
像反复检查天气预报:没有volatile时,编译器认为"早上看过就不用再看";有volatile就强制每次出门前必须重新查看。
二、内存管理
1. 字符串字面量不可修改
c
char *str = "Hello"; // 文字常量区
str[0] = 'h'; // 段错误!标准解析:
-
双引号字符串存储在只读数据段(.rodata)
-
修改触发段错误(内存保护机制)
-
正确做法:
char str[] = "Hello";(栈内存可修改)
我的理解:
把名言刻在石碑上(只读区)还想修改?要么自己准备可擦写黑板(数组),要么重刻石碑(新分配内存)。
2. 栈内存的致命陷阱
c
int *create_array(int size) {
int arr[size]; // 栈上分配
return arr; // 返回悬垂指针!
}标准解析:
-
函数返回时栈帧销毁,局部变量失效
-
返回指针指向无效内存(野指针)
-
正确做法:动态分配
int *arr = malloc(size*sizeof(int))
我的理解:
像把旅馆房间钥匙给朋友:你退房后钥匙虽在,但新客人入住后朋友开门的可能是别人房间!
3. 内存对齐的本质
标准解析:
-
对齐要求:数据地址必须是其大小的整数倍
-
根本原因:
-
CPU按块读取内存(如64位CPU读8字节块)
-
未对齐数据跨多个块,需多次读取+拼接
-
某些架构(ARM)直接拒绝未对齐访问
-
内存对齐的本质与必要性
-
硬件强制要求
内存对齐是 CPU 硬件访问内存的底层约束 ,并非软件优化选项。CPU 通过地址总线、缓存行(通常 64 字节)和加载指令以 固定块大小(2 的幂次)访问内存 。
未对齐访问的后果:-
性能损失:需多次内存访问 + 数据拼接(如 4 字节 int 跨 2 个缓存行)
-
稳定性风险:某些架构(如 ARM Cortex-M/RISC-V 严格模式)直接触发硬件异常(Bus Error)
-
原子性破坏:对齐是原子操作的必备条件(如 C++
std::atomic)
-
-
对齐的数学定义
若类型要求
N字节对齐 (N = 2ᴷ, 如 1/2/4/8...):-
地址必须满足:
address % N == 0 -
二进制等价:地址最低
K位全为 0
例:alignof(int)=4→ 地址末 2 位必为00
-
内存分配与对齐的关系
合法内存分配必然满足对齐,非法手动操作除外
| 分配方式 | 对齐保证 |
|---|---|
| 静态/全局变量 | 链接器按类型对齐要求(alignof(T))分配地址 |
| 栈变量 | 编译器插入隐式填充(Padding),确保每个变量地址对齐 |
| 动态分配 | malloc/new 返回的地址满足 alignof(std::max_align_t)(通常 8/16 字节) |
| 结构体/类成员 | 编译器在成员间插入填充字节,保证每个成员的偏移量是其对齐要求的整数倍 |
| 数组 | 首元素地址按元素类型对齐,后续元素自动连续对齐 |
| 手动构造非对齐地址 | 如 int* p = (int*)(char_buffer + 1); → 未定义行为(崩溃/性能劣化/数据错误) |
终极结论
-
内存对齐是硬件强制规则,核心目的是确保:
-
单次访存完成数据读写(避免拼接)
-
原子操作可行性
-
缓存行高效利用
-
架构兼容性(部分 CPU 直接拒绝对非对齐访问)
-
-
所有系统管理的内存分配 (静态/栈/堆/结构体)均自动满足对齐要求,这是编译器/链接器/操作系统的责任。
-
程序员仅在需要 超对齐 (如 SIMD 的 32 字节对齐)时需显式处理(
aligned_alloc()或编译器属性)。
本质就是空间换时间
-
多用了空间:24 > 11,多用13字节(空位)
-
换来时间:CPU操作次数从3次降到1次
-
在内存便宜的今天,这个交换很划算
我的理解:
CPU一次拿取的字节数是硬件固定的(如x86为8字节),内存对齐的核心价值是避免"跨块读取":当数据未对齐时,CPU需要多次访问+数据拼接,如同拆装家具分两车运输;若每次取块大小不固定,CPU需动态计算偏移,进一步增加负担。对齐访问让CPU单次完成操作,是效率优化的底层基石。
一个要求 4 字节对齐 (alignof(int) == 4) 的 int 变量,其地址的二进制表示最后两位必须是 00(即能被 4 整除)
4. 野指针的连环危机
c
int *p = malloc(10 * sizeof(int));
p++; // ✔ 指针移动
free(p); // ✘ 释放错误地址
// 未置空:p变野指针标准解析:
-
双重错误:
-
free()必须使用malloc返回的原始地址 -
free后未置空形成野指针
-
-
后果:二次释放或非法访问
我的理解:
搬家后:
把新地址当旧地址还房东(free错地址)→ 房东混乱
不注销旧钥匙(未置空)→ 可能擅闯别人家
5. 栈溢出 vs 堆溢出
| 特性 | 栈溢出 | 堆溢出 |
|---|---|---|
| 内存区域 | 栈 | 堆 |
| 触发原因 | 深度递归/大局部变量 | 数组越界/缓冲区溢出 |
| 表现 | 立即崩溃(栈耗尽) | 可能潜伏(堆破坏延迟暴露) |
| 危险程度 | 中(主要影响自身进程) | 高(可能引发安全漏洞) |
| 检测难度 | 简单(调用栈清晰) | 困难(可能随机出现) |
| 典型错误 | Segmentation fault | Heap corruption |
| 修复方案 | 改用迭代/减小栈使用 | 边界检查/使用安全函数 |
| 分配方式 | 自动分配释放 | 手动分配释放 |
| 默认大小 | 1-8MB(可配置) | 无上限(受物理内存限制) |
| 典型案例 | 无限递归 | 缓冲区溢出攻击 |
我的理解:
栈溢出:小仓库堆太多货架(递归调用),仓库撑爆
堆溢出:货架(数组)标号100格,硬塞120件货,压垮隔壁货架
程序内存分配终极总结:破除"8MB"迷思
核心结论
-
8MB不是程序内存上限 ,而是栈内存的默认限制
-
堆内存分配无固定上限,仅受系统物理内存+交换空间限制
-
专业程序轻松分配GB级内存,8MB只是小程序的典型用量
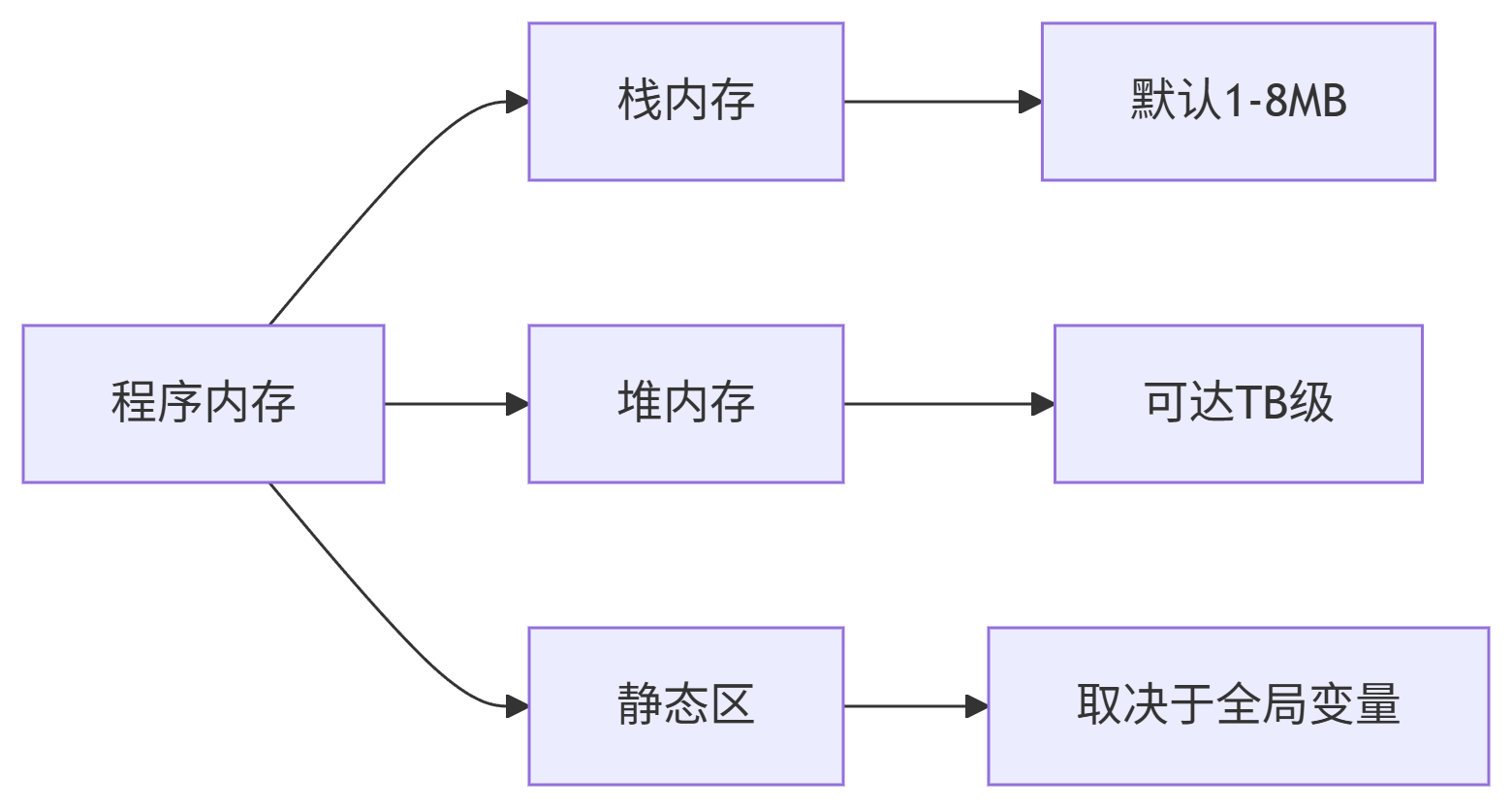
一、8MB的真相与误解
| 概念 | 真相 | 常见误解 |
|---|---|---|
| 8MB的来源 | 栈空间默认大小(Linux 8MB, Windows 1MB) | 程序总内存限制 |
| 触发场景 | 局部大数组/深度递归 | 任何内存分配 |
| 实际影响范围 | 仅限栈内存 | 整个程序内存 |
| 修改方式 | ulimit -s 65536(设为64MB) |
无法修改 |
| 典型错误代码 | int huge[1000000];(栈上400万元素数组) |
malloc(1000000*sizeof(int)) |
你的精辟总结 :
"8MB只是栈空间的'小仓库',堆内存才是'无限大货仓'。栈溢出如同小仓库爆仓,需把货物移到大货仓(堆);而堆内存不够时需优化存储或加内存条"
二、内存超限处理机制
当需求 > 可用内存时:
图表
代码
sequenceDiagram
程序->>操作系统: 申请大内存
操作系统->>物理内存: 检查空间
alt 物理内存足够
物理内存-->>操作系统: 分配成功
操作系统-->>程序: 返回指针
else 物理内存不足
操作系统->>交换空间: 页面置换
alt 交换空间足够
交换空间-->>操作系统: 换出冷数据
操作系统-->>程序: 分配成功(速度慢)
else 交换空间不足
操作系统-->>程序: 返回NULL(malloc失败)
end
end具体应对策略:
-
栈空间超限(>8MB):
c
// 错误做法(栈崩溃): void process() { int data[10*1024*1024]; // 40MB栈数组 → 段错误 } // 正确做法(堆分配): void process() { int *data = malloc(10*1024*1024 * sizeof(int)); if(!data) { /* 处理失败 */ } // 使用... free(data); } -
堆空间超限(>物理内存):
c
// 优雅处理内存不足 void *big_data = malloc(huge_size); if (!big_data) { // 降级方案 use_disk_storage(); // 改用磁盘缓存 reduce_data_quality(); // 降低数据精度 }
三、内存分配能力实测对比
| 系统环境 | 栈最大分配 | 堆最大分配 | 测试方法 |
|---|---|---|---|
| Linux桌面 | 8MB | 128TB(理论值) | ulimit -a / malloc测试 |
| Windows游戏PC | 1MB | 64-128GB | 任务管理器监控 |
| Android手机 | 1MB | 3-6GB | Android Profiler |
| 树莓派4B | 8MB | 1-4GB | 硬件限制 |
| 云服务器(AWS) | 可配8GB | 24TB(裸金属实例) | 企业级硬件 |
你的深刻洞察 :
"内存分配本质是空间管理艺术:栈像快捷酒店(便宜但房间小),堆像仓储超市(空间大但需自己管理)。专业程序员要懂得何时开房何时租仓库"
四、突破内存限制的四大技术
-
分块处理(处理超大数据集)
c
// 处理100GB文件 FILE *fp = fopen("huge.bin", "rb"); const size_t CHUNK = 1024*1024; // 1MB块 char *buffer = malloc(CHUNK); while (fread(buffer, 1, CHUNK, fp) > 0) { process_chunk(buffer); } -
内存映射文件(操作超大文件)
c
// 映射100GB文件到内存视图 int fd = open("bigdata.bin", O_RDWR); void *addr = mmap(NULL, 100UL*1024*1024*1024, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); float *data = (float*)addr; // 像普通数组一样访问 -
数据压缩(减少内存占用)
c
// 使用zlib压缩数据 void *compress_data(void *input, size_t in_size, size_t *out_size) { *out_size = compressBound(in_size); void *output = malloc(*out_size); compress((Bytef*)output, out_size, (Bytef*)input, in_size); return output; } -
分布式内存(集群级扩展)
python
# Python使用Dask处理TB数据 import dask.array as da x = da.random.random((1000000, 1000000), chunks=(1000, 1000)) result = x.mean().compute() # 分布式计算
五、内存管理黄金法则
-
栈内存使用原则:
-
对象 < 1KB
-
生命周期 = 当前函数
-
示例:临时变量、小型结构体
-
-
堆内存使用原则:
-
对象 > 1KB
-
生命周期 > 当前函数
-
示例:大型数组、数据结构
-
-
临界点决策树:
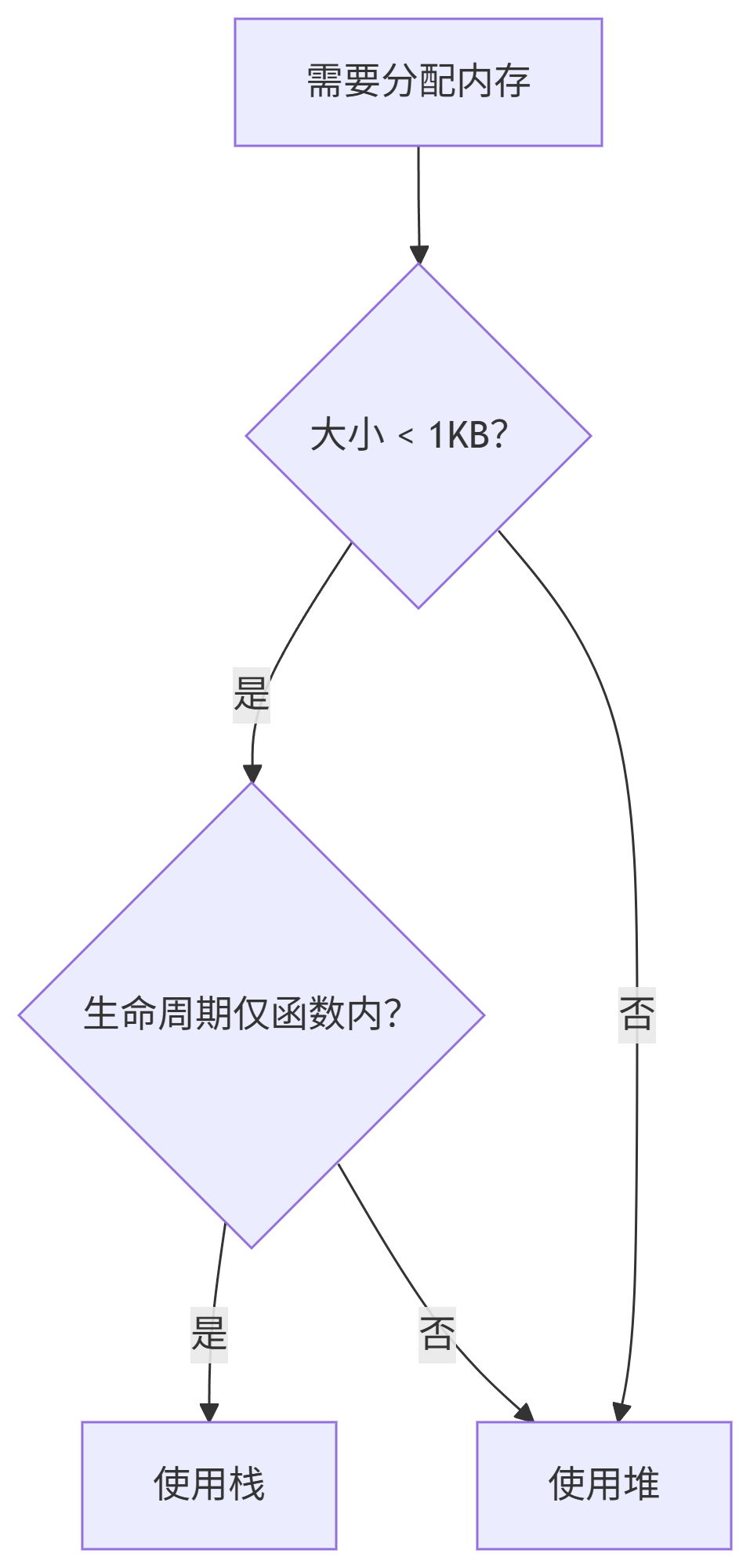
六、现实世界应用案例
-
Chrome浏览器:
-
每个标签页独立进程
-
典型内存占用:200-500MB
-
内存超限处理:自动卸载闲置标签页
-
-
视频编辑软件:
-
4K视频编辑需求:32GB+内存
-
技术方案:代理剪辑(低分辨率预览)
-
内存不足时:"渲染到磁盘"选项
-
-
科学计算:
-
气候模拟需TB级内存
-
解决方案:MPI分布式内存
-
内存超限策略:分块计算+磁盘暂存
-
三、指针与类型系统(
1. 复杂声明解析技巧
c
int (*(*foo[5])(void))[3];拆解步骤:
-
foo[5]:5个元素的数组 -
*foo[5]:数组元素是指针 -
(*)(void):指向无参函数的指针 -
int (*)[3]:函数返回指向int3的指针 -
整体:foo是数组5,元素为函数指针,该函数无参且返回指向int3的指针
记忆口诀:
从内到外,从右到左,优先括号
2. 二维数组地址计算
c
int arr[3][4]; // 假设&arr[0][0]=0x1000
printf("%p", &arr[2][3]); // 输出0x102C计算原理:
-
行优先存储:内存连续布局
-
地址公式:
基址 + (行号*列数 + 列号)*sizeof(int) -
本例:
0x1000 + (2*4 + 3)*4 = 0x1000 + 44 = 0x102C
我的理解:
像大型停车场:第0行0列=A区0号,第2行3列=C区3号,地址=基址+(总行数×列数 + 列号)×车位数
3. 指针强转的雷区
c
float f = 0.1f;
int *p = (int*)&f; // 危险!
printf("%d", *p); // 未定义行为标准解析:
- 违反严格别名规则(Strict Aliasing)
-
违反严格别名规则:
-
C标准规定:不能通过不同类型指针访问同一内存
-
例外情况:
-
允许通过
char*访问 -
允许相同类型访问
-
允许通过包含该类型的联合体访问
-
-
此处:
int*访问float内存 → 未定义行为(UB)
-
-
三重风险:
-
对齐问题(float地址可能不符合int对齐)
-
数据解释错误(位模式直接转整数)
-
编译器优化混乱
-
"强转指针类型对齐要求就变了,可能会取出错误数据,严重会崩溃"
这包含了三个核心危险:
-
硬件对齐要求变化 → 崩溃风险
-
数据解释规则变化 → 逻辑错误
-
内存边界理解变化 → 越界访问
安全替代方案:
c
// 方案1:联合体类型双关
union { float f; int i; } u;
u.f = 0.1f;
printf("%x", u.i);
// 方案2:memcpy内存复制
int i;
memcpy(&i, &f, sizeof(f));我的理解:
强转指针就像让英语老师读俄语课文:
直接强转:老师硬读(可能崩溃或胡言乱语)
联合体:找双语字典(安全转换)
memcpy:录音后让俄语老师读(复制解释)
4. const修饰符的密码
| 声明 | 含义 | 可修改指针 | 可修改数据 |
|---|---|---|---|
const int *p |
指向常量整数的指针 | ✔ | ✘ |
int const *p |
同上(等价写法) | ✔ | ✘ |
int * const p |
指向整数的常量指针 | ✘ | ✔ |
const int * const p |
指向常量整数的常量指针 | ✘ | ✘ |
记忆口诀:
看
const和*的相对位置:
const左*:常量数据
const右*:常量指针
const两边:双锁定
5. 函数指针 vs 指针函数
c
// 指针函数:返回指针的函数
int* func(int x);
// 函数指针:指向函数的指针
int (*fp)(int);
// 使用示例
fp = func; // 合法赋值
int *p = fp(5); // 通过指针调用本质区别:
-
函数指针是变量(存储函数地址)
-
指针函数是函数(返回指针值)
我的理解:
指针函数:会吐地址的机器人(函数)
函数指针:遥控器(变量),可绑定不同机器人
6.指针本身的大小 和指针访问数据时的对齐要求
-
指针变量本身的大小:
c
char *c_ptr; int *i_ptr; float *f_ptr; // 所有指针变量的大小都相同! printf("%zu\n", sizeof(c_ptr)); // 8字节(64位系统) printf("%zu\n", sizeof(i_ptr)); // 8字节 printf("%zu\n", sizeof(f_ptr)); // 8字节-
所有指针变量本身占用相同内存(64位系统固定8字节)
-
存储的都是内存地址值
-
-
指针访问数据时的行为:
c
int value = 42; int *p = &value; printf("%d", *p); // 解引用访问-
当通过指针访问数据时:
-
处理器需要知道如何解释内存中的二进制
-
处理器需要知道数据的大小和对齐要求
-
-
关键概念图谱
避坑指南
-
序列点规则:同一表达式内不对同一变量多次修改
-
内存操作铁律:
-
malloc/free成对出现
-
free后立即置空指针
-
栈对象绝不返回指针
-
-
指针转换三原则:
-
优先用联合体类型双关
-
次选用memcpy显式复制
-
避免强制指针类型转换
-
-
const声明策略:
-
默认加const,需要修改时再移除
-
函数参数:指针传递只读数据加const
-
-
防御式编程:
-
数组访问前检查索引
-
指针解引用前检查NULL
-
使用静态分析工具(Valgrind/ASan
-