1 前世今生:NGRAM
NGRAM:将词当成一个离散的单元(因此存在一定的局限性,没有考虑到词与词之间的关系)
neural network language model:只能处理定长序列,训练慢。使用RNN之后有所改善
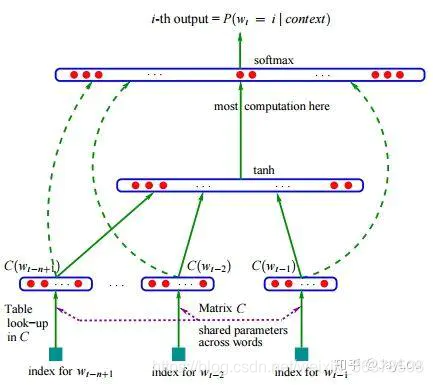
2 两种训练方式:CBOW,Skip-gram
CBOW(通过附近词预测中心词)、
Skip-gram(通过中心词预测附近的词)
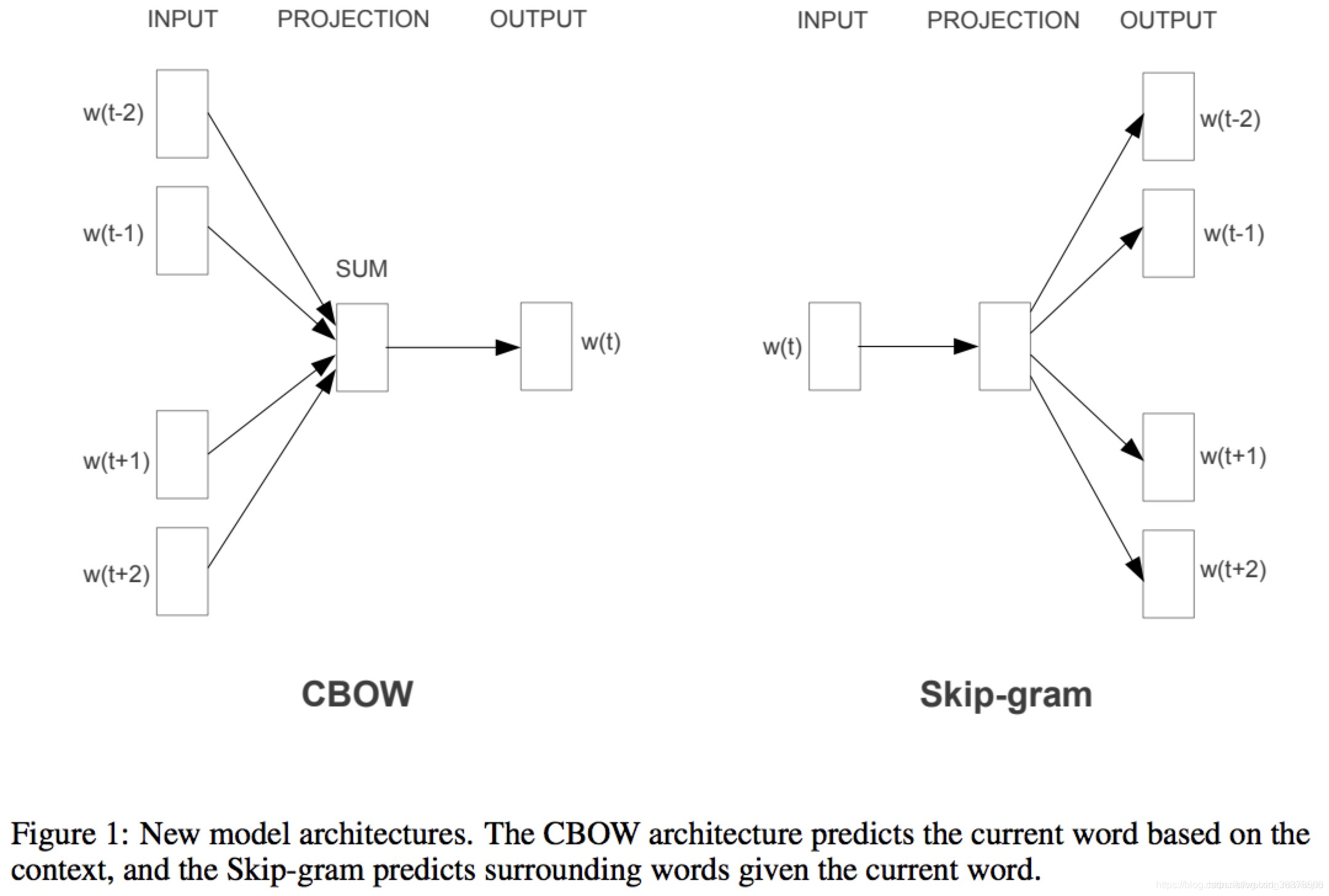
2.1 CBOW步骤
变量:词表大小V, 维度N,窗口大小C;N一般取50~300
步骤:
- 输入层:上下文窗口内的C个词的onehot表示
- 隐藏层1: 权重矩阵𝑊 + 激活函数
(V维表示降到N维表示)(所有的权重矩阵相同,即共享权重矩阵)
𝑊𝑉×𝑁 ,将 𝑉×𝐶映射为 𝑁×𝐶
word2vec中激活函数,用了简单取平均;- 隐藏层2: 权重矩阵W' + 激活函数
(N维升维到V维)
𝑊′𝑁×𝑉 ,将 𝑁×1映射为 𝑉×1- 输出层:softmax 激活函数,将值归一化到0~1之间 y
- 用BP+梯度下降优化cost function y和真实y之间的距离,迭代优化参数 𝑊、𝑊′
- 收敛result:y是V维向量,每个元素取值0~1, 将最大元素值,还原为onehot编码,就是最终结果了。
实际使用:得到第一个矩阵W之后,我们就能得到每个单词的词向量了。
训练示例:I drink coffee everyday1、第一个batch:I为中心词,drink coffee为上下文,即使用单词drink coffee来预测单词I,即输入为X_drink和X_coffee,输出为X_I,然后训练上述网络;
2、第二个batch:drink为中心词,I和 coffee everyday为上下文,即使用单词I和coffee everyday,即输入为X_I和X_coffee、X_everyday,输出为X_drink,然后训练上述网络;
3、第三个batch:coffee为中心词,I coffee 和 everyday为上下文,同理训练网络;
4、第四个batch:everyday为中心词,drink coffee为上下文,同理训练网络。
然后重复上述过程(迭代)3-5次(epoehs)左右即得到最后的结果。
具体的第三个batch的过程可见word2vec是如何得到词向量的?。得到的结果为0.23,0.03,0.62,0.12,此时结果是以coffee为中心词的词向量,每个位置表示的是对应单词的概率,例如该词向量coffee的概率为0.62。
需要注意的是每个batch中使用的权重矩阵都是一模一样的
2.2 skip-gram 步骤
思路同CBOW, 只是输入是1个词,输出是C个词;
一般用BP训练得到参数,预测用一次前向传播;
- 输入层:中心词的embedding表示,
looktable查表【V*d 表,每个词作为中心词的表示】得到中心词的embedding 表示1* 300
例如:你 真 漂亮。根据 真,预测其上下文的情况- 隐藏层: W 大小为300*10000, V*d 大小,是每个词作为背景词的表示
- 输出层:经过softmax,得到每个词的概率。
(0.3, 0.5, 0.7,), (0.1,0.9,0.1)
你出现在真之前的概率是0.3,之后是0.1;
真出现在真之前的概率是0.5,之后是0.9
漂亮出现在真之前的概率是0.7,之后是0.1
用蒙特卡洛模拟的方法根据哪些概率值去采样,就能得到一个具体的上下文。
然后就是优化了,使得输入的词之间"真漂亮"之间的概率足够大。写出目标函数:
- T是语料库单词的总个数,p(wt+j|wt)是已知当前词wt,预测周围词的总概率对数值
> - 训练数据: ( input word, output word ) 单词对input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
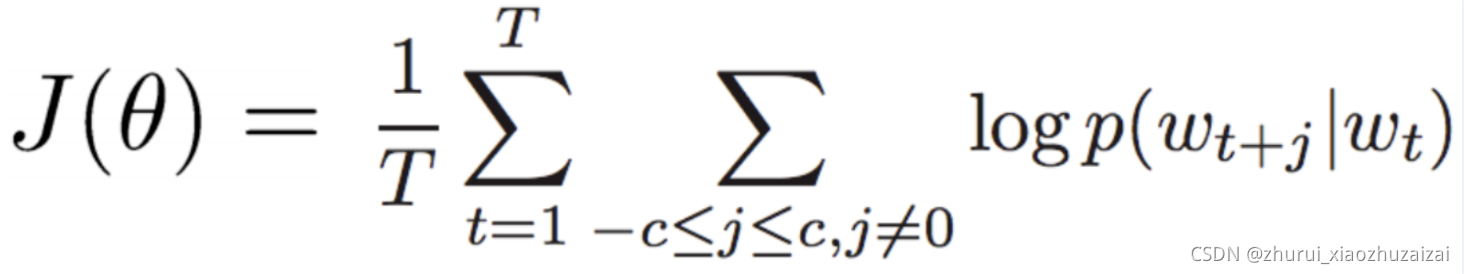
3 问题优化
word2vec结合了CBOW, skip-gram的方法 训练得到参数𝑊,
针对CBOW和SKIP-gram,样本大以及不均衡问题,在计算中做了很多优化;
可以看到,NNLM计算中,两个问题导致计算量大 ;词表维度大;
softmax计算量大
sofmax归一化需要遍历整个词汇表,
解决方案将常见的单词组合(word pairs)或者词组作为单个"words"来处理。
对高频次单词进行抽样来减少训练样本的个数。
层次softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路径变小;
负采样更为直接,实质上对每一个样本中每一个词都进行负例采样;这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
事实证明,对常用词抽样并且对优化目标采用"negative sampling"不仅降低了训练过程中的计算负担,还提高了训练的词向量的质量。
3.1 层次softmax
问题:
计算量瓶颈:
词表大
softmax计算大
每次更新更新参数多,百万数量级的权重矩阵和亿万数量级的训练样本
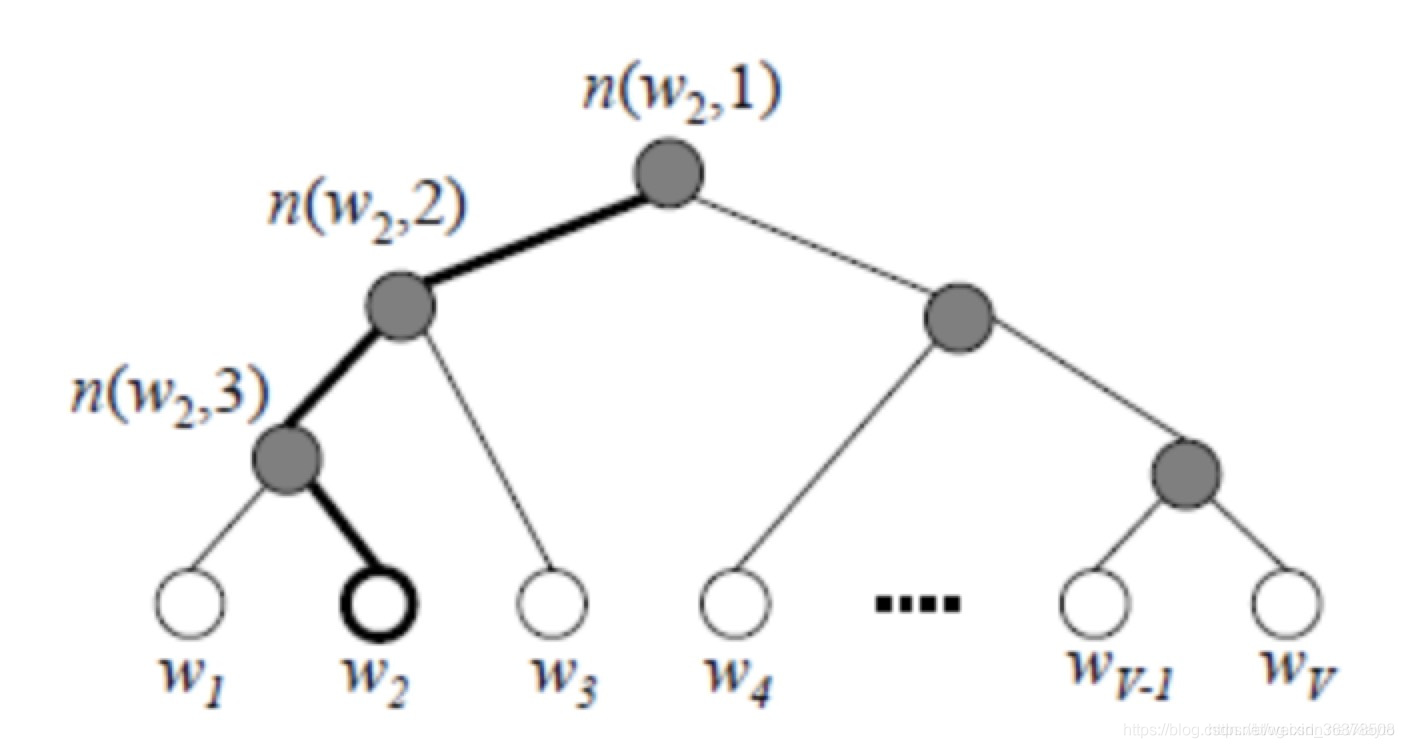
1)用huffman编码做词表示2)把N分类变成了log(N)个2分类。 如要预测的term(足球)的编码长度为4,则可以把预测为'足球',转换为4次二分类问题,在每个二分类上用二元逻辑回归的方法(sigmoid);
3)逻辑回归的二分类中,sigmoid函数导数有很好的性质,𝜎′(𝑥)=𝜎(𝑥)(1−𝜎(𝑥))
4)采用随机梯度上升求解二分类,每计算一个样本更新一次误差函数
从根节点到叶子节点的唯一路径编码了这个叶子节点所属的类别代价:增强了词与词之间的耦合性
Word2Vec中从输入到隐层的过程就是Embedding的过程。
在word2vec中,约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
二元逻辑回归 的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:
基于层次softmax的CBOW和SKIP_GRAM梯度推导以及训练过程
3.1.1 Hierarchical Softmax的缺点与改进
如果我们的训练样本里的中心词𝑤是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久.
负采样就是结局这个问题的
Negative Sampling就是这么一种求解word2vec模型的方法,它摒弃了霍夫曼树,采用了Negative Sampling(负采样)的方法来求解,下面我们就来看看Negative Sampling的求解思路
3.2 负采样
gensim的word2vec 默认已经不采用分层softmax了, 因为𝑙𝑜𝑔21000=10也挺大的;如果huffman的根是生僻字,则分类次数更多;
所以这时候负采样就派上了用场
Negative Sampling由于没有采用霍夫曼树,每次只是通过采样neg个不同的中心词做负例,就可以训练模型,因此整个过程要比Hierarchical Softmax简单。
不过有两个问题还需要弄明白:1)如果通过一个正例和neg个负例进行二元逻辑回归呢?
2) 如何进行负采样呢?
基于负采样的CBOW和SKIP_GRAM梯度推导以及训练过程
3.2.1负采样怎么做的
所有的参数都在训练中调整的话,巨大计算量
负采样每次让一个训练样本仅仅更新一小部分的权重
现在只更新预测词以及neg个负例词的权重
随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的"positive" word进行权重更新(在我们上面的例子中,这个单词指的是"quick")。
在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
3.2.2 如何选择negative words
"一元模型分布(unigram distribution)"来选择"negative words"。
出现频次越高的单词越容易被选作negative words。
每个单词被赋予一个权重,即f(wi), 它代表着单词出现的频次。公式中开3/4的根号完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。
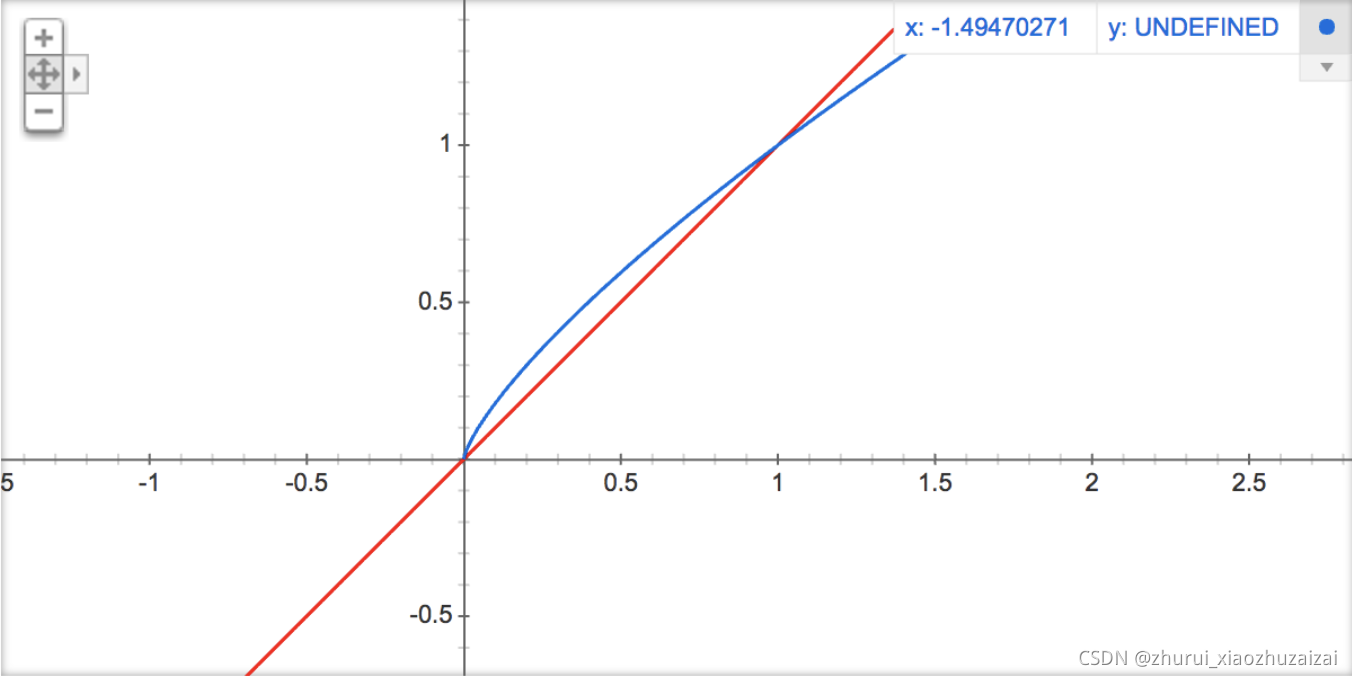
你可以在google的搜索栏中输入"plot y = x^(3/4) and y = x",然后看到这两幅图(如下图),仔细观察x在0,1区间内时y的取值,有一小段弧形,取值在y=x函数之上。
负采样的C语言实现非常的有趣。unigram table有一个包含了一亿个元素的数组,这个数组是由词汇表中每个单词的索引号填充的,并且这个数组中有重复,也就是说有些单词会出现多次。那么每个单词的索引在这个数组中出现的次数该如何决定呢,有公式P(wi)V,也就是说计算出的负采样概率 1亿=单词在表中出现的次数。有了这张表以后,每次去我们进行负采样时,只需要在0-1亿范围内生成一个随机数,然后选择表中索引号为这个随机数的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。
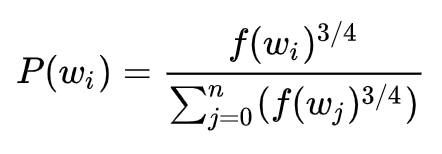
3.2.3 为什么需要做采样:
skip_gram 解决高频词训练样本太大的问题:
原始训练样本:
- 1.对于高频词。会产生大量的训练样本。
-2.("fox", "the") 这样的训练样本并不会给我们提供关于"fox"更多的语义信息,因为"the"在每个单词的上下文中几乎都会出现。
常用词出现概率很大,样本数量远远超过了我们学习"the"这个词向量所需的训练样本数。
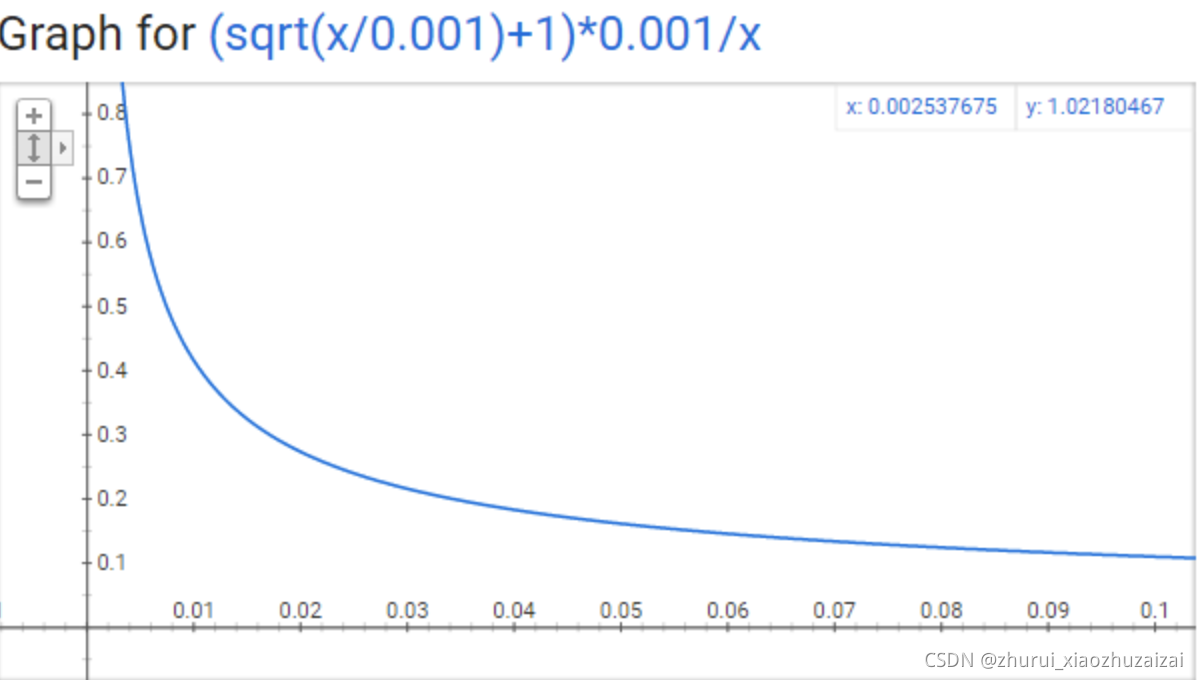
Word2Vec通过"抽样"模式来解决这种高频词问题。它的基本思想如下:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
Z(wi)即单词wi在语料中出现频率
当Z(wi)<=0.0026时,P(wi)=1.0。当单词在语料中出现的频率小于0.0026时,它是100%被保留的,这意味着只有那些在语料中出现频率超过0.26%的单词才会被采样。当Z(wi)<=0.00746时,P(wi)=0.5,意味着这一部分的单词有50%的概率被保留。
当Z(wi)<=1.0时,P(wi)=0.033,意味着这部分单词以3.3%的概率被保留。

4 问题
4.1 词袋模型到word2vec改进了什么?
词袋模型(Bag-of-words model)是将一段文本(比如一个句子或是一个文档)用一个"装着这些词的袋子"来表示,这种表示方式不考虑文法以及词的顺序。而
在用词袋模型时,文档的向量表示直接将各词的词频向量表示加和。通过上述描述,可以得出词袋模型的两个缺点:
词向量化后,词与词之间是有权重大小关系的,不一定词出现的越多,权重越大。 词与词之间是没有顺序关系的。而word2vec是考虑词语位置关系的一种模型。通过大量语料的训练,将每一个词语映射成一个低维稠密向量,通过求余弦的方式,可以判断两个词语之间的关系,word2vec其底层主要采用基于CBOW和Skip-Gram算法的神经网络模型。
因此,综上所述,词袋模型到word2vec的改进主要集中于以下两点:考虑了词与词之间的顺序,引入了上下文的信息
得到了词更加准确的表示,其表达的信息更为丰富
5 代码
python
import jieba
import os
import re
import pandas as pd
from gensim.models.word2vec import Word2Vec
import gensim
class TrainWord2Vec(object):
"""
训练得到一个Word2Vec模型
"""
def __init__(self, data, stopword, new_path, num_features=100, min_word_count=1, context=4, incremental=False):
"""
定义变量
:param data: 用于训练胡语料
:param stopword: 停用词表
:param num_features: 返回的向量长度
:param min_word_count: 最低词频
:param context: 滑动窗口大小
:param incremental: 是否进行增量训练
:param old_path: 若进行增量训练,原始模型路径
"""
self.data = data
self.stopword = stopword
self.num_features = num_features
self.min_word_count = min_word_count
self.context = context
self.incremental = incremental
#self.old_path = old_path
self.new_path = new_path
def clean_text(self):
"""
采用结巴分词函数分词
:param corpus: 待分词的Series序列
:return: 分词结果,list
"""
# 去除无用字符
pattern = re.compile(r'[\sA-Za-z~()()【】%*#+-\.\\\/:=:__,,。、;;""""''''??!!<《》>^&{}|=......]')
corpus_ = self.data.apply(lambda s: re.sub(pattern, '', str(s)))
# 分词
text = corpus_.apply(jieba.lcut)
# 过滤通用词
text = text.apply(lambda cut_words: [word for word in cut_words if word not in self.stopword])
return text
def get_model(self, text):
"""
从头训练word2vec模型
:param text: 经过清洗之后的语料数据
:return: word2vec模型
"""
model = Word2Vec(text, vector_size=self.num_features, min_count=self.min_word_count, window=self.context)
return model
def update_model(self, text):
"""
增量训练word2vec模型
:param text: 经过清洗之后的新的语料数据
:return: word2vec模型
"""
model = Word2Vec.load(self.old_path) # 加载旧模型
model.build_vocab(text, update=True) # 更新词汇表
model.train(text, total_examples=model.corpus_count, epochs=20) # epoch=iter语料库的迭代次数;(默认为5) total_examples:句子数。
return model
def train(self):
"""
主函数,保存模型
"""
# 加入自定义分析词库
#jieba.load_userdict("add_word.txt")
text = self.clean_text()
if self.incremental:
model = self.update_model(text)
else:
model = self.get_model(text)
model.train(text, total_examples=model.corpus_count, epochs=20)
# 保存模型
model.wv.save_word2vec_format(self.new_path, binary=True)
if __name__ == '__main__':
corpus = []
infile = "/dataset/sentence_sim/V1_6/data/qiwei/single"
stop_file = "qiwei_vocab_no_in.txt"
w2v_file = 'w2v_qiwei.bin'
for file_i in ["train.csv", "test.csv"]:
corpus.append(pd.read_csv(os.path.join(infile, file_i))["text"])
corpus = corpus[0].append(corpus[1])
print(len(corpus))
stopword = []
with open(stop_file, "r") as f:
for info in f.readlines():
stopword.append(info.strip())
new_model_path = w2v_file
model = TrainWord2Vec(corpus, stopword, new_model_path)
model.train()