在入门2中,使用pytorch中的sigmoid映射的方式对二值输出的概率进行了预测,但是显示中很多东西都并不是二值化的,需要我们在一定范围内选择概率最高的事件进行预测,这时候就需要我们进行多输出模型预测了,这里就使用简单的一个多输出模型对pytorch中的手写数字集进行预测;
首先分析一些数据集,数据集是一张张手写数字图片,那么输入维度就是图片的像素,这里图片的像素是28*28的,也就是输入维度是784,输出数据是要预测该数字是0-9的概率,输出维度为10,但是这里处理图像仍然使用简单的线性层;
(1)准备数据
第一步是准备数据,我这里已经下载好了原始数据
python
def get_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_data = datasets.MNIST(root='./data', train=True, download=False, transform=transform)
test_data = datasets.MNIST(root='./data', train=False, download=False, transform=transform)
train_data_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_data_loader = DataLoader(test_data, batch_size=64, shuffle=True)
return train_data_loader, test_data_loader如果已经下载好了原始数据,则可以使用datasets.MNIST传递参数download为false来进行直接导入,如果没有下载好可以直接在线下载到前面指定的文件地址中;
体重transform参数的作用是对图像数据进行预测里,这里首先进行的是transforms.ToTensor(),这个的作用是将图像数据转换为tensor以给pytorch进行处理,这里还自动将像素值缩放到了0-1之间,然后进行的是transforms.Normalize,这个方法主要对tensor进行归一化操作,里面的参数分别为像素均值和像素标准差,由于手写数据集是一个单通道灰度图,这里的均值和标准差只有一个值,如果是RGB图像,则应该有三个通道,参数为(n1, n2, n3), (d1, d2, d3);
获得训练数据和测试数据后,使用dataloader将数据变为一个可迭代对象,简单来说就是把一个数据进行分类,由于手写数据集一个数据很大,我们不可能一次把所有数据进行训练,因此我们先对数据集进行分类,第一个参数是原始数据集,batch_size是每一次分类的最大数据量,shuffle参数表示是否要将数据进行打乱;
调用这个函数,我们就可以获得一个训练数据和测试数据的可迭代对象了
(2)构建模型
开头分析了模型的输入维度为784,输出维度为10,模型不可能直接从784维度到10维,因为一层只能进行接近的线性变换,而多层+激活函数可以拟合出更加复杂的函数,所以需要一些中间层进行过渡,这种神经网络也叫全连接神经网络,至于要多少层和每层映射维度是多少,可以通过尝试的方式来进行,
class module(nn.Module):
def __init__(self):
super(cnn_model, self).__init__()
self.linear_1 = nn.Linear(784, 512)
self.linear_2 = nn.Linear(512, 128)
# self.linear_3 = nn.Linear(256, 128)
self.linear_4 = nn.Linear(128, 64)
self.linear_7 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.linear_1(x))
x = F.relu(self.linear_2(x))
# x = F.relu(self.linear_3(x))
x = F.relu(self.linear_4(x))
# x = F.relu(self.linear_5(x))
# x = F.relu(self.linear_6(x))
y = F.softmax(self.linear_7(x))
return y由于手写数字识别的图像像素是28*28的,这里由于我们使用的是线性模型,因此要把图像像素转为1维数据,则一维数据大小维28*28=784,所以我们第一层输入维784,接着我们使用几层线性层和relu激活函数将784个像素点向10维结果进行映射;
其中在这里relu函数相当于一个阈值函数,如果输入值大于0,输出为输入不变,如果输入值小于0,输出为0,通过这种方式可以向模型中引入非线性变换,增加模型的推理能力;
在最后还使用了F.softmax()函数,这个函数的主要作用是进行概率化处理,将结果进行概率和为1的映射,这样输出的结果就是在10维中的概率值,且概率和为1
(3)训练和测试模型
我们将训练模型和测试模型封装成一个函数
(1)训练模型
def train_data(model, criterion, optimizer, train_data_loader):
model.train()
for step, [data, target] in enumerate(train_data_loader):
target_pre = model(data)
loss = criterion(target_pre, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()这里构造一个训练模型的函数,需要的参数有训练的模型,损失函数,优化器和被训练的数据;
首先应该开启模型为训练模式,调用模型的train方法实现;
其次循环遍历训练数据可迭代对象,还是和以往一样,首先将特征给模型推理,接着使用结果计算损失函数,清空优化器梯度,损失反馈,更新;
(2)测试模型
训练模型也封装成一个函数
python
def test_data(model, test_data_loader):
model.eval()
success = 0
num = 0
with torch.no_grad():
for step, [data, target] in enumerate(test_data_loader):
target_pre = model(data)
# print(target_pre)
print(torch.argmax(target_pre, dim=1), target)
success += (torch.argmax(target_pre, dim=1) == target).sum().item()
num += len(data)
return success/num测试函数需要两个参数,一个是训练的模型,一个是测试的数据;
首先使用模型中的eval方法将模型切换到评估模式,设置每轮成功数和总共训练的值,为了后面方便返回训练的成功概率;
接着使用no_grad让torch不要更新权重,里面是平常的训练代码,这里首先遍历测试数据迭代器,为了能够获取步数,这里使用enumerate函数,它接收一个可迭代对象,返回计数值和数据的元组;
使用model传入特征值得到预测结果,由于这里一次预测有64个数据,这里使用torch.argmax()函数获取其中的最大值,后面参数dim决定是从行计算还是从列计算,可以填入0()或1();
让后使用success来加上预测成功的个数,使用num加上总共预测的个数,最终返回这轮训练的正确概率;
(4)训练和预测
通过上面的函数,只要构造将神经网络实例化,构造损失函数和优化器就可以调用上面函数进行训练了,我们每训练一次就测试一次,这样可以直观地看到成功率在训练阶段的变化
python
model = module()
train_time = 30
success_rate = [0.0 for i in range(train_time)] # 成功率列表
train_data_loader, test_data_loader = get_data() # 获取数据
fig, axs = plt.subplots(1, 1)
criterion = nn.CrossEntropyLoss() # 构造交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.05) # 构造优化器
for i in range(train_time):
train_data(model, criterion, optimizer, train_data_loader) # 训练
success_rate[i] = test_data(model, test_data_loader) # 测试,记录每轮训练的正确率
print(success_rate)
axs.plot(success_rate)
plt.show()(5)训练结果
通过plt绘画出每轮训练的成功率曲线,可以直观地看到训练过程中成功率的变化
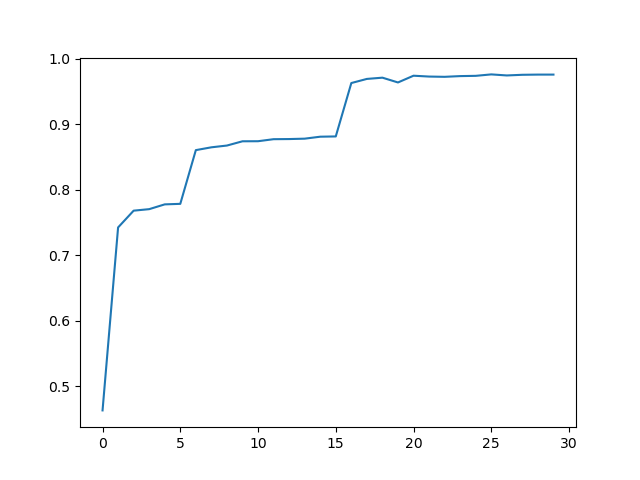
可以看到成功率在不断提高,在最后收敛且接近于1,通过打印成功率可以更加具体地看到成功率的数值

可以看到成功率在最后为0.97,这个成功率似乎很高,但是还有优化的地方,那就是图像之间的关系,图像在相隔很远的点位上是可能存在关系的,但是仅仅使用线性模型却没有考虑到这种关系,因此造成了一些信息的损失,如果要考虑图像空间上的关系,就需要使用卷积神经网络cnn,同时cnn中有很多可以优化的地方,到最后成功率会达到0.99接近1.