目录
[6.2 GRU](#6.2 GRU)
1.前言
时间序列预测在能源、气象等领域具有重要应用价值。传统方法如ARIMA、SVM等在处理非线性、非平稳序列时存在局限性,而深度学习模型(如GRU)虽能捕捉时序特征,但对初始参数敏感,且复杂序列需预处理以提升预测精度。变分模态分解(VMD)可将复杂时序分解为多个平稳模态分量,GRU可有效建模序列长期依赖关系,WOA优化则用于优化GRU的关键参数,形成 "分解-优化-预测" 的完整框架。该算法通过多技术协同,提升时序预测的准确性和鲁棒性。
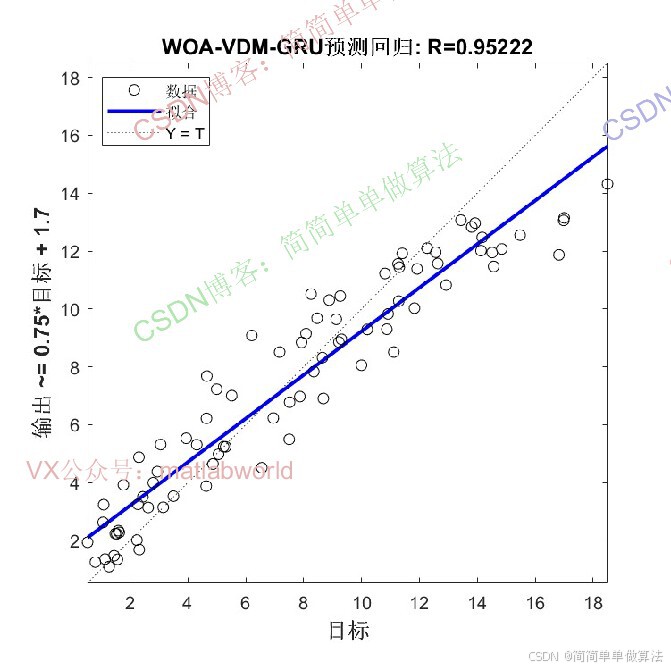
2.算法运行效果图预览
(完整程序运行后无水印)
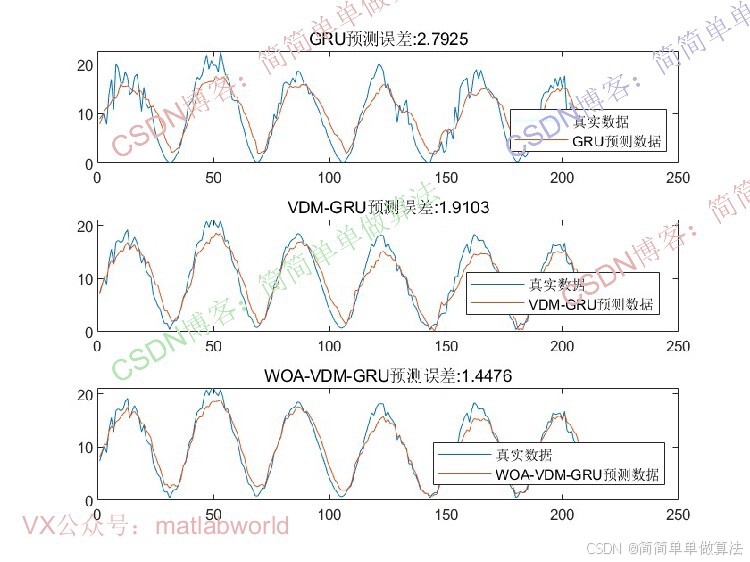
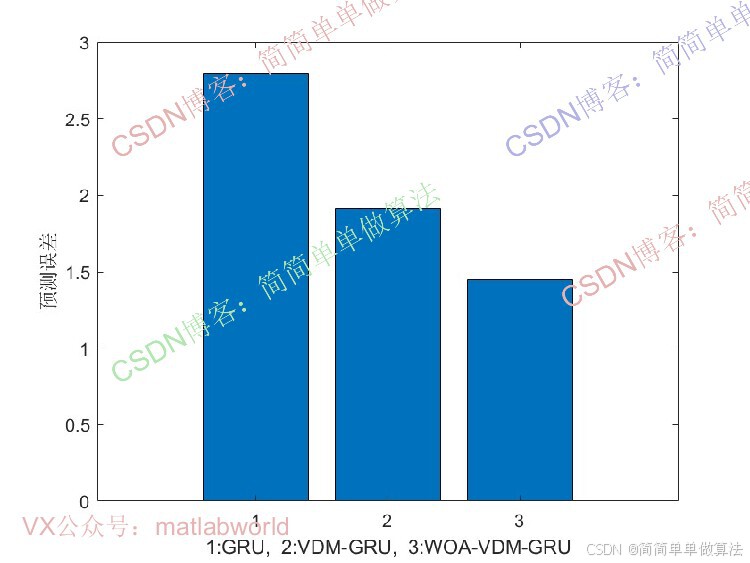
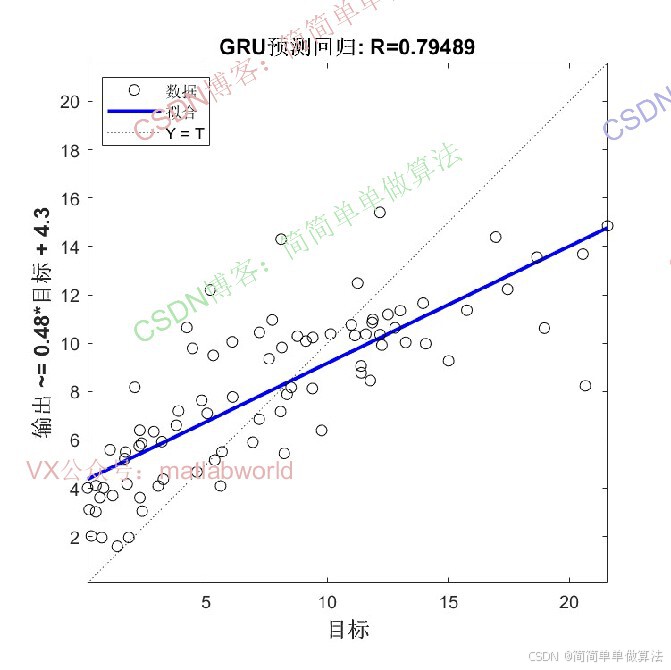
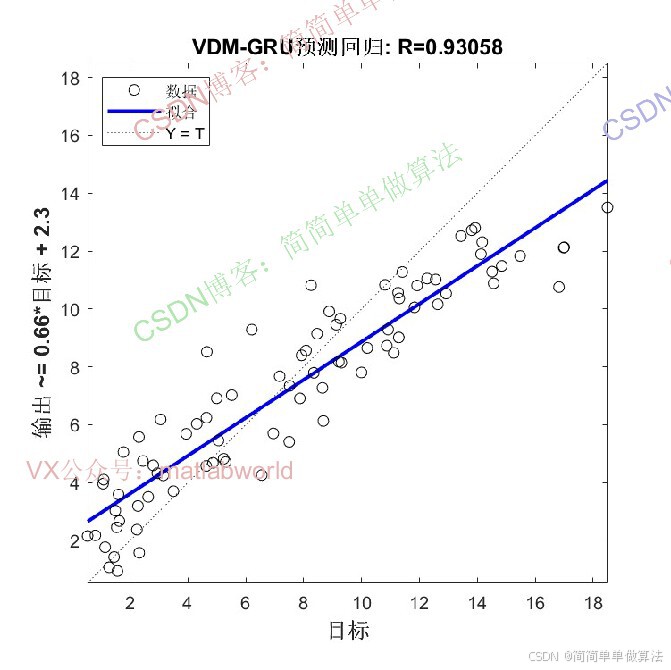
3.算法运行软件版本
Matlab2024b(推荐)或者matlab2022a
4.部分核心程序
(完整版代码包含中文注释和操作步骤视频)
...................................................................
layers = [ ...
sequenceInputLayer(indim)
gruLayer(Nlayer)
fullyConnectedLayer(outdim)
regressionLayer];
%训练
[net,INFO] = trainNetwork(Pxtrain, Txtrain, layers, options);
Rerr = INFO.TrainingRMSE;
Rlos = INFO.TrainingLoss;
%预测
Tpre1 = predict(net, Pxtrain);
Tpre2 = predict(net, Pxtest);
%反归一化
TNpre1 = mapminmax('reverse', Tpre1, Norm_O);
TNpre2 = mapminmax('reverse', Tpre2, Norm_O);
%数据格式转换
TNpre1s(d,:) = cell2mat(TNpre1);
TNpre2s(d,:) = cell2mat(TNpre2);
T_trains(d,:) = T_train;
T_tests(d,:) = T_test;
Rerrs(d,:)=Rerr;
Rloss(d,:)=Rlos;
end
2265.算法仿真参数
%每个变量的取值范围
tmps(1,:) = [10,100]; %
tmps(2,:) = [0.0001;0.05]; %
Num = 10; %搜索数量
Iters = 5; %迭代次数
D = 2; %搜索空间维数
woa_idx = zeros(1,D);
woa_get = inf;
%每个变量的取值范围
tmps(1,:) = [10,100]; %
tmps(2,:) = [0.0001;0.05]; %6.算法理论概述
6.1变分模态分解(VMD)
VMD是一种自适应信号分解方法,通过构建变分模型将原始序列分解为若干模态分量(IMF),每个分量对应特定频率尺度,且带宽之和最小化。该过程通过交替迭代更新各模态的频率和幅值实现,无需预设分解层数(实际应用中需结合数据特性确定或优化)。


6.2 GRU
门控循环单元解决传统RNN的梯度消失 / 爆炸问题,同时简化了长短期记忆网络(LSTM)的结构,在保持相似性能的前提下降低了计算复杂度。GRU的核心优势在于:
能有效捕捉序列数据中的长期依赖关系(如文本中的上下文关联、时间序列中的历史趋势);
结构比LSTM更简洁(仅含2个门控机制),训练速度更快;
在自然语言处理(NLP)、语音识别、时间序列预测等领域表现优异。
GRU通过门控机制控制信息的流动与遗忘,避免了传统 RNN 在长序列中梯度衰减的问题。其核心思想是:对于输入的序列信息,动态决定哪些信息需要保留(记忆),哪些信息需要更新(替换)。
7.参考文献
1彭德烊,赵胜利,吴圆圆,et al.基于VMD和LSTM的全球平均气温预测J.Climate Change Research Letters, 2024, 13.DOI:10.12677/ccrl.2024.135122.
2Sun H , Yu Z , Zhang B .Research on short-term power load forecasting based on VMD and GRUJ.PLoS ONE (v.1;2006), 2024, 19(7):21.DOI:10.1371/journal.pone.0306566.
8.算法完整程序工程
OOOOO
OOO
O