写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
3.4 管道
-
3.5 分组
-
3.6 案例研究:聚合和样本量
-
3.7 总结
3.4 管道
我们已经在前面向您展示了管道(pipe)的简单示例,但当您开始组合多个 verbs 时,它的真正威力就会显现出来。例如,假设您想找到飞往休斯顿 IAH 机场的快速航班:您需要结合使用 filter()、mutate()、select() 和 arrange():
flights |>
filter(dest == "IAH") |>
mutate(speed = distance / air_time * 60) |>
select(year:day, dep_time, carrier, flight, speed) |>
arrange(desc(speed))
#> # A tibble: 7,198 × 7
#> year month day dep_time carrier flight speed
#> <int> <int> <int> <int> <chr> <int> <dbl>
#> 1 2013 7 9 707 UA 226 522.
#> 2 2013 8 27 1850 UA 1128 521.
#> 3 2013 8 28 902 UA 1711 519.
#> 4 2013 8 28 2122 UA 1022 519.
#> 5 2013 6 11 1628 UA 1178 515.
#> 6 2013 8 27 1017 UA 333 515.
#> # ℹ 7,192 more rows尽管这个管道有四个步骤,但它很容易浏览,因为 verbs 出现在每一行的开头:从 flights 数据开始,then filter, then mutate, then select, then arrange。
如果我们没有管道会怎样?我们可以将每个函数调用嵌套在前一个调用中:
arrange(
select(
mutate(
filter(
flights,
dest == "IAH"
),
speed = distance / air_time * 60
),
year:day, dep_time, carrier, flight, speed
),
desc(speed)
)或者我们可以使用一堆中间对象:
flights1 <- filter(flights, dest == "IAH")
flights2 <- mutate(flights1, speed = distance / air_time * 60)
flights3 <- select(flights2, year:day, dep_time, carrier, flight, speed)
arrange(flights3, desc(speed))虽然这两种形式都有它们的时间和地点,但管道通常会产生更易于编写和阅读的数据分析代码。
要将管道添加到代码中,我们建议使用内置键盘快捷键 Ctrl/Cmd + Shift + M。您需要对 RStudio 选项进行一项更改,以使用 |> 而不是 %>%,如 Figure 3.1 中所示;稍后将详细介绍 %>%。
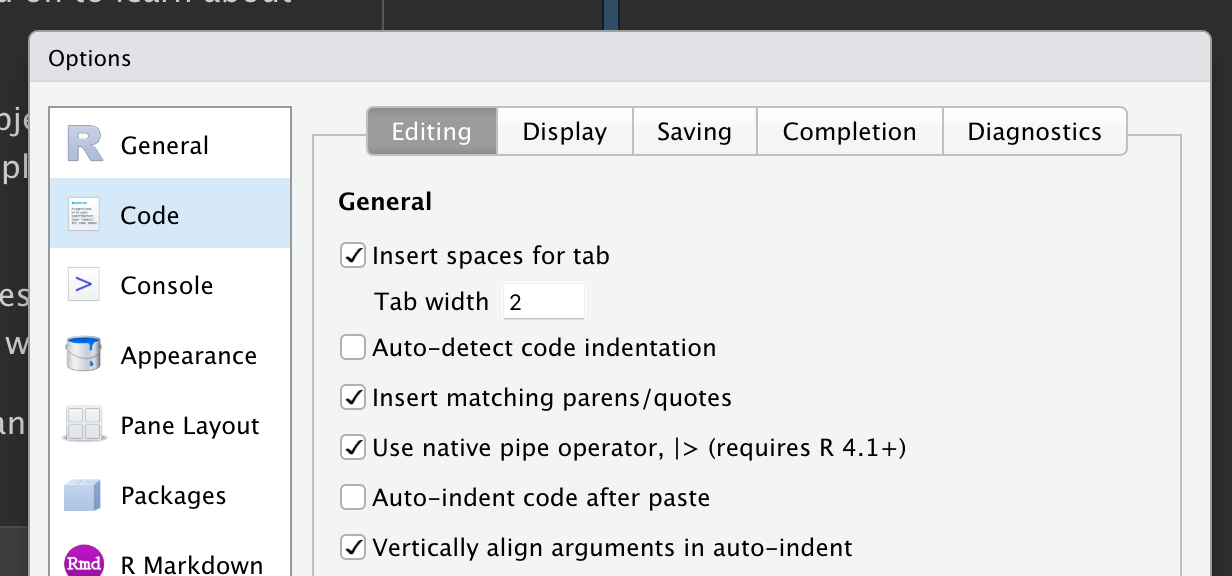
Figure 3.1:要插入 |>,请确保选中 "Use native pipe operator" 选项。
magrittr
如果您已经使用 tidyverse 一段时间,您可能熟悉 magrittr 包提供的
%>%管道。magrittr 包包含在核心 tidyverse 中,因此您可以在加载 tidyverse 时使用%>%:
library(tidyverse) mtcars %>% group_by(cyl) %>% summarize(n = n())对于简单的情况,
|>和%>%的行为相同。那么为什么我们推荐 base pipe(|>)呢?首先,因为它是 base R 的一部分,所以它始终可供您使用,即使您不使用 tidyverse。其次,|>比%>%简单得多:从 2014 年发明%>%到 2021 年将|>包含在 R 4.1.0 之间,我们对管道有了更好地了解。这允许基本实现放弃不常用和不太重要的功能。
3.5 分组
到目前为止,您已经了解了处理行和列的函数。当您添加与组(groups)一起工作的能力时,dplyr 变得更加强大。在本节中,我们将重点关注最重要的函数:group_by()、summarize() 和 slice 函数系列。
3.5.1 group_by()
使用 group_by() 将您的数据集分成对您的分析有意义的组:
flights |>
group_by(month)
#> # A tibble: 336,776 × 19
#> # Groups: month [12]
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, ...group_by() 不会更改数据,但是,如果您仔细查看输出,您会注意到输出表明它是按 month 分组的(Groups: month [12])。这意味着后续操作现在将按 month 进行。group_by() 将这个分组特征(称为类)添加到数据框,这改变了应用于数据的后续 verbs 的行为。
3.5.2 summarize()
最重要的分组操作是 summary,如果用于计算单个汇总统计数据,则会将数据框减少为每个组只有一行。在 dplyr 中,此操作由 summarize() 执行,如下例所示,它按月计算平均出发延迟:
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay)
)
#> # A tibble: 12 × 2
#> month avg_delay
#> <int> <dbl>
#> 1 1 NA
#> 2 2 NA
#> 3 3 NA
#> 4 4 NA
#> 5 5 NA
#> 6 6 NA
#> # ℹ 6 more rows呃!出了点问题,我们所有的结果都是 NA(发音为"N-A"),R 的缺失值符号。发生这种情况是因为一些观察到的航班在延误列中缺少数据,因此当我们计算包括这些值的平均值时,我们得到了 NA 结果。我们将在 Chapter 18 中回来详细讨论缺失值,但现在我们将告诉 mean() 函数通过将参数 na.rm 设置为 TRUE 来忽略所有缺失值:
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE)
)
#> # A tibble: 12 × 2
#> month avg_delay
#> <int> <dbl>
#> 1 1 10.0
#> 2 2 10.8
#> 3 3 13.2
#> 4 4 13.9
#> 5 5 13.0
#> 6 6 20.8
#> # ℹ 6 more rows您可以在一次调用 summarize() 中创建任意数量的 summaries。您将在接下来的章节中学习各种有用的 summaries,但一个非常有用的 summary 是 n(),它返回每组中的行数:
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
n = n()
)
#> # A tibble: 12 × 3
#> month avg_delay n
#> <int> <dbl> <int>
#> 1 1 10.0 27004
#> 2 2 10.8 24951
#> 3 3 13.2 28834
#> 4 4 13.9 28330
#> 5 5 13.0 28796
#> 6 6 20.8 28243
#> # ℹ 6 more rowsMeans 和 counts 可以让你在数据科学中走得更远!
4.5.3 slice_ 函数
有五个方便的函数可让您提取每个组中的特定行:
-
df |> slice_head(n = 1)从每组中取出第一行。 -
df |> slice_tail(n = 1)从每组中取出最后一行。 -
df |> slice_min(x, n = 1)获取列 x 中具有最小值的行。 -
df |> slice_max(x, n = 1)获取列 x 中具有最大值的行。 -
df |> slice_sample(n = 1)取一个随机行。
您可以改变 n 以选择多行,或者不使用 n =,您可以使用 prop = 0.1 来选择(例如)每组中 10% 的行。例如,以下代码查找到达每个目的地时最晚延误的航班:
flights |>
group_by(dest) |>
slice_max(arr_delay, n = 1) |>
relocate(dest)
#> # A tibble: 108 × 19
#> # Groups: dest [105]
#> dest year month day dep_time sched_dep_time dep_delay arr_time
#> <chr> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 ABQ 2013 7 22 2145 2007 98 132
#> 2 ACK 2013 7 23 1139 800 219 1250
#> 3 ALB 2013 1 25 123 2000 323 229
#> 4 ANC 2013 8 17 1740 1625 75 2042
#> 5 ATL 2013 7 22 2257 759 898 121
#> 6 AUS 2013 7 10 2056 1505 351 2347
#> # ℹ 102 more rows
#> # ℹ 11 more variables: sched_arr_time <int>, arr_delay <dbl>, ...请注意,有 105 个目的地(destinations),但我们在这里得到 108 行。这是怎么回事?slice_min() 和 slice_max() 保持绑定值,所以 n = 1 意味着给我们所有具有最高值的行。如果您只想每组一行,您可以设置 with_ties = FALSE。
这类似于使用 summarize() 计算最大延迟,但是您得到的是整个对应行(如果有平局则为行)而不是单个汇总统计数据。
3.5.4 按多个变量进行分组
您可以使用多个变量创建 groups。例如,我们可以为每个日期创建一个 group。
daily <- flights |>
group_by(year, month, day)
daily
#> # A tibble: 336,776 × 19
#> # Groups: year, month, day [365]
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, ...当您 summarize 由多个变量分组的 tibble 时,每个 summary 都会剥离最后一组。事后看来,这不是使该功能正常工作的好方法,但在不破坏现有代码的情况下很难进行更改。为了使发生的事情一目了然,dplyr 会显示一条消息,告诉您如何更改此行为:
daily_flights <- daily |>
summarize(n = n())
#> `summarise()` has grouped output by 'year', 'month'. You can override using
#> the `.groups` argument.如果您对此行为感到满意,您可以明确请求它以抑制消息:
daily_flights <- daily |>
summarize(
n = n(),
.groups = "drop_last"
)或者,通过设置不同的值来更改默认行为,例如,"drop" 删除所有分组或 "keep" 保留相同的组。
3.5.5 Ungrouping
您可能还想在不使用 summarize() 的情况下从数据框中删除分组。你可以用 ungroup() 来做到这一点。
daily |>
ungroup()
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, ...现在让我们看看当您汇总未分组的数据框时会发生什么。
daily |>
ungroup() |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n()
)
#> # A tibble: 1 × 2
#> avg_delay flights
#> <dbl> <int>
#> 1 12.6 336776您会返回一行,因为 dplyr 将未分组数据框中的所有行视为属于一个组。
3.5.6 .by
dplyr 1.1.0 包括一个新的、实验性的、用于每个操作分组的语法,即 .by 参数。group_by() 和 ungroup() 不会消失,但您现在还可以使用 .by 参数在单个操作中进行分组:
flights |>
summarize(
delay = mean(dep_delay, na.rm = TRUE),
n = n(),
.by = month
)或者如果你想按多个变量分组:
flights |>
summarize(
delay = mean(dep_delay, na.rm = TRUE),
n = n(),
.by = c(origin, dest)
).by 适用于所有动词,优点是您不需要使用 .groups 参数来取消分组消息或在完成后使用 ungroup()。
我们在本章中没有关注这个语法,因为在我们写这本书的时候它是非常新的。我们确实想提及它,因为我们认为它有很多希望并且很可能很受欢迎。您可以在 dplyr 1.1.0 博客文章中了解更多信息。
3.5.7 练习
-
哪家航空公司的平均延误最严重?挑战:你能分清糟糕机场与糟糕承运人的影响吗?为什么/为什么不?(提示:考虑
flights |> group_by(carrier, dest) |> summarize(n())) -
找出从每个目的地出发时延误最严重的航班。
-
一天中的延迟如何变化。用一个图说明你的答案。
-
如果您向
slice_min()和相关函数提供负数n会发生什么? -
根据您刚刚学习的 dplyr verbs 解释
count()的作用。count()的sort参数有什么作用? -
假设我们有以下微型数据框:
df <- tibble(
x = 1:5,
y = c("a", "b", "a", "a", "b"),
z = c("K", "K", "L", "L", "K")
)
a. 写下您认为输出的样子,然后检查您是否正确,并描述 group_by() 的作用。
df |>
group_by(y)b. 写下您认为输出的样子,然后检查您是否正确,并描述 arrange() 的作用。还要评论它与 (a) 部分中的 group_by() 有何不同?
df |>
arrange(y)c. 写下您认为输出的样子,然后检查您是否正确,并描述 pipeline 的作用。
df |>
group_by(y) |>
summarize(mean_x = mean(x))d. 写下您认为输出的样子,然后检查您是否正确,并描述 pipeline 的作用。然后,评论消息的内容。
df |>
group_by(y, z) |>
summarize(mean_x = mean(x))e. 写下您认为输出的样子,然后检查您是否正确,并描述 pipeline 的作用。输出与 (d) 部分中的输出有何不同。
df |>
group_by(y, z) |>
summarize(mean_x = mean(x), .groups = "drop")f. 写下您认为输出的样子,然后检查您是否正确,并描述 pipeline 的作用。两条 pipelines 的输出有何不同?
df |>
group_by(y, z) |>
summarize(mean_x = mean(x))
df |>
group_by(y, z) |>
mutate(mean_x = mean(x))3.6 案例研究:聚合和样本量
每当您进行任何聚合(aggregation)时,包含一个计数 (n()) 总是一个好主意。这样,您就可以确保您不会根据非常少量的数据得出结论。我们将使用 Lahman 包中的一些 baseball 数据来证明这一点。具体来说,我们将比较球员击球次数 (H) 与他们尝试将球投入比赛的次数 (AB) 的比例:
batters <- Lahman::Batting |>
group_by(playerID) |>
summarize(
performance = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
n = sum(AB, na.rm = TRUE)
)
batters
#> # A tibble: 20,730 × 3
#> playerID performance n
#> <chr> <dbl> <int>
#> 1 aardsda01 0 4
#> 2 aaronha01 0.305 12364
#> 3 aaronto01 0.229 944
#> 4 aasedo01 0 5
#> 5 abadan01 0.0952 21
#> 6 abadfe01 0.111 9
#> # ℹ 20,724 more rows当我们绘制击球手的技能(以击球率 performance 衡量)与击球机会的数量(以击球次数 n 衡量)之间的关系时,您会看到两种模式:
-
在击球次数较少的球员中,
performance的差异更大。该图的形状非常有特色:每当您绘制平均值(或其他汇总统计数据)与组大小的关系时,您都会看到变异随着样本大小的增加而减小。 -
技能(
performance)和击球机会 (n) 之间存在正相关关系,因为球队希望给最好的击球手最多的击球机会。batters |>
filter(n > 100) |>
ggplot(aes(x = n, y = performance)) +
geom_point(alpha = 1 / 10) +
geom_smooth(se = FALSE)
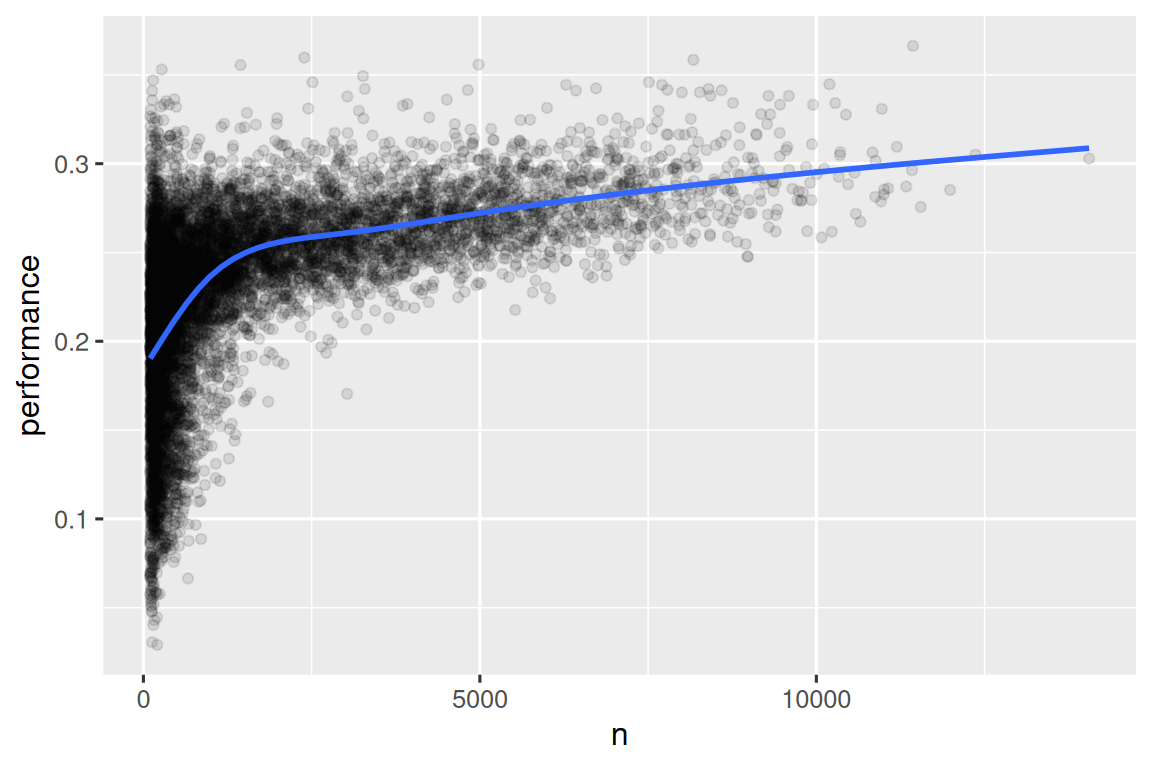
请注意组合 ggplot2 和 dplyr 的便利模式。您只需要记住从用于数据集处理的 |> 切换到用于向绘图添加图层的 +。
这对排名也有重要影响。如果你天真地按 desc(performance) 排序,平均击球率最好的人显然是那些尝试将球打入比赛并碰巧被击中的人,他们不一定是技术最好的球员:
batters |>
arrange(desc(performance))
#> # A tibble: 20,730 × 3
#> playerID performance n
#> <chr> <dbl> <int>
#> 1 abramge01 1 1
#> 2 alberan01 1 1
#> 3 banisje01 1 1
#> 4 bartocl01 1 1
#> 5 bassdo01 1 1
#> 6 birasst01 1 2
#> # ℹ 20,724 more rows您可以在 http://varianceexplained.org/r/empirical_bayes_baseball/ 和 https://www.evanmiller.org/how-not-to-sort-by-average-rating.html 找到这个问题的一个很好的解释以及如何克服它。
3.7 总结
在本章中,您学习了 dplyr 提供的用于处理 data frames 的工具。这些工具大致分为三类:操作行的工具(如 filter() 和 arrange()),操作列的工具(如 select() 和 mutate()),以及那些操纵分组的工具(如 group_by() 和 summarize())。在本章中,我们重点介绍了这些 "whole data frame" 工具,但您还没有学到很多关于可以使用单个变量做什么的知识。我们将在本书的 Transform 部分回到这一点,每一章都会为您提供用于特定类型变量的工具。
在下一章中,我们将回到工作流来讨论代码风格的重要性,让您的代码井井有条,以便您和其他人轻松阅读和理解您的代码。
-
稍后,您将了解
slice_*()系列,它允许您根据行的位置选择行。 -
请记住,在 RStudio 中,查看包含许多列的数据集的最简单方法是
View()。 -
或者
summarise(),如果您喜欢英式英语。 -
cough the law of large numbers cough.
--------------- 本章结束 ---------------
本期翻译贡献:
@TigerZ生信宝库