随着企业数字化转型的加速,分布式架构已成为支撑业务连续性的关键。然而,多数据中心管理面临网络延迟、数据同步偏差、运维工具分散等痛点。据Gartner统计,70%的企业因跨区域监控缺失导致故障响应延迟超2小时。如何构建统一管控体系?ManageEngine OpManager通过分布式监控架构与智能化工具,为多数据中心**智能运维**提供全链路解决方案。
一、多数据中心的 3 大核心矛盾
多数据中心不是 "单数据中心 ×N" 的简单复制,而是从 "集中式管理" 到 "分布式协同" 的范式转变。这种转变中,三个矛盾最突出:
1. 监控 "碎片化" vs 全局可视性需求
某金融机构在华北、华东、华南各有一个数据中心,分别使用不同品牌的网络设备和服务器:华北以华为为主,华东偏爱戴尔,华南则是混合架构。运维团队每天要登录 5 个监控系统,光是整理各区域的性能报表就要花 2 小时。更麻烦的是故障排查 ------ 一次用户投诉 APP 卡顿,团队花了 3 小时才定位到:是华南数据中心的防火墙规则与华东的负载均衡策略冲突,而这种 "跨区域关联故障" 在碎片化监控下几乎是 "盲人摸象"。
核心问题:不同数据中心的硬件品牌、网络架构、监控工具不统一,导致数据孤岛,无法快速建立 "故障 - 影响" 关联。
2. 配置 "差异化" vs 运维一致性要求
连锁企业的 IT 负责人王经理曾遇到一个哭笑不得的问题:总部要求所有数据中心的服务器超时登录锁定时间设为 15 分钟,但半年后审计发现,西南数据中心因 "方便本地维护" 改成了 30 分钟,结果导致一次内部账号被盗用事件。多数据中心的配置差异,往往源于 "本地特殊需求""临时应急操作",但长期积累就会变成 "合规雷区" 和 "故障隐患"。
核心问题:人工配置难以避免地域差异,缺乏统一的配置基线和自动校验机制,导致 "合规成本高、故障溯源难"。
3. 资源 "分散化" vs 协同调度效率
电商大促期间,某平台的北京数据中心负载过高,需要临时将部分流量调度到武汉数据中心。但运维团队发现:武汉节点的存储容量明明有冗余,却因为两地的资源监控数据不同步,直到北京节点出现过载告警,才手动完成调度 ------ 这个过程花了 47 分钟,期间已有 3% 的订单因延迟被取消。
核心问题:跨区域资源状态不透明,依赖人工判断和操作,无法实现 "负载预测 - 自动调度" 的闭环。
二、破局思路:用 "统一 + 自动化" 破解分布式难题
多数据中心运维的本质,是要在 "物理分散" 的架构下实现 "逻辑统一" 的管理。ManageEngine OpManager 的设计逻辑,正是从这一本质出发,通过 "统一监控、自动协同、合规可控" 三大能力解决核心矛盾。
1. 打破数据孤岛:一个控制台看透所有数据中心
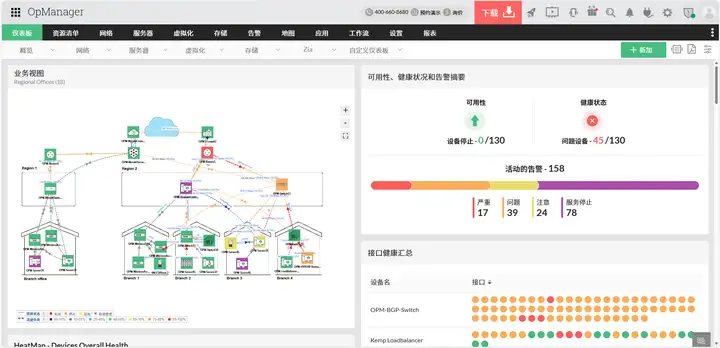
OpManager 的 "多数据中心统一监控" 功能,相当于给运维团队装了一个 "全局仪表盘"。它能对接不同品牌(华为、戴尔、Cisco 等)、不同区域(北京、上海、云端)的设备,将 CPU、内存、带宽、存储等 1000 + 指标汇总到一个界面。
比如某零售企业有 5 个区域数据中心,过去查 "全国 POS 机网络延迟" 需要逐个登录区域监控系统,现在通过 OpManager 的 "地理视图",能直接看到各区域延迟热力图,点击红色区域就能钻取到具体交换机和链路 ------ 故障定位时间从平均 40 分钟缩短到 8 分钟。
更关键的是 "跨区域关联分析"。当上海数据中心的数据库响应变慢时,系统会自动检查是否与北京的存储阵列 IO 延迟、广州的防火墙吞吐量有关联,通过算法生成 "故障影响链"。就像前面提到的 "APP 卡顿" 案例,OpManager 能在 5 分钟内定位到 "华南防火墙规则与华东负载均衡的冲突",并标记出具体的配置差异点。
2. 消除配置差异:用 "基线 + 自动化" 锁死一致性
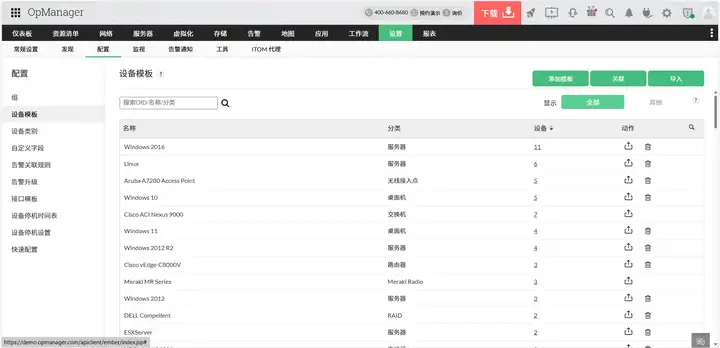
OpManager 的 "配置基线与合规管理" 功能,能从根源上解决 "地域配置差异化" 问题。运维团队可以定义统一的配置模板(比如 "服务器安全基线""网络设备 ACL 规则模板"),一键下发到所有数据中心的同类设备。
比如王经理所在的连锁企业,将 "登录超时锁定 15 分钟" 设为强制基线后,OpManager 会每小时自动校验所有区域的服务器配置,一旦发现西南数据中心的 "30 分钟" 异常,会立即触发告警并提供 "一键恢复基线" 选项。更灵活的是,对于确实需要差异化配置的场景(比如某区域因业务特殊性需调整端口策略),系统会记录 "例外申请" 并纳入审计日志,既满足灵活性又确保可追溯。
针对 "临时操作变永久隐患" 的问题,OpManager 的 "配置变更回滚" 功能很实用:运维人员在华东数据中心临时开放某个端口后,系统会自动记录操作时间和内容,若超过预设的 "24 小时临时窗口" 未恢复,会自动执行回滚,同时通知管理员 ------ 这就避免了 "应急操作忘复原" 的低级错误。
3. 提升协同效率:让资源调度 "预判 + 自动"
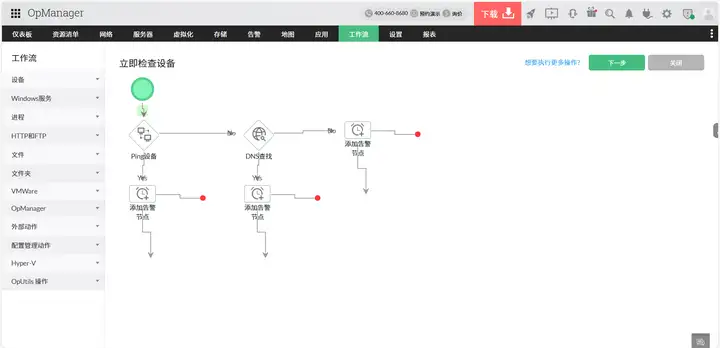
面对 "资源分散化" 导致的调度滞后,OpManager 的 "智能资源规划与自动化调度" 功能能实现 "从被动响应到主动预测"。它会基于历史数据(比如电商大促期间的流量规律),预测未来 24 小时各数据中心的负载趋势,当发现北京节点 CPU 可能在 3 小时后超过 80% 时,会自动触发调度策略:将部分非核心业务迁移到武汉节点的空闲服务器,并调整负载均衡策略。
某电商平台用这套功能后,去年双 11 期间实现了 13 次自动跨区域调度,没有出现一次人工干预,整体资源利用率从 65% 提升到 82%,订单延迟率下降了 90%。
对于跨区域链路管理,OpManager 的 "SDN 协同监控" 能对接不同数据中心的软件定义网络,实时监控 VxLAN 隧道状态、跨区域带宽使用率,并在带宽不足时自动触发 "流量压缩" 或 "优先级调度"。比如当北京到上海的链路带宽达到 90% 时,系统会自动将非关键的日志同步流量降级,优先保障交易数据传输。
三、实战中的两个关键细节
在实际运维中,多数据中心管理还有两个容易被忽略的痛点,而 OpManager 的细节功能恰好能解决:
1. 跨区域告警 "不扰民"
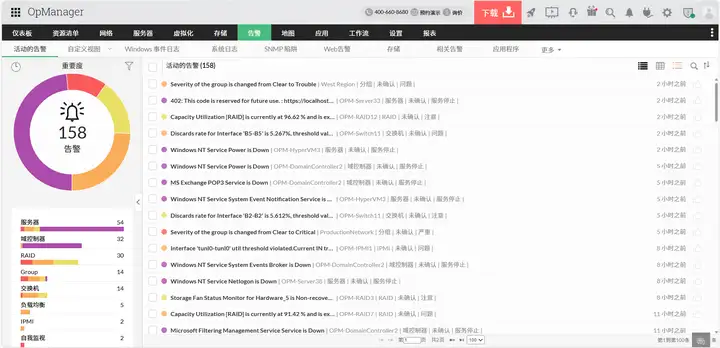
多数据中心的告警风暴是运维人员的噩梦 ------ 深夜同时收到北京、广州、上海的告警,根本分不清优先级。OpManager 的 "智能告警降噪" 能解决这个问题:通过分析告警的 "影响范围""业务关联度""历史出现频率",自动给告警分级。比如 "上海核心交换机故障"(影响全国业务)会标为 "P1 级" 并电话通知负责人,而 "广州某测试服务器离线"(仅影响本地测试)会标为 "P3 级" 并只发邮件 ------ 这让运维人员能把精力放在关键故障上。
2. 异地灾备 "真可用"
很多企业的 "异地灾备" 只是 "摆设",因为平时很少验证灾备切换的有效性。OpManager 的 "灾备演练自动化" 功能,支持一键发起 "模拟灾备切换":比如模拟北京数据中心故障,检查武汉灾备中心是否能在规定时间内接管业务,同时记录切换过程中的性能瓶颈(如数据同步延迟、应用启动时间)。某银行通过每月一次的自动演练,将灾备切换时间从原来的 4 小时优化到 45 分钟,真正实现了 "灾备不白备"。
四、写在最后:多数据中心运维的 "极简主义"
管理多数据中心,本质上是在做 "减法":减少数据孤岛,减少人工干预,减少故障影响。OpManager 的价值,不在于堆砌功能,而在于通过 "统一监控" 让运维人员少切换 10 个系统,通过 "自动化配置" 少做 50 次重复操作,通过 "智能调度" 少一次熬夜应急。
如果你正在经历 "多数据中心像多盘散沙" 的痛苦,不妨从三个问题入手:能不能用一个界面看到所有数据?能不能让配置差异自动消失?能不能让资源调度自己跑起来?------ 这三个问题的答案,或许就是多数据中心运维从 "混乱" 到 "有序" 的关键。
(如果你的企业也有多数据中心管理难题,欢迎在评论区留言具体场景,我们可以一起探讨解决方案~)