学习内容
神经网络(Neural Networks, NNs)作为目前最为流行的人工智能算法,是一种模仿人类大脑结构和功能设计的计算模型,它通过对大量数据的学习和处理,实现了对于各种类别事物的识别、分类、预测等能力。本课程将对神经网络中一些核心概念进行深入解析,包括线性模型、感知机、激活函数、损失函数、卷积神经网络(CNN)、反向传播算法、过拟合与正则化等。
一、神经网络的概念
神经网络(Neural Network,简称NN)是一类模拟生物神经系统结构和功能的计算模型。它由大量的节点(称为"神经元"或"单元")相互连接组成,通过加权连接传递信息,实现对数据的处理和学习。
-
起源背景:受生物神经系统启发,尤其是大脑中神经元之间的连接方式。
-
作用:能够自动从数据中提取特征,进行分类、回归、预测等任务。
-
特点:具有自适应、自学习和容错能力,能够处理复杂的非线性问题。
结构图如下:参考链接:神经网络基础
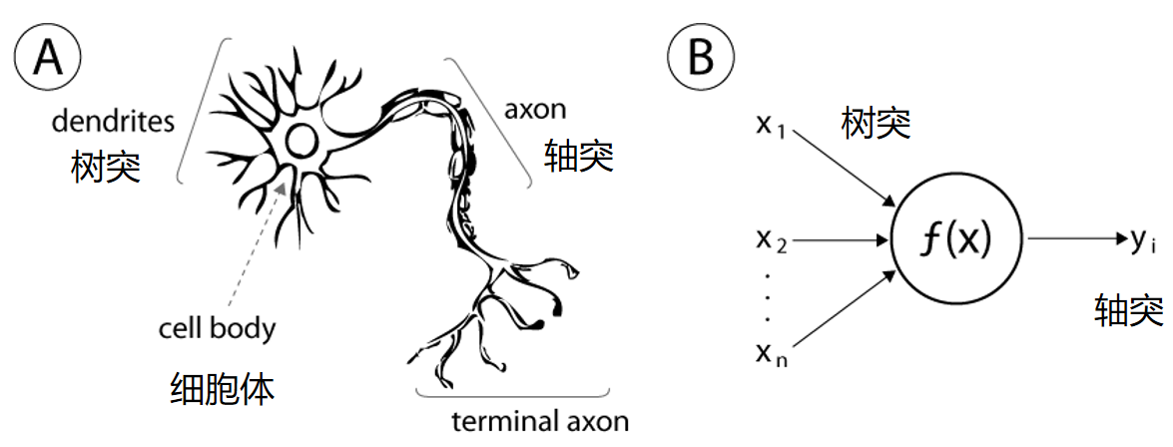
二、神经网络的核心思路
神经网络的核心思想是通过层层的神经元结构,将输入数据映射到输出,通过不断调整连接权重,使得网络输出接近目标值,实现学习。
-
结构组
-
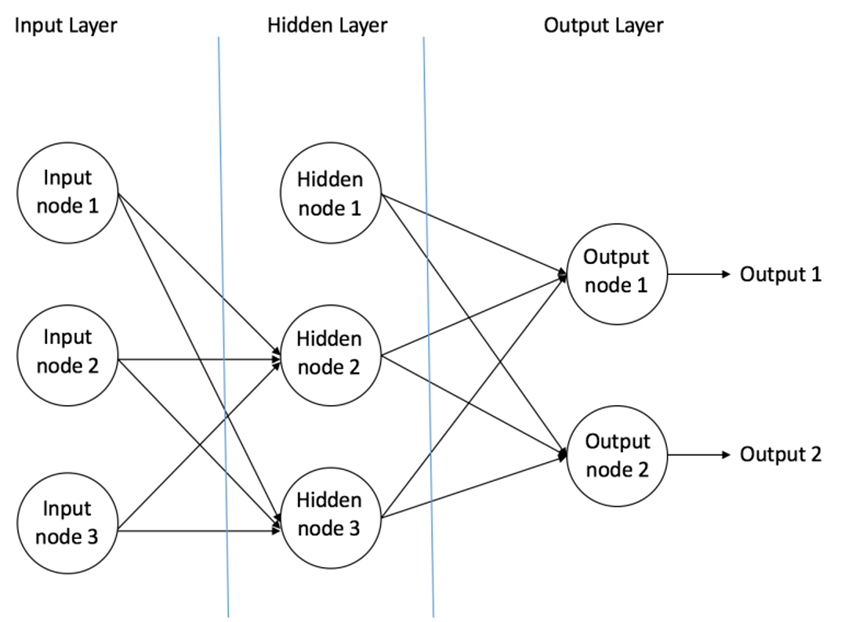
输入层(Input Layer):接收原始数据,如图片像素、文本向量等。
-
隐藏层(Hidden Layers):一层或多层神经元,对输入进行非线性变换,抽取特征。
-
输出层(Output Layer):给出最终的预测或分类结果。
-
-
前向传播(Forward Propagation)
- 输入数据经过每层神经元的加权求和、激活函数处理,逐层传递,最终得到输出。
-
激活函数(Activation Function)
- 为网络引入非线性能力,常用的激活函数有ReLU、Sigmoid、Tanh等。
-
损失函数(Loss Function)
- 用于衡量预测输出与真实标签的差距,如均方误差(MSE)、交叉熵损失等。
-
反向传播(Backpropagation)
-
利用链式法则计算损失函数关于各权重的梯度,将误差从输出层反向传播至输入层。
-
通过梯度下降法更新权重,减少预测误差。
-
-
训练过程
- 数据输入神经网络,经过多轮前向传播和反向传播,逐渐调整权重,网络学习到数据中的模式。
1、线性模型与感知机
1.1线性模型
-
在开始探讨复杂的神经网络之前,首先需要理解最简单的线性模型线性模型是一类基础的机器学习模型,它假设预测目标
-
-
-
b 是偏置(截距)
主要应用
-
回归问题(预测连续值)
-
分类问题(通过加个阈值或激活函数变成分类)
优点
-
简单,易理解
-
训练速度快
-
线性可解释性强
缺点
- 不能很好地拟合非线性数据
1.2. 感知机(Perceptron)
感知机是最早的一种二分类线性分类器,由Frank Rosenblatt在1958年提出。它本质上是一个带有阈值的线性模型,用于判别数据点属于正类还是负类。
公式:
输出
- 通过符号函数把线性输出映射成类别标签
学习算法
-
感知机采用感知机算法:当预测错误时,调整权重
-
更新规则:
-
-
-
其中
多层感知机示意图如下:参考链接:神经网络基础
优点
-
简单有效的线性分类器
-
可以在线更新权重,适合在线学习
缺点
-
只能解决线性可分问题
-
对噪声敏感
-
无法处理非线性问题
1.3. 线性模型与感知机的关系与区别
| 方面 | 线性模型 | 感知机 |
|---|---|---|
| 类型 | 泛指基于线性函数的模型 | 一种具体的线性分类模型 |
| 任务 | 回归、分类均可 | 二分类问题 |
| 输出 | 实数(回归),或者概率/分数 | 离散类别标签(+1或-1) |
| 激活函数 | 可以是恒等函数或其他(如sigmoid) | 符号函数(sign) |
| 学习算法 | 多样(最小二乘、梯度下降等) | 感知机学习算法(基于错误调整权重) |
| 适用范围 | 更广 | 仅线性可分二分类问题 |
1.4.激活函数
激活函数是在每个神经元内部使用的一个非线性变换,用于决定该神经元是否应该被激活。常用的激活函数有Sigmoid、ReLU(Rectified Linear Unit)、tanh等。这些函数使得神经网络能够在多个层次上捕捉数据中的复杂模式。
常用的激活函数的实现:
,
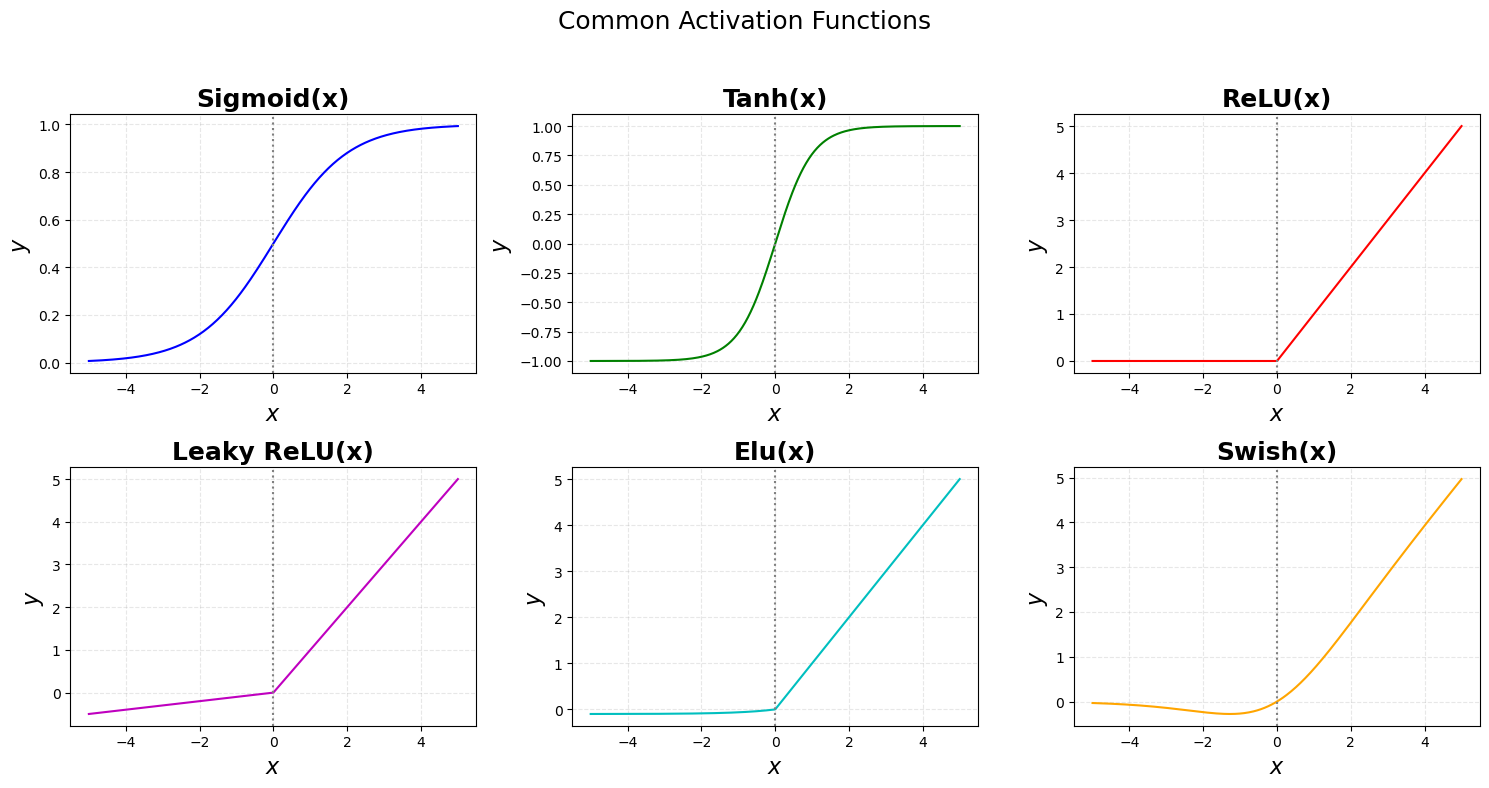
pythonimport numpy as np import matplotlib.pyplot as plt def sigmoid(x): return 1/(1+np.exp(-x)) def tanh(x): return(np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x)); def Relu(x): return np.maximum(0,x) def LRelu(x,alpha = 0.1): return np.where(x>0,x,alpha*x) def Elu(x,alpha = 0.1): return np.where(x>0,x,alpha*(np.exp(x)-1)) def Swish(x): return x*sigmoid(x) x = np.linspace(-5,5,400); y_sigmoid = sigmoid(x); y_tanh = tanh(x); y_Relu = Relu(x); y_LRelu = LRelu(x); y_Elu = Elu(x); y_Swish = Swish(x); fig,axs = plt.subplots(2,3,figsize = (15,8)) # 通用参数 xlabel = r"$x$" ylabel = r"$y$" title_fontsize = 18 label_fontsize = 16 linewidth = 2 grid_alpha = 0.3 grid_linestyle = '--' vline_color = 'gray' vline_style = ':' axs[0,0].plot(x,y_sigmoid,color = 'b'); axs[0,0].axvline(x=0, color=vline_color, linestyle=vline_style) axs[0,0].set_title('Sigmoid(x)', fontsize=title_fontsize, fontweight='bold') axs[0,0].set_xlabel(xlabel, fontsize=label_fontsize) axs[0,0].set_ylabel(ylabel, fontsize=label_fontsize) axs[0,0].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) # Tanh axs[0,1].plot(x, y_tanh, color='g') axs[0,1].axvline(x=0, color=vline_color, linestyle=vline_style) axs[0,1].set_title('Tanh(x)', fontsize=title_fontsize, fontweight='bold') axs[0,1].set_xlabel(xlabel, fontsize=label_fontsize) axs[0,1].set_ylabel(ylabel, fontsize=label_fontsize) axs[0,1].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) # ReLU axs[0,2].plot(x, y_Relu, color='r') axs[0,2].axvline(x=0, color=vline_color, linestyle=vline_style) axs[0,2].set_title('ReLU(x)', fontsize=title_fontsize, fontweight='bold') axs[0,2].set_xlabel(xlabel, fontsize=label_fontsize) axs[0,2].set_ylabel(ylabel, fontsize=label_fontsize) axs[0,2].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) # Leaky ReLU axs[1,0].plot(x, y_LRelu, color='m') axs[1,0].axvline(x=0, color=vline_color, linestyle=vline_style) axs[1,0].set_title('Leaky ReLU(x)', fontsize=title_fontsize, fontweight='bold') axs[1,0].set_xlabel(xlabel, fontsize=label_fontsize) axs[1,0].set_ylabel(ylabel, fontsize=label_fontsize) axs[1,0].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) # Elu axs[1,1].plot(x, y_Elu, color='c') axs[1,1].axvline(x=0, color=vline_color, linestyle=vline_style) axs[1,1].set_title('Elu(x)', fontsize=title_fontsize, fontweight='bold') axs[1,1].set_xlabel(xlabel, fontsize=label_fontsize) axs[1,1].set_ylabel(ylabel, fontsize=label_fontsize) axs[1,1].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) #Swish(x) axs[1,2].plot(x, y_Swish, color='orange') axs[1,2].axvline(x=0, color=vline_color, linestyle=vline_style) axs[1,2].set_title('Swish(x)', fontsize=title_fontsize, fontweight='bold') axs[1,2].set_xlabel(xlabel, fontsize=label_fontsize) axs[1,2].set_ylabel(ylabel, fontsize=label_fontsize) axs[1,2].grid(True, linestyle=grid_linestyle, alpha=grid_alpha) # 设置整体标题和间距 fig.suptitle('Common Activation Functions', fontsize=18) plt.tight_layout(rect=[0, 0, 1, 0.95]) # 留出上方空间给suptitle plt.show()
1.5.损失函数与优化目标
损失函数是用来量化模型预测结果与实际结果之间差异的一种度量方式。常见的损失函数包括均方误差(MSE)用于回归任务,交叉熵损失用于分类任务。优化的目标是通过调整模型参数来最小化损失函数的值,从而提高模型的准确性。
1.6.反向传播算法
反向传播算法是训练神经网络的核心技术之一。它利用链式法则计算每一层的梯度,并根据这些梯度更新权重以减小损失函数的值。这个过程从输出层开始一直回溯到输入层,因此称为"反向"传播。
1.7.过拟合与正则化
当一个模型在训练集上的表现非常好,但在未见过的数据(测试集)上表现不佳时,就发生了过拟合现象。为了避免过拟合,通常会采用正则化方法,如L1正则化、L2正则化或Dropout技术。正则化通过限制模型复杂度或者随机丢弃部分神经元来防止模型过度拟合训练数据。
三、深度学习中常见的神经网络类型
深度学习是多层神经网络(深度神经网络)的应用与发展,常见网络结构包括:
1. 多层感知机(MLP,Multi-Layer Perceptron)
-
最基础的全连接神经网络。
-
由输入层、多个隐藏层和输出层组成。
-
适合处理结构化数据。
2. 卷积神经网络(CNN,Convolutional Neural Network)
-
主要用于图像处理。
-
通过卷积层提取局部特征,使用池化层降维,减少参数量。
-
代表网络:LeNet、AlexNet、VGG、ResNet等。
3. 循环神经网络(RNN,Recurrent Neural Network)
-
适合处理序列数据(如文本、时间序列)。
-
网络节点之间存在循环连接,能够记忆序列中的上下文信息。
-
变体:LSTM(长短期记忆网络)、GRU(门控循环单元)。
4. 生成对抗网络(GAN,Generative Adversarial Network)
-
由生成器和判别器两个网络组成,互相对抗训练。
-
用于生成逼真的图像、视频等数据。
5. 变分自编码器(VAE,Variational Autoencoder)
-
生成模型的一种,通过编码器将数据映射到潜在空间,解码器重构数据。
-
用于数据压缩和生成。
6. Transformer
-
基于自注意力机制(Self-Attention)。
-
目前NLP领域的主流模型结构,如BERT、GPT系列。
-
擅长处理长距离依赖和并行计算。
四、总结
| 神经网络核心步骤 | 说明 |
|---|---|
| 输入层 | 接收数据 |
| 隐藏层 | 非线性特征抽取 |
| 激活函数 | 引入非线性 |
| 输出层 | 给出预测 |
| 损失函数 | 计算预测误差 |
| 反向传播 | 计算梯度并更新权重 |
| 训练 | 多轮迭代使误差最小 |