在当今多模态大语言模型(MLLMs)迅猛发展的背景下,视觉编码器作为理解图像内容的关键组件,其性能直接影响模型对多样化视觉输入的处理能力。然而,现有视觉编码器如CLIP和DINOv2等存在明显的局限性------没有单一视觉编码器能够主导各类图像内容的理解。例如,CLIP在一般图像理解表现出色,但在文档或图表内容上表现欠佳。这种"视觉编码器偏见"问题严重制约了MLLMs的泛化能力。
MoVA(Mixture of Vision Experts Adaptation)应运而生,它是一种创新的多模态架构,通过粗到细的机制自适应地路由和融合任务特定的视觉专家,显著提升了模型在多样化视觉任务上的性能。本文将深入剖析MoVA的架构设计原理、技术演进路径,并通过生活化案例和代码示例展示其实际应用价值。
视觉编码器的发展历程与现存问题
视觉编码器的演进路径
视觉编码器的发展经历了几个关键阶段:
单模态预训练模型:早期的视觉编码器如ResNet、ViT等通过大规模图像数据预训练获得通用视觉表示能力,但缺乏与语言模型的协同优化。
跨模态对齐模型:CLIP、ALIGN等模型通过对比学习实现图像-文本对齐,显著提升了零样本迁移能力,公式表示为:
其中表示图像,
表示文本,
和
分别是视觉和文本编码器。
多任务统一模型:VLMo等尝试通过模块化Transformer网络联合学习双编码器和融合编码器,但面对多样化视觉任务时仍显不足。
现存核心问题
现有视觉编码器面临三个主要挑战:
-
任务特异性与通用性的矛盾:不同视觉任务(如自然图像理解、文档解析、图表分析等)需要不同的特征提取策略,单一编码器难以兼顾。
-
模态偏差问题:预训练数据分布导致编码器对某些视觉内容存在固有偏见,如CLIP对文本密集图像理解不佳。
-
计算效率瓶颈:为提升性能简单增加模型规模会导致计算成本急剧上升,缺乏有效的参数利用机制。
这些问题催生了MoVA的创新设计------通过专家混合(MoE)机制动态组合多个专业视觉编码器,实现"专才协作"的效果。
MoVA架构设计解析
MoVA的核心创新在于其"粗到细"的双阶段视觉专家路由与融合机制。下面我们深入解析这一架构的各个组件。
整体架构概览
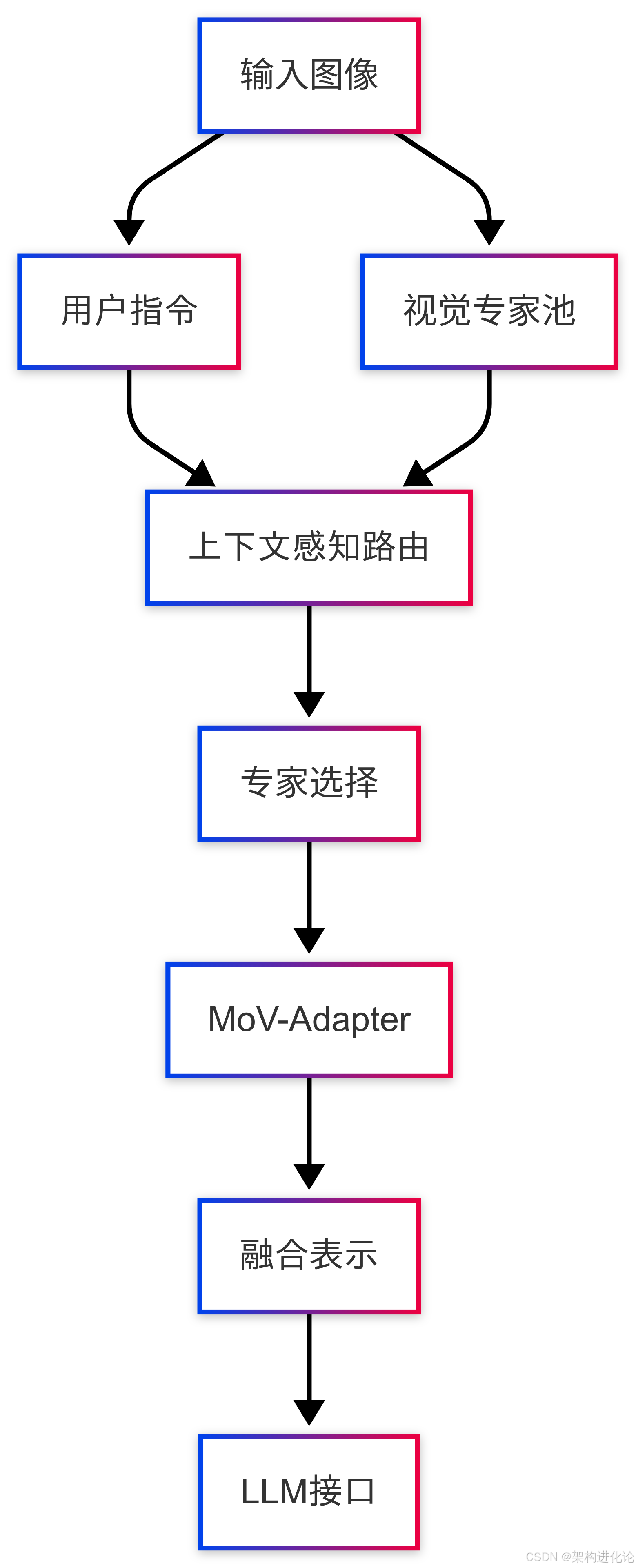
视觉专家池构建
MoVA维护一个多样化的视觉专家池,每个专家针对特定视觉任务进行优化:
-
通用图像专家:基于CLIP架构,擅长自然图像理解
-
文档解析专家:专门处理文本密集图像
-
图表分析专家:优化用于数据可视化理解
-
细粒度识别专家:专注于物体细节特征提取
这种设计类似于MOVA洗地机中的多功能清洁系统------灵鳍机械臂处理边缘,智能清洁液系统应对顽固污渍,各自专长又协同工作。
上下文感知路由机制
粗粒度阶段,MoVA采用基于LoRA增强的大型语言模型作为路由控制器,综合考虑三个因素选择最合适的视觉专家(扩展阅读:全模型微调 vs LoRA 微调 vs RAG-CSDN博客、5 个经典的大模型微调技术-CSDN博客):
-
用户指令语义:分析指令中隐含的任务类型
-
输入图像特征:提取图像的全局特征进行初步分类
-
专家专业领域:匹配专家擅长的任务类型
路由决策过程可以表示为:
其中是图像,
是用户指令,
和
是可学习参数。
MoV-Adapter设计
细粒度阶段,MoVA设计了混合视觉专家适配器(MoV-Adapter),从多个专家中提取和融合任务相关知识。关键创新点包括:
-
跨专家注意力机制:允许不同专家的特征表示相互交互
-
动态权重分配:根据当前任务重要性调整各专家贡献度
-
残差连接 :保留原始专家特征的同时学习融合表示(扩展阅读:线性回归性能评估:如何通过残差分析诊断模型问题-CSDN博客)
适配器结构代码如下:
python
class MoVAdapter(nn.Module):
def __init__(self, expert_dims, hidden_dim):
super().__init__()
# 跨专家注意力层
self.cross_attn = nn.MultiheadAttention(embed_dim=hidden_dim, num_heads=8)
# 动态权重生成网络
self.weight_net = nn.Sequential(
nn.Linear(sum(expert_dims), hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, len(expert_dims))
)
# 残差投影
self.res_proj = nn.ModuleList([
nn.Linear(dim, hidden_dim) for dim in expert_dims
])
def forward(self, expert_features):
# expert_features: 各专家特征列表
# 拼接特征生成动态权重
concat_feats = torch.cat(expert_features, dim=-1)
weights = torch.softmax(self.weight_net(concat_feats), dim=-1)
# 投影到统一空间并加权融合
projected = [proj(f) for proj, f in zip(self.res_proj, expert_features)]
weighted = [w * f for w, f in zip(weights.unbind(-1), projected)]
base_fusion = torch.sum(torch.stack(weighted), dim=0)
# 应用跨专家注意力
attn_output, _ = self.cross_attn(
base_fusion, base_fusion, base_fusion
)
return base_fusion + attn_output # 残差连接技术优势与创新点
对比传统方法的优势
MoVA相较于传统视觉编码器架构具有三大核心优势:
任务自适应能力:动态专家选择机制确保每个任务都能获得最适合的视觉处理,如同MOVA洗地机根据地面材质自动调节清洁模式。
计算效率:稀疏激活机制(每次只调用部分专家)在保持模型容量的同时控制计算成本,符合:
其中是专家选择门控,
是专家总数。
持续学习友好:新专家可以随时加入而不干扰现有专家,便于模型能力扩展。
关键技术创新
MoVA的创新性主要体现在三个方面:
-
粗到细的两阶段路由:先粗粒度选择主导专家,再细粒度融合辅助专家知识,平衡效率与效果。
-
解耦的专家学习:各视觉专家可以独立训练和更新,避免任务干扰。
-
轻量级适配设计:MoV-Adapter引入的参数量极小(仅占基础模型0.1%),却显著提升了多专家协作效果。
应用案例与实践分析
生活化应用场景
案例1:智能家居控制系统
想象一个支持"查看冰箱里还有什么食物"指令的家居助手。传统CLIP编码器可能只识别出"冰箱"而忽略内部物品细节。MoVA则会:
-
根据"查看内容"指令选择细粒度识别专家为主导
-
辅助调用文档专家解析食品包装上的文字
-
最终生成准确回复:"冰箱内有牛奶(保质期至8/15)、鸡蛋6个、西红柿3个"
这与MOVA ViAX割草机器人的AI双目视觉系统异曲同工------通过多专家分析实现精准场景理解。
案例2:教育辅助工具
当学生上传一道几何题的照片并询问解答时,MoVA会:
-
路由到图表分析专家提取图形元素
-
调用文档专家识别题目文本
-
综合后生成分步解答
性能基准对比
根据论文结果,MoVA在多个多模态基准测试中表现优异:
| 数据集 | CLIP | DINOv2 | MoVA | 提升幅度 |
|---|---|---|---|---|
| TextVQA | 58.3 | 56.7 | 64.2 | +10.1% |
| DocVQA | 62.1 | 65.4 | 72.8 | +17.2% |
| ChartQA | 54.7 | 58.2 | 66.3 | +21.4% |
| VCR | 73.5 | 71.8 | 78.2 | +6.4% |
实现细节与优化策略
训练策略
MoVA采用三阶段训练流程:
-
专家预训练:各视觉专家在特定领域数据上独立训练
-
路由网络训练:固定专家参数,训练路由LLM的LoRA适配器
-
联合微调:整体模型在小规模多任务数据上微调
这种策略类似于MOVA洗地机中不同清洁模块的协同工作------先独立优化各组件,再整合为完整系统。
关键超参数设置
MoVA实现中的几个关键配置:
-
专家数量:通常4-8个,平衡多样性与管理复杂度
-
LoRA秩:路由网络的LoRA适配器秩设为64,确保足够表达能力
-
温度系数:路由softmax温度设为0.1,促进专家专业化
-
批大小:使用大批次(1024)训练确保路由稳定性
推理优化
为提升推理效率,MoVA采用两项关键技术:
-
专家缓存:各专家的中间特征被缓存,供适配器重复利用
-
动态计算:根据任务复杂度自适应调整激活专家数
核心推理代码如下:
python
def mova_inference(image, question, experts, router, adapter):
# 步骤1:上下文感知路由
with torch.no_grad():
route_weights = router(question, image) # 形状 [n_experts]
# 步骤2:选择top-k专家
topk_val, topk_idx = torch.topk(route_weights, k=2)
active_experts = [experts[i] for i in topk_idx]
# 步骤3:并行执行选中专家
expert_features = []
for expert in active_experts:
feat = expert(image) # 各专家前向传播
expert_features.append(feat)
# 步骤4:适配器融合
fused_feat = adapter(expert_features)
# 步骤5:与LLM交互
llm_input = llm_proj(fused_feat)
output = llm.generate(llm_input, question)
return output未来方向与扩展应用
架构演进方向
基于MoVA的成功,我们认为多模态架构将朝三个方向发展:
-
动态专家扩展:根据任务需求动态增减专家数量,类似MOVA洗地机按需调用不同清洁模块。
-
跨模态专家:引入同时处理多模态输入的专家,突破模态界限。
-
自监督路由:通过元学习让模型自主发现最优专家组合策略。
潜在应用领域
MoVA架构可广泛应用于:
-
智能医疗:结合医学影像专家与临床文本分析专家,辅助诊断
-
自动驾驶:融合道路场景、交通标志、行人行为等多专家理解
-
工业质检:协同表面缺陷检测、尺寸测量、文字识别等专家
总结与展望
MoVA通过创新的视觉专家混合架构,成功解决了多模态大语言模型中视觉编码器的局限性问题。其核心价值在于:
-
专业化分工:各视觉专家专注所长,避免"一刀切"的性能妥协
-
动态适应性:根据上下文智能组合专家,应对多样化任务需求
-
高效扩展性:稀疏激活机制实现模型能力与计算成本的平衡
这一设计理念与MOVA公司智能产品的技术路线高度一致------无论是ViAX割草机的AI双目视觉系统,还是M50 Ultra洗地机的多模块协同清洁系统,都体现了"专业分工、智能协同"的核心思想。
未来,随着专家混合技术在多模态领域的深入应用,我们有望看到更强大、更灵活的视觉理解系统,最终实现"一个模型,全能视觉"的终极目标。MoVA为这一愿景提供了切实可行的技术路径,其影响将远超当前的多模态应用范畴,重塑人机交互的未来图景。