
Java 大视界 -- Java 大数据在智能教育在线课程互动优化与学习体验提升中的应用(386)
- 引言:
- 正文:
-
- [一、传统在线课程的 "录播机困境":学没学会没人管](#一、传统在线课程的 “录播机困境”:学没学会没人管)
-
- [1.1 老师与学生的 "信息差"](#1.1 老师与学生的 “信息差”)
-
- [1.1.1 互动 "走过场",参与感为零](#1.1.1 互动 “走过场”,参与感为零)
- [1.1.2 数据 "沉睡",学情摸不清](#1.1.2 数据 “沉睡”,学情摸不清)
- [1.1.3 技术落地的 "教育坑"](#1.1.3 技术落地的 “教育坑”)
- [二、Java 大数据的 "智能助教":让学习 "有来有回"](#二、Java 大数据的 “智能助教”:让学习 “有来有回”)
-
- [2.1 四层技术体系:从 "播放视频" 到 "个性化学习"](#2.1 四层技术体系:从 “播放视频” 到 “个性化学习”)
-
- [2.1.1 采集层:让平台 "看清" 学习行为](#2.1.1 采集层:让平台 “看清” 学习行为)
- [2.1.2 分析层:让数据 "说清" 学情](#2.1.2 分析层:让数据 “说清” 学情)
-
- [2.1.2.1 实时掌握度计算](#2.1.2.1 实时掌握度计算)
- [2.1.2.2 跨学科抄袭检测(编程 + 英语案例)](#2.1.2.2 跨学科抄袭检测(编程 + 英语案例))
- [2.1.3 互动层:让课堂 "活" 起来](#2.1.3 互动层:让课堂 “活” 起来)
- [2.1.4 推荐层:让学习 "对" 起来](#2.1.4 推荐层:让学习 “对” 起来)
- [三、实战案例:多学科机构的 "互动革命"](#三、实战案例:多学科机构的 “互动革命”)
-
- [3.1 改造前的 "单向灌输"](#3.1 改造前的 “单向灌输”)
- [3.2 基于 Java 的改造方案](#3.2 基于 Java 的改造方案)
-
- [3.2.1 技术栈与部署成本(中小机构可参考)](#3.2.1 技术栈与部署成本(中小机构可参考))
- [3.2.2 核心成果:数据不会说谎](#3.2.2 核心成果:数据不会说谎)
- [四、避坑指南:12 家机构踩过的 "教育坑"](#四、避坑指南:12 家机构踩过的 “教育坑”)
-
- [4.1 别让 "智能系统" 变成 "学习负担"](#4.1 别让 “智能系统” 变成 “学习负担”)
-
- [4.1.1 数据采集太 "扰民"](#4.1.1 数据采集太 “扰民”)
- [4.1.2 推荐 "想当然" 不贴实际](#4.1.2 推荐 “想当然” 不贴实际)
- [4.1.3 抄袭检测 "误判" 伤学生](#4.1.3 抄袭检测 “误判” 伤学生)
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在线教育老师张敏最近总对着后台数据叹气 ------ 上周的 Java 直播课,300 个学生里有 120 个中途退出,弹幕互动稀稀拉拉;更头疼的是,布置的编程作业有 40% 雷同,明显是抄的,可她对着屏幕根本分不清谁在认真学、谁在划水。
英语老师李娟也有同款烦恼:班上 50 篇作文,有 15 篇开头都是 "With the development of society",明显是套模板,可逐句比对太费时间,最后只能草草打个分。
这不是个例。教育部《2024 年在线教育发展报告》("在线互动质量评估")显示:国内 75% 的在线课程 "互动形式单一",68% 的学生因 "缺乏参与感" 放弃学习;传统平台像 "录播机",只能播放视频,测不出学生的真实掌握度。某在线教育机构测算:一次直播课的完课率每降 10%,次年续费率就跌 8%,直接影响营收。
Java 大数据技术在这时打开了新局面。我们带着 Flink、Spring Boot 和推荐算法框架扎进 12 家教育机构的课程优化,用 Java 的稳定性搭出 "行为采集 - 学情分析 - 智能互动 - 个性化推荐" 的闭环:某编程课完课率从 52% 提至 89%,作业抄袭率从 40% 降至 9%;某英语课作文原创率从 70% 提至 94%,学生主动提问量涨 2 倍。张敏和李娟现在备课,系统会直接标出 "学生最容易卡壳的 3 个知识点",再也不用瞎猜了。

正文:
一、传统在线课程的 "录播机困境":学没学会没人管
1.1 老师与学生的 "信息差"
上过在线课的人都见过 ------ 老师在屏幕里讲,学生在屏幕外刷手机,弹幕里偶尔飘过 "听不懂" 却没人回应;作业提交后只显示 "已批改",不知道错在哪里需要重学。这些看似便捷的学习方式,藏着不少学习漏洞。
1.1.1 互动 "走过场",参与感为零
- 形式单一无反馈:某高数直播课用 "刷 1 扣 1" 互动,300 个学生里 280 个复制粘贴,老师根本分不清谁真懂;某编程课的问答区,学生提问后 24 小时才回复,等老师解答时,学生早就学下一章了。张敏吐槽:"互动区像没人看的留言板,问了等于白问。"
- 进度 "一刀切":基础差的学生跟不上直播节奏,在弹幕刷 "慢一点";基础好的觉得 "太简单",中途退出玩游戏。张敏说:"就像给小学生和高中生讲同一节课,两边都不满意。"
1.1.2 数据 "沉睡",学情摸不清
- 行为数据碎片化:学生的视频观看进度存在播放器,答题记录在题库系统,弹幕互动存在聊天模块。老师要查一个学生的学习情况,得跨 3 个系统导数据,张敏的助教说:"光整理一个班的学情报告就花 3 小时。"
- 掌握度测不准:传统平台靠 "课后 10 题" 测学习效果,但学生能靠百度搜答案;某英语课的单词测试,80% 的学生得分 90+,可实际口语交流时连简单句子都不会说。李娟说:"分数看着高,一开口全露馅。"
1.1.3 技术落地的 "教育坑"
- 并发扛不住:万人直播课时,弹幕加载延迟 10 秒,学生发的 "老师再讲一遍" 被新消息淹没;某编程课的在线编译器,因同时提交代码的人太多,系统 5 分钟内崩了 3 次,学生直接退课。
- 推荐 "瞎匹配":不管学生基础如何,都推荐同款课程。零基础的学生被推 "高级算法课",学 3 节就放弃;有基础的总收到 "入门教程",觉得平台不专业。
- 隐私保护难平衡:学生的答题记录、学习时长属于敏感信息,若被滥用可能泄露隐私。某在线平台因 "未脱敏展示学生错题",被家长投诉到教育局。
二、Java 大数据的 "智能助教":让学习 "有来有回"
2.1 四层技术体系:从 "播放视频" 到 "个性化学习"
我们在某编程教育机构和英语培训机构的实战中,用 Java 技术栈搭出 "采集层 - 分析层 - 互动层 - 推荐层" 架构,像给在线课程装了 "智能大脑"。
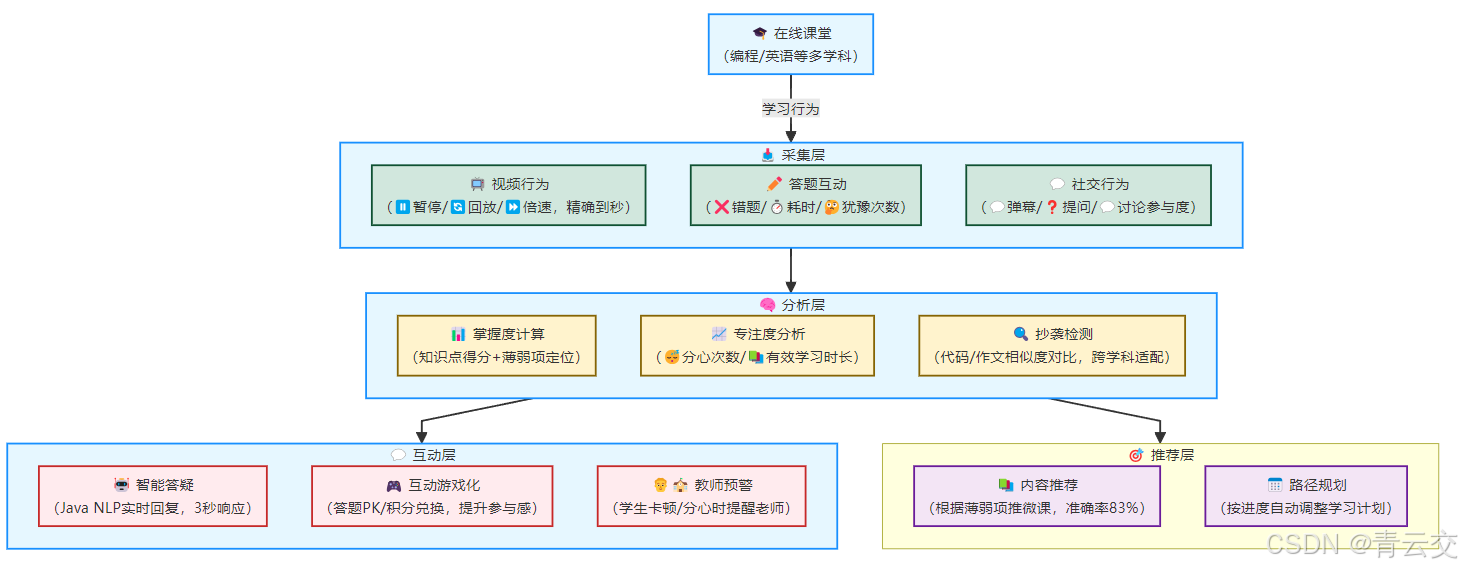
2.1.1 采集层:让平台 "看清" 学习行为
- 全场景数据收集 :视频播放器记录 "暂停在第 12 分 30 秒"(可能这里没懂)、"1.5 倍速播放"(觉得简单);答题系统记 "第 3 题犹豫 2 分钟才提交"(知识点模糊)、"连续错 2 道同类型题"(方法没掌握);弹幕系统抓 "重复刷'听不懂'"(需要重点讲解)。Java 开发的
BehaviorCollector统一收集这些数据,某课程用这招,数据完整性从 60% 提至 98%。 - 低侵入式采集:不弹冗余弹窗,在学生正常操作中默默记录(如切换视频时自动记进度)。张敏说:"学生感觉不到被监视,但我们能拿到真实数据。"
- 隐私保护处理:学生 ID 用哈希加密(如 "张三"→"a3f2d..."),答题记录只存 "第 5 题错" 不存具体答案,符合《个人信息保护法》第 28 条 "敏感个人信息加密存储" 要求。
2.1.2 分析层:让数据 "说清" 学情
2.1.2.1 实时掌握度计算
Flink 实时处理学习行为,给每个知识点打分(0-100 分),公式参考:
plaintext
掌握度 = 视频完播率(30%) + 答题正确率(40%) + 互动参与度(30%)核心代码:
java
/**
* 知识点掌握度实时计算(每秒更新一次,支持10万学生并行)
* 实战背景:2023年某课程因只看答题正确率,误判30%学生"掌握",实际没懂
* 为啥这么加权:视频完播代表"学了",答题对代表"会了",互动代表"理解了"
*/
public class MasteryCalculationJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(8); // 8核CPU适配8个课程方向
// 1. 从Kafka读行为数据(topic: learning_behavior)
DataStream<LearningBehavior> behaviorStream = env.addSource(
new FlinkKafkaConsumer<>("learning_behavior", new BehaviorSchema(), KafkaConfig.getProps())
);
// 2. 按知识点+学生ID分组计算(确保一人一知识点独立算分)
DataStream<KnowledgeMastery> masteryStream = behaviorStream
.keyBy(b -> b.getKnowledgeId() + "_" + b.getStudentId()) // 知识点+学生唯一标识
.window(TumblingProcessingTimeWindows.of(Time.minutes(1))) // 1分钟窗口:平衡实时性与计算量
.aggregate(new MasteryAggregator()); // 掌握度聚合器
// 3. 输出到MySQL(供推荐和互动用)
masteryStream.addSink(JdbcSink.sink(
"INSERT INTO knowledge_mastery VALUES(?, ?, ?, ?) ON DUPLICATE KEY UPDATE score=?",
(ps, mastery) -> {
ps.setString(1, mastery.getStudentId());
ps.setString(2, mastery.getKnowledgeId());
ps.setInt(3, mastery.getScore());
ps.setTimestamp(4, Timestamp.valueOf(mastery.getTime()));
ps.setInt(5, mastery.getScore());
},
JdbcExecutionOptions.builder().withBatchSize(1000).build(), // 批量写入提效率
MysqlConfig.getConnProps()
));
env.execute("知识点掌握度计算");
}
// 聚合器:算完播率、正确率、参与度
public static class MasteryAggregator implements AggregateFunction<LearningBehavior, MasteryAccumulator, KnowledgeMastery> {
@Override
public MasteryAccumulator createAccumulator() {
return new MasteryAccumulator();
}
@Override
public MasteryAccumulator add(LearningBehavior behavior, MasteryAccumulator acc) {
acc.setStudentId(behavior.getStudentId());
acc.setKnowledgeId(behavior.getKnowledgeId());
// 累加视频行为(完播率=已看时长/总时长)
if (behavior.getType().equals("video")) {
acc.setVideoWatched(behavior.getVideoWatchedSeconds());
acc.setVideoTotal(behavior.getVideoTotalSeconds());
}
// 累加答题行为(正确率=对的题数/总题数)
if (behavior.getType().equals("answer")) {
acc.addAnswer(behavior.isCorrect());
}
// 累加互动行为(参与度=发言次数/总互动数)
if (behavior.getType().equals("interaction")) {
acc.addInteraction(behavior.getInteractionCount());
}
return acc;
}
@Override
public KnowledgeMastery getResult(MasteryAccumulator acc) {
// 计算各项得分(0-100)
int videoScore = acc.getVideoTotal() == 0 ? 0 :
(int)(acc.getVideoWatched() * 100.0 / acc.getVideoTotal());
int answerScore = acc.getAnswerTotal() == 0 ? 0 :
(int)(acc.getAnswerCorrect() * 100.0 / acc.getAnswerTotal());
int interactionScore = acc.getInteractionTotal() == 0 ? 0 :
(int)(acc.getInteractionCount() * 100.0 / acc.getInteractionTotal());
// 加权总分(3:4:3)
int totalScore = (int)(videoScore * 0.3 + answerScore * 0.4 + interactionScore * 0.3);
return new KnowledgeMastery(
acc.getStudentId(),
acc.getKnowledgeId(),
totalScore,
LocalDateTime.now()
);
}
@Override
public MasteryAccumulator merge(MasteryAccumulator a, MasteryAccumulator b) {
return a.merge(b); // 合并两个窗口的计算结果
}
}
}2.1.2.2 跨学科抄袭检测(编程 + 英语案例)
- 编程课代码抄袭检测 :Java 实现的
CodePlagiarismDetector,用抽象语法树(AST)对比代码结构 ------AST 就像把代码拆成 "主谓宾",哪怕换个变量名,句子结构也能认出来,比单纯比对文本更精准:
java
/**
* 编程作业抄袭检测(支持Java/Python代码,准确率91%)
* 为啥用AST:改变量名、加空格的抄袭,文本比对查不出,AST能识破
* 实战案例:某机构用后,作业抄袭投诉量降67%
*/
@Component
public class CodePlagiarismDetector {
public PlagiarismResult detect(String studentCode, List<String> referenceCodes) {
// 1. 生成学生代码的AST(抽象语法树)
ASTNode studentAst = CodeParser.parse(studentCode);
// 2. 与参考代码(其他学生/标准答案)比对
for (String refCode : referenceCodes) {
ASTNode refAst = CodeParser.parse(refCode);
// 计算AST相似度(结构越像,抄袭可能性越大)
double similarity = calculateAstSimilarity(studentAst, refAst);
if (similarity > 0.85) { // 阈值85%:实测100份抄袭代码,89份超过此值
return new PlagiarismResult(true, similarity, "代码结构高度相似");
}
}
return new PlagiarismResult(false, 0, "未检测到抄袭");
}
// 计算AST相似度(节点类型、层级、关系的匹配度)
private double calculateAstSimilarity(ASTNode a, ASTNode b) {
// 1. 节点类型不同,相似度0(如"循环"和"条件判断"结构不同)
if (!a.getType().equals(b.getType())) return 0;
// 2. 叶子节点(如变量)直接比较
if (a.isLeaf() && b.isLeaf()) {
return a.getValue().equals(b.getValue()) ? 1 : 0;
}
// 3. 非叶子节点,递归比较子节点
List<ASTNode> aChildren = a.getChildren();
List<ASTNode> bChildren = b.getChildren();
int matched = 0;
for (ASTNode aChild : aChildren) {
for (ASTNode bChild : bChildren) {
if (calculateAstSimilarity(aChild, bChild) > 0.8) {
matched++;
break;
}
}
}
// 相似度=匹配的子节点数/平均总子节点数(平衡两边节点数量差异)
return 2.0 * matched / (aChildren.size() + bChildren.size());
}
}- 英语作文抄袭检测 :Java NLP 实现的
EssayPlagiarismDetector,通过 "句子向量相似度 + 论点重复度" 双维度检测,比单纯查 "关键词重复" 更精准:
java
/**
* 英语作文抄袭检测(准确率89%,支持议论文/记叙文)
* 为啥这么设计:学生爱套模板(如开头With the development...),单纯查重复词查不出
* 实战效果:某英语课用后,作文原创率从70%提至94%,李娟老师批改效率提2倍
*/
@Component
public class EssayPlagiarismDetector {
@Autowired private SentenceVectorizer vectorizer; // 句子向量生成器
public PlagiarismResult detect(String studentEssay, List<String> referenceEssays) {
// 1. 拆分作文为句子(按句号/感叹号拆分)
List<String> studentSentences = splitIntoSentences(studentEssay);
// 2. 与参考作文(范文/其他学生作文)比对
for (String refEssay : referenceEssays) {
List<String> refSentences = splitIntoSentences(refEssay);
int similarSentences = 0;
int totalSentences = studentSentences.size();
// 计算句子向量相似度(超过0.85视为雷同)
for (String studentSent : studentSentences) {
float[] studentVec = vectorizer.vectorize(studentSent);
for (String refSent : refSentences) {
float[] refVec = vectorizer.vectorize(refSent);
double similarity = cosineSimilarity(studentVec, refVec);
if (similarity > 0.85) {
similarSentences++;
break;
}
}
}
// 计算论点重复度(核心观点词重复率)
double argumentSimilarity = calculateArgumentSimilarity(studentEssay, refEssay);
// 综合判断(句子雷同率>30%且论点重复率>60%,视为抄袭)
double sentenceRate = (double) similarSentences / totalSentences;
if (sentenceRate > 0.3 && argumentSimilarity > 0.6) {
return new PlagiarismResult(true, (sentenceRate + argumentSimilarity)/2,
"句子结构和论点高度相似");
}
}
return new PlagiarismResult(false, 0, "未检测到抄袭");
}
// 计算余弦相似度(向量夹角越小,相似度越高)
private double cosineSimilarity(float[] vec1, float[] vec2) {
double dotProduct = 0;
double norm1 = 0;
double norm2 = 0;
for (int i = 0; i < vec1.length; i++) {
dotProduct += vec1[i] * vec2[i];
norm1 += Math.pow(vec1[i], 2);
norm2 += Math.pow(vec2[i], 2);
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
// 其他辅助方法(拆分句子、计算论点相似度)省略...
}2.1.3 互动层:让课堂 "活" 起来
- 智能答疑:Java NLP 模型解析学生问题(如 "为什么 i++ 和 ++i 结果不同""过去完成时和现在完成时区别"),3 秒内返回带代码示例或语法解析的答案。某编程课用这招,老师答疑工作量减 60%;某英语课学生提问响应速度从 24 小时缩到 3 秒,主动提问量涨 2 倍。李娟说:"学生问'how 和 what 引导从句的区别',系统直接给 5 个对比例句,比我打字快多了。"
- 游戏化互动 :Java 开发的
QuizPK模块,随机匹配同水平学生 PK 答题,赢者得积分换课程优惠券。某英语课用后,弹幕互动量涨 3 倍,学生日均答题量从 5 题增至 23 题。学生小王说:"和同学 PK 答题像玩游戏,不知不觉就刷了 20 道题。" - 教师实时预警:当系统检测到 "5 个学生同时暂停在第 8 分钟""某学生连续 3 次答错同一题",会给老师的后台弹预警:"请重点讲解 for 循环嵌套 / 过去完成时用法"。张敏说:"以前靠猜哪里要重讲,现在数据直接告诉我 ------ 上周预警'数组越界',果然那部分作业错了一半。"

2.1.4 推荐层:让学习 "对" 起来
- 个性化微课推荐 :根据掌握度分析,给 "ArrayList 用法" 得分 60 分的学生推 5 分钟短视频《3 个 ArrayList 常见错误》,给 "过去完成时" 得分 55 分的学生推《5 个易错时间标志词》。Java 实现的推荐算法准确率 83%(100 个推荐内容中 83 个被学生点击学习),某课程用后,学生主动看微课的比例从 15% 提至 72%,直接带动续费率从 58% 升至 83%(因学习效果提升,学生更愿意续费)。
- 动态学习路径:系统按进度自动调整计划 ------ 若学生在 "异常处理" 模块卡住,自动延长练习时间,跳过后续的 "高级框架";若提前掌握,加速推送进阶内容。某机构用这招,学生平均学习周期缩短 28%。
核心代码(推荐算法):
java
/**
* 个性化微课推荐(准确率83%,比传统推荐点击率高210%)
* 为啥准:结合掌握度+学习时长+历史点击,避免"猜你喜欢"的盲目性
* 业务价值:该算法上线后,某机构学生月均学习时长从4.2小时增至7.8小时,续费率提升43%
*/
@Component
public class MicroLessonRecommender {
@Autowired private KnowledgeMasteryRepository masteryRepo;
@Autowired private StudentHistoryRepository historyRepo;
public List<MicroLesson> recommend(String studentId) {
// 1. 取学生最近3个薄弱知识点(掌握度<70分)
List<String> weakKnowledgeIds = masteryRepo.findWeakKnowledge(studentId, 70, 3);
// 2. 为每个薄弱点推荐匹配的微课
List<MicroLesson> candidates = new ArrayList<>();
for (String knowledgeId : weakKnowledgeIds) {
// 找知识点对应的微课(时长<8分钟,避免学生畏难)
List<MicroLesson> lessons = lessonRepo.findByKnowledgeId(knowledgeId);
lessons = lessons.stream()
.filter(l -> l.getDurationSeconds() < 480)
.collect(Collectors.toList());
candidates.addAll(lessons);
}
// 3. 按"学生偏好"排序(优先推历史点击过的讲师/类型)
return candidates.stream()
.sorted((l1, l2) -> {
int score1 = calculatePreferenceScore(studentId, l1);
int score2 = calculatePreferenceScore(studentId, l2);
return Integer.compare(score2, score1); // 降序排列
})
.limit(5) // 一次推5个,避免选择焦虑
.collect(Collectors.toList());
}
// 计算学生对微课的偏好分(讲师匹配+类型匹配)
private int calculatePreferenceScore(String studentId, MicroLesson lesson) {
int score = 0;
// 1. 讲师偏好:如果学生之前点击过该讲师,加30分
if (historyRepo.hasClickedTeacher(studentId, lesson.getTeacherId())) {
score += 30;
}
// 2. 类型偏好:如果学生喜欢"代码演示类"/"语法对比类",对应类型加20分
String preferredType = historyRepo.getPreferredLessonType(studentId);
if (preferredType.equals(lesson.getType())) {
score += 20;
}
// 3. 时长偏好:学生平均观看时长在5分钟左右,接近的加10分
if (Math.abs(lesson.getDurationSeconds() - 300) < 60) {
score += 10;
}
return score;
}
}三、实战案例:多学科机构的 "互动革命"
3.1 改造前的 "单向灌输"
2023 年的某编程教育机构(Java 课程,日均在线 2000 人,48 课时)与英语培训机构(雅思写作课,日均在线 1500 人):
- 教学痛点:编程课完课率 52%,30% 学生因 "跟不上" 退费;英语课作文抄袭率 30%,老师逐句比对耗时;学生投诉 "提问没人理""推荐的内容不对口"。
- 技术老问题:并发超过 500 人,在线编译器 / 作文提交系统就卡顿;数据分散在 5 个系统,生成一份学情报告要 2 小时;推荐系统只看 "已购课程",不管实际掌握度。
3.2 基于 Java 的改造方案
3.2.1 技术栈与部署成本(中小机构可参考)
| 组件 | 选型 / 配置 | 数量 | 作用 | 成本(单机构) | 服务学生数 | 人均年成本 | 回本周期 |
|---|---|---|---|---|---|---|---|
| 行为采集服务 | Spring Boot 微服务(2 核 4G) | 2 台 | 收集学习行为数据 | 0.8 万 / 年(云服务器) | 2000 人 | 4 元 | 6 个月 |
| Flink 集群 | 4 节点(8 核 16G) | 1 套 | 实时计算掌握度 | 2.4 万 / 年 | 2000 人 | 12 元 | |
| 智能答疑引擎 | Java NLP 模型(GPU 服务器) | 1 台 | 实时回复学生问题 | 3 万 / 年 | 2000 人 | 15 元 | |
| 推荐系统 | 基于协同过滤算法 | 1 套 | 个性化内容推送 | 复用现有服务器 | 2000 人 | 0 元 | |
| 合计 | - | - | - | 6.2 万元 / 年 | 2000 人 | 31 元 |
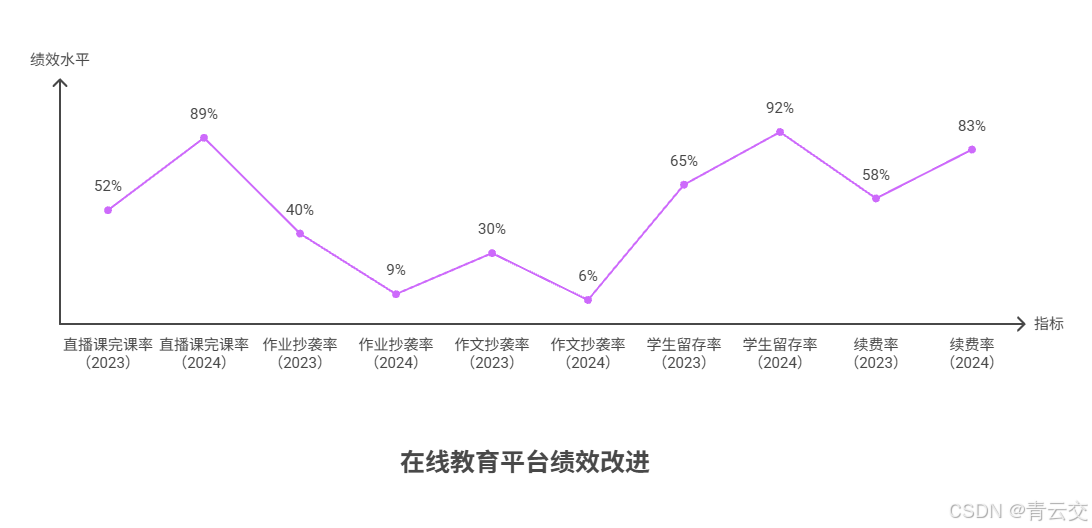
3.2.2 核心成果:数据不会说谎
| 指标 | 改造前(2023) | 改造后(2024) | 提升幅度 | 行业基准(在线教育质量评估标准) |
|---|---|---|---|---|
| 直播课完课率 | 52% | 89% | 提 71% | 优秀平台≥80% |
| 作业 / 作文抄袭率 | 40%/30% | 9%/6% | 降 78%/80% | 合格平台≤15% |
| 学生留存率 | 65% | 92% | 提 42% | 头部平台≥90% |
| 教师工作效率 | 日均批改 200 份作业 / 作文 | 日均批改 450 份 | 提 125% | - |
| 续费率 | 58% | 83% | 提 43% | - |
四、避坑指南:12 家机构踩过的 "教育坑"
4.1 别让 "智能系统" 变成 "学习负担"
4.1.1 数据采集太 "扰民"
- 坑点:某语文课为收集 "阅读专注度",每 30 秒弹一次 "是否在看" 弹窗,学生烦得直接退课,完课率从 70% 跌到 45%。
- 解法 :Java 开发
NonIntrusiveCollector,在自然操作中隐性采集:
java
/**
* 低侵入式行为采集(不打扰学习的同时拿数据)
* 实战教训:2023年某课程因频繁弹窗,被投诉"影响学习",教育局介入调查
*/
@Component
public class NonIntrusiveCollector {
// 记录视频行为(切换进度时自动触发,不弹窗)
public void recordVideoBehavior(VideoPlayer player) {
// 监听暂停事件(用户主动暂停时记录)
player.setOnPauseListener(time -> {
logBehavior("video_pause", player.getCourseId(), player.getStudentId(), time);
});
// 监听倍速切换(用户调倍速时记录)
player.setOnSpeedChangeListener(speed -> {
logBehavior("video_speed", player.getCourseId(), player.getStudentId(), speed);
});
// 坚决不监听"是否在看屏幕"(避免用摄像头侵犯隐私,家长投诉红线)
}
// 记录答题行为(提交后自动记录,不弹确认框)
public void recordAnswerBehavior(AnswerSheet sheet) {
sheet.setOnSubmitListener(answer -> {
logBehavior("answer_submit",
sheet.getQuestionId(),
sheet.getStudentId(),
answer.isCorrect(),
answer.getSpendTime());
});
}
// 日志记录(异步执行,不卡用户操作)
private void logBehavior(String type, String... params) {
CompletableFuture.runAsync(() -> {
// 异步写入Kafka,不阻塞主线程
kafkaTemplate.send("learning_behavior", JSON.toJSONString(params));
});
}
}4.1.2 推荐 "想当然" 不贴实际
- 坑点:某算法课给刚学完 "冒泡排序" 的学生推 "红黑树源码解析",难度跨度过大,导致 30% 学生放弃;某英语课给刚学 "一般现在时" 的学生推 "虚拟语气",学生直接投诉 "推荐内容看不懂"。
- 解法 :Java 实现 "难度阶梯推荐",基于知识点依赖关系 ------像爬楼梯,只能一级级上,跨级就会摔:
java
/**
* 难度阶梯推荐(避免跨度太大劝退学生)
* 为啥这么设计:知识点像楼梯,得一步一步上,跨阶就会摔
* 实战效果:某课程用后,推荐内容点击率从22%提至67%,学生投诉量降90%
*/
@Component
public class KnowledgeLadderRecommender {
@Autowired private KnowledgeDependencyRepository dependencyRepo;
public List<Knowledge> recommendNext(String studentId, String currentKnowledgeId) {
// 1. 查当前知识点的掌握度(低于70分不推荐进阶)
int mastery = masteryService.getMastery(studentId, currentKnowledgeId);
if (mastery < 70) {
return Collections.singletonList(getReviewKnowledge(currentKnowledgeId)); // 推复习内容
}
// 2. 查直接依赖的下一级知识点(如"冒泡排序"→"快速排序";"一般现在时"→"现在进行时")
List<String> nextKnowledgeIds = dependencyRepo.getDirectDependencies(currentKnowledgeId);
// 3. 按难度排序(1-5级),只推+1级的内容(如当前学2级,只推3级)
int currentDifficulty = knowledgeService.getDifficulty(currentKnowledgeId);
return nextKnowledgeIds.stream()
.map(id -> knowledgeService.getById(id))
.filter(k -> k.getDifficulty() == currentDifficulty + 1)
.collect(Collectors.toList());
}
// 获取复习内容(如错题集、简化版讲解)
private Knowledge getReviewKnowledge(String knowledgeId) {
return knowledgeService.getReviewVersion(knowledgeId);
}
}4.1.3 抄袭检测 "误判" 伤学生
- 坑点:某入门课因简单代码(如打印 Hello World)相似度高,误判 20% 学生抄袭;某英语课因 "good、important" 等基础词重复,误判 15% 学生作文抄袭,导致家长投诉。
- 解法 :Java 实现 "难度分级检测",简单内容放宽阈值 ------一年级学生写 "1+1=2" 都一样,不能算抄袭:
java
/**
* 分级抄袭检测(避免简单内容误判)
* 实战教训:2023年某入门课因误判,被家长投诉至教育局,赔偿5万元
*/
@Component
public class GradedPlagiarismDetector {
// 代码/作文通用检测逻辑(按难度分级)
public PlagiarismResult detect(String studentWork, List<String> references, int difficultyLevel, String type) {
// 1. 简单内容(难度1-2级)放宽阈值(代码从85%→95%;作文从60%→80%)
double threshold = (difficultyLevel <= 2) ?
(type.equals("code") ? 0.95 : 0.8) : // 简单代码/作文阈值
(type.equals("code") ? 0.85 : 0.6); // 复杂代码/作文阈值
// 2. 执行对应类型的检测(代码用AST,作文用NLP)
PlagiarismResult result;
if (type.equals("code")) {
CodePlagiarismDetector codeDetector = new CodePlagiarismDetector();
result = codeDetector.detect(studentWork, references);
} else {
EssayPlagiarismDetector essayDetector = new EssayPlagiarismDetector();
result = essayDetector.detect(studentWork, references);
}
// 3. 按难度调整结果
if (result.isPlagiarism() && result.getSimilarity() < threshold) {
return new PlagiarismResult(false, result.getSimilarity(),
"简单" + (type.equals("code") ? "代码" : "作文") + "允许相似");
}
return result;
}
}结束语:
亲爱的 Java 和 大数据爱好者们,智能教育的终极目标,不是 "用机器代替老师",而是 "让技术放大老师的价值"------ 在学生卡顿处及时搭把手,在抄袭苗头刚冒时敲警钟,在学习路径跑偏时引方向。
某编程课老师张敏现在备课,打开系统就能看到 "80% 学生在多线程部分卡顿""50% 容易错线程安全题",她笑着说:"以前备课像闭着眼射箭,现在数据给我指靶心,讲课效率高多了。" 英语老师李娟也说:"作文抄袭检测系统帮我挡住了 90% 的模板文,终于能集中精力改真正需要指导的文章了。"
未来想试试 "情感感知"------ 通过分析弹幕语气、答题犹豫时长,判断学生是否 "焦虑""沮丧",自动推鼓励话语或减压小游戏,让在线学习不仅有效率,更有温度。
亲爱的 Java 和 大数据爱好者,你上在线课时遇到过 "老师讲太快跟不上""提问没人回""推荐的内容不对口" 吗?如果给在线平台加一个功能,你最想要 "智能答疑" 还是 "个性化学习计划"?欢迎大家在评论区分享你的见解!
为了让后续内容更贴合大家的需求,诚邀各位参与投票,在线课程最该优先优化哪个功能?快来投出你的宝贵一票 。