深度学习就是搭建多层神经网络的一种机器学习方法。那学习是个啥呢,学习就是不停的迭代更新设定参数的过程。
1、深度学习的概念
人工智能 → 机器学习 → 神经网络(包括浅层和深层)。
- "神经网络"是一个更广的概念,深度学习是它的一个特殊情况(多层结构)。有些浅层神经网络(1~2层)不能算深度学习。
整个机器学习的过程就是预测结果的过程,通过学习已有数据,寻找最优参数得到模型,然后使用模型预测可能的数据。
而深度学习则是使用深度神经网络的机器学习方法。学习的过程,就是迭代更新每个参数权重的过程。
深度学习 = 使用深层神经网络(通常三层以上隐藏层)的机器学习方法。
深度学习的网络结构见下图:
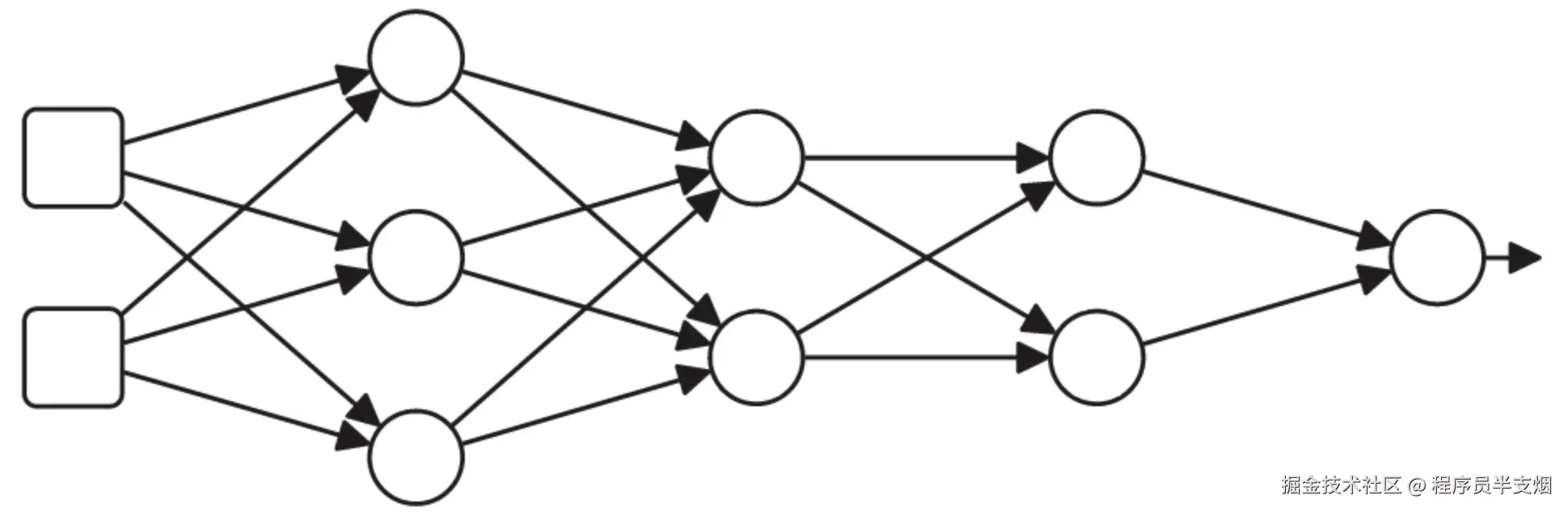
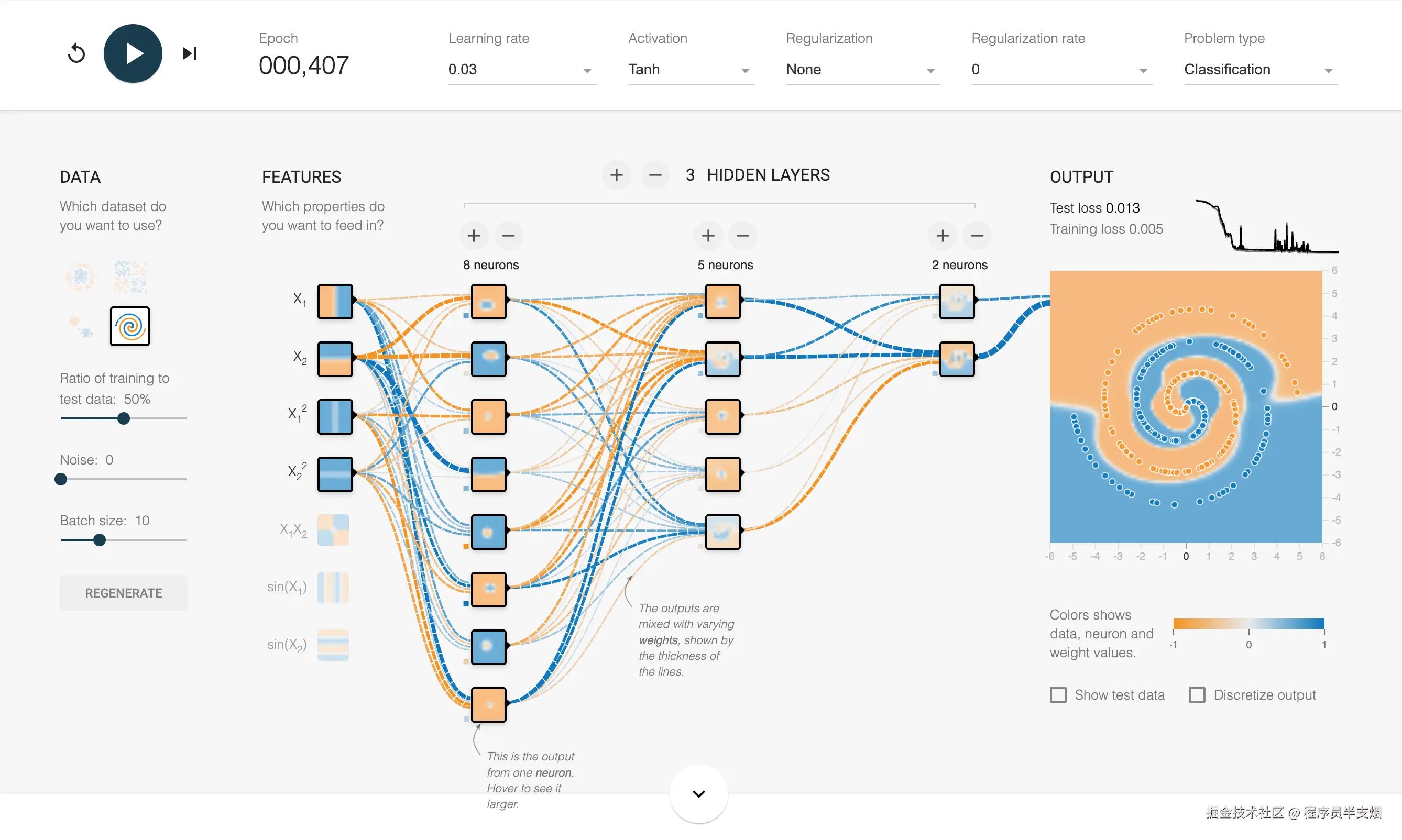
下图这个更直观些,是一个通过神经网络训练某个点的分类情况,图中有多层网络结构、训练批次、训练轮数、每层多少神经元、激活函数等等。这是网址:playground.tensorflow.org,读者可以自行尝试。
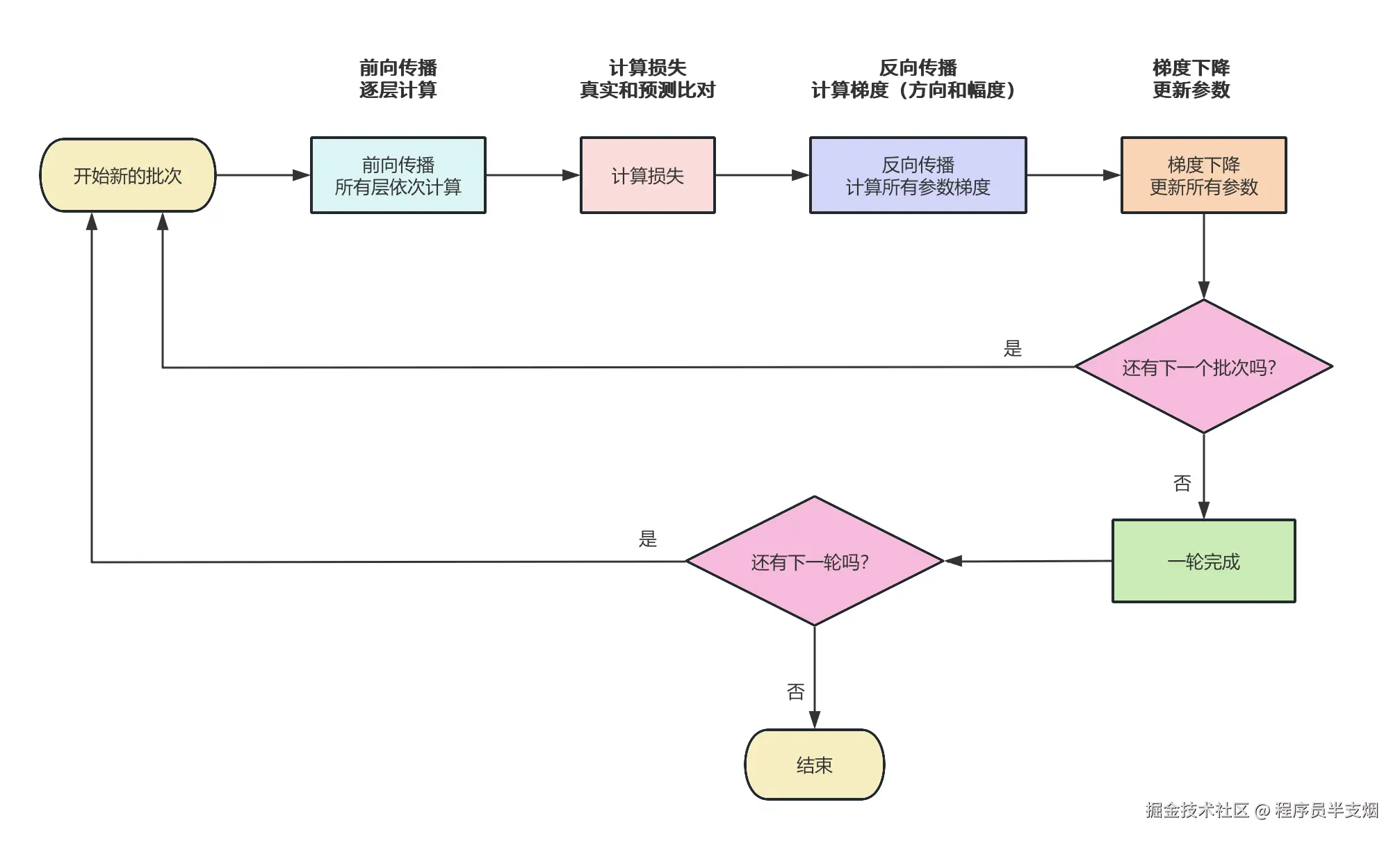
2、深度学习的流程
深度学习按照如下流程进行:根据每一层的输入进行前向传播预测 → 损失函数算分 → 反向传播算计算梯度 → 优化器按学习率更新参数。
- 在
optimizer.step()前,通常会先optimizer.zero_grad()(否则梯度会累加)。 - 数据要按 batch 喂,且训练过程中会多轮(epoch)训练。
2.1、深度学习核心流程
-
准备数据
-
定义模型,搭建网络层
-
定义损失函数和优化器
-
训练模型,按批次训练
- 前向传播:outputs = model(images)
- 计算损失:loss = criterion(outputs, labels)
- 反向传播:loss.backward()
- 更新参数:optimizer.step()
-
测试模型、使用模型预测、保存模型
2.2、流程图
3、深度学习核心概念
3.1、神经网络的组成
神经网络是深度学习的核心,它由许多相互连接的节点(称为神经元)组成。一个典型的神经网络包括3个主要部分:输入层、隐藏层和输出层。
- 输入层:接收数据输入,每个神经元代表输入数据的一个特征或者维度。
- 隐藏层:处理数据并提取特征,每一层通过权重和偏置对输入进行变换,再通过激活函数(引入非线性激活方式),使得神经网络能够学习到复杂的特征。
- 输出层:产生最终的输出结果,用于分类或回归等任务。
我们要想神经网络的效果更好,要不就是增加某一层的神经元,要不就是增加隐藏层数量。
3.2、什么是参数
参数(权重)= 模型的"知识",模型学到的知识其实就是这些参数的具体值。
- 参数是什么:神经网络学到的具体数值
- 参数的作用:决定网络如何处理输入数据
- 例子:某个连接的权重是 0.5
3.3、前向传播
**前向传播(Forward Propagation)**是指数据从输入层经过神经网络的各层逐层传递,最终产生输出结果的过程。
具体来说:
- 输入数据:我们把一组输入数据(比如一张图片的像素值、一个句子的词向量等)传入神经网络的输入层。
- 逐层计算:每一层都会对输入进行线性变换(加权求和 + 偏置),然后通过激活函数(比如ReLU、Sigmoid、Tanh等)做非线性映射,产生这一层的输出。
- 层层传递:每层的输出作为下一层的输入,依次进行计算。
- 最终输出:经过最后一层后,得到网络的输出(比如分类概率、回归数值等)。
总结就是:前向传播的过程,就是网络把输入数据"推"过每一层,计算出最终结果的过程。
它的作用是:
- 根据当前网络参数,计算预测结果。
- 计算损失函数时需要用到预测结果。
3.4、什么是损失函数
损失函数是衡量模型输出和真实答案差距的函数。它的输出是一个数字,这个数字越小,说明模型越接近正确答案。
3.5、什么是梯度
梯度表示"模型的参数往哪个方向调整,损失函数会下降得最快",代表了一个调整的方向和需要调整的幅度。
梯度是个方向向量,告诉我们"如果参数往这个方向微调一点,损失会下降"。梯度本身不会更新参数,它只是"导航指令"。更新参数的动作交给优化器。
3.6、什么是优化器
优化器就是用梯度来更新模型参数的工具。
3.7、激活函数
激活函数是神经网络中引入非线性能力的关键组件。它决定了一个神经元是否被激活,影响数据在网络中的传播。只有激活的神经元才会将输出传递到下一个神经元的输入。
常见的激活函数包括:
- ReLU:ReLU是目前使用最广泛的激活函数之一,它将输入的负值归零,仅保留正值。ReLU的计算简单且能够有效缓解梯度消失问题。
- Sigmoid:将输入映射到(0, 1)区间,常用于二分类问题的输出层。
- Tanh:类似于Sigmoid,但将输入映射到(-1, 1)区间,常用于RNN中。
我们的现实世界是非常复杂的,无法用线性关系去表示。如果神经网络在加权计算后,得出的就是线性函数,很难表示我们的复杂世界。
因此,为了使神经网络能够实现非线性映射,神经元在处理信息时就要包含非线性步骤(即激活函数)。神经网络的层数越深,学习复杂非线性映射的能力就越强。
3.8、反向传播
神经网络有很多参数(权重),如何知道哪些参数需要调整,以及如何调整?反向传播就是**帮你算"每个参数应该往哪调、调多少"**的过程。通过计算梯度,可以知道每个参数对最终损失的影响程度,然后计算每个参数需要调整多少。
反向传播就是用来:计算每个参数的梯度,也就是方向和幅度。
- 计算什么:每个权重对最终损失的影响程度(偏导数)
- 如何计算:使用链式法则,从输出层向输入层逐层计算
- 结果:得到所有参数的梯度值
3.9、前向传播和反向传播对比
深度学习里,前向传播和反向传播是分开进行的,先完成整个网络所有层的前向传播,再统一进行反向传播。
前向传播:输入数据从第1层经过第2层、第3层......一直传到最后一层,逐层计算输出。这个过程是顺序的,必须先计算完所有层的输出,才能得到最终的预测结果。
反向传播:在前向传播得到最终输出和计算出损失之后,反向传播才开始。反向传播是从最后一层开始,逐层计算梯度,更新参数。也就是说,反向传播是"逆向"的,从网络的输出层向输入层传播误差信号。
一次完整的训练迭代包括:先全部做完前向传播,得到输出和损失,再全部做反向传播,计算梯度并更新参数。
3.10、什么是学习率
学习率就是参数更新的步子大小,是优化器的一个超参数。
作用
- 决定每次更新时,往梯度方向走多远
- 步子太大:可能会错过最低点(loss 上上下下跳动)
- 步子太小:收敛太慢(要训练很久才能到达最低点)
形象比喻
你在黑暗山谷里找最低点:
- 梯度 = 指南针(指方向)
- 学习率 = 你走的步长
- 优化器 = 你走路的方式(直走、加速走、边走边调整步长等)
3.11、梯度和参数的对比
梯度 = "改进建议"
- 是什么:告诉参数应该如何调整的"方向和幅度",梯度每次训练就会清空,不会像参数一样保留下来。
生活化比喻
想象你在调节音响音量:
参数 = 当前音量大小(比如现在是50)
梯度 = 调节建议(比如"再调大5格")
- 参数50 ≠ 梯度5
- 新参数 = 50 + 5 = 55
3.12、梯度和梯度下降
当我们知道梯度(方向 和 需要调整的幅度),但如何更新参数来减少损失?
梯度下降算法就是系统性地调整参数,使得损失函数最小,然后再通过一定的步长去迭代。通过多次迭代逐渐接近最优解。梯度下降就是拿着梯度去一步步调参数,直到损失最小。
每次执行梯度下降,都会更新参数。
新参数 = 旧参数 - 学习率 × 梯度,这是"梯度下降法"的核心更新规则。
3.13、反向传播和梯度下降的比喻
反向传播 = 手电筒,告诉你哪个方向是下坡,哪个方向是上坡,不会直接带你到山底,只是提供信息。
梯度下降 = 走路的策略,根据手电筒提供的坡度信息决定怎么走,每次向下坡方向走一小步,重复多次,最终到达山底。
- 反向传播(backpropagation)不仅算方向,还有幅度,因为它算的是精确的梯度值,不只是告诉你"向左走"或"向右走"。
- 梯度下降只是利用这些梯度来更新。
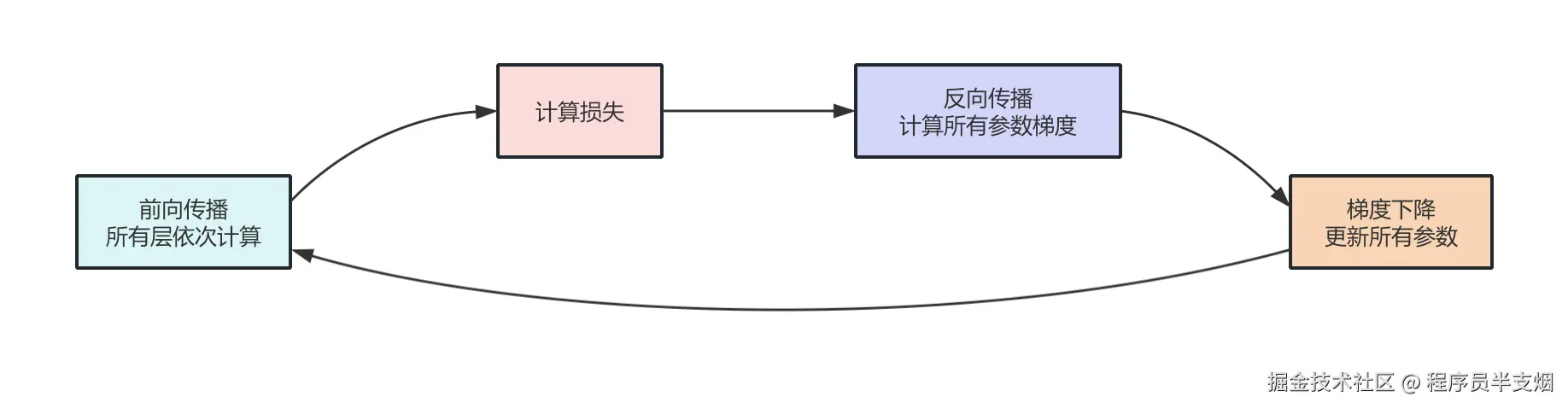
3.14、几个概念的关系
- 损失函数:告诉你当前预测值和真实值有多少差距(算分数)
- 反向传播:根据损失函数结果算出梯度(找方向 和 调整幅度)
- 优化器:拿梯度去更新参数(往目标走)
- 学习率:控制每一步的大小(走多快)
3.15、训练批次
我们每次训练模型时,都是按批次训练,比如一批训练64条数据,每次训练都会跟新参数。为什么不是每一条数据训练一次呢?
如果每条数据都更新参数:
❌ 计算效率低:GPU无法并行
❌ 训练不稳定:每条数据的梯度变化太大
❌ 收敛慢:噪声太多
使用batch的好处:
✅ 效率高:GPU可以并行处理64条数据
✅ 稳定:64条数据的平均梯度更可靠
✅ 收敛快:减少了随机性
每个批次训练一次,然后调整一次参数
每个batch(64条数据)会导致所有参数更新一次
- 输入:64条数据同时处理
- 输出:64个预测结果
- 损失:64个预测的平均损失
- 更新:基于这64条数据的平均梯度更新所有参数
3.16、每次参数更新都是"全局"的
参数更新是"瞬间全局",不存在"先更新前面层,再更新后面层"。虽然更新是全局的,但梯度计算是逐层从后往前(反向传播),这也是"反向传播"名字的来源。
不是只更新某几层,而是同时更新整个网络的所有可学习参数,这样整个网络都在朝着减少损失的方向"进化"。
4、PyTorch的核心概念
PyTorch框架就是对深度学习理念的一个实践,它有如下具体概念。
4.1、Tensor(张量)
- 就是多维数组,类似
numpy数组,但可以放到 GPU 上加速计算。 - 张量是深度学习的"数据容器",模型所有的输入、输出、权重,都是张量。
4.2、requires_grad
- 决定张量是否需要计算梯度。
- 如果需要训练,就得开
requires_grad=True,PyTorch 会自动记录它的计算过程,用来反向传播更新权重。
4.3、Autograd(自动求导)
- PyTorch 的自动微分引擎。
- 当你对
requires_grad=True的张量做运算时,PyTorch 会帮你搭建一个计算图 ,最后loss.backward()会沿着这个图算出梯度。
4.4、Model(模型)
- 就是一个函数,把输入(张量)映射到输出。
- 在 PyTorch 里,模型通常是
nn.Module的子类,里面定义了层(layers)和前向计算(forward)。
4.5、Loss function(损失函数)
- 衡量模型输出和真实答案差距的函数,比如
MSELoss(均方误差)或CrossEntropyLoss(交叉熵)。
4.6、Optimizer(优化器)
- 负责根据梯度去更新模型参数,比如
SGD、Adam。
4.7、训练流程
一般有 4 步:
- 前向传播(forward pass)
- 计算损失(loss)
- 反向传播(backward pass)
- 参数更新(optimizer.step)
5、使用PyTorch训练的示例
下面是一个经典的入门深度学习的示例,训练识别手写数字的模型。
5.1、准备数据
ini
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# ========== 0. 自动检测设备(Mac M1/M2 用 mps,加速) ==========
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
# ========== 1. 准备数据 ==========
transform = transforms.Compose([
transforms.ToTensor(), # 转张量
transforms.Normalize((0.5,), (0.5,)) # 归一化到 [-1, 1]
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 类别标签
class_names = [
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9"
]5.2、定义模型
ini
# ========== 2. 定义模型 ==========
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入层-或者叫做全连接层1:输入 784(28x28 展平),输出 128。
self.fc2 = nn.Linear(128, 64) # 隐藏层-或者叫做全连接层2:128 → 64。
self.fc3 = nn.Linear(64, 10) # 输出层-或者叫做全连接层3:64 → 10(10 类)。
# 定义前向传播。
def forward(self, x):
x = x.view(-1, 28*28) # 展平
# 经过第一层并用 ReLU 激活。
x = torch.relu(self.fc1(x))
# 经过第二层并用 ReLU 激活。
x = torch.relu(self.fc2(x))
# 输出 logits(不加 softmax,配合交叉熵损失更稳定)。
x = self.fc3(x) # 最后一层不加 softmax
return x
model = Net().to(device)5.3、定义损失函数和优化器
ini
# ========== 3. 定义损失函数 & 优化器 ==========
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)5.4、训练模型
ini
# ========== 4. 训练模型 ==========
epochs = 5
for epoch in range(epochs):
model.train()
running_loss = 0.0
# 这里并不是每一条数据都进行训练,而是每一个batch数据进行一次训练。比如上面定义的batch_size=64,那就是64条数据进行一次训练。
# 这样效率高,稳定,收敛快。
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 清空梯度,每个批次训练完要清空梯度,避免梯度累加
optimizer.zero_grad()
# 前向传播:计算输出
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播:计算梯度。反向传播只是告诉了我们梯度,但是没有告诉我们参数。
loss.backward() # 这一步计算出所有参数的梯度
# 梯度下降:使用梯度更新参数。这一步用梯度下降算法更新参数。
optimizer.step() # 这一步用梯度下降算法更新参数
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {running_loss/len(train_loader):.4f}")5.5、测试模型
ini
# ========== 5. 测试模型 ==========
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")5.6、用模型去预测
ini
# ========== 6. 推理(单张图片预测) ==========
sample_img, sample_label = test_dataset[0]
plt.imshow(sample_img.squeeze(), cmap="gray")
plt.title(f"True: {class_names[sample_label]}")
plt.show()
model.eval()
with torch.no_grad():
sample_img_device = sample_img.unsqueeze(0).to(device) # 增加 batch 维
output = model(sample_img_device)
predicted_label = torch.argmax(output, 1).item()
print("Predicted Label:", class_names[predicted_label])6、总结
本篇主要讲了深度学习的概念和初步入门,希望对你有帮助。AI时代,每个人都应该拥抱AI,释放自己,勇于去创造。
======>>>>>> 关于我 <<<<<<======
本篇完结!欢迎点赞 关注 收藏!!!