在现代分布式系统中,利用缓存(如 Redis)来加速数据访问是一种常见的优化手段。然而,当面对高并发场景时,确保缓存和数据库之间的一致性变得尤为挑战。特别是在缓存和数据库更新失败的情况下,如何实现最终一致性成为了一个重要的议题。本文将探讨几种有效的策略,并结合简单的图示帮助理解。
异步队列处理
使用消息队列(例如 RabbitMQ、Kafka)可以在应用层和数据库之间建立一个异步的桥梁。当需要更新数据时,应用程序不会直接操作数据库,而是把更新请求发送到消息队列。接着,有一个独立的服务或进程监听这个队列,并执行实际的数据更新工作。
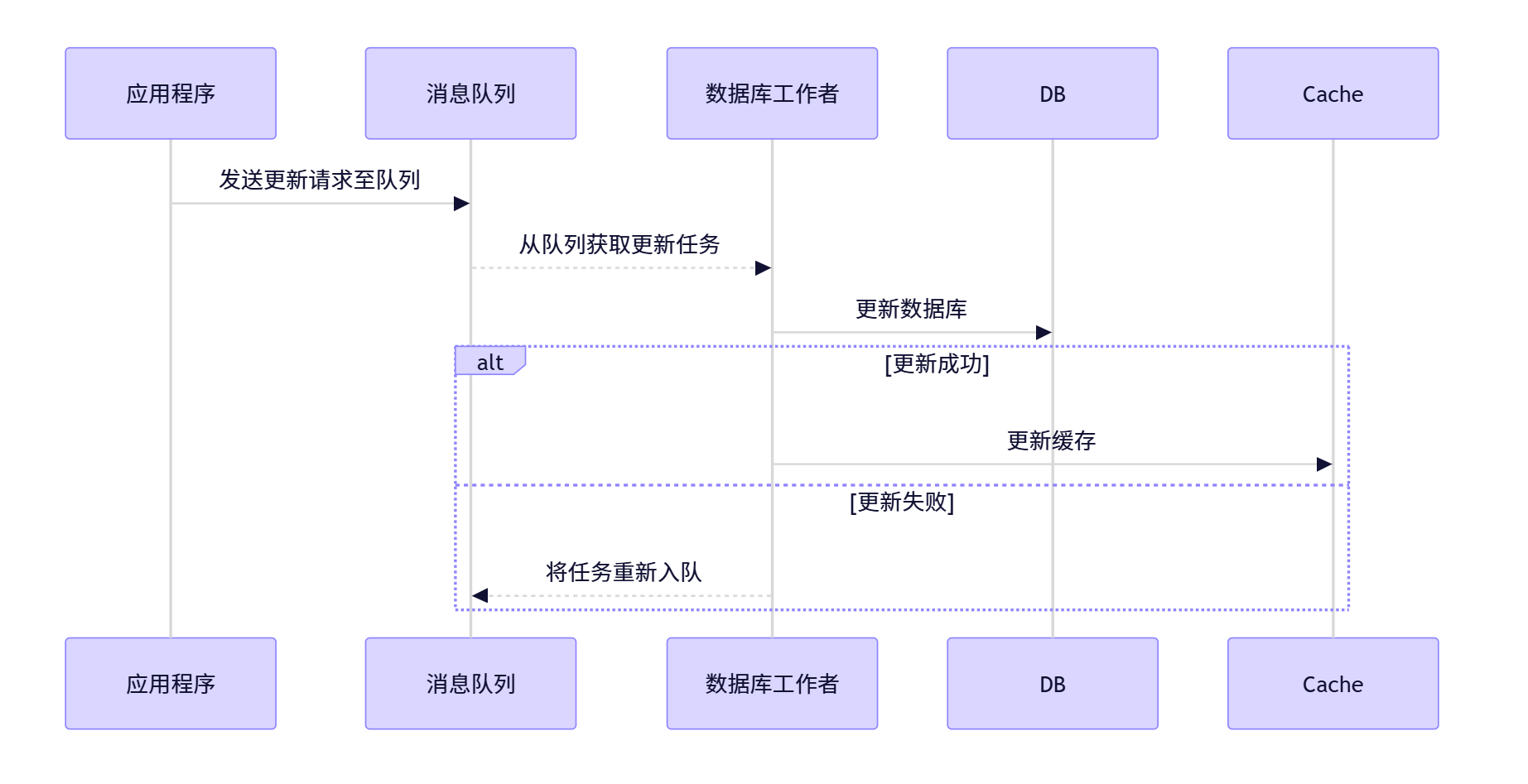
优点 :提供重试机制,直到更新成功为止。 缺点:增加了系统的复杂性,且如果消息丢失可能导致数据不一致。
补偿事务/事后修复
对于偶尔出现的数据不一致问题,可以设计补偿机制,在检测到不一致后自动进行修正。比如,定时检查数据库和缓存中的数据差异,并根据业务逻辑进行修复。
- 优点:简单易行,适用于偶尔发生的问题。
- 缺点:可能存在短暂的不一致窗口,不适合频繁发生的错误。
双写策略改进
传统的"先更新数据库,再删除缓存"策略可以通过增加重试机制或引入分布式锁减少并发情况下导致的不一致风险。此外,延迟双删策略也是一种有效的方法,即在第一次删除缓存之后等待一段时间再次删除,以覆盖可能存在的缓存重建情况。
使用分布式事务
在某些对强一致性要求较高的场景下,可以采用分布式事务(如两阶段提交协议2PC)。但是,这种方法通常会带来性能损耗,并增加系统复杂度。
基于事件驱动架构
利用事件溯源(Event Sourcing)或命令查询职责分离(CQRS)等模式,通过记录所有对系统状态改变的事件来维护数据的一致性。这种方式允许异步地传播这些变化到不同的服务或存储中,从而达到最终一致性。
结论
在高并发环境下,完全避免更新失败是不现实的。因此,关键在于如何有效地管理和恢复这些异常情况。本文提到的方法各有优劣,具体选择哪种方法取决于你的应用场景的具体需求,包括对一致性的要求程度、系统复杂度容忍度以及性能考量等因素。综合运用这些策略,可以有效地提升系统的健壮性和可靠性,确保即使在缓存和数据库更新失败的情况下也能实现数据的最终一致性。