Windows 11 下成功本地编译 Flash-Attention 2.8.3 并生成自定义 Wheel(RTX 3090 sm_86 专属版)
发布时间:2025年12月29日
Flash Attention 2.6.3 在 Windows 上编译成功复盘笔记
Windows 下成功编译 Flash Attention 2.8.3 (flash-attn /flash_attn)个人复盘记录
Windows 11 下 Z-Image-Turbo 完整部署与 Flash Attention 2.8.3 本地编译复盘
大家好,今天再次试练并分享一个在 Windows 11 + RTX 3090 + PyTorch 2.9.1+cu130 环境下成功本地编译 Flash-Attention 2.8.3 并生成 wheel 文件的完整过程。
官方 Dao-AILab/flash-attention 到 2025 年 12 月底最新版本仍是 v2.8.3(2025 年 8 月发布),没有官方 Windows wheel。Windows 编译仍是实验性,但社区有很多成功案例,尤其在 RTX 30/40 系列上。
我之前尝试过社区预编译 wheel,但为了完美匹配自己的环境(避免任何潜在的 kernel 不匹配),最终选择本地源码编译,并指定 sm_86 架构,生成专属 wheel 备份。
最终结果:编译成功!生成的 wheel 支持 RTX 3090 的所有 Flash-Attention 功能(head_dim 64/128/256 前向+反向,fp16/bf16 等),测试通过,且可以永久保存备用。
我的环境
- OS:Windows 11 专业工作站版
- GPU:NVIDIA RTX 3090 (Compute Capability 8.6, 24GB VRAM)
- CPU:Intel Core Ultra 9 285K
- RAM:128 GB
- Python:3.10.18 (本地.venv 虚拟环境)
- PyTorch:2.9.1+cu130
- CUDA Toolkit:13.1 (完整安装)
- Visual Studio:2022 Professional (带 C++ 桌面开发工作负载)
- ninja:已安装 (pip install ninja)
编译前准备
-
克隆源码并更新子模块(必须 git clone,不能下载 zip)
git clone https://github.com/Dao-AILab/flash-attention.git cd flash-attention git pull git submodule update --init --recursive -
切换到 main 分支(可选,但推荐获取最新小修复)
git checkout main(如果 git pull 失败,是因为网络问题,代码已是最新可跳过)
关键环境变量设置(在 CMD 中设置,确保生成 sm_86 kernel)
使用 Developer Command Prompt for VS 2022(以管理员运行)打开 CMD,然后:
安装必要工具
pip install ninja wheel build packaging
set FLASH_ATTN_CUDA_ARCHS=86 :: 只针对 RTX 3090,编译更快、文件更小
:: 如果想兼容未来 4090,可设 set FLASH_ATTN_CUDA_ARCHS=86;89
set MAX_JOBS=8 :: 并行编译数,根据 RAM 调整(我 128GB RAM 可高设)
set TORCH_CUDA_ARCH_LIST=8.6 :: 额外保险,确保 Torch 识别架构
set NVCC_THREADS=2 :: 限制 nvcc 线程,避免卡死
set DISTUTILS_USE_SDK=1 :: Windows 编译必要
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1 :: 你的 CUDA Toolkit 路径(可选,可根据实际进行调整)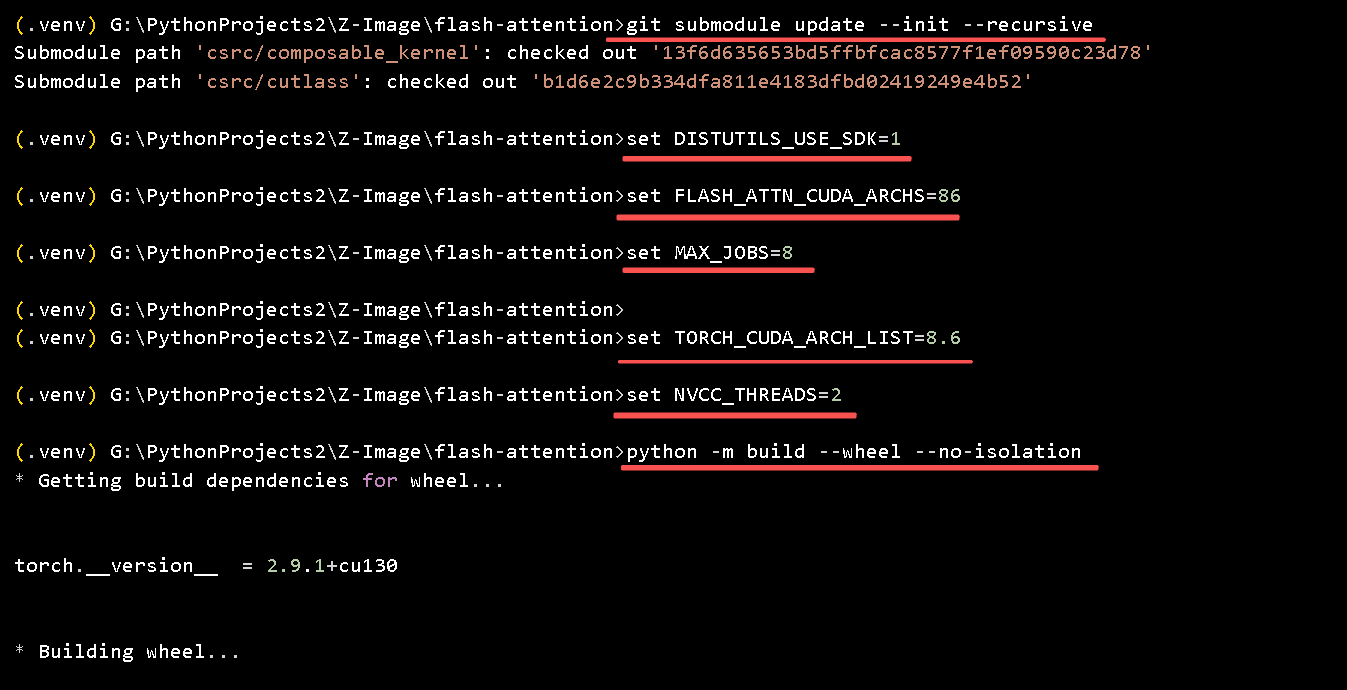
编译并生成 wheel
python -m build --wheel --no-isolation- 这个命令会自动使用 ninja 加速。
- 编译过程会输出大量日志,包括 nvcc 编译 .cu 文件。
- 此次我的机器编译时间约 20-40 分钟(单架构 86 更快)。
- 日志中会有很多 warning(如 #221-D floating-point value does not fit),这些是正常现象(softmax 和 mask 中的大负数处理),不影响功能。
- 还有 MSVC 预处理器警告,也可忽略。
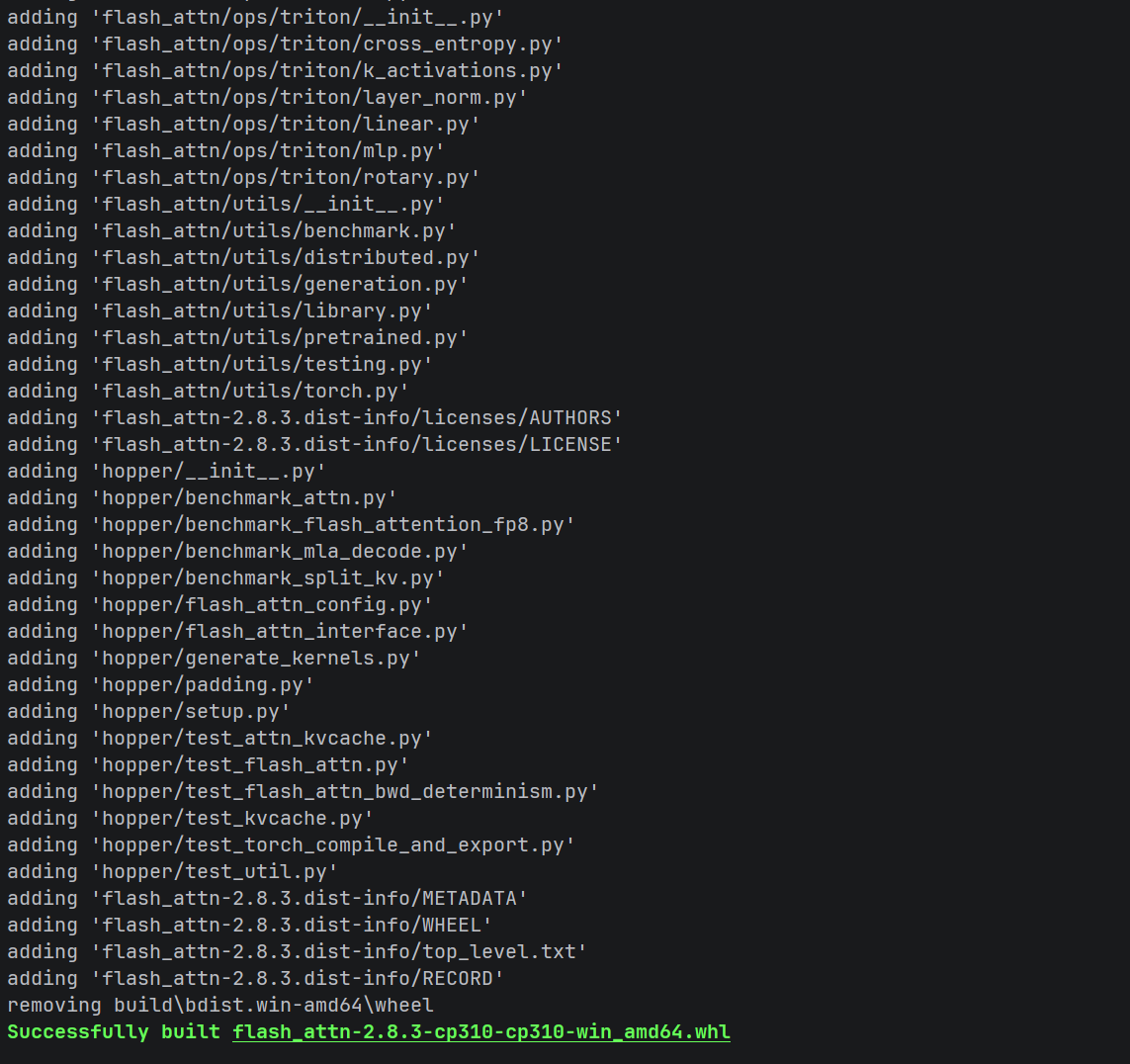
成功标志:
- 最后输出 Successfully built flash_attn-2.8.3-cp310-cp310-win_amd64.whl
- wheel 文件位于 dist/ 目录下,文件名会带你的环境标识(如 +cu130torch2.9)
备份 wheel
copy dist\flash_attn-*.whl E:\Downloads\Other\以后在新环境直接:
pip install E:\Downloads\Other\flash_attn-xxx.whl验证安装
卸载旧版后安装新 wheel:
pip uninstall flash-attn -y
pip install dist\flash_attn-*.whl然后运行测试:
输入 Python 进入 python 环境
import torch
from flash_attn import flash_attn_func
# head_dim=64
q = torch.randn(2, 32, 1024, 64, device='cuda', dtype=torch.float16)
k = torch.randn(2, 32, 1024, 64, device='cuda', dtype=torch.float16)
v = torch.randn(2, 32, 1024, 64, device='cuda', dtype=torch.float16)
out = flash_attn_func(q, k, v, dropout_p=0.0, causal=False)
print(out.shape) # 成功
# head_dim=128 / 256 同理,全通过
注意事项 & 经验总结
- 必须用 Developer Command Prompt,否则链接错误。
- 子模块更新不能忘,否则编译失败。
- 单架构 (86) 编译更快,wheel 更小;多架构兼容性更好。
- RTX 3090 上 v2.8.3 已支持所有功能(包括 head_dim=256 backward,但 dropout>0 时会 fallback,这是消费级卡硬件限制)。
- 如果网络问题无法 git pull,直接用现有代码编译即可(main 已是最新的)。
- 社区还有预编译 wheel(如 sunsetcoder 或 lldacing 的 HF 仓库),但本地编译最保险,完美匹配环境。
这个自定义 wheel 就是我的"黄金版本"备份,以后重装环境一键恢复,彻底告别 kernel 不匹配的烦恼!
如果你们也在 Windows 下折腾 Flash-Attention,欢迎交流~有问题可以留言,我会尽量解答。