近日,来自香港大学和字节跳动的研究团队提出了一种简单有效的框架 ------JoVA,它支持视频和音频的 Token 在一个 Transformer 的注意力模块中直接进行跨模态交互。为了解决人物说话时的 "口型 - 语音同步" 问题,JoVA 引入了一个基于面部关键点检测的嘴部区域特定损失 (Mouth-area specific loss)。
作者介绍:本文第一作者黄小虎同学,目前是香港大学的三年级在读博士生,导师是韩锴教授。黄小虎的研究方向是以视频为中心的领域,包括音视频生成、视频理解以及视频识别。
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。
近日,来自香港大学和字节跳动的研究团队提出了一种简单有效的框架 ------JoVA,它支持视频和音频的 Token 在一个 Transformer 的注意力模块中直接进行跨模态交互。为了解决人物说话时的 "口型 - 语音同步" 问题,JoVA 引入了一个基于面部关键点检测的嘴部区域特定损失 (Mouth-area specific loss)。
实验表明,JoVA 只采用了约 190 万条训练数据,便在口型同步准确率、语音质量和整体生成保真度上,达到了先进水平。


一、研究背景与动机
目前的开源解决方案通常分为两大类别:一类是 "级联式",即先生成视频再配音,或者先生成语音再驱动视频生成,这种方式在一定程度上会导致音频和画面的割裂;另一类是 "端到端的联合生成",试图同时输出视频和音频。
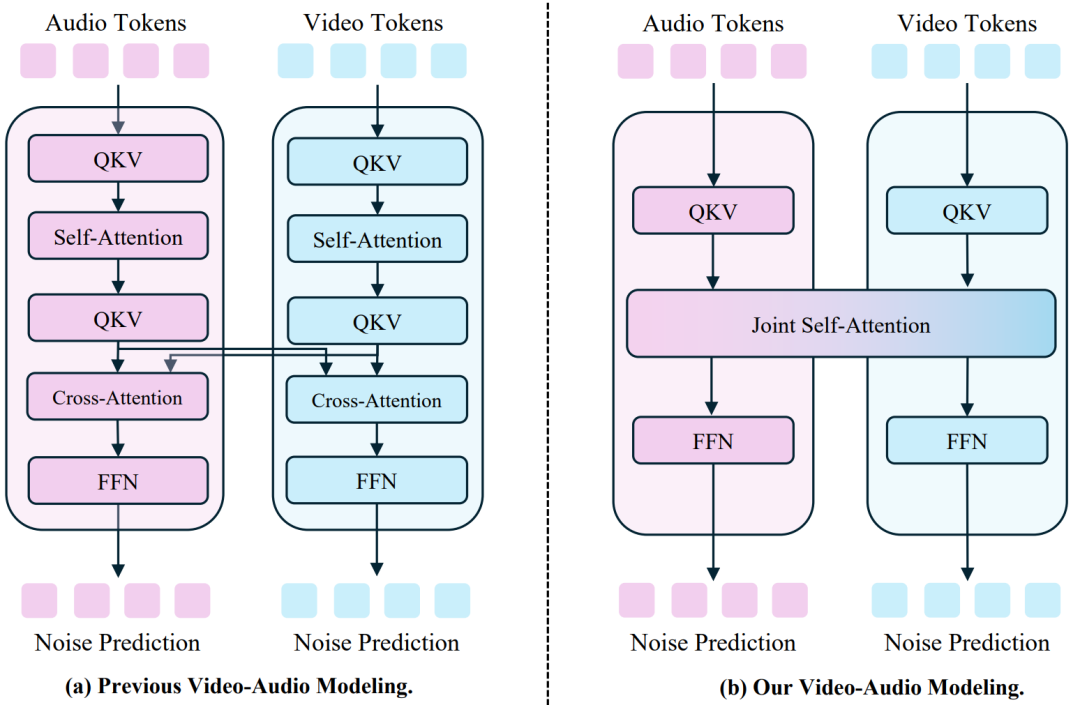
如下图 a, 现有的端到端方法(如 OVi 和 Universe 等),为了实现双模态对齐,需要在自注意力层 (self-attention) 之外,额外设计融合模块或跨注意力层 (Cross-attention)。这不仅破坏了 Transformer 架构的简洁性,还可能阻碍进一步的数据和模态扩展。
相比之下,JoVA 采用了更加简洁的设计(如图 b),直接使用联合自注意力层 (joint self-attention) 进行两种模态特征的融合与对齐。它同时承担了单模态内的建模以及跨模态的融合任务,无需引入任何新的模块。
二、方法设计
1. 架构描述
JoVA 采用 Waver 作为基础模型。为了实现音频生成,JoVA 首先通过复制预训练视频主干网络 (Backbone) 的参数来初始化音频扩散模型。在特征提取方面,采用了 MMAudio VAE 将原始音频转换为声谱图潜在表示 (Latent Representation)。
音频分支的训练沿用了与视频分支相同的流匹配 (Flow Matching) 目标函数。在预训练阶段,视频和音频模态是独立训练的;而在后续阶段,两者被统一整合进同一个架构中进行并行处理。此外,对于视频生成,模型支持参考图像 (Reference Image) 作为条件输入。该图像经由视频 VAE 编码后,在通道维度上与噪声视频潜特征进行拼接。
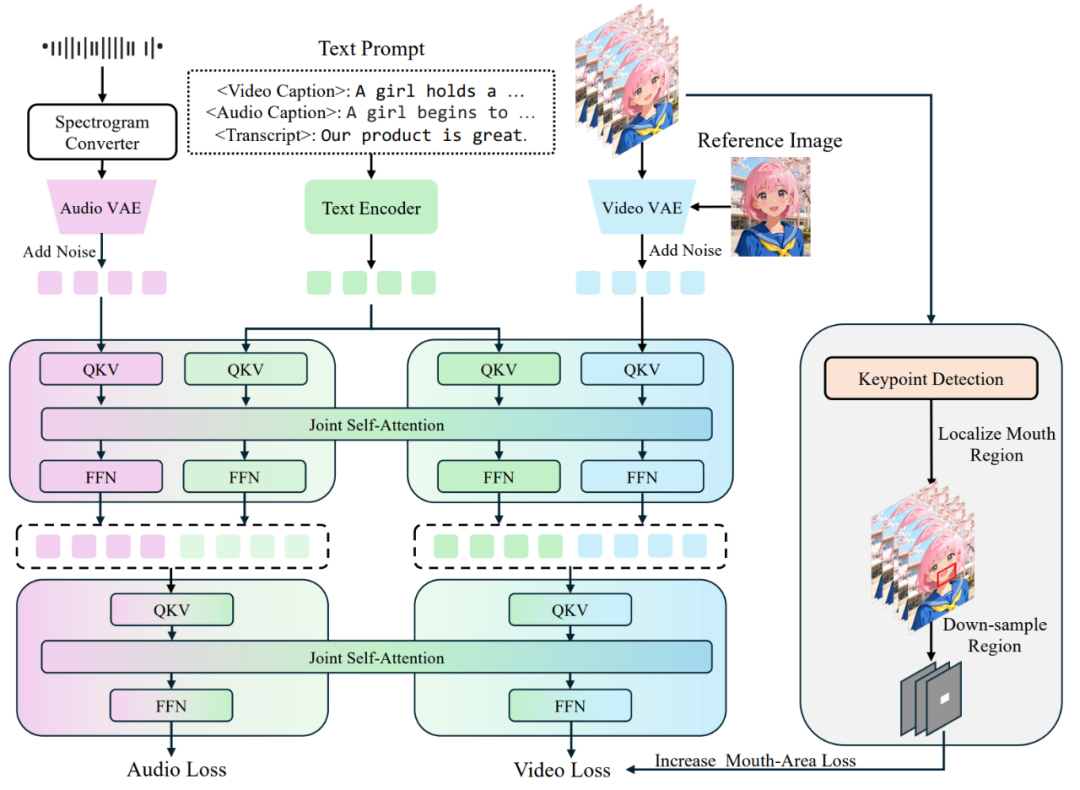
2. 音频 - 视频 - 文本联合自注意力层
为了实现模态间的融合,JoVA 在 Transformer 块内部采用联合自注意力机制(Joint Self-Attention)。具体而言,视频 Token、音频 Token 以及对应的文本 Token 被拼接在一起,输入到共享的自注意力层中进行处理。这种设计允许不同模态的 Token 在每一层都进行直接的信息交换,既保留了各自的预训练知识,又实现了特征融合。为了确保视频与音频在时间维度上的精确同步,模型采用了源自 MMAudio 的时间对齐旋转位置编码(Temporal-aligned RoPE),在时间维度上同步了两种模态的位置编码。
3. 潜空间嘴部区域感知监督(Mouth-Aware Supervision)
为了解决人像生成中的唇形同步问题,JoVA 引入了一种针对嘴部区域的增强监督策略。该过程包含三个步骤:
- 区域定位:首先在原始视频帧上进行面部关键点检测,计算出覆盖嘴部区域的像素级边界框。
- 潜空间映射:将像素空间的边界框映射到 VAE 的潜空间。这包括空间上的缩放(除以空间下采样因子 s)和时间上的滑动窗口聚合(根据时间下采样因子 t 合并窗口内的边界框),以精确定位潜特征中的嘴部区域。
- 加权损失:在训练目标函数中引入了专门的嘴部损失项。该损失仅对视频潜特征中的嘴部掩码区域计算流匹配损失,并通过权重系数进行调节。最终的总损失函数由视频损失、音频损失和嘴部区域损失共同构成,从而在不增加推理阶段架构复杂度的前提下,强制模型学习细粒度的唇形 - 语音对齐。
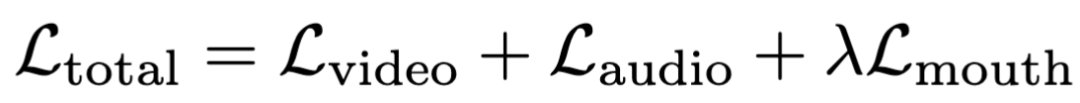
如下图,我们可以发现,这种映射方式可以很好地在潜空间定位到嘴部区域:

三、训练数据集构建
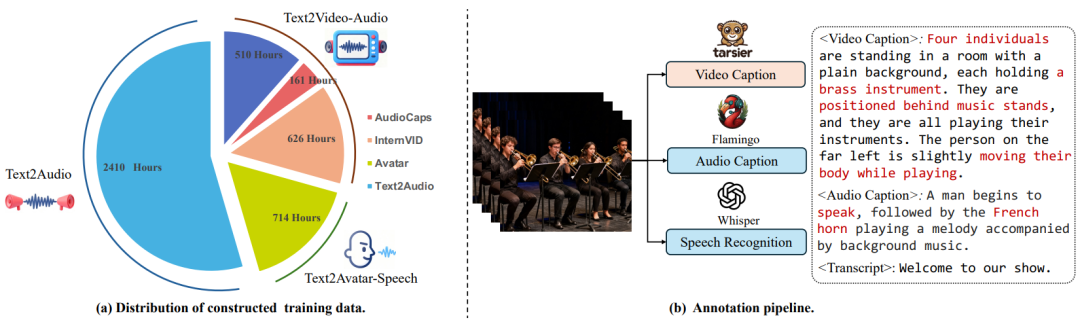
作者构建了包含三个部分的训练数据集:Text2Audio(环境音)、Text2Video-Audio(自然场景视听对)以及 Text2Avatar-Speech(数字人 / 说话人视频),总共约 1.9M 的训练样本。数据标注采用了一套自动化流水线:使用 Tarsier2 生成视频描述,Audio-flamingo3 生成音频描述,并利用 Whisper 进行自动语音识别(ASR)以获取语音文本。
在实施细节上,采用两阶段训练策略:先进行语音单模态独立训练(80K 步),再进行联合视听训练(50K 步),并在推理时使用了分类器无关引导(Classifier-Free Guidance)以提升生成质量。
四、实验结果
1. SOTA 方法对比
在 UniAvatar-Bench(作者精选的 100 个样本)和 Verse-Bench(600 个多样化样本)两个基准上进行了评估。对比对象包括两类:一是使用真实音频驱动的视频生成模型(如 Wan-S2V, Fantasy-Talking),二是联合视听生成模型(如 Universe-1, OVI)。
UniAvatar-Bench 表现:JoVA 在整体性能上表现最佳。
- 唇形同步(LSE-C):得分为 6.64,不仅优于联合生成模型 OVI (6.41) 和 Universe-1 (1.62),甚至超过了使用真实音频驱动的 Wan-S2V (6.43),证明了嘴部监督策略的有效性。
- 语音与音频质量:在文本转语音准确性上,JoVA 取得了最低的词错误率(WER 0.18);在音频生成指标(FD, KL, CE, CU, PQ)上均取得最佳分数。
- 视频质量:在动态程度(MS 0.98)和美学评分(AS 0.47)上均领先。虽然身份一致性(ID 0.78)低于音频驱动模型,但在联合生成任务中处于合理范围。
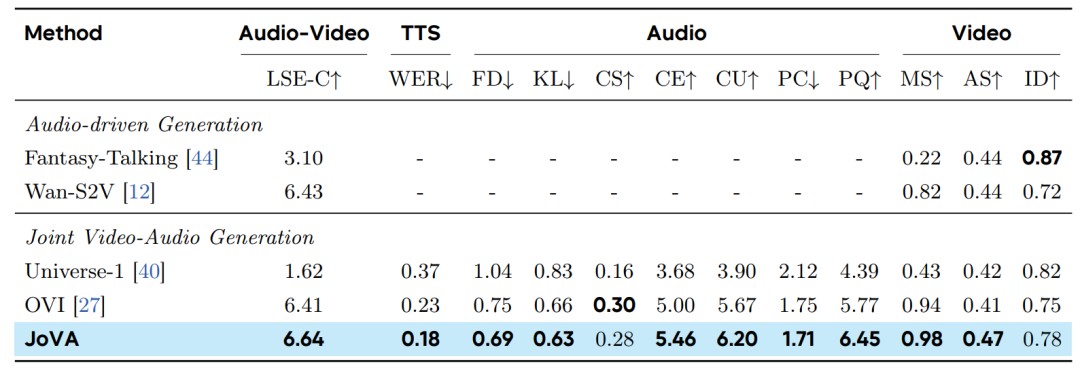
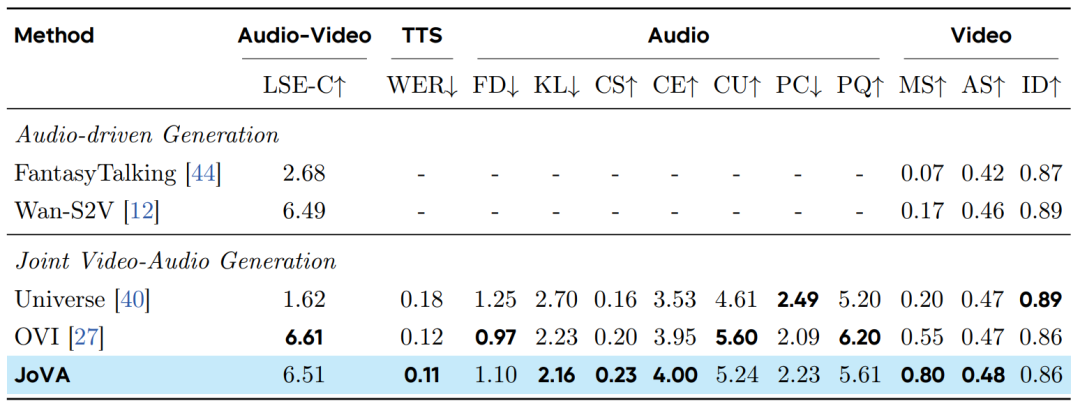
Verse-Bench 表现:JoVA 展现了在多样化场景下的鲁棒性。
- 语音准确性:WER 低至 0.11,验证了其稳健的语音合成能力。
- 视听对齐:LSE-C 得分为 6.51,略低于 OVI (6.61) 但远高于 Universe (1.62)。
- 综合质量:在保持最高视频动态(MS 0.80)和美学质量(AS 0.48)的同时,音频生成的一致性(CS, CE)也达到了最优水平。
模型扩展性与效率分析
研究进一步对比了基于 Waver-1.6B(总参数量 3.2B)和 Waver-12B(总参数量 24B)主干网络的 JoVA 模型性能:
- 小模型的高效性:仅使用 3.2B 参数和 1.9M 训练数据的 JoVA 模型,其 LSE-C 得分达到 6.20,显著优于参数量更大(7.1B)且训练数据更多(6.4M)的 Universe-1 模型(LSE-C 1.62),并与 10.9B 参数的 OVI 模型具备竞争力。
- 大模型的性能上限:随着参数量增加至 24B,JoVA 在各项指标上均达到最佳水平(LSE-C 提升至 6.64,WER 降至 0.18)。

2. 融合实验对比
为了验证各模块的有效性,作者进行了多项消融实验:
嘴部感知损失(Mouth-Aware Loss)的影响:
- 当权重为 0.0 时,模型无法学习细粒度的唇形对齐(LSE-C 仅为 1.39)。
- 增加权重至 5.0 时,LSE-C 显著提升至 6.64,且未损害其他音频或视频质量指标。这表明针对嘴部区域的显式监督对于实现精确同步至关重要。
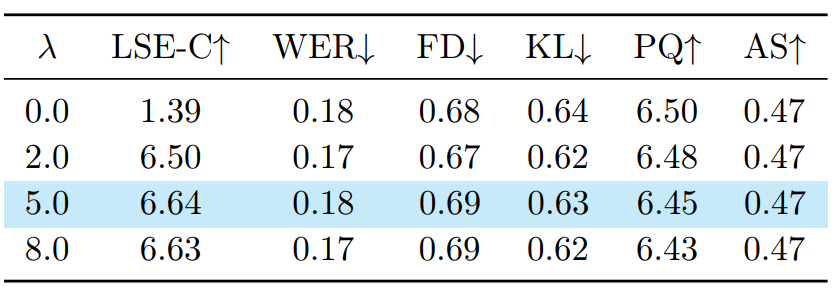
时间对齐 RoPE 的影响:
- 采用时间对齐的 RoPE(视频和音频共享时间维度的位置编码)相比未对齐版本,LSE-C 从 6.58 提升至 6.64。
- 尽管在音频分布相似度(FD)上存在轻微折损(0.58 vs 0.69),但该设计显著增强了帧级的时间对应关系,更利于人像视频生成。

联合自注意力 vs. 交叉注意力:
- 对比结果显示,联合自注意力(Joint Self-Attention) 机制在唇形同步(LSE-C 6.64)和语音准确性(WER 0.18)上均优于交叉注意力变体。
- 特别是带线性适配层的交叉注意力方案表现最差(LSE-C 1.63)。这证实了在统一的注意力空间内直接处理多模态 Token,比通过独立的交叉注意力模块更能促进特征的有效对齐。

如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。